基于大数据的平安城市智能运维平台设计与实施
2022-02-28蔡其波王晴筠李植达陈嵩荣陈光淙
蔡其波 王晴筠 李植达 陈嵩荣 陈光淙
1. 福建省泉州市公安局 2. 福建省南威软件股份公司
引言
泉州市城市安全信息系统为泉州市的平安城市项目,2012年以来连续9年“市政府为民办实事”项目,建设内容包括公共安全视频监控、道路交通电子卡口、治安RX卡口、无线感知、计算平台、存储系统、网络系统、安全系统等设施设备及软件系统,项目建设周期长,投资大,所建软硬设备数量庞大,系统复杂,运维难度高。为提高系统稳定性,保障系统在社会治安防控、侦察破案、维护社会安定、服务群众工作中持续高效发挥作用,提出运维工作全面信息化,引入大数据智能化技术,精心设计建设了智能化运维管理平台,并围绕平台制定严谨运维工作制度,推行严格考评机制,强化运维督促制度,平台上线运行以来取得了良好成效。
一、存在问题
在平安城市、雪亮工程的运维中普遍存在一些难题,制约了运维的成效,主要有:
(一)资产种类多、数量大、变化频,发现问题难度大
随着前端感知技术的不断发展和相关平台的建设,拥有资产种类和数量,包括服务器、存储、网络设备、机房设施、前端感知设备等硬件资产和操作系统、数据库、中间件、应用业务系统以及系统产生的数据等资产越来越庞大;同时随着城市化进程难免存在因城市建设等原因导致资产变动,资产纷繁复杂加上频繁变动导致资产的巡查工作相当困难,及时发现问题更是难上加难。
(二)点多面广,环境复杂,运维难度大
城市安全信息系统的前端感知设备大部分在户外工作,往往工作环境恶劣,比理想环境中故障率高出许多倍;同时在系统中信息传输链路长,环节多,子系统间联系复杂,一旦出现问题,往往难以迅速准确定位故障点。
(三)传统信息沟通方式不能满足运维工作要求
一个故障需要多个不同部门技术人员共同协作,传统的通信手段难以迅速完成全面准确的信息交互,信息遗漏往往导致故障没能全面彻底解决。
(四)安全性、保密性、可靠性要求高,也为运维工作带来更高要求
城市安全信息系统故障响应和维修处理时间需要符合GA 308、GA/T 367、GA 669.8、GA/T 792等国家标准。同时城市安全信息系统构建在公安视频专网上,全国性网络互联互通的特殊性和传输内容的敏感性均要求网络较高安全,确保运维中的信息安全是一项复杂的工程,也为运维工作提出更高要求。
二、方案设计
构建一个高可靠的智能运维平台,以运行监测和故障告警两个方面为重点,将所有业务系统中所涉及的网络资源、硬件资源、软件资源、数据资源等纳入统一的运维监控中,并通过消除采集软件和采集手段差别,对各种不同的数据来源实现统一管理、统一处理,最终实现运维规范化、自动化、智能化的大运维管理,为工作团队提供一个看得见、理得清、查得准的综合运维平台。
基于信息技术基础架构库(ITIL,Information Technology Infrastructure Library)体系,运维平台以统一资产管理为基础,精细监控监测管理、统一告警管理、统一运维服务为主体,辅以统一运维机制为确保运维工作高效稳妥。
(一)统一资产管理
