结合掩码定位和漏斗网络的6D姿态估计
2022-02-28李冬冬郑河荣刘复昌潘翔
李冬冬,郑河荣*,刘复昌,潘翔
1. 浙江工业大学计算机科学与技术学院, 杭州 310023; 2. 杭州师范大学信息科学与技术学院, 杭州 311121
0 引 言
由于从2维图像恢复出6维(6 dimensions,6D)姿态在虚拟现实、增强现实和机器人交互等方面有着巨大的应用,因此6D姿态已经成为计算机图像领域的研究热点(杨步一 等,2021)。虽然基于深度彩色(red, green, blue,RGB)图像算法进行姿态估计已经能够取得较好效果(Choi和Christensen,2016;Cao和Zhang,2017),但是现实场景中的物体非常复杂(Hinterstoisser等,2012;Brachmann等,2014),场景物体烦多,目标遮挡严重,受天气、光照及设备成本等影响,很难大量获取图像的深度信息,从而使得基于图像的6D姿态估计成为一个较复杂的研究难题。
6D姿态估计主要分为基于关键点的方法和直接使用深度学习的方法两类。基于关键点的方法是目标物体先通过局部特征点方法提取关键点,然后通过关键点进行位姿计算;直接使用深度学习的方法是直接通过深度学习神经网络来估计位姿。基于关键点的方法由于是直接预测图像坐标,因此预测范围小、准确度高。而使用深度学习网络直接估计物体的旋转和平移,由于旋转空间是非线性的且范围较大,所以通常误差较大,对数据集有依赖性。
本文提出一种基于热力图的局部特征约束下的关键点预测算法,用于提高6D姿态估计结果的准确性。首先提出一种分割网络生成物体边框与掩码,该网络以YOLOv3(you only look once v3)(Redmon和Farhadi,2018)网络为骨架,增加一个分支网络生成目标对象的掩码,提高物体检测外包围盒的准确性。其次使用物体表面特征点,提出一种关键点检测网络生成特征关键点的热力图,该网络采用一个漏斗网络为骨架的多尺度特征提取结构, 实现局部特征的融合,提高关键点的预测精度。同时为了进一步提高关键点的置信度,利用掩码预测来约束特征点范围,剔除掩码以外的关键点。最后通过视角n点(perspective-n-point,PnP)(Lepetit等,2009)恢复出6D姿态。实验结果表明,本文提出的分割掩码和基于热力图的特征检测网络能够明显提高关键点的预测准确性,有效提高了6D姿态估计的准确性。
1 相关工作
与姿态估计相关的工作主要包括关键点提取、基于卷积神经网络(convolutional neural network, CNN)的直接回归和热力图网络3方面。
对于关键点提取,常采用传统的匹配方法(Lowe,1999),这类方法根据图像中的纹理信息以及局部特征实现关键点定位。此外,Wagner等人(2008)在特征跟踪时,利用相机在初始时提取特征点,将候选特征点与当前帧中的特征点进行匹配,计算当前帧新的位姿。但是这些算法只能准确处理高分辨率图像中的纹理对象,不能很好地处理表面光滑、无纹理的物体。类似的其他方法还有基于3D模型的配准(Li等,2011)和基于3D曲线模型与图像对齐的3D匹配(Ramnath等,2014)。
