基于混合推荐技术的新闻推荐系统
2022-03-01陈昱霖温源周洪宇李佳奇李晨
陈昱霖,温源,周洪宇,李佳奇,李晨
(北京信息科技大学 计算机学院,北京 100011)
0 引言
随着信息时代的来临,互联网提供了非常便捷的消息获取方式,越来越多的人青睐于在线读取新闻报道。但在网络上有几百万篇来自不同渠道、不同领域的新闻报道,使用户迷失在海量数据中,以至于需要花费大量的时间和精力来甄别自己想看的新闻,即产生了" 信息过载"问题。推荐系统(Recommendation System)是一种信息过滤系统,其根据分析用户的兴趣特点和历史行为数据,预测用户对物品的评分或偏好,帮助用户决策分析。好的推荐算法能够帮助用户快速定位目标,节约大量时间,提升用户体验,从而也能提高用户黏性。
推荐算法经过多年的研究,虽然形成了一些较为成熟稳定的体系,但推荐算法并没有形成统一的分类标准。国内外主流的推荐算法分类主要有:基于内容(Content-Based)的推荐、协同过滤(Collaborative-Filtering)推荐和混合推荐(CF+CB)。而协同过滤又 可分为基于邻域(Neighborhood-Based)的协同过滤和基于模型(Model-Based)的协同过滤。几类常用推荐算法的基本实现过程:
(1)基于内容的推荐算法:提取用户历史的特征,学习用户的兴趣特征表示,进而筛选出与用户历史喜欢相关性较强的内容;也可以根据用户选择的对象,推荐与当前对象具有相同特征的对象内容。
(2)协同过滤算法:主要思想是根据现有用户群以往的意见和行为,对当前用户最有可能感兴趣的物品进行推荐。
(3)混合推荐算法:将两种或两种以上算法和模型的优点结合在一起。一般分为整体式混合、并行混合、流水线混合等混合设计。
本文研究目的是开发一种针对于“新闻推荐”这一行为的解决方案,并且努力使这一解决方案具有较强的兼容性及应用性。通过研究混合推荐技术,设计并实现一套可行的新闻推荐系统。该系统最终会以一个轻量级程序的形式(例如微信小程序)展现出来。本文主要阐述新闻推荐系统的基本原理与实现。对于“推荐”这一行为,需要经过数据挖掘与清洗、推荐算法的选择与实现、推荐系统的评估以及推荐系统的优化等过程方能得以实现。
1 数据挖掘
数据挖掘是个性化推荐的第一步,也是推荐算法的计算依据。在这一步中将要对原始数据进行清洗与变形,该步骤的完整程度决定了后续推荐中的准确度。
1.1 数据预处理
数据预处理是指在利用数据进行建模或分析之前,对原生数据进行清洗与标准化的过程。对于利用爬虫等工具所获取的初始数据,由于具有一定的随机性,因此预处理是必不可少的一个环节。
1.1.1 新闻热度值
新闻热度值是该新闻是否被推荐的重要因素,其可以直观地看出一个新闻在当下受关注程度。每天都要对每条新闻的热度值进行计算,且要将每天的热度值存进数据库中方便调用。新闻热度值的计算公式为:

其中,为新闻热度值;为点击量;为当前日期;为发布日期。
在这样的计算方法下,既不会出现某条新闻的热度值持续过高,每次都进行推荐,也不会出现某条新闻连续推荐时间过长的现象。
1.1.2 数据标准化
数据标准化可以使不同新闻之间有一个更加公平的比对,其数据标准化有多种方式,本文采用的是Min-max 标准化。Min-max 标准化是将0~1 作为一个标尺,标准化后数值越靠近1,说明该新闻热度越高。标准化数值计算公式如下:
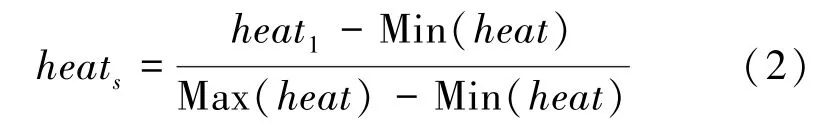
其中,heat为新闻热度标准化数值;为当日新闻热度;Min()为往日热度最小值;Max()为往日热度最大值。由公式可以看出,热度值标准化数值越大,表示其最近受关注度越高,越值得推荐。反之,则不值得推荐。
1.1.3 新闻分词处理
Jieba 是python的第三方中文分词库,可以将文本拆分成一个个词汇,且支持中、英文。虽然Jieba的搜索引擎模式与全模式都可以对新闻标题进行处理,但搜索引擎模式可以最大限度的对标题进行分词处理,不存在冗余数据。因此,本研究选择搜索引擎模式对其进行处理。
1.1.4 数据降维
数据降维可以使一个新闻的特征更加明显,在对新闻标题分词后,若分词过多则必然会产生一些停用词。当新闻标题分词后维度大于8 时,将分词中的停用词删除,直至该新闻分词维度小于等于8。
1.1.5 数据清洗
在计算出热度值的标准化数值后,可能会出现一些数据计算失误,导致其数据超出[0,1]区间或无法计算的情况,此时需要针对不同情况对其进行修正。
(1)数据无效:当新闻第一天出现的时候,其往日最大新闻热度值及最小值均为0,此时式(2)中分母为0 无意义,因此将热度标准化数值改为1。
(2)数据不一致:因为是混合推荐技术的新闻推荐系统,所以导入的数据集不只一个,而是多方提供的数据。因此,很可能在两方提供的数据中有相同的新闻,但其历史信息有所不同,导致计算标准化数值时出错。对于这种脏数据的处理,只保留一方的数据,另一方删除。
(3)数据缺失:在导入数据集过程中,新闻历史数据可能会出现缺失的情况。其原因可能为本身缺失或是导入过程中出现缺失。对于这种情况的处理办法为整例删除。
1.2 相似度计算
在计算两篇文章的相似度时,需要用到TF-IDF算法。简单理解来说,TF 为文章中的词频,IDF 为逆文本频率指数,IDF 越高,说明这个词汇越偏。当TF、IDF 都高时,该词汇很可能为中心词,在相似度计算时,每篇文章都取20个TF-IDF 最高的词,各放到一个集合里作为特征词。
1.2.1 欧氏距离
欧氏距离源自两点间的距离公式,在计算文章相似度时也可用到。其计算公式为:
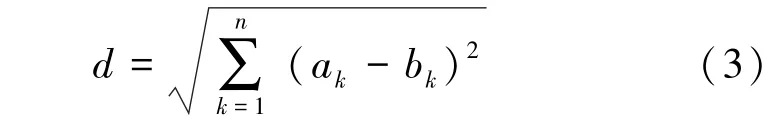
其中,为欧氏距离,ab为、两组对应位置的元素,值越小,两篇文章相似度越高。
1.2.2 夹角余弦距离
、两向量取值方法与欧式距离向量、相同。计算公式为:

其中,为夹角余弦距离,A、B为、向量的第个元素。当余弦值越靠近1,说明相似度越大,否则相似度越小。
1.3 关联分析
在向用户进行新闻推荐时,需要根据用户的喜好来进行推荐,这样能够更好地提高用户的使用体验。通过Apriori 算法找出用户关注度高的话题,然后找到其中关联规则,从而向用户进行推荐。
2 混合新闻推荐算法设计
2.1 原理简述
首先通过映射,将三维系统转化为3个两维的系统:客户-客户、新闻-新闻、标签-标签。在此基础上对传统推荐算法进行简化和创新。其中包括:建立基于TF∗IDF的用户模型、优化用户对标签的喜好度评估算法、用户对标签的依赖程度评价、建立标签基因以对用户喜好溯源。根据以上分析对用户兴趣建模,挖掘用户感兴趣的新闻内容。
如前所述,推荐算法有多种,本项目中主要使用的是协同过滤推荐算法。该算法易理解也很有效,可最直接的反应人类大脑判断别人喜好的过程和步骤。该算法基本实现步骤如下:
