基于大数据的图书馆借阅量估计模型设计
2022-02-28冯玉平
徐 震,李 杨,冯玉平
(中国人民解放军战略支援部队信息工程大学,河南 郑州 450000)
1 图书馆借阅量估计模型设计
1.1 图书馆借阅大数据特征分析
图书馆借阅量的影响因素较多,数据的变化相对复杂,存在一定的周期性和混沌性,为此,本文以一年为周期,利用大数据对借阅数据特征进行分析。
本文对借阅特征的分析是建立在大数据的基础之上的,因此需要采集估计目标前一年的实际借阅数据。假设得到的样本数据中共包含n个数据,首先将其按照借阅资源的类目进行分类处理,此时的数据可以表示为
n={a1,a2,…,ai}
(1)
其中,a表示不同类目资源的借阅量,i表示类目总数,此时的借阅量实现初步划分。因此,要实现对不同因素作用强度的分析,才能根据新学期的入学人数信息估计出准确的借阅量。
本文将学生的专业、年龄以及性别作为影响因素,分析其在不同类目资源借阅量中的影响权重,得到不同影响因素在不同类目资源借阅量中的作用大小,以此作为估计模型的构建基础,实现对新周期内图书馆借阅量的准确估计。
1.2 构建图书馆借阅量估计模型
在得出不同因素对图书馆借阅量的影响作用基础上,构建的图书馆借阅量估计模型如图1所示。
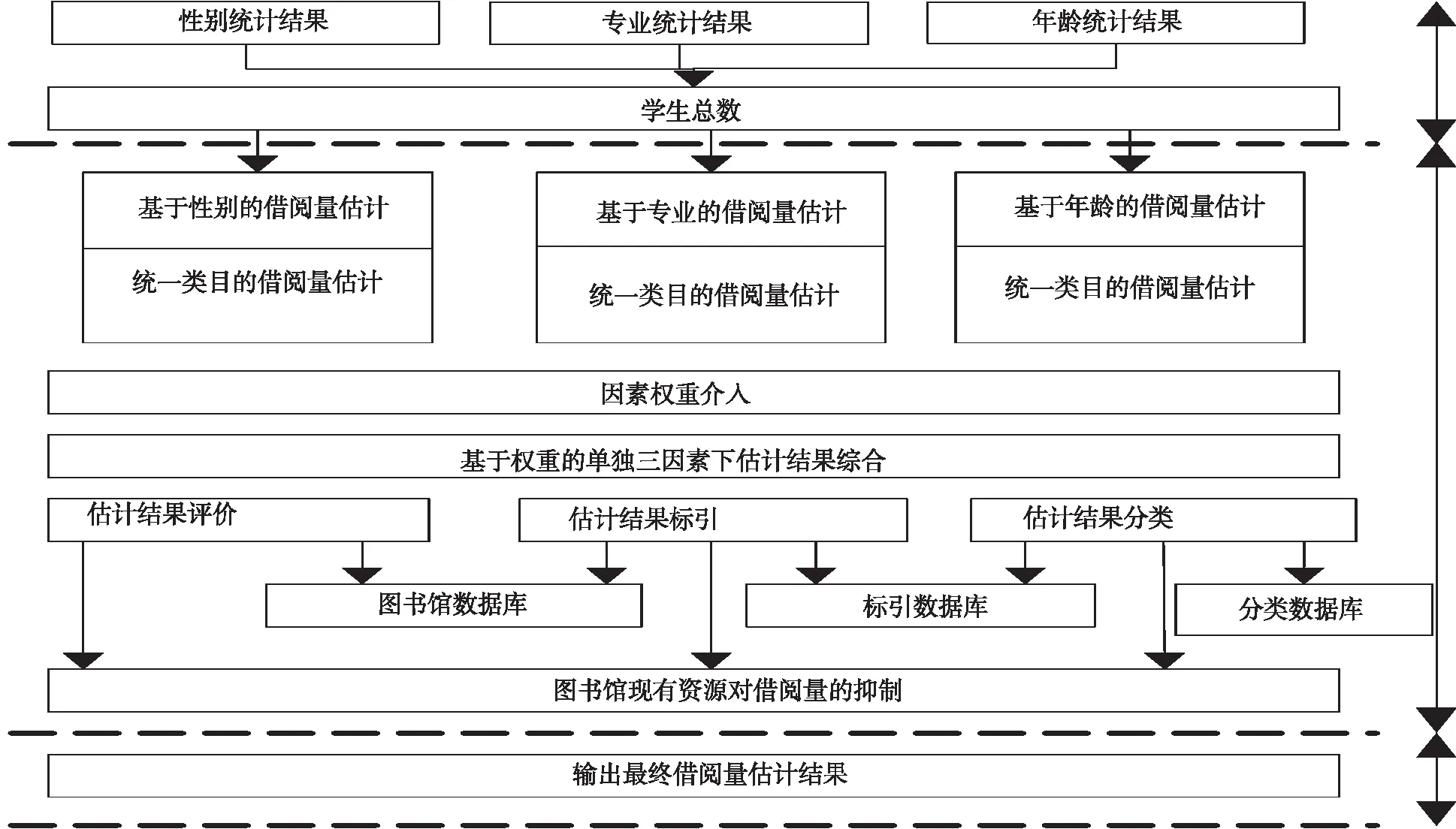
图1 图书馆借阅量估计模型
模型对最终借阅量的估计是以新周期内学生的数量为基础。首先将学生按照性别、专业以及年龄分别进行分类,统计不同类别的数量后,按照大数据特征分析得到的各自在借阅量中的影响权重初步计算出借阅量,图书馆资源的储备量低于实际借阅需求时,会对借阅量产生一定的抑制作用,因此,模型通过将估计结果与实际资源储备之间建立对应关系,得出抑制效果的大小,以此为基础实现对图书馆借阅量的准确估计。
2 试验测试
2.1 测试环境
