垂直型人员亲属关系数据结构研究与大数据建模实践
2022-02-28肖啸广东省惠州市公安局
肖啸 广东省惠州市公安局
引言
2020年10月,央视报道了某地的陈先生在国务院“互联网+督导”平台上反映自己历时7个多月证明“我爸是我爸”未果的问题。近年来,此类问题屡见不鲜,事情曝光后,群众在不了解事情真相前,往往首先是质疑政府的执行力,而公安机关又首当其冲。虽然最后通过各方面努力问题都得到了解决,但不难看出,各地的做法实为特事特办,全国并没有形成一套有效的、制度化的证明体系。
亲属关系主要产生于生育和婚嫁。传统的纸质族谱较好的体现了本族内的亲属关系,近几年互联网上也兴起了一些编撰电子族谱的网站,用于帮助人们寻根认祖,但无论是哪种,其建立的方法和标准并不统一[1],关系人也有极大的局限性。可以想见,如果由政府职能部门统一建立全国性的人口亲属关系大数据平台,将具有广泛的应用场景和社会意义。
一、需求分析
根据民政部等六部门《关于改进和规范基层群众性自治组织出具证明工作的指导意见》,亲属关系的证明不再属于基层群众性组织工作职责。因此,一些最基础的证据材料全压在公安机关肩上,这也是近年来公安工作的难点和痛点。我国基层公安组织一般始建于上世纪五十年代后期,然后逐步开始建立人事户籍档案,且至今仍主要采用纸质档案方式保存,原始的户籍档案缺失、模糊、遗漏情况也无法避免。随着我国信息化水平的普遍提升,各类业务系统已逐步实现了数据的电子化,但如何利用现有的业务数据构建出全面、高效的人员亲属关系网络,仍是一大难题。
当前,对人员亲属关系的研究主要集中在三个方面,一是“族谱”或“家谱”的展示,如刘军丹提出的家谱关系的元图表示[2];二是关系网络的查询算法,如闫绍惠的关系追溯算法[3]和 张霞的特定家庭结构匹配方法[4];三是数据存储的优化,如采用Neo4j图数据库和HDFS列式数据库[5]等。但一直以来对其数据结构的研究并没有较大进展,主要原因是各类法律活动产生的亲属关系极大复杂了关系网络。要涵盖所有亲属关系且结构简洁易检索,亟需在亲属关系的数据结构上破冰。
二、数据结构详细设计
本部分说明了垂直型亲属关系数据结构的产生、优化过程及验证结论,介绍了建设全国性的人口亲属关系大数据步骤。
(一)垂直型关系及其数据结构的产生
1. 传统型关系及其数据结构
以一家四代人关系为例,传统的亲属关系结构如图1所示。

图1中,实心圆代表男性,空心圆代表女性,平辈如夫妻或兄弟姐妹间用实心箭头连接,上、下辈间用空心箭头连接(下同)。在不考虑死亡、离婚等情况下,一家四代人关系网络已较为复杂。现在随机选择关系较远的二人建立最短链接,如图2所示。

图2中,以两个红色圆建立关系链为例,从红色线路所示可以看出,起、止之间最少有3个关系人,最小正确链路为4级,最大正确链路为10级。传统型关系结构存在以下问题:(1)由于每个人的关系设定是多维的,即父母、子女、兄弟姐妹等,每多一名子女或兄弟姐妹就多一维,可能的链路数呈几何级增长;(2)从左右下角四个人的关系可以发现,关系链存在大量无限循环情况,这对于机器遍历算法设计是极大的挑战。
在实际建模时,传统型关系的数据结构如表1所示。

