基于Apriori风险数据分析的网络漏洞挖掘研究
2022-03-01管军霖师功才
管军霖,师功才,陈 宏
(桂林电子科技大学计算机与信息安全学院,广西 桂林 541004)
1 引言
网络应用服务的增加,促进了人们对网络环境的关注。安全良好的网络有利于抵抗攻击行为,保护用户的敏感数据。网络漏洞是导致入侵攻击的主要因素[1],现代网络每时每刻都在遭受大量的恶意攻击,黑客通过寻找网络漏洞,将一些脚本植入应用,进而截获所需数据并谋取利益[2-3]。因此,网络漏洞的及时准确发现是关乎网络安全的关键[4]。
对于网络漏洞的挖掘,早期的思想是构造漏洞库,通过比较的方式识别出漏洞的存在。如文献[5]通过对比网页信息与规则库来识别SQL或者XSS攻击,优点是能够支持GET与POST请求,缺点是挖掘速度较慢。由于漏洞库比较的方式在实际应用场合中过于复杂,受到的限制较多,一些学者提出了动态分析挖掘。如文献[6]利用载荷单元的属性差异对攻击行为采取划分,同时也建立了规则库,这种方法能够避开对源码的依赖,但是相对而言准确性要差一些。于是,又有部分学者开始从漏洞入侵日志着手,通过引入一些数据分析算法来达到漏洞检测的目的。如文献[7]针对WEB应用采用了一种SVM算法,对HTTP报文进行特征提取及分类处理,这种方法能够保持良好的泛化性,但是应用范围过于狭窄,目前只支持对Struts2-045的识别。文献[8]对入侵攻击的风险日志采取关联规则分析,通过与库的比较实现漏洞挖掘,这种方法充分利用日志信息,很好的把数据分析与漏洞挖掘结合起来,但是在数据处理和时间性能方面仍有很大的优化空间。
随着应用对漏洞攻击日志的大量收集,通过日志分析能够获取到很多关于漏洞的价值信息,因此,本文也采用风险数据分析技术完成漏洞挖掘。为改善风险数据的可用性,在预处理阶段对数据进行标准化和去冗余操作,再利用Apriori算法增强置信度和关联规则计算,提高对漏洞挖掘的准确性和效率。最后将分析挖掘算法在MapReduce上实现,进一步提高漏洞挖掘过程对海量数据的处理性能。
2 网络风险数据融合模型
风险数据保存了网络攻击行为,是网络漏洞挖掘的数据基础,在识别网络入侵的时候,相同类型的入侵会生成众多格式近似的风险数据,非相同类型的入侵会生成不同格式的风险数据。由于入侵类型的不同,要么得到大量异构风险数据,要么得到大量冗余风险数据,不管类型差异与否,都将给网络漏洞挖掘带来严重数据干扰。于是,本文在漏洞挖掘的初始阶段对风险数据采取融合处理。
对几类典型的风险数据进行格式分析。根据数据分析,能够得到漏洞信息,从而指导攻击防御。表1罗列了Ossec、Snort和Firewall三类风险数据格式。对于不同的风险数据,包含的字段信息并非完全相同,需要对其进行标准化处理来提高数据的处理性能。在标准化过程中,应充分考虑字段对网络攻击的表达,确保标准化字段可以清楚描述攻击属性。表2列举了标准化后的风险数据字段。经过格式标准化处理后,所有的入侵信息被统一描述,避免了异构数据对分析性能的影响。

表1 三类典型风险数据格式

表2 标准化风险数据字段
除了格式标准化以外,风险数据还存在大量近似的攻击日志,为降低数据冗余度,对数据采取相似度融合。因为字段存在多个类型,且每个字段对相似度的影响程度各不相同,所以针对每个字段采取独立的相似度求解,再通过权重得到整体相似度。参与相似度计算的字段包括:Time、Src_IP/Dst_IP、Src_Port/Dst_Port、Type、Level、Pro_Type以及Description。
在某个时间范围内产生的风险数据,可能是由某个共同的入侵行为引起。假定两次风险日志依次表示为Risk1与Risk2,则根据它们在时间上的接近程度,将时间相似度描述为

(1)
其中,Thtime表示时间阈值,用于控制时间相似度的衡量标准。Risk1与Risk2的时间越靠近,表明Risk1与Risk2的相似度越高。
当风险数据中的网络地址较为接近时,也意味着可能是由同种网络入侵所造成。某些网络入侵会针对同一网段主机发起攻击,考虑IP字段的位数,将IP相似度描述为
Sip=k/bitip
(2)
其中,bitip表示IP对应的二进制位数;k表示相同的位数。IP用于区分主机,端口号用于区分服务类型,端口号为int类型,根据两条风险数据中的端口一致性,利用boole类型表示其相似度,端口一致则Sport=1,否则Sport=0。描述如下

