基于FPGA的SqueezeNet推断加速器设计
2022-02-28储萍,倪伟
储 萍,倪 伟
(合肥工业大学 电子科学与应用物理学院,安徽 合肥 230009)
近几年深度神经网络算法在计算机视觉、自然语言处理、语音识别等领域得到广泛应用。VGG16、GoogLeNet和ResNet101[1-3]等深度神经网络模型在取得优越性能的同时伴随着较高的存储空间需求和计算复杂度。移动设备虽具有丰富的计算和存储资源,但运行以上深度神经网络模型仍面临较大的挑战。
深度神经网络中存在大量冗余计算,造成存储和计算资源浪费,因此研究人员试图通过压缩网络模型来减少冗余计算。该研究主要分为3个方向,即网络剪枝、网络参数量化和加速网络结构设计。网络剪枝用于训练较好的神经网络模型,移除网络模型中特征信息少的权值数据。文献[4]提出低值连接直接删除的剪枝法,将原始密集神经网络转换为稀疏神经网络,并为剪枝后的网络设计了首个稀疏网络加速器EIE(Efficient Inference Engine)[5]。网络参数量化主要针对权值和特征图值进行量化处理,使用低位定点数据代替高精度训练下的浮点数据。文献[6]提出二值神经网络(Binarized Neural Networks,BNN),对网络中权值和中间特征图值进行二值化处理,使用位运算代替原来浮点数乘法运算,减少了计算复杂度。文献[7]提出同或网络XNOR-Net,为二值化处理中产生的误差引入近似因子,XNOR-Net精度仅比全精度网络低10%。加速网络结构设计是指探索最优的网络结构,例如轻量型网络ShuffleNet、MobileNet、SqueezeNet[8-10]等。与前面深度神经网络模型相比,此类轻量型网络网络参数少,识别精度高,能减少计算复杂度和存储空间需求,因此更具研究价值。近几年多种变形的轻量型网络也已被应用到实际生活中[11-13]。复旦大学ASIC重点实验室提出了基于层结构设计的SqueezeNet轻量型网络加速器[14],其以蝶形流水线结构使多层并行计算,但是其网络层数较深,无法并行整个网络进行同时计算,仍存在改进空间。
本文在深入研究SqueezeNet网络的基础上,以处理块结构部署网络进行加速设计,减少了计算模块和内存间流动的数据量,降低了内存读写消耗。此外,本文利用激活函数特性,为计算模块引入提前结束卷积计算的思想,减少了无效值占用的计算量和计算周期,提高了网络部署的效率。
1 SqueezeNet网络模型
1.1 SqueezeNet网络模型
SqueezeNet网络是一种轻量且高效的神经网络模型,参数量仅为AlexNet网络的1/48,但识别精度与 AlexNet网络相同[10]。