?
从表1中可以发现,传统型关系的数据结构存在以下问题:(1)如考虑离婚,将会出现张三父母、妻子数量不可控情况或者出现新数据覆盖旧数据从而断裂旧关系指向情况;(2)数据冗余极大,每个兄弟姐妹之间均会形成相互指向。
2. 垂直型关系及其数据结构(原型)
针对传统型关系结构和其数据结构存在的问题,设计新的关系结构和其数据结构至少需要满足以下三点:(1)原关系人和关系不可缺少;(2)减少链路数,消除无限循环风险;(3)尽量减少无法预知的数据,减少数据冗余。新关系结构如图3所示。
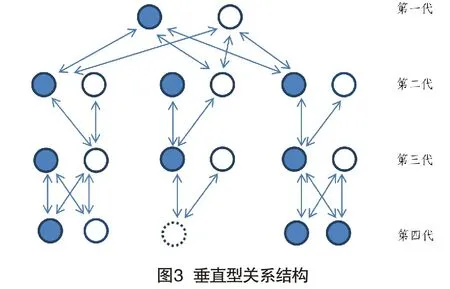
在图3中,新结构删除了所有横向关系指向,每个人只有上、下(父母和子女)关系指向,因此命名为:垂直型关系结构。图3中第四代中间有一个虚线的圆,这是垂直型关系结构中提出的一个关键名词——虚拟子女,即对任何一个人,只要结婚,即在其下辈中产生一个虚拟子女,虚拟子女由且仅由实际子女替代,否则一直存续,其主要作用是标注每次产生的夫妻关系。
下面分四种典型情况描述垂直型关系的数据结构(原型),如表2~表5所示。
(1)情况1:未婚。

?
(2)情况2:已婚(或离异),未生育。

?
(3)情况3:已婚(或离异),有生育。

?
(4)情况4:无生育再婚。

?
3. 合法性检测及结构改进
原型的数据结构仅能机械的登记每条数据,无法对数据的合法性进行检测。现假设某人有多条婚育记录,如图4所示。

在图4中,张三有两条婚姻关系李三和王三,并分别有子女张四-1和张四-2。若直接将两条数据进行合并,张三子女指向张四-1和张四-2,数据符合标注格式,但数据是否合法却需通过分析张三的婚姻状态和产生当前状态的时间来确定,数据格式趋向复杂,因此须对数据结构原型进行适当改进。
因垂直型关系结构中取消了夫妻关系指向,双方通过子女进行关联,则在数据结构中用子女标注父母状态,分为:已婚、离异、丧父、丧母、双丧五个状态(如果虚拟子女不可被实际子女替代,可直接由虚拟子女标注父母状态和产生状态的时间,结构更简洁,但考虑到现有婚姻登记数远小于实际夫妻关系数,笔者认为当前保留父母状态属性更为恰当)。
张三和李三的婚姻状态由其子女张四-1来标注,如表6所示。

