基于改进Deeplabv3+的雾气图像分割
2022-03-01冯传盟邢彦锋李学星蒋世谊
冯传盟,邢彦锋,李学星,蒋世谊
(1 上海工程技术大学 机械与汽车工程学院,上海 201620;2 无锡职业技术学院 机械技术学院,江苏 无锡 214121)
0 引言
在现实生活中,有很多场景都需要使用高压喷雾,例如烟气调质、汽车彩绘、焚烧炉降温等。其中,雾气几何形貌对其性能有着至关重要的影响,而精确将雾气与背景分割开来,则是准确测量雾气几何形貌的前提。传统分割算法分割速度较慢,分割结果存在缺陷。近年来,深度卷积神经网络由于其强大的特征提取能力,从而在分割任务上有着独特的表现。
语义分割是在像素级别理解图像,为图像中的每个像素分配一个类别。目前,在语义分割上应用深度卷积神经网络主要面临分辨率下降及多尺度目标的挑战。
对于分辨率下降问题:在特征提取过程中,连续的池化或者步长为2的卷积操作,会导致输入特征张量的分辨率持续降低,从而损失原始图像信息,且在上采样过程中难以完全恢复。Chen 等人提出的DeepLabv1 网络,将空洞卷积应用在语义分割任务中。空洞卷积的引入,能够在不增加额外学习参数的情况下,控制输出特征张量分辨率的同时,调整感受野的大小,从而有效解决这一挑战,这一技巧也被PSPNet 网络所采用。
对于多尺度目标的问题:在同一幅图像中,目标之间呈现出来的大小可能有差异,语义分割任务要求对不同大小的目标都要做到准确分割。Farabet等人通过将不同尺度的图像输入同一网络,得到不同大小的特征张量,将这些多尺度信息再做融合,解决多尺度目标。Jonathan Long 等人提出的语义分割开山之作—FCN 网络,定义了一种跳跃连接结构,使得语义信息可以和表征信息相结合,用以精细分割结果。Ronneberger 等人提出的U-Net 网络,以Concat 方式做了4 次特征融合,以满足精细的医学小目标分割任务。Vijay Badrinaryanan 等人提出的SegNet 网络,将编解码结构普适化,并在上采样过程中使用反池化操作,减少端到端的训练参数。Chen 等人在DeepLabv2 网络中提出ASPP 结构来获得多尺度信息。在DeepLabv3+网络中,为了捕捉更清晰的目标边界,在DeepLabv3基础上增加了解码结构。
