聚合细粒度特征的深度注意力自动裁图
2022-02-28方玉明钟裕鄢杰斌刘丽霞
方玉明,钟裕,鄢杰斌,刘丽霞
江西财经大学信息管理学院, 南昌 330032
0 引 言
自动裁图是计算机视觉中具有实用性和挑战性的问题,旨在裁剪出图像中构图更佳的区域,提升图像美感。自动裁图广泛应用于摄影、印刷和缩略图技术等相关领域。随着深度学习的发展,利用数据驱动解决自动裁图问题的方法越来越多。
早期研究从人眼关注的图像显著区域(Jian 等,2015)出发,以凸显视觉重要信息为目的进行裁图。Suh等人(2003)结合显著性检测和人脸高级语义特征指导缩略图的裁剪。Stentiford(2007)将像素平均显著分数作为衡量裁图好坏的标准。Chen等人(2016a)探索了基于图像显著性的自动裁图搜索算法的复杂度。上述方法的效果均取决于像素级别的分类精度,容易产生误判和漏检。同时,由于缺乏对图像构成的考量,结果往往不符合审美要求。Zhang等人(2013)提出基于邻接图的概率模型,较早地关注了图像构图完整性。Yan等人(2013)基于先验规则提取38维手工特征,探究了图像在专业裁剪前后的差异。Fang等人(2014)总结3种普遍的图像裁剪规则,提出一个评估图像构成和内容的模型。这类方法对裁图有一定提升,但多数采用滑窗生成候选裁图框的方式,增加了算法时间复杂度。此外,由于图像构图的规则和技巧相对复杂,实际应用过程中存在诸多问题,如局部特征丢失、空间形变失真和平移不敏感等。
卷积神经网络(convolutional neural network,CNN)因性能优异广泛应用于自动裁图领域。Chen等人(2017a,b)发布了一个用于成对比较(pairwise ranking)的裁图数据集,并基于排序思想提出一个孪生网络(siamese network)裁图模型。Wei等人(2018)进一步提高裁图数据集的规模,提出首个密集标注的裁图数据集,并采用迁移学习(transfer learning)方法,将复杂模型所学知识迁移到基于目标检测(object detection)的高性能裁图模型,提高了自动裁图的效率。Zeng等人(2020)基于网格的图像表示和语义约束生成更加合理的候选裁图框,提高了裁图数据集标注的密度,促进模型学习更有区分力的特征表示。
尽管深度学习方法较传统方法取得了更好的效果,但仍很少考虑裁图区域的局部和全局上下文依赖关系、裁图特征的细粒度等与图像构成相关的重要信息,多数深度学习方法对复杂场景、显著目标位置、空间形变以及裁图平移等问题仍然不够鲁棒。为此,本文提出一种聚合细粒度特征的深度注意力自动裁图方法(deep attention guided image cropping network with fine-grained feature aggregation,DAIC-Net)。
主要贡献如下:1)结合区域特征提取和空间金字塔池化技术,提高模型对图像构成的解析,可以有效捕获多尺度结构信息。由于图像低维特征的共享,可以在几乎不增加额外运行时间的条件下,同时应用多种不同细粒度区域特征聚合操作,提高模型的检测精度和效果。2)融合全局和局部多尺度注意力特征,由粗到细地对输入特征进行重编码,引入更多上下文信息,进一步增强对裁图特征的学习,采用通道注意力指导语义特征的校准,可以获得更为丰富的全局关系依赖特征,促进最终决策。3)提出一个涵盖分数回归、成对比较和相关性排名的多任务损失函数,在3种不同的特征提取主干网络上性能均有提升,并在多个裁图数据集中取得了最优性能,使模型具有实用价值。
1 相关工作
1.1 美学质量评价