对于姿态估计卷积网络,随着深度学习和卷积理论在图像分析领域的广泛应用,研究人员采用卷积网络方法提高6D姿态估计的准确性。Pavlakos等人(2017)根据3D模型特征生成3D关键点,利用3D关键点预测图像中对应的2D关键点投影位置,然后使用PnP方法恢复6D的姿态。Rad和Lepetit(2017)以及Kehl等人(2017)采用边框的8个角点作为关键点,利用卷积神经网络回归出8个角点在2D图像中位置。Tekin等人(2018)在Kehl等人(2017)方法的基础上增加了一个物体的中心点,通过YOLOv2(Redmon和Farhadi,2017)为主要框架的CNN网络回归9个关键点。尽管通过回归能够定义8个角点的估计网络,但是由于8个角点是一种空间相对位置,并没有任何明确的几何特征描述,精度很难得到明显提高。另一类则是直接回归6D姿态(Xiang等,2018)。该类方法首先利用深度学习的端到端网络生成一系列候选区域,然后利用感兴趣区域和特征图对每个区域分别预测类别、旋转(rotation,R)和平移(translation,T)。Kendall等人(2015)通过CNN网络回归姿态。由于直接回归旋转矩阵和平移矩阵误差较大,结果通常没有基于关键点的算法效果好,所以直接回归6D姿态通常还需要结合深度信息进一步优化,这也导致实用性效果差。
对于姿态估计,在理论上还可以通过投票方法实现多个特征的组合,从而进一步提高姿态估计在遮挡下的准确性。Kehl等人(2016)根据每个部分对整个整体进行投票。Michel等人(2017)基于随机森林预测3D坐标,然后利用几何约束生成2D—3D的对应关系。Peng等人(2019)利用投票对关键点投票,可以在遮挡情况下利用局部特征向量得到关键点。Wang等人(2019)对RGB图像和深度对应3D点云使用网络得到融合的像素密集特征, 然后通过投票得到最后6D姿态。但是这类方法由于需要过多地对数据进行处理, 这些大量后处理严重影响算法运行速度,所以也不能应用到一些实际场景。
根据2维图像进行6D姿态估计的一个核心问题是如何准确高效地得到关键点用于3维姿态恢复。关键点提取有两类方法。一类方法是检测计算物体边框的8个角点,但是由于8个角点不在物体表面上,与目标物体表面特征信息关联不大,不能自然地利用物体信息来约束角点生成,使用卷积网络提取8个角点可靠性存在很大的不稳定性,因此这种方法会导致姿态估计结果存在准确率较低问题。另一类方法是研究人员考虑直接从物体表面提取关键点,从而能够更加充分地利用物体表面特征。但是已有方法在提取表面特征点时,只考虑物体的全局特征,却没有考虑物体的纹理信息等局部特征,影响了关键点估计的准确性。为了避免没有考虑物体局部特征直接预测关键点坐标带来误差较大的问题,本文利用热力图来预测关键点位置。
Zhao等人(2018)采用残差网络(He等, 2016)直接回归关键点热力图,然而残差网络在关键点预测中缺少局部特征来约束关键点位置,导致关键点位置出现较大偏差。本文利用漏斗网络(Newell等,2016)解决关键点热力图中缺少局部特征的问题。该网络类似于编码器与译码器结构,负责提取特征和生成热力图,利用在每一层中增加相同分辨率的特征进行融合。由于热力图是由全卷积网络生成,容易受到局部噪声的污染,需要对生成的热力图关键点进行筛选,剔除误差较大的关键点。本文算法采用掩码剔除掩码区域以外的特征点,保证特征点在物体表面上。
2 本文方法流程