SqueezeNet网络结构如图1所示,主要包含卷积层(Conv)、ReLU激活函数、池化层(Pool)和Fire块。其中Fire块表示SqueezeNet网络的核心组成模块Fire module,其由Squeeze(S1)、Expand(E1、E3)、ReLU、Concat(C)和Pool(P)层组成。S1是卷积核为1×1的卷积层Squeeze1×1,经过该层后输出的特征图数据深度较小,具有降维作用。E1和E3分别是卷积核为1×1、3×3的卷积层Expand1×1和Expand3×3。C为拼接层,E1和E3层输出特征图数据经过C层后,在通道上进行拼接,输出数据量增加一倍。输入大小为227×227×3的图片数据,经过SqueezeNet网络多层处理后可得到1 000个图像分类结果。

图1 SqueezeNet网络结构
1.2 网络基础层
1.2.1 卷积层
卷积计算是卷积核在输入特征图上滑动时与对应卷积框内特征图数据的乘累加计算。SqueezeNet网络中的卷积计算及拼接过程如图2所示,其中输入特征图ifmap分别与1×1、3×3的卷积核K1、K2进行卷积计算,输出大小相同的特征图数据ofmap1、ofmap2,再经过Concat拼接层后输出特征图ofmaps。输入特征图的高(H)和宽(W)与输出特征图的高(E)和宽(F)满足式(1)。
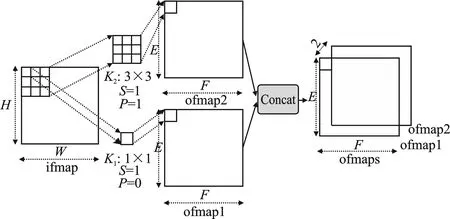
图2 卷积计算及拼接过程
(1)
式中,S为卷积核每次移动的步长;P为填充单位;K为卷积核大小。
1.2.2 激活函数
当网络中不引入激活函数时,即使网络层数再深,也与单层线性网络性质等价,仅限于处理线性问题。而激活函数的引入为网络中加入了非线性因素,可解决线性模型无法解决的问题。常用的ReLU激活函数式为
ReLU(x)=max(0,x)
(2)
式中,x为卷积层输出特征图值;ReLU激活函数将小于0的输出特征图值置为0,其余值保持不变。这给网络中引入大量稀疏数据0。
1.2.3 池化层
通常在连续的卷积层后插入池化层,常用的有最大池化和平均池化,即取池化框内最大值或平均值替换池化框内所有数据。池化操作后的特征图尺寸相比原始特征图有所缩小,可降低网络中的数据量和计算量。
2 加速器硬件架构设计
2.1 加速器整体架构
加速器整体架构如图3所示,主要分为配置模块、全局缓冲模块、输入缓冲模块、权重缓存模块、核心计算模块和中间值缓存模块。其中配置模块根据网络结构参数配置每个处理块(Process block,Pb)中的信息,包括输入特征图传输、权重值加载、核心计算模块运算、中间特征图存储。特征图数据存储在全局缓冲模块,可选择是否经过输入缓冲模块送到核心计算模块中。若计算Expand3×3卷积层,则需要先将特征图数据送到输入缓冲模块的移位寄存器中,等到卷积计算开始时,再从移位寄存器中取值送到核心计算模块。若计算Expand1×1卷积层,则直接从全局缓冲模块取出特征图数据送到核心计算模块。核心计算模块主要完成处理块中Expand3×3、Expand1×1和Squeeze1×1卷积层的运算。若核心计算模块输出完整特征图数据,则直接将完整特征图数据送到激活单元后写回全局缓冲模块,否则将产生的部分特征图数据送到部分值缓存单元,等待核心计算模块送出的下一组特征图数据一起进行累加计算,直到输出完整特征图数据再送到激活单元,最后写回全局缓冲模块。