(1)判断用户所喜欢事物的特征;
(2)在数据库中寻找与用户喜欢事物特征相似的事物;
(3)为特征相似的事物排序,判断其排序后最符合用户喜欢事物的特征,利用推荐算法判断用户喜好。
2.2 基于标签的推荐
2.2.1 数据标注
关键词是指能够反映文本语料主题的词语或短语。在不同的业务场景中,词语和短语具有不同的意义。如,从新闻中仅仅需要提取关键词就能够传达重要新闻内容。
数据标注是对数据进行唯一(或不唯一)的标注。标注有许多类型,由于本文探究的是新闻文本的推荐算法,所以只介绍文本类的标注,叫做分类标注。分类标注即打标签,一般指从既定的标签中选择数据对应的标签,得到的结果是一个封闭的集合,常用在图像、文本中。
数据标注步骤如下:
(1)确定标注标准:设置标注样例和模板(如标注颜色时对应的比色卡等)。对于模棱两可的数据,制定统一的处理方式。
(2)确定标注形式:标注形式一般由算法人员确定。例如,在垃圾问题识别中,垃圾问题标注为1,正常问题标注为0。
(3)确定标注方法:可以使用人工标注,也可以针对不同的标注类型采用相应的工具进行标注。
2.2.2 标签的分类
传统基于标签的检索采用强制匹配方式,把查询条件包含的标签关联的项目作为检索结果。该检索方式没有考虑标签的关系,如同义或多义、相关或不相关等。因此,如果用户给出的查询条件不恰当,将导致检索结果不符合要求。通过研究标签关系,可以对用户的查询条件进行语义化扩展,进而得到用户更想得到的检索结果。例如用户搜索‘苹果’一词时,可以检索出‘apple'。由此,可以将标签关系分为:不相关、同义相关以及多义相关。如图1 所示:
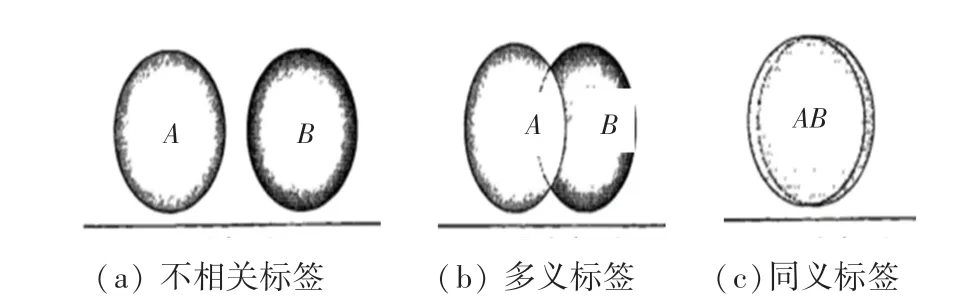
图1 标签相关度Fig.1 Relevance of tags
其中,图1(a)表示标签与的语义集合不相交,即标签、不相关;图1()表示标签、语义集合部分相交,虽然在一定程度上存在语义重叠,但都可以表示自己特有的语义;图1(c)表示标签、的语义集合基本上重叠,因此这两个标签属于同义标签。
2.2.3 基于TD-IDF的关键词提取
TF-IDF 是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF 算法的主要思想是:如果某个词或短语在一篇文章中出现的频率(TF)高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类。
通常,在一篇新闻内容中提取关键词不能只考虑词频(TF),因为有大量的介词、虚词等无关紧要的词将对模型产生影响。为了减少这些词对推荐模型的影响程度,就需要逆文档频率,其能够削弱大多数文档中常用的高频词汇的权重,对小部分文档中出现的低频词汇进行权重增强达到均衡。于是TFIDF 特征权重计算公式可以概括为:
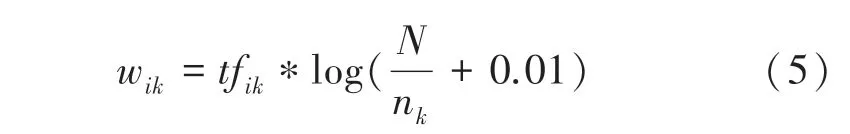
式中,为文本总数;tf为特征项在文档中出现的次数; n为包含特征项的文档数。
为了降低个别高频特征词对其他低频特征词的抑制作用,通常要对特征的权重进行归一化处理。TFIDF的归一化形式为:
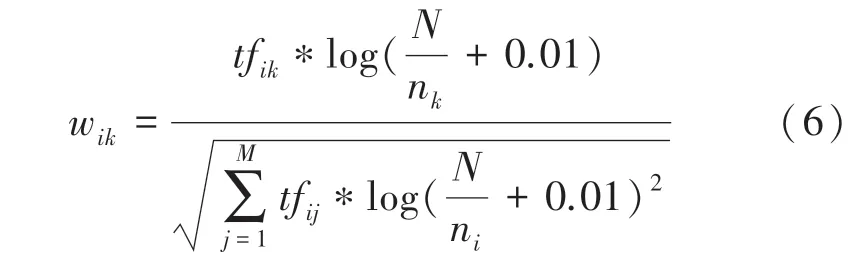