本文提出一种结合掩码定位和漏斗网络的方法估计物体的6D姿态。输入一幅RGB图像后,首先通过目标分割网络对物体对象进行目标识别及掩码分割,并根据掩码对物体对象进行裁剪以去除多余的干扰信息,然后通过关键点预测网络模型得到对应的关键点位置,最后利用PnP算法恢复物体的6D姿态位姿(旋转矩阵R, 平移矩阵t)。本文算法可以解决遮挡情况下姿态估计精度较差问题。算法流程如图1所示。
2.1 目标检测与分割
为了维持网络的高效速度,目标预测网络模型(图1中目标分割模型)以YOLOv3为网络模型骨架,利用DarkNet53网络,将输入的分辨率为s×s像素的三通道RGB图像(s为图像原始分辨率)通过大小为3×3、步长为2的卷积核进行5次下采样,随后利用1×1和3×3卷积加深特征维度,并在原有的预测边框以及分类基础上,添加一个新的分支用来预测分割。由于没有改变原有的识别网络,所以本文算法的目标检测模型可以实现多目标识别。
算法掩码分支模型如图2所示。为了使输入图像可以是任意尺寸,掩码分割网络采用全卷积神经网络。为了减少卷积和池化对图像分割掩码的影响,使图像分割可以输出更精细结果,对分辨率进行多次扩大,每次扩大分辨率均采用大小为2×2、步长为2的反卷积核。为了防止下采样时分辨率减小导致局部特征消失,在特征提取过程中保留1/8×s和1/4×s两种不同分辨率的特征图。在生成目标掩码的反卷积后加入保留的特征图,并与反卷积得到的特征图在维度上进行拼接。拼接特征图后,每一层网络都使用两种大小为C×1×1和(2×C)×3×3以及步长为1的卷积核。其中,C为1×1卷积核的维度,(2×C)表示3×3卷积核的维度为1×1的两倍,最后还有一层C/2维度的1×1卷积核。每次反卷积后分辨率扩大1倍,1×1、3×3、1×1这3种维度不同的卷积核维度缩小1倍。最后输出的对于训练网络,需要输出目标的边框、类别和掩码图。边框损失和分类损失采用与YOLOv3相同的损失函数,掩码损失Lm采用均方误差函数,具体为

图2 掩码分支网络结构Fig.2 The structure of mask branch network
分割图设定阈值为0.6,每一像素置信度大于0.6为目标前景,小于0.6为背景。
(1)
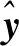
训练中采用3个损失函数对整个网络进行约束,具体为
L=λcLc+λbLb+λmLm
(2)
式中,L为总的损失函数,Lc为对该目标的对象置信度损失,Lb为对边框的回归损失,Lc与Lb均采用YOLOv3的损失函数,Lm为掩码损失。λc,λb与λm均为参数。
2.2 基于漏斗网络的特征预测与状态恢复
提取物体区域后,利用预测的边框对原始图像进行裁剪,裁剪后的图像分辨率为320 × 256像素。然后使用裁剪后的图像通过关键点预测神经网络模型(如图3所示)预测关键点。由于物体的纹理信息较差,直接进行关键点的预测会导致误差加大, 因此采用回归热力图方式预测关键点。同时,为了减少由于局部信息丢失导致关键点预测精度下降,采用以漏斗网络为骨架的神经网络模型。
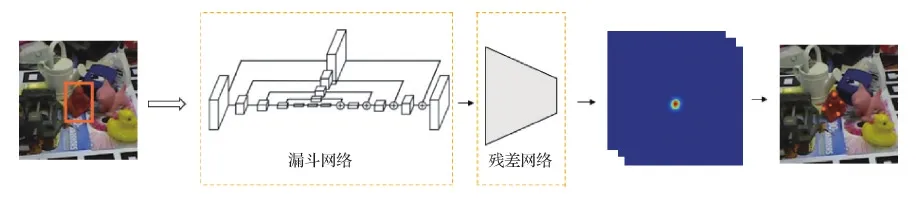
图3 关键点检测网络结构Fig.3 The structure of key point detection network