(3)
与Src_Port/Dst_Port字段类似,对Type、Level、Pro_Type和Description字段相似度的计算也同样根据一致性判断,将相似度描述为boole类型,分别标记为Stype、Slevel、SproType和Sdesc。基于各字段独立相似度,通过加权求解风险数据的整体相似度,公式描述为
Stotal=ω1*Stime+ω2*Sip+ω3*Sport+ω4*Stype+ω5*Slevel+ω6*SproType+ω7*Sdesc
(4)
其中,ω1~ω7分别代表各字段的加权系数。
3 Apriori 挖掘算法
Apriori算法的基础是关联规则,对于一组具有关联规则的事务,对应集合可以表示为A={A1,A2,…,An}。A中全部项集表示为I={I1,I2,…,Im},m代表项特征数量。对于任何X⊆I,Y⊆I,如果存在X→Y关联规则,则有X∩Y=∅。假定集合A内包含X∪Y项的事务比例为p,则可得如下表达式
Sup(X∪Y)=P(X∪Y)=p
(5)
根据Sup(X∪Y)与Sup(X),可得X→Y的置信度为

(6)
通过对Sup(X∪Y)与C(X→Y)的最小限制可以确定频集。为防止出现大量小候选集,在采取数据扫描之前,将数据转换成布尔矩阵处理。把A视为行向量,I视为列向量。当项i包含于事务j中时,就令对应的矩阵元素等于1,否则等于0。从而得到关于事务与项的布尔矩阵。每一行代表一条事务记录,每一列代表一项记录。布尔矩阵表示如下