随着深度学习的发展,CNN对图像信息的表征能力不断增强,基于CNN的图像美学质量评价(image aesthetic assessment,IAA)也得以快速发展。IAA与图像质量评价(image quality assessment,IQA)不同,IAA关注图像内容和构图对美感的影响程度,强调主观的图像感受;而IQA则通过对图像信号进行相关特性分析,评价图像的视觉失真程度(方玉明 等,2021),强调客观影响因素。因此IQA难以预测图像内容和构图。常见构图方法如图1所示。
带有主观美学标注的图像数据集主要有CUHKPQ(Chinese University of Hong Kong photo quality dataset)(Tang等,2013)、AVA(aesthetic visual analy-sis database)(Murray等,2012)和AADB(aesthetics and attributes database)(Kong等,2016)等。基于这些美学数据集,Lu等人(2014)提出一个基于全局、局部和风格属性的CNN分类模型,用于判断图像美丑,在当时达到了较高精度。Mai等人(2016)依据空间金字塔思想,提出自适应卷积神经网络以解决输入图像形变问题,该网络可接收任意尺寸的输入,但无法进行批量训练。类似地,Chen等人(2020)直接从卷积核结构上解决了图像形变和图像长宽比构图信息的共存问题,设计了一种自适应的空洞卷积(Yu 和Koltun,2015)结构,在批量训练的同时考虑了不同纵横比图像的缩放问题。Li等人(2020)提出一种融合大众审美和人格特征的IAA模型,探索了个人偏好对个性化IAA的影响。Zhu等人(2020)基于元学习(meta-learning)方法解决个性化IAA中的小样本学习问题,有效捕捉了人们在审美判断时共同的先验知识。Sheng等人(2020)针对一系列图像处理操作(如加噪、模糊和压缩等),发现这些操作的强弱程度与图像美学质量的线性关系,从自监督学习的角度重新审视IAA问题。目前,基于美学评价的研究方法已成为自动裁图的主流方向,对同一幅图像中的不同裁图进行美学评价,相比常规的图像美学质量评价对模型的细粒度识别要求更高。

图1 不同构图方法示例Fig.1 Example images of different composition rules((a)rule of thirds;(b)rule of center;(c)rule of symmetric)
1.2 图像区域特征提取
随着深度学习在目标检测任务中的发展,产生了一系列图像区域特征提取技术。空间金字塔池化(spatial pyramid pooling,SPP)(He等,2015)和感兴趣区域(region of interest pooling,RoI)(Girshick,2015)是两个经典的区域特征提取技术。SPP采用不同粒度的金字塔将区域特征划分为不同网格,然后将所有网格进行池化合并;RoI池化则仅采用一种网格粒度,输出特征大小可由用户指定,训练更为灵活。二者都能将多尺度特征提取为固定大小的特征输出,从而不影响顶端模块(如全连接层)的执行。目前,感兴趣区域特征提取已衍生出多种方法。RoI Align(He 等,2020)和RoI Warp(Dai 等,2016)方法不同程度地提高了区域特征提取的精度,Lu等人(2019)进一步分析了RoI池化操作的利弊,提出RoI Refine方法降低精度损失。感兴趣区域特征提取模块衔接不同尺度的区域特征和最终的分类/回归层,实现了图像特征的重用,在保持较高检测精度的同时,能显著提高模型训练和测试速度。
Zeng等人(2020)认为自动裁图不仅需要考虑感兴趣区域,还应考虑裁掉区域(region of discard,RoD)。本文模型采用了相似做法。RoD池化操作是通过去除感兴趣区域的特征,通过双线性插值算法将余下特征图映射到指定大小,一般是与RoI特征相同的空间尺寸,便于后续操作。