?
张三和王三的婚姻状态由其子女张四-2来标注,如表7所示。

?
在改进后的数据结构下进行数据合并时,通过检测张三两个子女对应的父母状态即可判断数据的合法性。
改进后完整的数据结构如表8所示。

?
(二)垂直型关系及其数据结构的验证
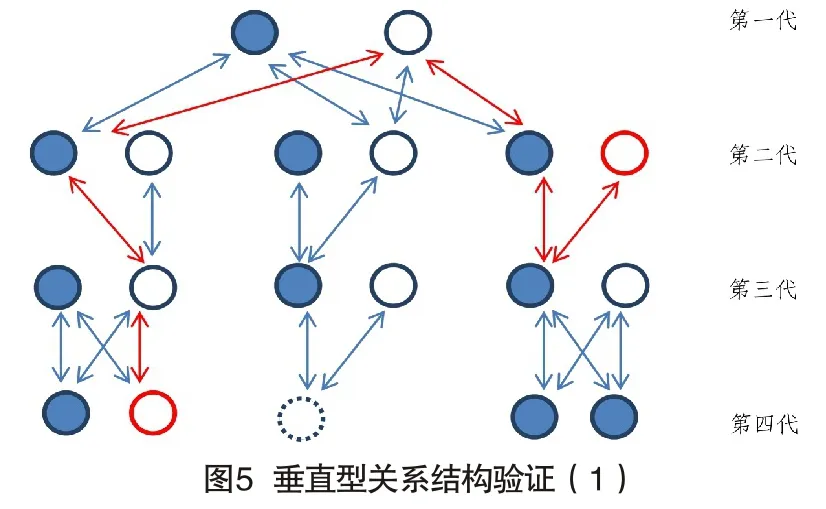
1. 关系人和关系网验证
图5中,仍选择之前示例的两个关系人,如红色圆所示,现在最短路径增加为6级,中间关系人增加到5个,但两人之间仍然可以建立链接。
2. 减少链路条数验证
图6分别截取了传统关系结构和垂直关系结构左下角四个关系人的关系网,从左图中可以看出,如果建立从第二行红色圆到第一行绿色圆的链接,可以有:1级链路1条、2级链路2条、3级链路2条;而右图中建立同样的链接,则为:1级链路1条、3级链路1条。相比较,新的关系网极大减少了可能链路的产生,并消除了无限循环风险。
3. 减少数据冗余验证
传统型数据结构中,数据的冗余主要来自两个部分:(1)兄弟姐妹之间的互相指向;(2)夫妻双方及其主要亲属关系间的重复指向。
垂直型数据结构中,每个人只需要指向父母和子女,不需要考虑家庭中其他成员,从而有效消除了数据冗余。
4. 其他优势验证
垂直型关系结构最大的优势是引入了虚拟子女概念。传统结构中,关系链建立在真实的人物和关系上,现假设有两人结婚后未生育离婚,两人夫妻关系链随即断裂,而即使有生育,此时虽仍可通过子女建立关系,但如果一方再婚,无论子女指向亲生父母还是继父母均会存在关系缺失。引入虚拟子女后,实际子女和虚拟子女永远指向其真实父母,确保了父母数量唯一,且父母与子女间的指向不会产生数据冲突,同时无论父母再经历多少次离婚和再婚,子女均可以通过父(母)一方的新子女(或新虚拟子女)转而指向继母(父),关系结构保持完整。
(三)全国人口亲属关系大数据建设
本部分将从建设粒度和建设步骤两个方面阐述全国人口亲属关系大数据建设。
1. 建设粒度
建设粒度是指建立关系网的最小范围,在此基础上对每个颗粒进行互联以形成全国的关系网络,粒度的选择应当遵循易建设、便管理、高实用的原则。分析建立粒度大小的利弊,笔者认为以省级行政单位为主体,选择若干中心城市、中心地区采取独立建设、优先建设的策略较为合适。搭建全国关系网络时各数据中心采用区块链技术实现实时更新和备份。
2. 建设步骤
(1)建立中心库
在各省级行政单位和部分中心城市政府的大数据中心建立数据库,并导入辖区人口户籍数据、出生和死亡数据、婚姻登记数据、人口普查数据等作为原始库。
(2)初始标注
初始标注分为两个部分,第一部分是户籍标注,第二部分是其他数据补正。
户籍标注:从人口数据中按年龄进行排序(无论是否已身故),以年龄从大到小进行标注,根据户籍信息和人口普查数据分别标注其父母、子女信息形成关系库Ⅰ。
其他数据补正:①死亡数据补充关系库Ⅰ,对已死亡的人员修改其子女对应的父母状态为“死亡”;②婚姻登记数据查找结婚双方名下是否有共同的子女指向,如无则修改双方子女指向“虚拟子女”;③出生数据补充关系库Ⅰ,将已进行户籍登记的出生人员加入关系库Ⅰ,设定其父母指向,并修改其父母的子女指向。经过数据纠正后,形成关系库Ⅱ。