以某高校图书馆作为实验对象,利用Microsoft Visual C++6.0软件实现对本文模型的编程。同时,为了提高估计结果评价的客观性,将文献[2]和文献[3]提出的估计方法作为对照组。
本文以高校借阅系统的实际数据为实验数据,调取图书馆某一年内的借阅量原始数据,其中包含借阅者姓名、年龄、性别、专业以及借阅书籍信息数据。将其作为样本数据,构建了估计模型,利用该模型估计样本数据下一年的借阅情况。为了简化多估计接轨评价的难度,本文将误差作为评价指标,计算方式为:
(2)
其中,d表示估计结果的误差,Xi表示i类目资源的实际借阅量,xi表示i类目资源的估计借阅量。以此为基础,分析统计不同方法的估计效果。
2.2 估计结果分析
在上述数据的基础上,分别采用3种方法对图书馆的借阅量进行估计,不同方法估计结果如表1所示。

表1 不同方法的估计结果 单位:%
从表1可看出,估计结果与实际之间的差异出现了明显的波动,最大值几乎达到500,并且在估计结果中出现了多个类目借阅量估计值低于实际借阅量的情况,这将直接影响学生的实际阅读需求,虽然在整体借阅量的估计上误差仅为-1.13%,但对那个类目的估计误差最大值达到了12.24%(综合);文献[3]方法对整体借阅量的估计误差也相对较低,仅为0.56%,通过观察单个类目的估计结果可发现,其稳定性较差,最大误差达到了13.42%(交通),最小误差仅为-0.41%(农业)。可看出估计结果并不理想。相比之下,本文方法的估计结果具有更高的可靠性,不仅整体误差仅为0.55%,单个类目的估计误差最高值也仅为2.82%,表明本文设计的估计模型可实现对图书馆借阅量的精准估计。
3 结语
图书馆资源管理工作作为一项重要的工作,既要对书籍资料的采购方向进行合理控制,又要对不同类型资料的储备量作出合理规划,这些都需要以实际的图书借阅需求为参考。本文设计了一种基于大数据的图书馆借阅量估计模型,实现了对图书借阅需求的高精度预测,为图书馆的资源管理工作提供了重要的数据指导。
