预测工业经济的指标选择
2022-02-28曹秋雯王子杰
曹秋雯,王 凯,王子杰
(郑州大学数学与统计学院,河南 郑州 450001)
引言
工业经济对国民经济发展的重要作用不可替代。工业是全面建成小康社会和建设现代化强国的基础支撑;是推动经济持续健康发展的重要力量;是国际贸易与投资的关键支撑;是新技术与新模式创新的重要载体;是带动落后地区经济发展的重要动力。预测工业增加值可以帮助政府和企业提前制定策略以应对未来经济变化。
现如今,越来越多的学者利用各种模型对工业经济进行预测,例如吾彦军、邱斌、王占峰、严庆江探究了大数据技术在工业经济统计与预测中的应用[1];朱云英论述了统计指标和景气指数对工业经济预测的意义,其中企业景气指数对工业经济预测在建立模型预测工业增加值时具有信息可靠、前瞻性强、预测性强的特点,同时也说明了工业统计指标对于工业经济预测的重要性[2]。本文在先前学者论述的基础上创新性的从建立模型所需要选取的指标的角度来说明不同指标建立的BP神经网络模型在预测同一地区的工业增加值的准确性不同,相同指标建立的BP神经网络模型预测不同地区工业增加值的准确性不同;进而得出结论:预测不同地区的工业增加值时,不能用相同的指标建立的模型进行预测。
1 预测工业增加值相关因素的选取
1.1 地域的选取
根据统计局数据,河南省2020年的生产总值产业结构为:第一产业占比9.4%,第二产业占比41.6%,第三产业占比48.7%;黑龙江省2020年的生产总值产业结构为:第一产业占比25.1%,第二产业占比25.4%,第三产业占比49.5%;海南省2020年的生产总值产业结构为:第一产业占比20.5%,第二产业占比19.1%,第三产业占比60.4%[3]。河南省,黑龙江省和海南省的产业结构显著不同,为了说明选用相同的指标建立模型分别预测不同省份的工业增加值的准确性不同,选择这三个省份来进行建模分析。
1.2 指标及数据的选取
在预测工业增加值时,首先需要选取适当的指标。对影响工业增加值的指标进行分析,将影响工业增加值的指标分为自然因素指标和社会因素指标。自然因素主要指自然灾害、温度、气候等。大的自然灾害如火山喷发、地震等必然会对工业产生负影响,温度和气候的变化一定程度上会影响工业的投入成本。但是这些因素对工业增加值的影响是短期的,且这些指标难以量化,在预测工业增加值的具体数据的时候就会造成困难,因此在选择预测工业增加值的指标时不考虑自然因素。
影响工业增加值的社会因素有劳动力人口总数,规模以上企业个数、GDP、社会用电量,居民消费价格指数、税收、利润、社会用水量等。为了获取数据的方便,选择国家统计局或者地方统计局中已统计的指标。由于国家政策的改变,规模以上工业企业亏损企业单位数,规模以上工业企业主营业务收入,规模以上工业企业主营业成本,规模以上工业企业利息支出,规模以上工业企业营业利润等指标的数据在2018年之后不被国家统计局公布;而营业收入,营业成本,营业利润等指标在2018年之前没有被国家统计局公布;因此为了方便建模,选择2019—2021年的数据进行建模分析。