1.3 深度视觉注意力模型
视觉注意力机制(visual attention mechanism)是一种用于提升基于循环神经网络(recurrent neural network,RNN)的编码器—解码器结构模型性能的机制,广泛应用于机器翻译、语音识别和语义分割(Yan 等,2021)等领域。近年来,注意力模型也应用于诸多视觉任务。Xu等人(2015)将注意力机制引入图像描述中,提出一个深度递归注意力模型。Chen等人(2016b)将注意力机制用于像素级别增强的语义分割任务,并自适应地选择多尺度特征。Liu等人(2018)提出PiCANet用于显著性检测任务,通过对每个像素(区域)产生丰富的上下文注意力信息,以获得更高级的语义特征,从而提高最终的检测效果。由于注意力机制赋予模型更强的分辨能力,能够模拟视觉场景中信息聚焦区域和上下文信息。本文模型针对复杂场景、多尺度特征的裁图进行设计,结合了全局和局部的区域注意力特征,裁图模型的鲁棒性有了进一步提升。
作为RNN的变体,长短期记忆网络(long short term memory,LSTM)改善了RNN梯度消失等问题,通过门控机制使循环网络不仅能记忆过去的信息,其隐含层还能选择性遗忘不重要的信息,对长期语境和远距离上下文依赖进行建模。LSTM常用于时间序列信息的编码,ReNet(Visin 等,2015)的提出使更多研究开始关注空间上下文的依赖关系,Varior等人(2016)利用空间LSTM捕捉人体各部分之间的空间依赖关系,提高行人重识别的准确度;Byeon等人(2015)和Liang等人(2016)则将类似的方法分别应用于语义分割和语义对象解析。本文模型采用空间LSTM进行全局上下文特征编码,更好地关联来自卷积层和全连接层的特征。
2 模型设计
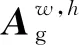
2.1 通道校准的语义特征提取模块
通道校准的语义特征提取模块旨在获取图像的高级语义特征,服务于后续操作。多项研究证明,某一领域发展较快的网络模型可以很好地迁移至其他领域当中,如图像分类(Simonyan 和Zisserman,2014;He 等,2016)任务中模型所学知识可以有效地迁移至目标检测(Girshick,2015;Ren等,2017)和图像质量评价(Zhang等,2020)等任务。通用特征提取模块耦合度低,因此本文方法能自适应主流的网络框架。对比实验表明,对于不同网络的语义特征,本文方法均能有效提升模型整体的预测结果。
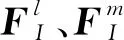
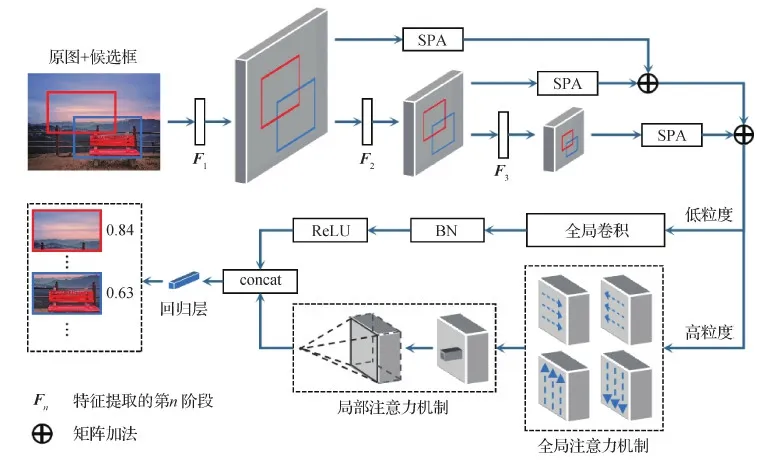
图2 本文模型DAIC-Net的整体框架Fig.2 Overall framework of the proposed DAIC-Net
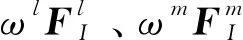
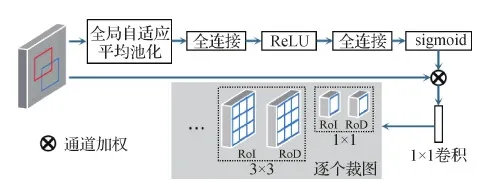
图3 通道注意力校准的区域金字塔特征提取Fig.3 Regional pyramid feature extraction with attention calibration between channels
2.2 细粒度特征聚合模块
构图规则具有复杂多样性,图1显示了三分构图、中心构图和对称构图3种最常见的构图方法。不同的构图方法需要关注不同位置上的重要信息,例如,三分构图要求人们将重要信息放在4个交点处(在摄影中也称黄金分割点),而中心构图将重要信息居中显示,凸显目标的全貌。穷举所有的构图规则是不切实际的,即便是同一种构图,物体本身也会随场景变化造成尺度不一致(Chen 等,2020)。对此,本文基于常见的构图先验知识,将ECC提取的低维多尺度语义特征进行分流组合,并行获取所有裁图的3种尺度区域特征。同时,为更好地表征学习图像构成,本文采用一种构图敏感的细粒度特征聚合(FFA)模块,即使用RoI和RoD输出多级区域特征,如图4所示。