(7)
矩阵B(i)n×m第i行是事务i对应数据;第j列是项特征j对应数据。通过第j列元素累加,计算出项特征j支持度如下

(8)
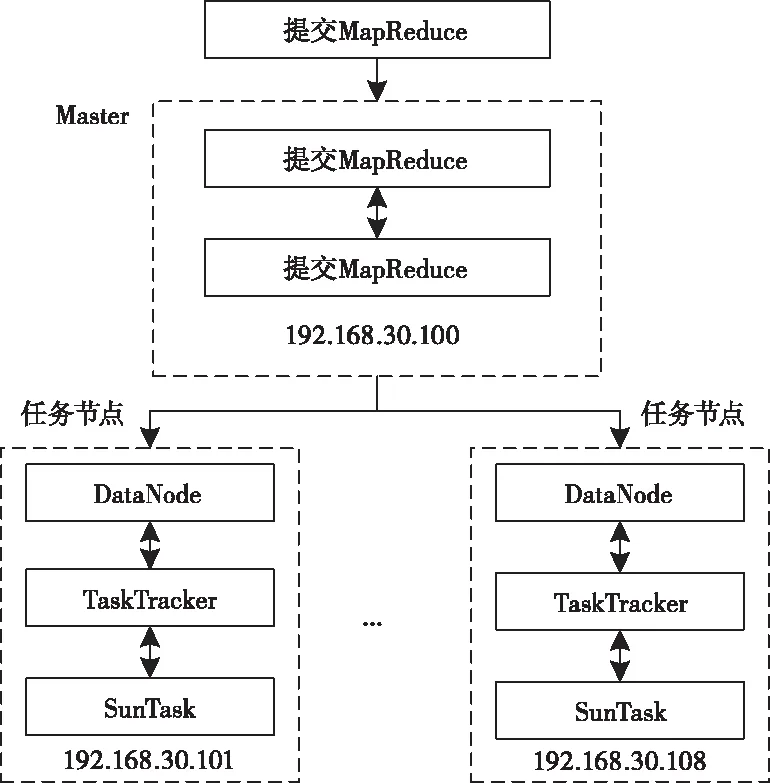
对B(i)n×m进行扫描,将Sup(Ij)和最小限制TSup做比较,符合Sup(Ij) (9) 因为当行值低于2的时候,将不再生成频集,所以能够避免形成大量小候选集。比较Sup(Ij→Il)和最小限制TSup,去掉U2中小于TSup的元素,建立频集F2。根据F2,计算得到项间置信度为: (10) 依据置信度比较能够确定强关联规则。为确保关联规则的合理有效,设计评判策略,构建评判矩阵如下 (11) 矩阵元素hij是事务i对项j的评判。如果hij大于零,说明事务i对项j采取过评判;如果hij等于零,说明事务i对项j未采取过评判。结合事务对项的置信度,得到预评判如下 E(i)ij=max(H(i))×C(i)kj (12) 其中1≤k≤m。利用E(i)ij值构建预评判矩阵,构建方式描述为 (13) 其中ai表示项加权系数。对于En×m中等于零的元素,选择关联项的预评判来替换。从而使得到的关联规则能够更好的体现事务联系。 根据网络风险数据融合与Apriori算法架构,基于MapReduce的网络漏洞挖掘模型描述如图1所示。 图1 基于MapReduce的网络漏洞挖掘模型 仿真基于Windows10操作系统,Java开发环境为JDK1.8,选择EasyJSP、Jauction、Jinsure、Jvote,以及MeshCMS五类项目。搭建网络漏洞挖掘云模型,实现MapReduce架构,如图2所示。本文共配置了9台机器,包含1台Master和8台任务节点。它们的操作系统均为Ubuntu,开发环境也为JDK1.8。 图2 网络漏洞挖掘云模型 风险数据融合过程中,设置各字段的加权系数ω1=0.1,ω2=0.15,ω3=0.1,ω4=0.2,ω5=0.1,ω6=0.2,ω7=0.15。Apriori算法处理过程中,设置支持度阈值为0.55,置信度阈值为0.65。实验从漏洞挖掘效率和挖掘精度两方面对网络漏洞挖掘效果进行分析,另外,引入文献[8]作为性能比较。由于文献[8]中没有提及分布式云框架,所以在模拟文献[8]的过程中没有采用云模型。 由于本文和文献[8]都采用了关联规则对风险数据进行分析,差别是本文引入了Apriori算法优化关联规则的搜索。为了比较本文相对文献[8]在关联规则查找方面的性能,通过仿真得到规则比较次数。分别向五个测试应用中注入Medium XSS反射攻击,在请求次数达到5000的情况下,记录漏洞挖掘过程中的单次规则比较次数,结果如图3所示。 图3 规则比较次数 根据实验结果对比,本文的规则比较次数较文献[8]有所降低,五个项目的比较次数依次降低了18.61%、24.44%、11.63%、21.95%和5.26%。比较次数的缩减,说明对关联规则查找效率的提升,此外关联规则的查找会影响漏洞挖掘速度,有利于降低漏洞挖掘的响应时间。 分别向五个测试项目中注入Medium XSS反射攻击,在请求次数达到5000的情况下,记录漏洞挖掘的平均响应时延,结果如图4所示。 图4 平均响应时延 根据实验结果对比,本文的漏洞挖掘方法平均响应时延大幅降低,五个项目的响应时延依次降低了7.805s、8.211s、9.698s、8.588s和9.170s。此外可以看出,文献[8]对于不同的项目会产生较为明显的响应时延差异,最大和最小平均时延相差1.830s。而本文方法对于所有的测试项目都具有较为接近的响应时延,最大和最小平均时延仅相差0.118s。结果说明本文所提的挖掘方法在时间性能上有显著的优势,不仅缩短了平均响应时延,还提高了不同应用的稳定性。导致这种结果的原因是:对风险数据的融合处理降低了初始数据的冗余性和异构性,有效去除了同一入侵行为产生的大量风险数据,规范了不同入侵行为产生的不同格式数据,有利于数据的操作和分析;改进Apriori算法对风险数据关联规则分析的优化,避免了小候选集的过多出现;MapReduce框架实现了Apriori算法漏洞挖掘的并行计算。 通过准确率和误报率来验证漏洞挖掘精度。实验得到五个项目对应的准确率和误报率结果,如图5和图6所示。 图5 漏洞挖掘准确率 图6 漏洞挖掘误报率 根据实验结果对比,本文的漏洞挖掘方法准确率明显提升,五个项目的准确率依次提高了7.38%、6.78%、3.64%、5.45%和5.53%,所有项目的准确率均在92%以上。误报率明显下降,五个项目的误报率依次下降了6.40%、6.62%、3.18%、4.26%和4.36%,所有项目的误报率均在4%以下。结果表明本文方法有效提高了网络漏洞的挖掘精度,得益于改进Apriori算法对频集和关联规则的准确提取。 针对网络漏洞入侵攻击,提出一种改进Apriori风险数据分析挖掘方法。该方法通过对大量风险日志的融合分析,得到数据间的关联规则,从中搜索得出漏洞信息。实验搭建了基于MapReduce架构的漏洞挖掘模型,从挖掘效率和挖掘精度两方面进行仿真分析,得到结果为:单次请求的规则比较次数为35,响应时延为2.73s;五个项目的平均准确率为93.87%,平均误报率为3.17%。结果表明风险数据处理和改进Apriori算法有效优化了关联规则查找性能,通过风险数据分析结合MapReduce架构,显著提升了漏洞挖掘的效率和精度。




4 仿真与结果分析
4.1 仿真环境搭建
4.2 挖掘效率分析


4.3 挖掘精度分析


5 结束语