漏斗网络的拓扑结构是对称的,类似于编码解码形式。在编码部分,先经过步长为2的7×7卷积核,再采用最大池化方式进行下采样降低尺度,每次下采样后接入残差模块(如图4所示)提取特征。残差模块提取关键点特征信息,不改变特征图尺寸,只改变特征图深度。在解码过程中,采用上采样恢复尺度。每次上采样同样经过残差模块。为了防止在扩大尺度时特征图丢失局部信息,采用多尺度特征约束,在每次下采样之前分出支路保留原尺度信息,利用只包含1个卷积核为1的跳级层,在每次上采样后的相同尺度下进行拼接。本文方法使用在进行卷积时的4个不同分辨率拼接到上采样中,利用开始的特征图与上采样的特征图进行合并。同时对漏斗网络进行改进,没有直接回归与网络输入相同分辨率的热力图,而是利用漏斗网络进行中继监督,生成一个中继结果,最终的热力图由最后一层残差网络生成。在关键点预测模型中,本文方法最后生成k幅热力图,每幅热力图都代表一个关键点的位置。
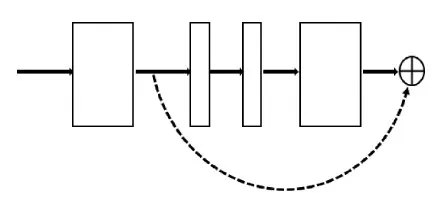
图4 残差模型结构Fig.4 The structure of residual model
损失函数采用均方误差函数,最后生成的热力图以像素中最高的置信度值的当前位置为关键点的位置, 计算为
(3)
式中,x,y为第p个关键点的估计坐标,i和j为预测的热力图像素点,H为热力图。
生成的关键点坐标记为Mk2D,利用PnP公式,得出最后的旋转矩阵R与平移矩阵t,具体为
Mk2D=K[R|t]Mk3D
(4)
式中,Mk3D为开始标注的3D模型关键点坐标,K为相机矩阵参数。[R|t]为旋转矩阵和平移矩阵在行上保持不变,在列上进行拼接,得到3×4的矩阵。采用式(4)时,需要点的个数大于3才能求解出最后的姿态,在本文实验中,算法的特征点个数为50。
3 实验与结果分析
3.1 数据集介绍
使用姿态估计中有挑战的数据集LineMod(Hinterstoisser等,2012)验证本文算法。
LineMod数据集是目前针对6D姿态估计研究的标准数据集,含有15个物体对象,15 783幅RGB图像。每幅图像中的目标对象都注释了类别、边界框位置、真实的旋转矩阵和平移矩阵,提供了带有表面颜色的3维空间点云模型。该数据集场景情况较为复杂,物体对象缺少纹理信息,使得检测难度较大。图5 为LineMod数据集中物体的不同姿态图像示例。

图5 LineMod数据集下物体不同姿态Fig.5 Different postures of objects from LineMod dataset
3.2 评估指标
在6D姿态估计中,公共评估算法的性能指标有两个,即2D投影误差和模型点的3D平均距离(3D average distance,ADD)。
2D投影误差是指3D模型点的2D投影与真实2D投影的平均距离。当平均距离小于5像素时判定该幅图像估计为正确,大于5像素时为错误。该指标可以用于预测的姿态投影与真实的投影位置距离,适应用于作为增强现实与虚拟现实指标应用。
模型点的3D平均距离(ADD)是指3D模型顶点坐标通过预测的姿态与真实的姿态得到变换后的模型点坐标,计算变换后的模型点平均3D距离。当ADD小于模型直径的10%时判定估计的姿态为正确,否则判为错误。ADD指标计算为
(5)
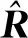
(6)