根据此算法计算某特征词的TFIDF值,当w大于某个阈值时,将其认为是关键词,极大程度避免了一些具有偶然性的高频词对模型产生较大影响。TFIDF 算法提取关键词的步骤为:
(1)对标题进行分词并进行停用词去除;
(2)计算TFIDF值;
(3)生成关键词;
(4)在jieba 分词结果中提取TFIDF 计算出来的关键词。
3 新闻推荐系统实现
本项目所设计的推荐系统主要以网页的形式呈现。由于后端的推荐算法是由python 设计的,为了后端与前端的交互方便,前端网页计划使用django框架制作,并且利用bootstrap和jquery 优化网页效果。
Django 作为主流且热门的网站框架,其使用的程序结构与MVC 类似,采用的是MVT(model,view,template)架构。其中model 主要用于与对数据库进行定义以及数据库的交互;view 类似于jsp 中的controller,用于后台控制网站的行为;template 即为“模板”,用于显示网页的前端效果。与MVC模式相比较,MTV模式下的开发复用性更好,一个template 可以同时供多个网站使用,只需加入不同的内容即可。这样既可以保证整个网站的风格统一,又降低了开发成本。由于Django 使用python 作为开发语言,因此很多底层功能可以直接使用现成的package,大大提升了开发效率。本项目主要针对推荐算法本身做文章,简单实用的Django 框架便是众多开发工具中最理想的选择。
3.1 前端设计
网站的前端设计主要涉及template的设计与开发。与jsp 技术不同,在Django 框架下,一个html 网页并不单单作为一个页面来使用,而是充当一个可以多次复用的模板。
模板功能的实现:当用户登入一个Django 框架的网站时,首先通过URL 控制器进行路由分发,匹配合适的view 视图函数;view 函数会根据程序员编写的流程,对models 进行读取或者是直接渲染一个模板返回到用户界面。不同的view 视图函数,能够对同一模板做渲染,且模板中的内容会根据view 传递的参数发生变化。这样的设计便能够让风格变化不大的页面进行复用,降低了大量的开发成本。整个框架的运行流程如图2 所示。

图2 MTV 结构的运行流程Fig.2 Operation process of MTV structure
所有的网页结构都基于导航栏与正文两个部分组成,导航栏在上方,这是一种基本的页面结构。主页模板布局如图3 所示。

图3 主页模板布局Fig.3 Homepage template layout
前端除了templates的设计,还涉及到对后端数据的展示。在该框架下先由控制器将数据处理好之后,通过相应API 传送到模板中。以主页为例,该页面需要的参数有新闻标题、新闻分类标签、用户信息等。其中,新闻标题和新闻标签作为一个列表传入页面中,用户信息只需传入一个用户名即可。在后台中,新闻列表将根据用户的信息进行排序,处理好后再进行输出。
在模板中调用参数的方式与在JSP 技术中相似,通过循环传入的参数,将列表中的每个元素利用遍历的方式显示在页面中。值得一提的是,本项目所有的页面都使用了bootstrap 来美化网页外观。且由于bootstrap 是一个响应式框架,因此使用bootstrap 能够让网页在不同尺寸的设备下不发生显示错位的问题。
3.2 后端设计
3.2.1 views 简述