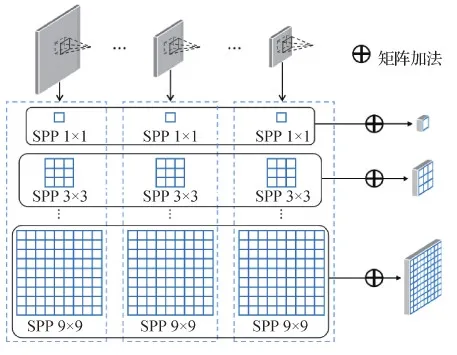
图4 细粒度特征聚合(FFA)模块Fig.4 The fine-grained feature aggregation (FFA) module
全局池化保留了全局显著特征,使模型消除了空间变化带来的不一致性,但也导致局部特征的丢失。出于对图像构成多样性的考量及受空间金字塔池化(He 等,2015)的启发,本文提出多重细粒度特征聚合方法,不同的细粒度反映并作用于不同的构图,具体为
(1)
式中,X表示同一种粒度的裁图区域特征,concat表示特征融合操作,ω表示语义特征的通道注意力权重。对于相同粒度的RoI和RoD特征,先按通道维度合并,得到16维融合特征,再对3种不同尺度的融合特征进行逐元素相加,作为上下文注意力融合模块的输入特征。本文实验使用了{1,3,5,7,9}共5种粒度的组合。
与生成单一细粒度的池化方法相比,多重细粒度特征聚合方法结合了局部和全局信息,有利于图像构成的解析,提供更丰富的鲁棒性特征,产生更好的效果。由于每种粒度均采用相同处理方式,可用并行化计算,整个过程无需增加额外训练参数。
2.3 上下文注意力融合
上下文注意力由全局注意力(global attention,GA)和局部注意力(local attention,LA)组成,由粗到细地对输入特征进行重编码,引入更多上下文依赖信息,进一步增强对裁图特征的学习。GA为输入的每个像素块产生自顶向下、自左向右的上下文区域注意力,可以获得更为丰富的上下文特征,促进最终决策;LA提取局部细粒度特征,将上下文特征转化到分数回归层的输入空间。
2.3.1 全局注意力机制
GA的初始输入为同一种粒度的裁图区域特征X∈RN×16×k2,N表示候选裁图集合的大小,K∈{1,3,5,7,9},需要产生像素级别全局特征,即提高每个区块像素的感受野。本文采用双向长短期记忆网络(bi-directional long short term memory,BiLSTM)(Graves等,2013)代替传统RNN,分别处理上下左右4个方向的序列数据,通过横向和纵向交替扫描,混合4个方向的上下文信息,每个像素的信息传播至其他像素,同时存储来自任意方向的上下文信息。对于细粒度为k的裁图区域特征图上任一位置(w,h),特征编码产生注意力权重向量αw,h∈RN×k2,将所有k×k个像素产生的注意力权重与初始输入特征内积,转化为全局注意力特征。计算为
(2)
式中,xi∈RN×16表示N个裁图在第i个位置上的细粒度特征,⊙表示哈达玛乘积。输出的全局注意力特征与原始输入特征大小相同。
2.3.2 局部注意力机制
以(w,h)为中心,LA只关注其局部区域内的相邻特征,即局部特征块Xw,h∈RW×H×16,W×H为每个位置的感受野大小。本文使用全卷积层进行裁图分数回归,为便于处理,采用全卷积操作进行局部注意力特征提取。首先,将多层W×H大小的卷积核应用于输入特征,以细粒度k=9为例,采用4个3×3的卷积核,输出通道数分别是16、32、64和768,随着输出特征尺度降低至1,最后采用3层权值共享的1×1卷积降维,输出预测分数。
消融实验表明,并非所有细粒度特征都需要计算GA和LA。细粒度较低的特征本身包含了全局空间信息,同时也会限制LA的局部特征块数量,因此,为降低计算复杂度,实验中仅对细粒度最高的特征进行上下文特征转化,如图2所示。其他细粒度特征则采用全局卷积、批归一化层和ReLU激活函数操作处理,得到一个与LA输出相同维度的特征图,所有细粒度特征融合后输入到由两个全卷积层组成的分数回归层,最终预测每个候选框的美学分数。