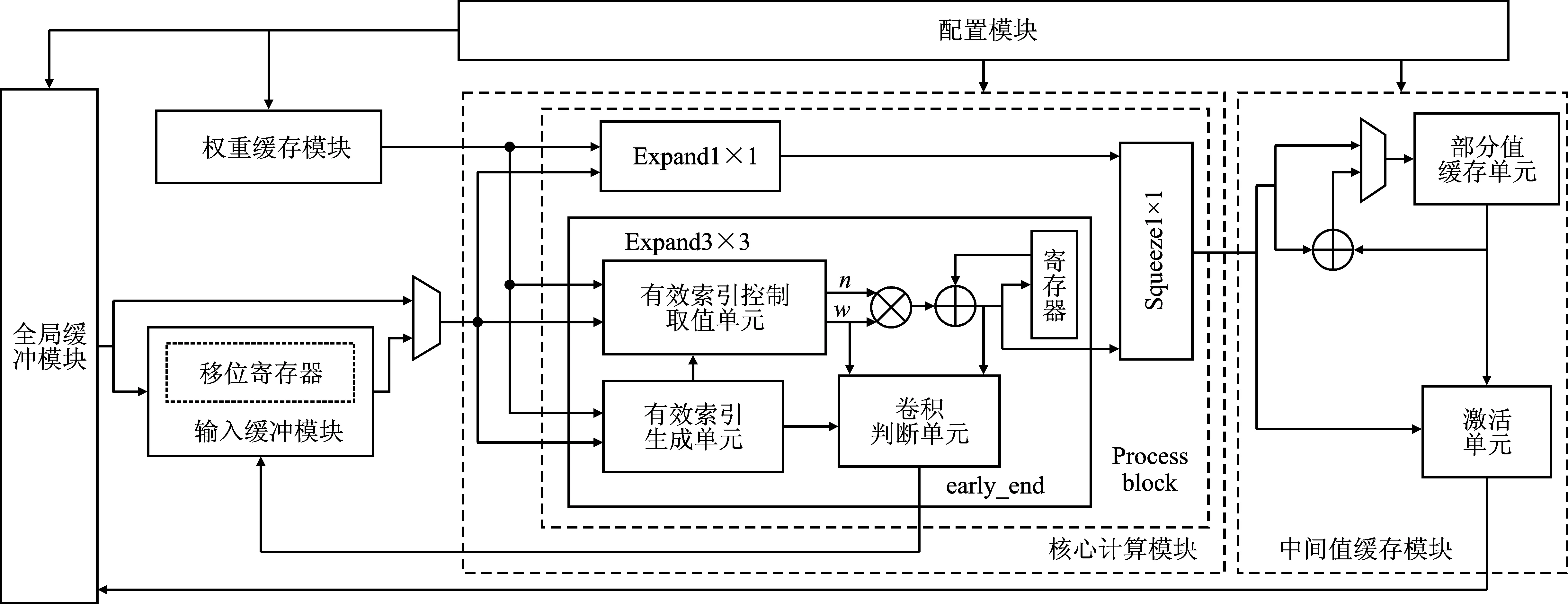
图3 加速器整体架构
2.2 降低访存数据量
SqueezeNet网络参数量仅为AlexNet网络的1/48,但中间流动的特征图数据量达到202 kB。若逐层部署网络,每层输出特征图数据需先写入内存中,等待下一层计算需要时,从内存中取出送回计算单元。在计算单元和内存间流动的202 kB数据会产生大量读写消耗,导致此种部署方式效率不高。文献[14]为避免单层网络部署效率低问题,以SqueezeNet核心模块Fire来部署网络,此时读写入内存中的数据为Concat层输出数据,计算单元和内存间流动数据量达到177 kB,相比单层网络部署减少了12.3%。
图4给出SqueezeNet网络部分层输入、输出特征图数据大小,其中Concat层将Expand1×1和Expand3×3卷积层输出数据在通道维度上进行拼接,输出数据量增加一倍,故文献[14]中以Fire块部署网络仍具探索空间。为进一步减少中间流动数据量并降低读写内存消耗,本文利用Squeeze1×1层降维作用,以处理块结构重新划分网络。除个别层外,处理块由Expand1×1、Expand3×3(E1、E3)层和Squeeze1×1(S1)层组成,以Squeeze1×1层结束的处理块。这样处理使得输出特征图数据量明显减少,由此可知处理块结构部署网络能有效减少中间流动数据量并降低读写内存消耗。

图4 处理块划分的SqueezeNet网络
2.3 减少计算周期
激活函数ReLU给网络中引入大量的稀疏数据0,这些0值虽不影响卷积计算输出,但占用了无效的计算量和计算周期,影响网络计算速度。文献[15]设计的加速器能跳过特征图中0值计算,避免浪费多余的计算量和计算周期,但该方法仅考虑了跳过0值占用的无效计算。本文通过研究ReLU激活函数特性,为核心计算模块设计了有效索引生成单元、有效索引控制取值单元和卷积判断单元,进一步减少了无效值包括非0特征图值占用的计算量和计算周期,加快了网络计算速度,减少了计算资源消耗。
2.3.1 有效值生成单元
有效值生成单元包括有效索引生成单元和有效索引控制取值单元,如图5所示。其中权值和特征图值分别来自权重缓存模块和输入缓冲模块的移位寄存器。首先给权值降序排序产生原始位置索引,然后特征图值按照原始位置索引取值生成输入判断值。若原始位置索引值对应位置的特征图值不为0,则输入判断值为1,否则输入判断值为0。将生成的输入判断值和原始位置索引相与,输出中间索引。对中间索引再排序。非0值索引依序靠前排列,0值索引相应靠后排列,得到有效索引。
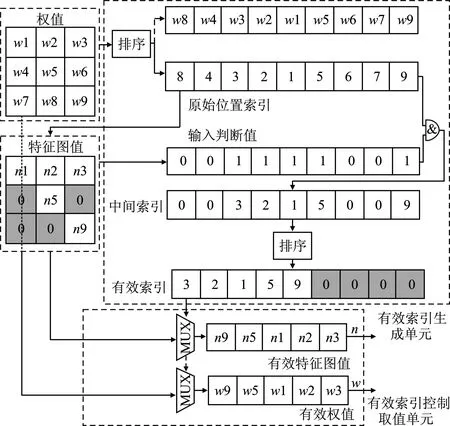
图5 有效值生成单元