虽然DeepLabv3+模型较好的解决了这上述两个挑战,但也存在一些不足。本文针对雾气研究对象,提出一种改进的DeepLabv3+算法。研究的主要贡献如下:
(1)对基础DeepLabv3+模型融合层结构进行重新设计,并加入边缘细化模块、注意力通道模块。
(2)在雾气图像上具有良好的分割结果,实现了快速精细分割。
1 DeepLabv3+基础模型
DeepLabv3+基础模型网络结构如图1 所示。该网络以DeepLabv3 网络作为编码器,在此基础上增加解码模块进一步优化分割结果。
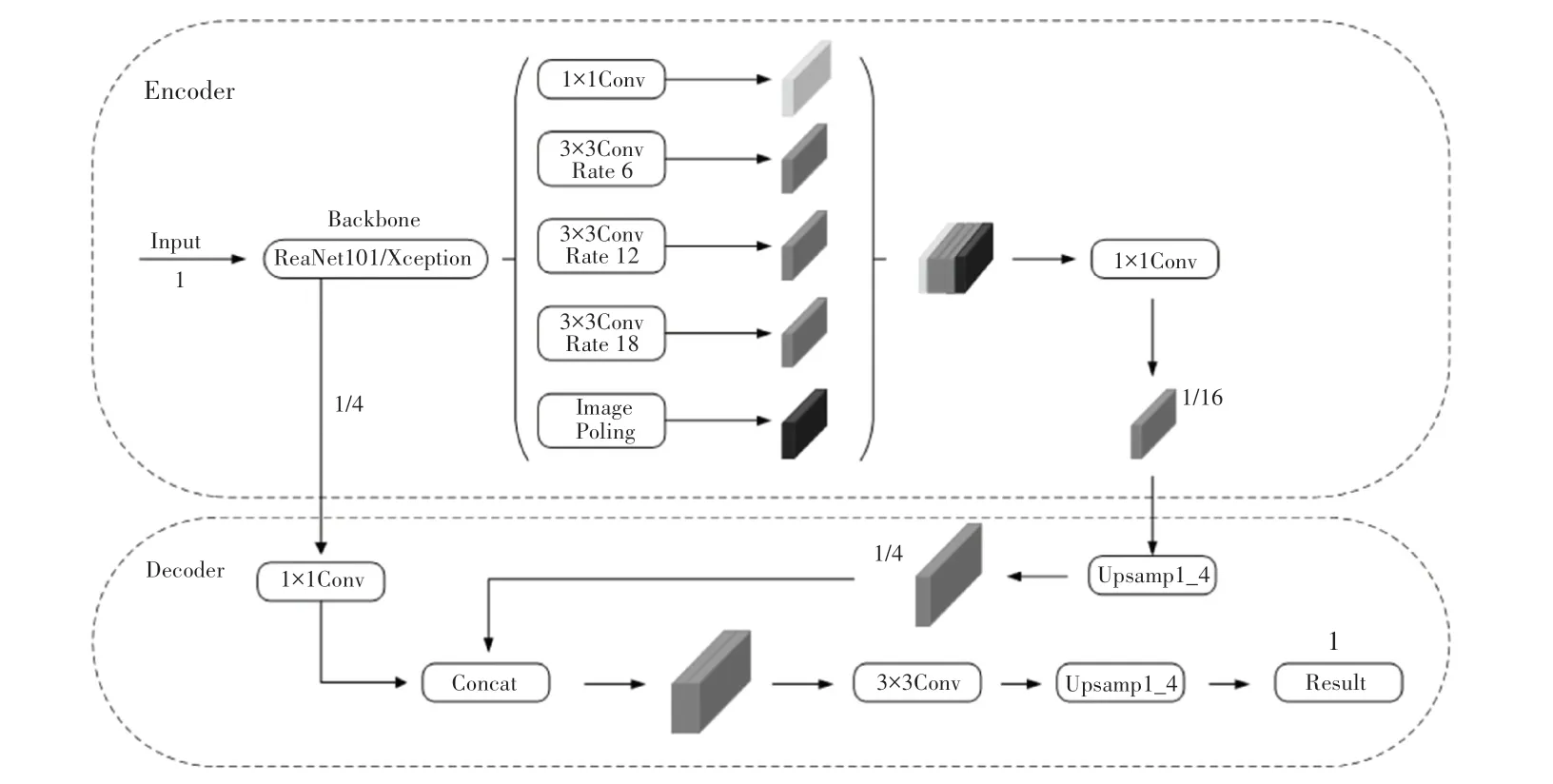
图1 基础Deeplabv3+模型网络结构Fig.1 Structure of the basic Deeplabv3 plus mode
在Encoder模块,初始输入图像在Backbone 过程有选择地保留阶段特征,以存储局部信息做后续融合。通过空洞卷积控制,输出特征张量分辨率的同时调整感受野的大小。在output-stride 等于16 时,Backbone 最终输出特征张量分辨率为原始图像1/16。不同于DeepLabv3 中ASPP模块,DeepLabv3+中ASPP模块由1个1∗1的普通卷积层,分别以6、12、18 为扩张率的并行空洞卷积层及1个全局池化特征层组成。ASPP模块输出的多尺度信息以Concat 方式拼接后,再通过1∗1 卷积进行通道压缩。
在Decoder模块,1∗1 卷积降维后输出的特征张量,通过第一次双线性插值上采样4 倍,与Backbone 阶段储存的同分辨率特征张量做融合,融合后的特征张量再经过3∗3的卷积及第二次双线性插值上采样4 倍,即可得到与原始输入图像相同分辨率的分割预测结果。
2 DeepLabv3+改进模型
2.1 融合层改进
DeepLabv3+基础模型以直接4 倍上采样的方式恢复图像分辨率,会造成特征张量中像素信息损失,破坏了图像中像素之间的连续性。且仅融合Encoder 过程中储存的1/4 大小的特征张量,忽略了更深层次特征张量包含的语义信息与浅层特征张量包含的空间细节信息,导致像素还原效果较差,最终雾气图像分割结果边缘信息丢失严重。基于此,本文提出的改进算法将Encoder 阶段产生的低分辨率深层特征与高分辨率浅层特征进行逐级融合,以连续2 倍上采样的方式,减少特征张量中像素信息损失,使分割边界更加精细。