通过实时动态监测,资产管理实现从资产入库、安装调试、运行、维修到变更、报废的全生命周期管理,资产管理透明化、精细化、动态化。平台提供覆盖各种服务器、存储设备、网络设备、安全设备、数据库和中间件、业务系统等IT资源和包括摄像机、电子卡口、电子警察、RX卡口、RFID、电围设备等前端感知设备关键指标的统一管理,奠定统一运维平台的基础。
(二)精细监测管理
运维平台的核心工作之一是运行监控。运维平台对纳入资产管理的所有设备进行运行监控管理,支持SNMP、CLI(Telnet、SSH)、WMITELNET、SSH、ICMP、JDBC、ODBC、JMX及私有协议等方式,进行不间断监控服务。同时,周期性通过机器加人工复核的方式,对监测机制进行调优,确保监测准确性。
(三)统一告(预)警管理
故障告警或临界预警是故障处理的第一步,通过数据抽取模块从数据收集服务器获取需要的数据进行分析并实现实时告警,告警方式支持客户端告警、短信告警、邮件告警、App告警等,以最快的方式通知相关人员进行处理。APP和客户端还能够快速、清晰、高效流转工单信息,反馈工作结果,具备团队间协作必要的通信功能。
(四)统一运维服务
定义了包括事件管理、问题管理、配置管理、变更管理、服务级别管理、作业计划、知识库等在内的服务管理流程,通过各流程环节的工单形成运维服务的闭环管理,利用系统将人员、流程、技术和信息有机地结合起来,提高运行维护的有效性。
(五)统一运维机制
根据公安工作实际配套建立三级(市级、县级、派出所级)分级运维管理机构,同步建立资产管理、日常巡检、故障响应、安全管理、人员培训、绩效考核等一系列完善的运维管理制度,将管理、服务、考核在系统里有机结合,使运维工作制度化、规范化、精细化。
(六)统一安全标准
运维工作中严格要求按照有关规范进行操作,尤其是信息安全方面,建立完善安全监测手段,及时发现并阻止非法设备和违规网络联接,加强网络及视频图像信息应用的动态审计监督和管理,实行行为日志审计,保障安全事件可追溯、可查证,实现可管可控。
三、平台架构和实施
智能运维管理平台基于大数据的计算和存储能力以及ITIL的最佳实践经验,将复杂的运维管理工作变得简单化、可视化、规范化和自动化(部分),有效提升服务效率和效果。平台的架构设计如图1所示。
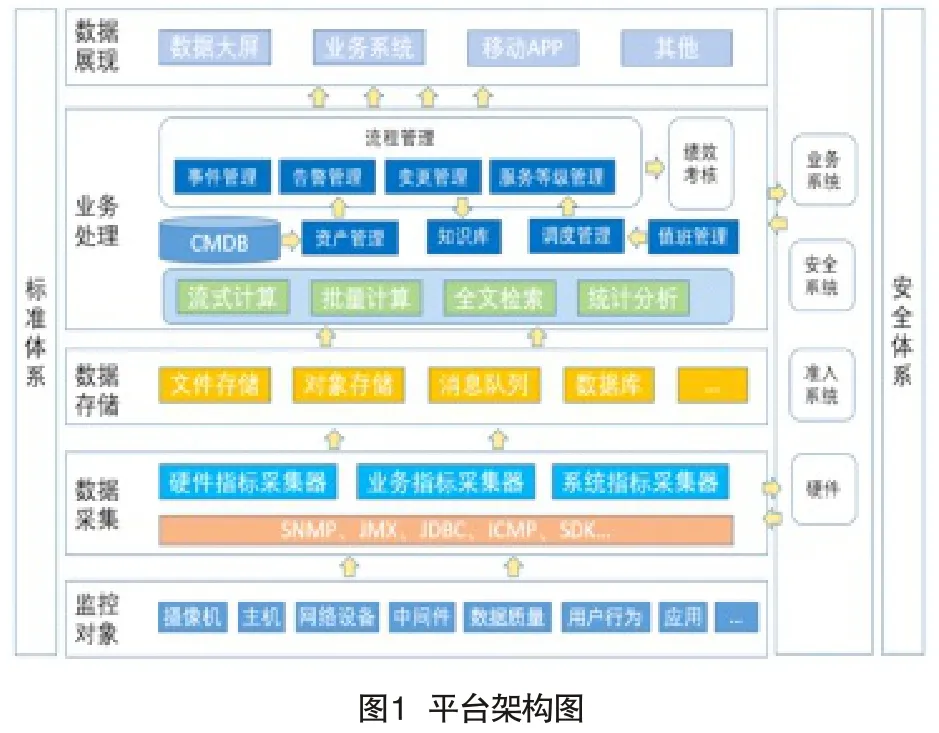
(一)监控对象
监控对象,大致可以分为四大类:业务应用、中间件、基础设施和数据。业务应用主要包括应用软件、业务系统等。中间件包括数据库、缓存、消息队列、Web容器等。基础设施又可以分成前端感知设备和后端IT设备。前端感知设备主要包括摄像机(包括车辆卡口、RX卡口等)、无线终端、电围设备、智能箱等;后端IT设备主要包括物理机、虚拟机、网络设备、安全设备、存储设备等。数据主要有用户使用情况和数据质量。主要资产监测指标如下:
网络设备:运行时间、通信状态、CPU负载、MEM利用率、线路流量、帧流量等指标。
服务器:CPU性能指标、内存使用情况、硬盘、网口状态及流量、操作系统(Windows、HP Unix、Aix、Solaris、Linux)的系统状态、主进程、系统告警情况等。
存储设备:设备运行状态、网络连通性、磁盘运行状态、控制器状态、存储总空间、空闲及占用情况等。
摄像设备:摄像头的运行状态、网络连通性及视频图像质量、录像完整性等。