有效索引生成单元输出的有效索引具有以下特点:非0索引值靠前,0值索引置后;按照非0索引值取出的权值降序排序。由图5可以看出,有效索引控制取值单元按照有效索引取出的有效特征图值和权值比原始数据短,减少了乘累加计算量和周期消耗。
2.3.2 卷积判断单元
卷积判断单元的输出由有效索引(idx)、有效权值(w)和累加计算输出值(s)决定,如图6所示。若输入有效索引值为0或累加计算输出值小于0且有效权值小于0,则卷积判断单元的输出为1;不满足两者条件时,卷积判断单元的输出为0。当卷积判断单元输出为1时,跳过剩余乘累加计算,输出当前累加计算值并拉高early_end信号,控制移入下一组特征图数据。若卷积判断单元输出为0,则将累加计算输出值送到寄存器中,与乘法器下一个输出值一起送到加法器进行累加计算,将新得到的累加计算值和有效权值、有效索引值再次送到卷积判断单元中,进行下一次卷积提前结束的判断。

图6 卷积判断单元
图7中给出单张特征图与权值的卷积计算过程,并对比了正常卷积计算和卷积提前结束计算下的周期消耗。正常卷积计算下,特征图1和特征图2与权值相乘,9个时钟周期后输出乘累加值0、40,共消耗18个时钟周期。卷积提前结束计算时,有效索引控制取值单元根据有效索引生成单元输出的有效索引取相应的特征图值和权值送往右边进行乘累加计算。此计算过程加入了卷积判断单元,用于停止卷积计算。当特征图1与权值计算到第3个时钟周期,乘累加输出结果为负且权值为负,卷积判断单元的输出为1,此时停止卷积计算,将乘累加值-4送到激活单元后输出值0。特征图2与权值计算到第6个时钟周期时有效索引值为0,卷积判断单元输出为1,停止卷积计算,乘累加值40送到激活单元后输出值40,总耗时9个时钟周期。由图7可以看出,卷积提前结束下特征图1、特征图2与权值的乘累加输出值与正常卷积计算相同,相比正常卷积计算,新方法跳过了9个无效值占用的计算量和计算周期。

图7 卷积计算过程
3 实验与结果分析
为了验证加速器优化效果,本文使用Vivado和Modelsim对设计的轻量型SqueezeNet网络加速器进行功能仿真验证和现场可编程门阵列(Field Programmable Gate Array,FPGA)验证。
3.1 访存数据量分析
加速器以处理块结构部署网络,减少了计算模块和内存间流动的数据量,降低了读写内存消耗。而读写内存中数据的能耗远大于计算模块中计算的能耗。
文献[14]以Fire module(Fm)划分网络本加速器以Pb划分网络,两种划分方式的流动数据量比较如图8所示,其中网络流动数据量包括输入特征图(In)、权重(W)和输出特征图(O)数据量,并给出Pb流动数据量占Fire module流动数据量的百分比(Pb/Fm)。

图8 两种划分方式流动数据量对比
看由图8可以出,以处理块划分网络的流动数据量比Fm划分方式少。所有Fm中流动数据量输出值为7.62 MB,所有Pb中流动数据量输出值为3.40 MB。相比之下,Pb中总流动数据量减少为Fm中总流动数据量的44.62%,即以Pb划分网络后,整个网络减少55.38%的数据流动量。