在Django 框架中,负责后端行为的文件是views.py。在该文件下,网页开发者可以通过编写函数来控制网页的输出与数据的处理。同时,views 还负责与models的交互,通过models 对数据库进行读取与写入。在本项目中,数据库系统使用的是sqlite,该系统虽然是单线程的,但是由于其轻量且易移植的特性,特别适合本项目的数据存储。
views 主要由模板渲染模块、新闻推荐模块、用户管理模块3个部分组成。其中,模板渲染模块负责对处理好的新闻数据进行渲染,并输出到页面中供用户观看阅读;新闻推荐模块主要负责根据相关规则,对数据库中的新闻数据进行排序处理,最终生成一个列表,递交给渲染模块进行输出;用户管理模块主要负责存取用户的相关信息,在新闻推荐模块中利用用户的一些信息,作为对用户推荐的依据。
3.2.2 新闻推荐模块的实现
新闻推荐模块为后端核心模块,其主要有3 种推荐方式:
方式一:先计算出每个新闻的热度值,再根据热度值对新闻进行降序排序输出。每个新闻热度值计算规则如下:

其中,为该新闻被浏览次数;为该新闻被评论次数;为新闻发表日期与当前日期的时间差。
经过计算将每个新闻的热度值单独存储成一个字段,放入新闻记录中。当需要从新闻热度来对新闻做推荐时,只需要依据每条新闻的热度在列表中将其降序排列,即可得到一个热度从高向低的一个列表。最后将列表递交给渲染模块输出即可。热度推荐策略流程如图4 所示。
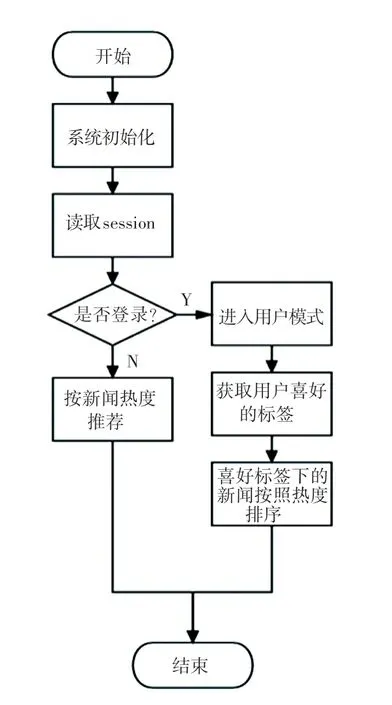
图4 热度推荐策略Fig.4 User recommendation strategy
方式二:根据新闻门类进行推荐。首先,需要对所有的新闻标题进行分词处理。一般而言,新闻的标题便总结了整篇新闻的主旨。因此,只要提取出每份新闻标题中出现频率最多的词汇,基本上就能断定这篇新闻的门类与属性。在本项目数据集中,共有1 000条新闻,这些新闻经过jieba 分词之后,共获得了22个关键词。将这22个关键词利用原生sql 语句进行分类,便可以分别得到22个新闻列表,将这些新闻列表传递给渲染模块输出即可。由于该方案需要较大的存储空间,因此可以通过网页中的表单传给后台需要的新闻门类,再利用sql 语句返回一个该新闻门类的列表,将22个列表压缩至一个,则减轻了服务器的负担。
方式三:根据用户的信息标签进行推荐。在新用户注册时,用户会选择几项感兴趣的门类,这些门类是通过数据库中新闻的分词结果动态显示,并不是固定好的。用户选择之后,在对网站的访问过程中,后端会优先显示其感兴趣的门类。这种推荐方式主要是为了应对推荐系统的“冷启动”问题。在推荐数据成型之前,使用标签推荐来应对推荐系统没有充足数据进行推荐分析的情况。同样,利用sql语句对需要的新闻对象整理成一个链表后渲染输出。在页面中,通过迭代循环的方式来读取新闻标题。标签推荐方式流程如图5 所示。

图5 标签推荐流程Fig.5 Label recommendation process
4 结束语
本文通过对混合推荐算法的探索与阐述,大致总结了市面上主流推荐算法的特点与实现方式。在实际的开发过程中,不同的推荐算法往往对某一特定类型的情况有较好的适应性。因此,解决推荐算法的最佳方案方式便是“博采众家之长”,不同的环境使用不同的推荐算法。因此,研究混合推荐技术是发展推荐算法的重要一步。本文针对混合推荐算法提出的一些浅薄的见解,希望能够给后续的研究提供参考。