2.2 边界细化模块
在ResNet 网络残差模块的启发下,改进模型也使用到了类似的残差模块,用以进一步细化目标边界(Boundary Refinement Model)。模块结构示意如图2 所示。输入特征张量,经过一个1∗1的卷积进行通道压缩;在残差分支,通过2个3∗3的卷积进行特征细化;最后与输入特征张量做Sum 融合。
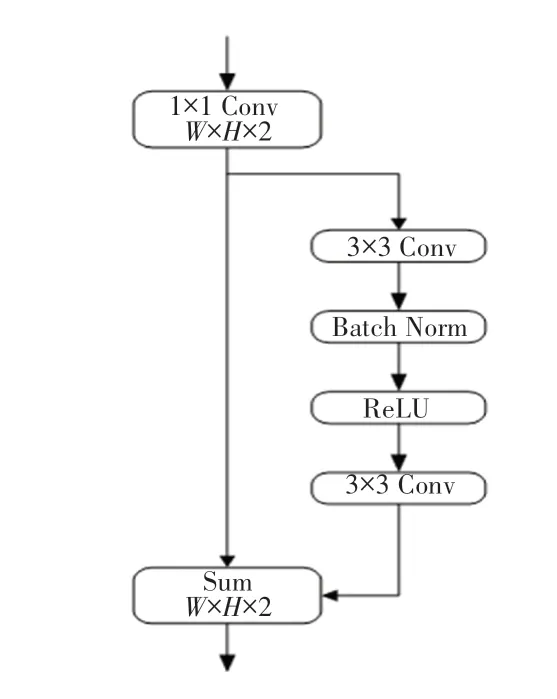
图2 边界细化模块Fig.2 Boundary Refinement Model
2.3 通道注意力模块
以连续2 倍上采样的方式,恢复图像分辨率包含更多的特征融合操作。由于浅层特征与深层特征所处位置不同,经历的卷积层有所差异。浅层特征包含更多的空间细节信息,深层特征包含更多的语义信息,若简单的将浅层特征与深层特征直接融合效果可能较差。为了弥补浅层与深层特征之间的信息差距,改进模型将深层特征中的语义信息引入浅层特征,以进一步增强特征融合。
在浅层与深层特征张量中,不同通道对目标预测能力的大小有差异。为了加强模型对重点通道特征张量的学习,快速提取重要特征并抑制对当前任务不重要的特征,改进模型使用到的注意力模块结构示意如图3 所示。浅层特征与深层特征Concat拼接后,输入全局池化层进行特征压缩。经第一个1∗1 卷积进行通道压缩,激活函数保证输出为正,第二个1∗1 卷积进行特征映射后,输入函数生成通道权值。输入特征张量各个通道与对应通道权值相乘即为重要特征通道突出后的特征张量。

图3 通道注意力模块Fig.3 Channel attention model
此外,改进模型将ASPP模块中的普通3∗3 卷积替换为深度可分离卷积(SeparableConv)。ASPP模块输出特征张量以Concat 方式拼接后,通道数变为1 280,改进模型通过两个1∗1 卷积减少通道压缩过程中的信息损失。DeepLabv3+改进模型整体结构示意如图4 所示。
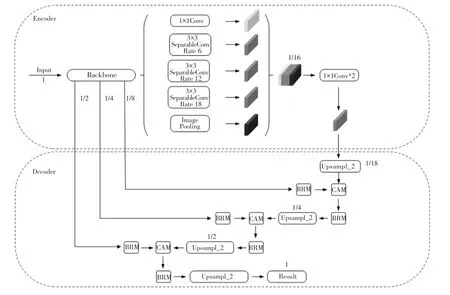