数据库:运行状态、连接数、并发数、数据库日志、缓存情况、索引信息、库缓存情况、监听器工作情况、进程数、会话、实例性能信息、SQL语句执行状况、日志和表空间使用率等指标。
中间件:运行状态、队列信息、线程信息、事务信息、连接池状态、连接数量、最大连接数量、Session数等指标。
应用系统:应用状态、进程状态、进程占用资源情况、最大时延、最小时延、端口状态等指标。
感知设备:服务运行状态、端到端响应时间、业务/应用所关联的资源对象的性能等。
数据质量:抓拍图像清晰完好情况、识别准确率、8秒数据入库率、倒挂率、数据及时上传上级部门情况等。
用户使用情况:使用记录、故障报告、用户反馈、使用中的系统异常报告、系统反应时间等。
(二)数据采集
数据采集,主要负责检测以及收集各种监控对象的监控指标数据,然后将收集到的数据进行规范化,并进行存储。由于监控对象种类繁多,各类数据的采集方式也不尽相同,主要的采集方式包括:SDK接口采集、客户端采集、通过网络协议(http/snmp/jmx)主动抓取等。
(三)数据存储
根据不同的数据特点以及业务的需要,采集到的数据分别存储到文件系统(HDFS)、对象存储(Fastdfs)、指标库(Influxdb),建立索引系统(Elasticsearch)、消息队列(Kafka),为后续大数据分析以及业务处理做好准备。
(四)业务处理
业务处理是系统架构中体现核心价值的部分。其关注点主要集中在业务规则的制定、业务流程的实现等与业务需求有关的设计,是运维管理平台所使用的各种业务逻辑,集中管理和协调各子系统之间的服务调用。业务处理主要有资产管理、监测配置、运维服务、数据分析等核心业务。
资产管理:结合日常监测,把资产管理由被动管理转为主动管理,从多个维度管理资产,将极大提高资产管理效率,实现资产全生命周期的数字化、无纸化。
监测配置:通过CMDB(配置管理库)识别、控制、维护与检查资产,保障资产数据的准确与安全,实现更好的资产决策,优化资产生命周期投资以提供更好的服务。
运维服务:解决资产运行过程中已发生的和潜在的问题,通过调查和分析基础构架的薄弱环节,查明事故原因,由此制定解决方案和防止事故再次发生的具体措施。
数据分析:针对不同类型设备设施设计不同的模型,既分析其量值又分析其变化情况,既分析其个体又分析同类资源情况还分析其“上下游”关联设备情况、系统总体情况。分析结果一方面以“界定、测量、分析、改进、控制”管理规范为指导,以改进为目标,在测量的基础上对数据统计、分析,为总体工作上改进、控制提供依据。另一方面分析人员、团队、区域保障资产设备稳定运行的工作情况,为建立科学运维绩效考核体系提供数据。
(五)数据展现
展示层负责处理所有的界面展示以及交互逻辑,是用户和系统之间交流的桥梁,一方面为用户提供了交互的工具,另一方面也为显示和提交数据实现了一定的逻辑,以便协调用户和系统的操作。实现多维度分析报表、巡检报表、多种格式报表导出。
四、主要功能应用
(一)规范的自动化运维流程
平台工单主要采用自动派发方式,并根据实际灵活保留手动创建派发工单的方式。工单类型包含故障工单、应急工单、巡检工单、其他工单,涉及工单处理角色包含监理、业主(分级)、运维人员(分域)、运营商(电信或电力)4种角色。