式中,M为3D模型的点集,x1和x2为模型点集中的点。由于式(6)使用最小误差时的点,所以使用范围非常小,需要对象是旋转对称,例如鸡蛋盒这类物体才可以使用。
3.3 方法比较
表1是本文算法与Zhang等人(2019)、Tekin等人(2018)等方法的ADD指标对比。可以看出:1)由于本文算法采用引入多尺度特征融合中以漏斗网络为基础的网络结构,极大提升了关键点的预测准确性,在现有关键点热力图预测算法中达到最好水平。与直接预测关键点的算法Betapose(Zhao等,2018)相比,预测准确性整体平均提高了10.1%。与包志强等人(2020)、Tekin等人(2018)、Zhang等人(2019)和Pix2pose方法(Park等,2019)相比,分别提高了31%、26.75%、11%和10.3%。2)对于猿(ape)、台虎钳(ben.)、钻工(driller)等纹理信息比较丰富及表面特征比较突出的模型,本文方法明显优于Betapose方法。对于对称物体鸡蛋盒(eggbox),由于对称物体沿对称轴两边的物体表面特征相同,网络预测这些相同位置会出现较大偏差。Betapose对这种对称物体,在特征点提取时采用沿对称轴一半物体的特征点为关键点的策略,提高了准确度。而本文方法没有针对点的选取进行改变,依然针对整体进行特征点提取,使得网络预测由于对称问题损失精度。当本文方法和Betapose方法均采用式(6)进行评估时,实验结果表明,本文算法依然可以提高6D姿态估计的准确率。对于缺少纹理信息的手机模型,本文算法的ADD指标为81.1%,远高于Betapose方法。在13个模型中,本文算法的ADD指标有12个模型高于Betapose方法。3)在遮挡情况下,本文算法采用掩码剔除误差点,比Betapose方法更加适合。
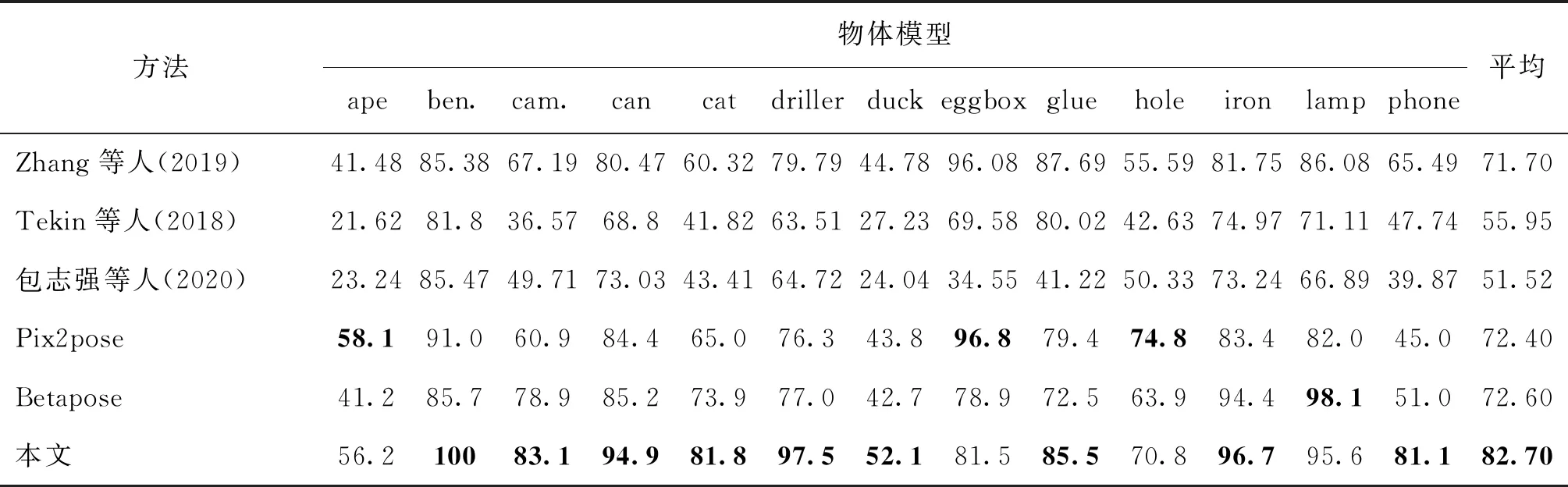
表1 不同方法在LineMod数据集上的ADD对比Table 1 ADD comparison experiment results /%
表2是本文算法与其他对比算法的2D投影正确率指标对比结果。其中,Betapose等对比模型数据系复现结果,Betapose平均值94.5%(原文献提供)。可以看出:1)在2D投影正确率指标上,本文算法的实验结果整体平均值为98.9%,高于Betapose方法。在13个物体模型中,本文算法的2D投影正确率均比Betapose方法更优,对台虎钳(ben.)、照相机(cam.)、罐(can)等纹理信息丰富的目标对象的2D投影正确率为100%。2)与Tekin等人(2018)和Zhang等人(2019)的方法相比,本文方法的2D投影正确率平均提高了8%和4%。实验结果表明,本文算法在2D投影中具有很高的准确性。
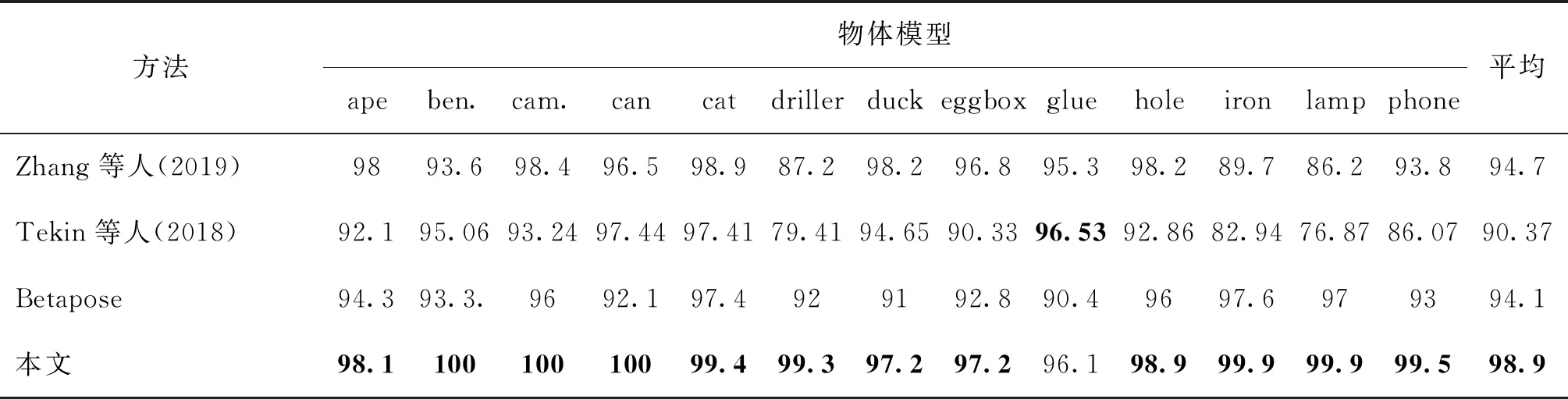
表2 2D投影正确率Table 2 2D projection accuracy /%
最后给出算法运行帧率表,虽然本文算法增加了网络结构,但是本文算法的时间并没有明显增加。如表3所示,在同一实验条件下,本文算法的运行速度达到了15帧/s。虽然Betapose可以达到17帧/s的速度,相比较ADD精度与2D精度的提高,本文算法的速度可以接受。

表3 算法运行帧率Table 3 Algorithm running frame rate