2.4 损失函数
考虑到分数回归的特殊性,本文提出基于多任务训练的裁图评分模型,总体损失函数由3种损失函数加权求和得到,具体为
Ltotal=ω1LR+ω2LP+ω3LC
(3)
式中,LR为分数回归损失函数,LP为成对比较损失函数,LC为相关性损失函数,ω1、ω2和ω3为各项损失的均衡化权重。
2.4.1 分数回归损失
光滑L1损失因对异常值的鲁棒性而广泛应用于目标检测的回归问题(Ren等,2017),结合平方误差损失和线性误差损失的优点,使训练过程更加稳定。本文使用光滑L1损失用于裁图分数回归,具体为
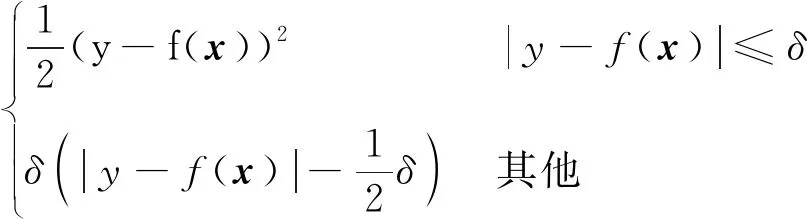
(4)
式中,δ是超参数,本文在所有实验中设置δ=1,y是真实分数,f(x)是模型的预测分数。
2.4.2 成对比较损失
成对比较(pairwise comparison)思想广泛应用于排序问题,通过打擂方式,设计一个针对列表中的元素进行两两比较的模型,最终实现排序。本文采用成对比较思想,引导模型学习更具有区分度的特征,使得裁图之间的分数差距更符合人的主观评价。对于同一幅图像中的任意一对候选裁图x1和x2,假设预期前者的真实美学分数大于后者,则可定义损失函数为
LP(f(x1),f(x2))=
max{0,f(x2)-f(x1)+g}
(5)
式中,f(x)表示模型预测分数,g是用于正则化最小间距的超参数,本文在所有实验中设置g=0.5。
考虑到穷举所有的裁图组合会大幅降低模型的效率,实验过程中,过滤裁图分数间距较小的裁图组合。由于裁图组合数量减少,模型训练过程中仅使用成对比较损失不能得到很好的效果,因此本文将该损失函数作为其他损失函数的辅助项,设置更低的权重。
2.4.3 相关性损失
尽管分数回归损失和成对比较损失对裁图分数进行了隐式排序,但裁图特征之间本身具有很强的相似性,因此本文仍采用相关性损失监督模型的训练,显式地对不同的裁图进行美学质量排名,以捕获不同裁图间的细节特征。为便于计算,采用皮尔森线性相关系数,计算为
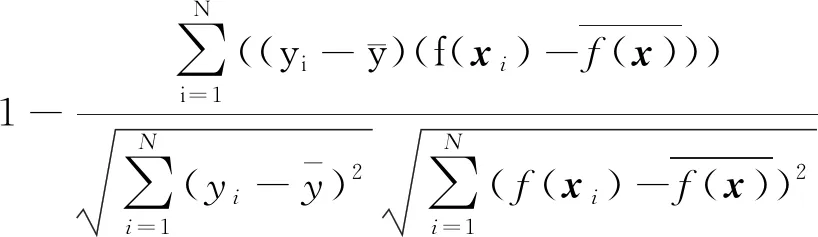
(6)
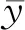
考虑到裁图的最终目标是找出构图更佳区域,因此,真实主观分数更高的裁图更受关注,模型对其也有更强的区分能力。为此,本文针对不同分数的裁图设置了不同的损失权重,最终的相关性损失为
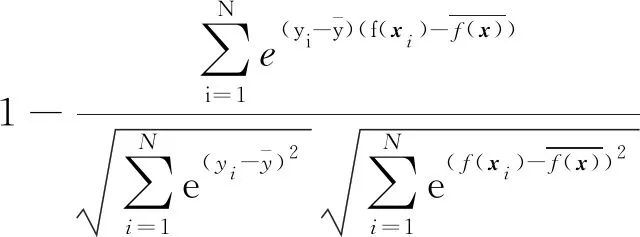
(7)
3 实验与分析
实验在Intel Core i5-3470 CPU、Nvidia GeForce GTX 1060显卡、16 GB内存的台式电脑上进行,操作系统采用Ubuntu 20.04.1 LTS,深度学习框架为PyTorch 1.6.0,CUDA和cuDNN版本为CUDA 10.2和 cuDNN v7.6.5,编程语言为Python 3.6.12。
3.1 数据集和评估指标
首先在最新公开的裁图数据集GAICD(grid anchor based image cropping database)(Zeng 等,2020)上进行实验。该数据集共3 336幅图像,划分为训练集2 636幅、验证集200幅和测试集500幅。每幅图像包含[52,90]个有效裁图,共288 069个。每个裁图都有坐标位置和平均意见得分(mean opinion score,MOS)。评估指标同样采用GAICD数据集使用的排名相关性、最佳回报率和排名加权最佳回报率3类指标。