在预测工业增加值时,首先要对选择的指标进行相关性分析,对于相关系数r;当>0.95时,显著性相关;当>=0.8时,高度相关;当0.5≤<0.8;中度相关;当0.3≤<0.5时,低度相关;当<0.3时,弱相关[4]。当相关系数大于0.5时认为两组数据之间的相关性较大。将统计局中各省份的指标与相应的工业增加值做相关性分析,指标与各省份工业增加值的相关系数如下页表1所示。

表1 指标与各省份工业增加值的相关系数[5]
2 工业增加值预测
使用BP神经网络模型,将2019年1月—2021年5月的数据作为训练集,2021年6—11月的数据作为测试集,以固定资产投资、发电量累计增长、社会消费品零售总额、规模以上综合能源消耗量和房地产累计投资增长五个指标的数据建立BP神经网络模型,预测河南省、黑龙江省和海南省的工业增加值;再以固定资产投资,营业收入累计增长,房地产投资累计增长,社会消费品零售总额,规模以上综合能源消耗量这五个指标建立BP神经网络模型二对黑龙江省工业增加值进行预测,以发电量累计增长、社会消费品零售总额、营业收入累计增长、营业利润累计增长和亏损企业亏损额累计增长这五个指标建立BP神经网络三对海南省的工业增加值进行预测。结果显示:模型一可以很好地预测河南省的工业增加值,预测黑龙江省的工业增加值时误差较大,预测海南省的工业增加值时误差特别大,无法显示预测结果;模型二预测黑龙江省的工业增加值的误差小于用模型一预测时的误差;模型三可与预测出海南省的工业增加值。
2.1 数据的来源与处理
以工业增加值累计增长值作为观测指标,以固定资产投资、发电量累计增长、社会消费品零售总额、规模以上综合能源消耗量、房地产累计投资增长、营业收入累计增长,营业利润累计增长和亏损企业亏损额累计增长作为建模指标;数据来源于国家统计局网站与地方统计局网站。各指标的累计增长值可以从统计局中得到,但是缺失一月份的数据,因而需要对数据进行处理;具体处理方法为:以当年2月—12月数据的平均值作为该指标的一月份数据,2021年为2月—11月数据的平均值作为一月份的数据。
2.2 BP神经网络模型的建立
人工神经网络(Artificial Neural Networks,简写为ANNs)是模拟人的形象思维建立起来的。神经网络的拓扑结构分为三层,即输入层、隐藏层、输出层。在BP神经网络提出之前很长一段时间里没有找到隐藏层的连接权值调整问题的有效算法,BP神经网络的提出解决了这一问题[6]。
BP神经网络属于传统神经网络,是一种求解权重w的算法。通常分为两步[7]:FP:信号正向传递(FP)求损失;BP:损失反向回传(BP)。