运维平台以集群运行,避免单点故障,各资产均实现24小时的监测,一旦获取到故障信息或超过告警阈值,均会自动告警并派发工单至相关负责人员。工单负责人员接收后,工单将开始处理时间统计,按照不同工单等级,运维人员应在规定时间内完成工单处理。
在排查过程中,故障一般分为3种情况:一是由于运营商网络连通故障,二是由于第三方不可抗力因素(如修路、停电等),三是由于设备自身故障等。针对3类故障情况,对应进行转发、挂起、修复等操作,通过平台快速反馈现场排查情况。除了线上自动派单,为配合线下巡检工单机制,设定自查告警,在周期性巡检中发现的问题及时派发工单。
(二)精准告(预)警
运维监控平台通过配置阈值,达到阈值后自动触发,生成告警信息,平台对信息进行压缩合并与降噪处理。一是降噪,在指定时间内容自动去重,并消除不重要的事件,识别重要关键信息,避免告警疲劳。二是聚类,将相关的事件分门别类聚合起来,抑制告警风暴。三是根因识别,基于故障模式及关联消息的持续自我学习,进行自主机器学习后,识别告警的根本原因进行告警。通过以上方法到达运维人员的告警信息基本上是有效信息。
(三)绩效考核
结合责、权、利三个方面建立运维服务考核与激励机制,做到工作质量与绩效挂钩,根据平台客观统计数据结合复核结果做到精准考核、奖惩有度,建立起科学规范、系统全面的运维绩效管理体系,有效调动运维组员工劳动积极性,提高执行力,保障维护工作的持续稳定运行,打造优质的运维服务质量。
(四)基于知识库的智慧运维
知识库是一个解决方案的汇总,日常运维故障典型解决方案的总结、积累,相关小组组织研究运维事件发生的原因和特点,分析事件发展过程,总结处理过程中的经验和教训,进行知识积累,进一步补充、完善和修订相关应急预案记录知识库。经过沉淀,针对各种资产设备故障现象以及面对突发事件,知识库均能提供行之有效的解决方案,能够自动推送解决方案发给问题解决人员以供工作参考。部分故障情形下可根据情况对服务器进程、智能化前端进行远程重启、复位,实现自动快速运维。
五、初步成效
目前接入前端设备包括摄像机、无线终端监控、电围设备监控、智能箱监控等,监控数量超过7万个;后端设备包括服务器、虚拟机、安全设备、中间件、Web应用等,数量超过5千个。每日产生的监控数据超过1000万条,每日产生预(告)警信息约2500个,触发有效工单约1000个。原来设备依靠人工巡检,周期需要两三个月,现在前端设备每半小时巡检一次,后端设备每日至少一次或多次检测。以某日情况为例,各地设备在线率、视频图像完好率普遍在99.5%以上,其中核心(重要)点位设备大部分地方长时间保持100%在线,磁盘完好率99%,录像完整性96%,所有软件故障总时间由原来300小时以上降低到不到1小时,运维效率稳步提高。
六、结语
本文针对平安城市项目运维难点问题,提出通过构建平台进行实时监控,随时掌握各个资源的运行状态,通过大数据分析后及时预警或告警,甚至自动修复,为尽快解决问题提供条件,并为领导决策、团队管理、建立经验、完善工作流程等提供依据,最终实现持续提升运维和建设水平。
在运维平台指导下,运维团队整合资源,明确分工,积极作为,确保质效,形成统一管理、集约高效的一体化运维服务质量保障体系,从而保障城市安全信息系统安全、稳定、高效、持续的运行。