3.2 计算周期分析
利用激活函数特性为核心计算模块设计了有效索引生成单元、有效索引控制取值单元和卷积判断单元,可跳过无效值占用的计算量和计算周期。
图9(a)为SqueezeNet网络中不同处理块(Pb)的计算量,包含Expand3×3(E3)、Expand1×1(E1)和Squeeze1×1(S1)层中0值乘累加计算量(Zero MAC)、非0值乘累加计算量(Nonzero MAC)以及0值乘累加计算量占总计算量(Zero MAC/Total MAC)的比例。由图9(a)中可知,随着网络层数加深,0值乘累加计算量占总计算量的比例也在增加。

(a)
图9(b)给出了不同处理块的理想周期消耗(Cycle_Th)和仿真周期消耗(Cycle_Ac),其中理想周期消耗不考虑数据延迟,而仿真周期消耗为Modelsim仿真结果统计的周期消耗数,其加入了数据延迟。由图9(b)可知,引入提前结束卷积计算思想后,仿真周期消耗数低于理想周期消耗数。而处理块1(Pb1)中未利用提前结束卷积计算思想,其理想周期消耗数为29 256,仿真周期消耗数为32 362。汇总所有处理块中理周期消耗数得到网络整体周期消耗数为419 688,而汇总所有处理块中仿真周期消耗数可得到网络整体周期消耗数为358 071。相比理想周期消耗数,仿真周期消耗数减少为它的85.32%,跳过了14.68%无效值占用的计算量和计算周期。
3.3 加速器性能分析
表1是加速器设计综合后的FPGA中资源消耗,其中DSP用于执行卷积计算,BRAM用于存储特征图值和权值。

表1 资源消耗
表2为所设计的加速器与其它研究中加速器的对比结果。本文设计的加速器与文献[16]相比,都使用定点数表示网络参数,但本文加速器增加了网络并行度,消耗的计算资源DSP为文献[16]的8倍左右,延迟加速比则达到93倍。在消耗相同计算资源的情况下,相比文献[16],本加速器的延迟加速比达到11倍左右。本文与文献[14]加速器均使用相同的精度数据表示网络参数,加速器间延迟数据相差不大,但本加速器中计算资源DSP和存储资源BRAM消耗比文献[14]中低,加速器整体性能高于文献[14]中的加速器。

表2 与其它研究的对比
4 结束语
本文针对轻量型SqueezeNet网络中间流动数据量大及计算周期长等问题,设计了一种基于FPGA的SqueezeNet推断加速器。本文提出了处理块结构部署网络,相比文献[14]的方案减少了55.38%的数据流动量,降低了读写内存消耗。此外,本文为处理块中计算模块引入提前结束卷积计算思想,跳过特征图中14.68%的无效值占用的计算量和计算周期,减少了计算资源和存储资源的消耗。实验结果分析表明,利用处理块结构和提前结束卷积计算的思想能提高加速器性能。本加速器是针对轻量型网络SqueezeNet设计的,在以后的研究中可尝试设计通用性更强的网络加速器。