BP(Back Propagation)神经网络算法的学习过程主要由信号的正向传播和误差的反向传播两个过程组成。原始数据从输入层输入,经隐藏层处理以后,传向输出层。如果输出层的实际输出和期望输出不符合,就进入误差的反向传播阶段。误差反向传播是将输出误差以某种形式通过隐层向输入层反向传播,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,这个误差信号就作为修正个单元权值的依据。直到输出的误差满足一定条件或者迭代次数达到一定次数便停止迭代。BP神经网络的层与层之间为全连接,同一层之间没有连接,其结构模型如图1所示。
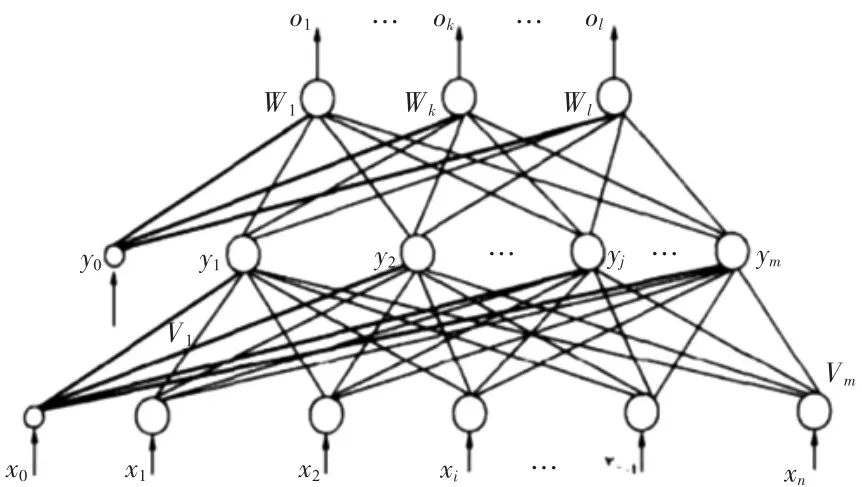
图1 BP神经网络结构模型
输入向量为x=(x1,x2,…,xn),其中图中x0为隐藏神经元引入阈值设置的;隐层输出向量为y=(y1,y2,…,yn),其中图中y0为输出神经元引入阈值设置的;最终输出向量为o=(o1,o2,…,ol),W1,…,Wk,…,Wl为隐藏层到输出层的权值。即输出层的输入是隐层的输出,隐层的输入是输入层的输出。
BP神经网络输入和输出层的节点数是固定的,不论是回归还是分类任务,选择合适的层数以及隐藏层节点数,在很大程度上都会影响神经网络的性能。在建立模型时设定的参数为:输入层节点数为5;输出层节点数为1;隐藏层节点数为7;最大训练次数为20 000;学习效率为0.001。
选取Sigmoid函数作为激活函数,交叉熵代价函数(Cross-Entropycost function)作为损失(代价)函数。将2019年1月—2021年5月的数据作为训练集,2021年6月—11月的数据作为测试集,建立BP神经网络模型。
2.3 BP神经网络模型的预测结果
基于固定资产投资,发电量累计增长值,房地产投资累计增长,社会消费品零售总额,规模以上综合能源消耗量这五个标建立模型一对工业增加值进行预测。各省份的绝对误差如下页表2所示。

表2 模型一预测各省份的工业增加值时的绝对值
用模型一与模型二预测黑龙江省的工业增加值的绝对误差,用模型一与模型三预测海南省的工业增加值的绝对误差如表3所示。
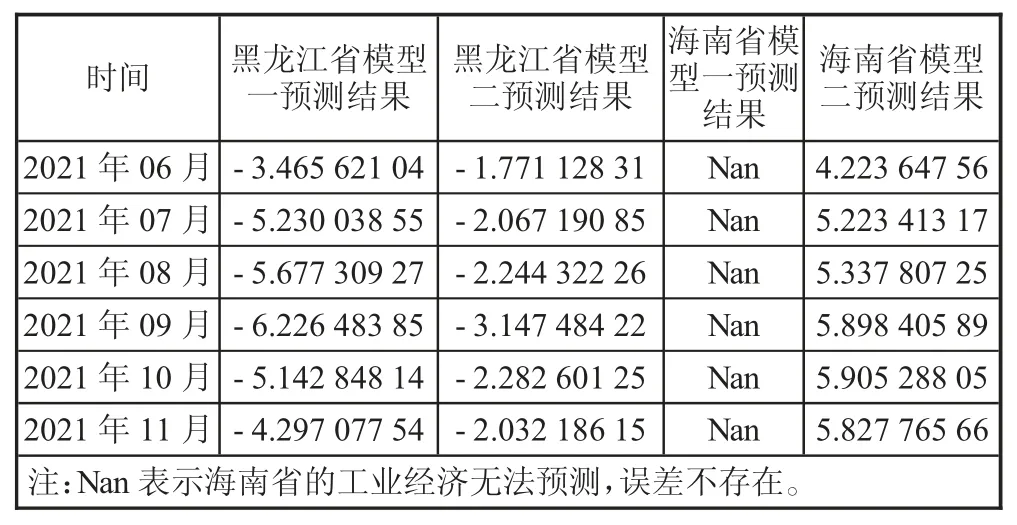
表3 黑龙江省和海南省分别两次建模的绝对误差
3 结论与启示
本文通过建立BP神经网络模型预测各省份的工业增加值;横向对比模型一分别预测河南省、黑龙江省和海南省的工业增加值的绝对误差,可以得出结论:同一模型在预测不同地区的工业增加值时,准确性不同。纵向对比模型一预测黑龙江省的工业增加值的绝对误差与模型二预测黑龙江省的工业增加值的绝对误差;模型一预测海南省的工业增加值的绝对误差与模型三预测海南省的工业增加值的绝对误差,得出结论:与工业增加值的相关性越大的指标建立的模型,对工业增加值的预测效果越好。
在当今信息化时代大背景下,预测未来经济发展,提前做好应对措施是所有国家,企业保证自身经济平稳发展的必要举措。本文浅显地论述了在预测工业经济时不同地区要建立不同的模型,以防止用同一个模型预测不同地区的工业经济时产生远偏离实际的结果,导致管理人员做出错误的决策。