(3)自主标注
完成系统标注后,对社会开放自助填报接口,由群众自主申报,结合本次人口普查数据进行人工核对校验,查漏补缺,形成关系库Ⅲ。
(4)数据合法性验证
对同一人涉及多条婚育关系的数据进行合法性验证,合并合法数据,不合法数据则发送核查报警给数据源单位。
(5)数据更新与区域互联
传统的数据更新与数据共享机制一般是设定一个固定频率由单个中心库向其他库发送更新数据,根据本数据的应用场景,采用每日更新一次即可。随着区块链技术的成熟和发展,如采用区块链将原有各中心库进行链接,则更能保证数据的鲜活和可靠,也是数据的更可信备份。
三、建模实践
本部分将介绍笔者在某地市级公安大数据平台的建模过程,考虑保密原则,只展示了主要步骤的处理逻辑,对列举的数据也进行了处理。
(一)建模过程
1. 数据清理
将原常住人口信息表中“与户主关系”栏的“长子”“次子”等及“长女”“次女”等修改为“子女”;将原常住人口信息表数据按出生日期由小到大排列(年龄由大到小)。清理后的表命名为“过程表”。
2. 创建新表,并命名为“结果表”
数据格式如表9所示。

?
3. 逐一抽取过程表中数据,并按以下规则填入表9中
(1)将当前数据的身份证号码填入表9;
(2)如数据中父亲或母亲身份证号码不为空,则将父亲或母亲身份证号码分别填入表9的对应栏;
(3)分别检测父母数据是否已在表9,如不在则新增数据,修改其子女栏数据;
(4)检测当前数据中“与户主关系”字段:如为“父亲”或“母亲”,则在“过程表”找到当前数据同户号的户主身份信息,并将信息加入当前数据的子女栏;如为“子女”,则与上同样操作并根据户主性别分别将信息加入当前数据的父亲或母亲栏;如为“户主”,则与上同样操作并将关系为“父亲”“母亲”“子女”身份信息加入对应栏。
4. 逐一抽取结婚登记信息表中数据,并按以下规则填入表9中
(1)分别检查“男公民身份证号”和“女公民身份证号”是否已在表9的数据中,如不在则新增数据,新增其子女栏一条虚拟子女数据,虚拟子女格式为:&男身份证号&女身份证号&结婚日期;
(2)判断男公民子女和女公民子女除虚拟子女外是否有交集,如有则删除虚拟子女。
5. 逐一抽取出生登记信息表中有身份证号码的数据,并按以下规则填入表9中
(1)检查本身份证号码是否已在表9的数据中,如不在则新增数据,并填入其父亲、母亲信息;
(2)检查其父亲、母亲的子女栏数据中是否已包含本身份证号码,如未包含则修改其子女栏数据。
6. 导入人口普查数据、离婚登记数据、死亡注销数据等,完善表9
完成上述步骤后,表9中数据情况如表10(示例)所示。

?
(二)实践情况
目前,模型已基本完成笔者所在地市中2个区的数据处理。以惠*区为例,共标注人口数据473717条,其中年龄最大的为1901年出生的叶某,年龄最小的为2021年10月7日出生的黄某(此数据截至投稿时为止),模型结果已共享给多个部门直接使用或其他模型调用。
建模过程中,最大难点是现有业务数据的不完整和不规范。以惠*区的常住人口信息表为例,有登记父亲或母亲信息的数据仅为134175条和136592条。另外,同一户号存在多个户主、与户主关系统一表述为“侄女”“侄子”等情况也较为常见,这类数据需要编写大量的判断逻辑处理。可喜的是,笔者发现数据越新业务库数据也越规范,同时,业务库中一些旧数据也在不断趋于完善。
四、结语与展望
人口亲属关系网的建立具有广泛的民事和执法活动应用场景,其数据也是我国姓氏、家庭关系变迁的数字体现。从政府层面来看可以为制定人口及衍生的经济、教育、医疗等相关政策提供参考依据,从社会层面来看,数据也是一个全国版的“族谱”,不仅为各姓氏、家族提供了科学规范的族谱登记,也契合中国人传统的“认祖归宗”思想。
虽然,目前实现的两个区人员亲属关系模型只进行了部分业务系统数据的标注,但已初显成效,工作中发现的诸多“疑点”数据,如空挂户、非法定投靠、频繁结离婚等,均已纳入当地重点管控对象管理。笔者相信,随着本次人口普查的进行和人口登记的不断规范,特别是政府职能部门间数据共享机制的进一步完善,从各地分散建设人员亲属关系模型到建成全国性的人口亲属关系大数据网将指日可待,其价值也更能得以体现。