为了比较模块效果,进行算法模块之间的对比实验,如表4所示,其中,本文—掩码为本文算法去除掩码模块预测出的实验结果,本文—漏斗为本文算法中漏斗网络没有使用多尺度特征信息融合的实验结果,本文为本文算法最后的实验结果。可以从表4中得出,本文—漏斗方法要比最终实验结果减少5.4%,去除掩码模块后实验结果要减少2.3%,实验表明提出的网络模块非常有效。

表4 算法消融性实验Table 4 Algorithm ablation experiment /%
3.4 结果可视化
如图6所示,热力图越集中表明预测效果越好。从图6中可以看出,本文热力图效果明显更好,预测的热力图更加规整、集中,接近真实热力图,而Betapose方法热力图明显分散。

图6 热力图对比Fig.6 Heatmap comparison ((a) Betapose; (b) ours; (c) ground truth)
如图7所示,对LineMod数据集上的结果进行可视化,对于8个模型图像,分别展示本文方法与Betapose方法的效果。实验结果均在相同的实验环境下生成。可以明显地观察到,对于猿、照相机、罐和钻工4个模型的边框盒在Betapose中存在一定偏差,本文可以通过更准确地预测2D关键点信息去纠正错误6D位姿,达到更高精度的要求。值得注意的是,当Betapose预测的6D姿态完全错误时,本文算法仍然可以恢复出对象的6D姿态。例如,鸭、猫和胶中第3列误差偏大,Betapose甚至无法生成出边框盒。但是通过本文算法,这些物体的边框依然可以完好地恢复出来。
在遮挡情况下,首先增加了多尺度特征信息进行关键点预测,提高了关键点预测的准确度,并且增加了分割掩码,可以剔除在物体之外的误差点。如图8所示,对遮挡目标红色猿的图像进行实验可视化对比,图中绿色为目标对象真实的边框,蓝色为算法预测出来的边框。从图8中可以明显看出,本文方法在遮挡比较严重的时候依然可以恢复出来,而Betapose方法则出现明显偏差。
4 结 论
本文提出一种结合掩码和关键点的6D姿态方法。针对已有姿态估计网络采用残差模块没有考虑局部特征问题,在特征描述方面引入漏斗网络,实现局部特征的融合,提高关键点的准确性。同时,为了防止热力图被污染,造成误差偏大,引入了掩码,通过掩码来挑选置信度高的特征点。提出的网络结构与最新热力图关键点算法Betapose比较,ADD性能指标提高了10%,2D投影性能指标提高了4%。
但是,目前本文算法还没有考虑更为先进的关键点预测方法如投票方法,因此在遮挡问题上准确率还可以进一步提升。在后续研究中,需要考虑在关键点预测模块基础上,引入投票规则,提高网络在遮挡约束下的关键点预测准确性。另一方面,关键点预测来进行姿态估计的方法,大多依赖于目标检测的框架,可以考虑直接对目标进行3维目标框检测,进一步提高姿态估计的准确性。

图7 算法结果可视化对比图Fig.7 Visual comparison map of algorithm results ((a) ape; (b) camera; (c) can; (d) driller; (e) cat; (f) duck; (g) eggbox; (h) glue)

图8 目标遮挡图对比Fig.8 Target occlusion map comparison ((a) Betapose; (b) ours; (c) original)