图4 DeepLabv3+改进模型网络结构Fig.4 Structure of the improved Deeplabv3 plus mode
3 实验结果与分析
3.1 实验环境
雾气图像分割模型实验环境基于Ubuntu 系统、PyTorch 框架以及Image 图像处理库等,具体的软硬件环境配置见表1。
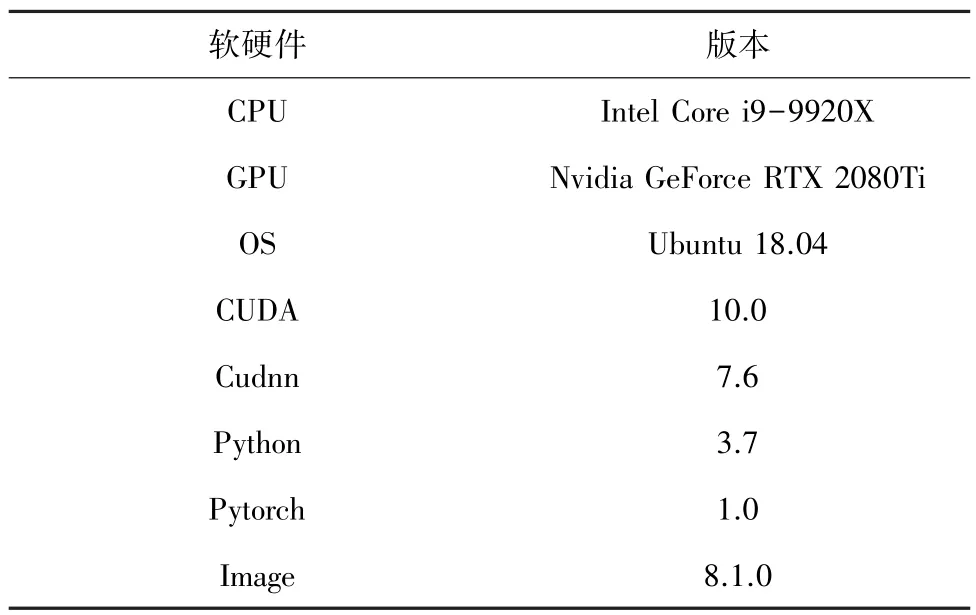
表1 软硬件环境配置Tab.1 Hardware and software environment configuration
3.2 数据集与预处理
由于目前尚未有公开的雾气图像分割数据集,所以改进模型实验数据集基于实拍制作而成。雾气图像采集装置见图5 中a 图,所用相机为大恒工业相机MER-132-30 GM,采集数据集中包含训练图像2 500 张,验证图像800 张。

图5 数据采集Fig.5 Data collection
通过工业相机拍摄得到的雾气原图如图5 中b图所示,图c 为通过传统阈值分割算法制作而成的标签图像。
为了使训练样本的形貌丰富多样化,避免模型过拟合并增强模型的泛化能力,实验使用到数据增强技术。其中包括随机缩放、随机裁剪、随机旋转、随机水平翻转、随机竖直翻转、及组合操作等。具体效果如图6 所示。此外,通过随机改变图像的亮度、对比度和饱和度,以模拟现实世界中光照亮度等变化。

图6 数据增强Fig.6 Data augmentation
3.3 实验结果对比分析
实验过程中的超参数设置见表2。
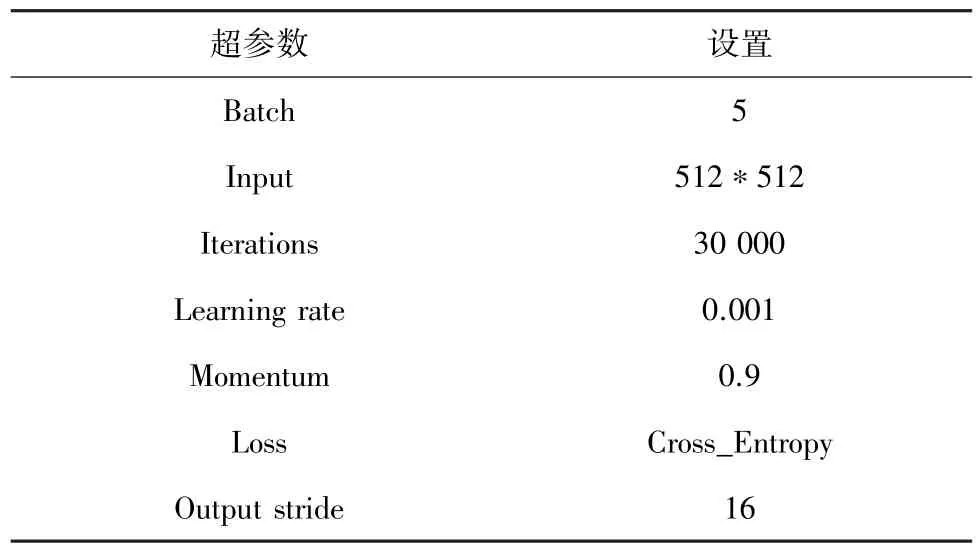
表2 超参数设置Tab.2 Super parameter setting
实验总共迭代30 000 次,训练过程中采用基于动量的随机梯度下降优化算法。其中,output-stride 等于16,学习率采用poly 策略,power 等于0.9,ASPP 空洞率设置为[6,12,18]。每隔10 次打印一次Loss,每隔100 次进行一次验证,验证过程中保存当前最优值模型作为测试模型。为了动态观察模型收敛情况及分割结果,通过Visdom 进行可视化展示。
常用的语义分割评价指标为:像素精度()、均像素精度()、均交并比()、频权交并比()。为了便于对比分析DeepLabv3+改进模型与DeepLabv3+基础模型及其它经典分割模型,评价时仅将作为分割结果评价指标。
针对Deeplabv3+基础模型,本文对其进行不同骨干网络的替换与不同阶段特征融合对比分析实验,实验结果见表3。其中,Backbone 表示骨干特征提取网络,Layer 表示进行特征融合时融合的特征张量分辨率大小。如Layer 等于4,代表只融合特征提取阶段储存的输入图像1/4 大小的特征张量;表示输入图像经骨干特征提取网络后,输出的特征张量通道数,也即ASPP模块输入通道数;为分割评价指标;表示模型所占内存大小;表示模型参数量;表示在CPU上运行单张图像所用时长。
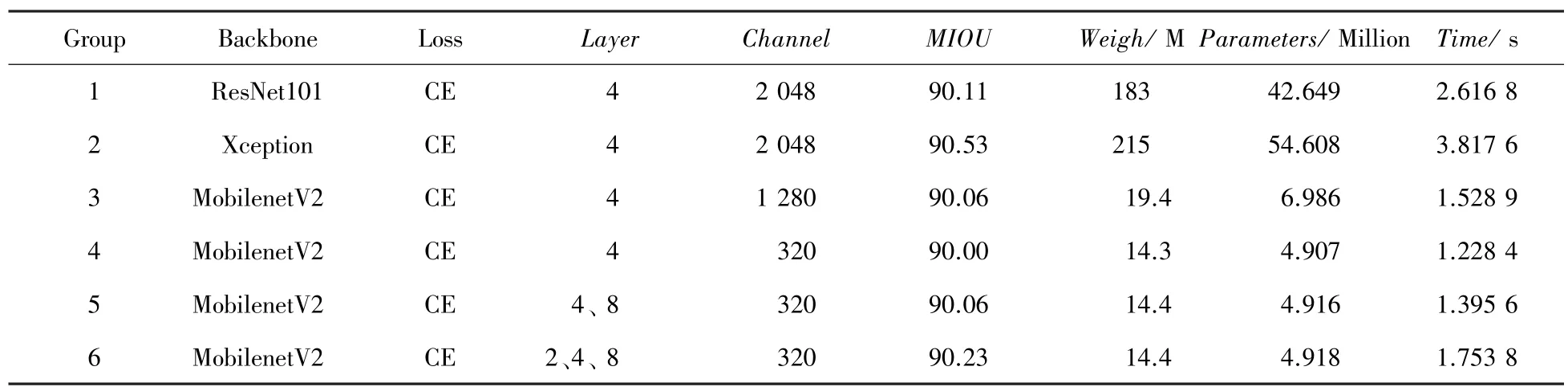
表3 不同骨干网络与特征融合的Deeplabv3+基础模型分割性能对比Tab.3 Comparison of the segmentation performance of the Deeplabv3 plus basic model with different backbone networks and feature fusion
表3 中,1、2 组实验为分别以ResNet101、Xception网络为骨干网络,且仅融合1/4 大小特征张量的DeepLabv3+基础模型进行分割实验。由结果可知,基础模型分割速度较慢,且权重参数文件对内存需求较高,很难布置在移动设备以及嵌入式设备中。
表3 中,3、4 组实验为分别以1 280、320 通道的MobileNetv2网络为backbone,且仅融合1/4 大小特征张量的DeepLabv3+模型进行对比分析实验。由分割结果可知,320 通道的MobileNetv2 其分割精度相比1 280 通道几乎没有变化,但模型参数量更少,单张图像耗时更少。
表3 中,4、5、6 组实验以320 通道的MobileNetv2网络为backbone,分别融合不同阶段特征张量的模型进行对比分析实验。从分割结果可知,融合层为2、4、8 时,值最高,分割边界最精细,从而验证了2.1 节提出的改进思想。
通过消融实验,验证了在改进模型中加入的边界细化模块(BRM)、通道注意力模块(CAM)的有效性,实验结果见表4。组别1、2、3 皆以320 通道的MobileNetv2 网络为backbone,融合层皆为2、4、8层,实验超参数设置保持一致。

表4 消融实验Tab.4 Ablation experiments
由表4 中1、2 组实验对比结果可知,改进模型中通道注意力通道模块(CAM)的引入,加强了模型对重点通道特征张量的学习,提高了信息利用率;2、3 组实验对比结果表明,边缘细化模块(BRM)的引入进一步细化了目标边界。最终采取的改进模型即为组别3。相比以 ResNet101 为 Backbone的Deeplabv3+基础网络(表3 中组别1),最终改进的Deeplabv3+网络不仅带来了精度上的提升,分割速度亦提高了57.26%,模型容量减少了92.62%,更易布置在移动设备以及嵌入式设备中。
改进模型的雾气图像分割结果如图7 所示。对于传统分割算法存在的分割凹陷问题(标签中椭圆部分),改进模型也能够较好的修补,且在较暗环境下也能得到良好的分割。

图7 改进模型分割结果可视化Fig.7 Improved model segmentation results visible
最后,将改进模型与当前一些比较流行的语义分割算法进行了比较分析,分析结果见表5。由此可见,本文提出的DeepLabv3+改进模型,在分割精度及分割速度上都做到了最好,并且本文改进模型权重所占内存要远远少于其它模型,更易布置在移动设备以及嵌入式设备。

表5 不同分割模型性能对比Tab.5 Comparison of performance of different segmentation models
4 结束语
雾气图像的精确分割对工业领域具有重要的研究意义,本文针对基础DeepLabv3+网络的不足之处,将原结构编码器的Backbone 替换为更轻量的Mobilenetv2 网络,将解码器的特征融合结构进行重新设计,同时加入注意力通道模块、边缘细化模块。实验结果表明,改进算法在分割精度带来提升的同时,分割速度亦大幅度提升,对于传统分割算法存在的分割凹陷问题也能够较好的修补,模型权重所占内存少使其更易布置在移动设备以及嵌入式设备,具有更大的工业应用价值。在后续研究中,将考虑利用深监督损失,进一步提升模型预测精度。