针对每幅图像的各个裁图分数及对应的模型预测分数,排名相关性指标包括斯皮尔曼相关性(Spearman’s rank-order correlation coefficient,SRCC)和皮尔森相关性(Pearson correlation coefficient,PCC),用于评估模型预测分数与实际分数之间的一致性和相关性;最佳回报率指标AccK/N,一般取K∈{1,2,3,4},N∈{5,10},共组成8种指标,衡量模型产生美学质量裁图的概率;排名加权最佳回报率指标wAccK/N在最佳回报率指标的基础上增加了排名权重,该类指标的评估更加准确和严格(Zeng等,2020)。特别地,本文还使用了平均最佳回报率及其加权指标,计算为
(8)
(9)
GAICD数据集的提出打破了经典的裁图评估方法,以往的裁图数据集只有稀疏的裁图标注,使用交并比(intersection over union,IoU)和四边偏移误差(boundary displacement error,BDE)等客观评价指标,如ICDB(image cropping database)(Yan等,2013)、FCDB(flickr cropping database)(Chen等,2017a)和HCDB(human cropping database)(Fang等,2014)等。对于每幅图像,IoU计算模型预测的裁图框与人为标注的最优裁图框之间的面积交并比,而BDE计算两者对应四条边的平均偏移量。虽然这两类评价指标具有一定的局限性(Zeng等,2020),本文仍然在ICDB和FCDB两种数据集上测试,并与其他裁图算法进行了对比实验。ICDB包含950幅图像,由3位专家标注,因此每幅图像包含3个最好的裁图,分别反映了不同标注者的主观性;FCDB包含348幅裁图测试图像,每幅图像由多人投票选出一个最好的裁图标注。
3.2 实施细节
3.2.1 基本设置
训练前对数据进行归一化处理有助于加快网络收敛并防止过拟合。首先使用ImageNet数据集(Deng等,2009)的均值和方差对输入图像的像素值进行归一化,然后将裁图的主观分数映射到零均值正态分布。模型参数均采用随机初始化,初始学习率为0.000 1,训练周期为40 epochs,学习率每15个训练周期衰减为当前的10%,最初的一个周期内采用warmup策略预热学习率(He等,2016),训练中使用自适应矩估计优化算法(Kingma和Ba,2015)对网络参数进行更新,动量为0.9,权值衰减系数为0.000 5。
3.2.2 数据增强
数据增强是一种提高模型鲁棒性、防止过拟合的有效方式。在图像分类任务中,常采用随机裁剪、随机旋转和随机翻转等数据增强操作,这些操作的出发点是使模型具有旋转不变性,有助于图像分类,缺点是会破坏图像的原始构图,不利于美学评价等主观任务。本文采用能保留构图一致性的数据增强方法(Chen等,2020),通过对输入图像进行缩放,有助于减少训练资源的开销。在训练阶段,不同于常规缩放处理(缩放到同一固定尺寸,如256×256像素),本文采用批量的随机尺寸缩放。具体地,将每个样本等比缩放,且最短边缩放到[224,416]范围内、以32为步长作为输入。实验还采用了其他对图像原始构图影响小的数据增强方法,如随机调整亮度、对比度、饱和度和色调等,以提高模型的鲁棒性。在测试阶段,通过大量实验发现,将测试图像最短边缩放至384时取得的裁图效果最佳,这与大多数图像分类任务将图像缩放至224或256不同,间接验证了图像缩放对自动裁图和图像美学评价的影响很大(Chen等,2020)。
3.2.3 训练细节
为了验证本文提出框架的通用性,测试了3种自动裁图任务中常用的主干网络(backbone)作为本文的图像语义特征提取模块,包括VGG16 (Visual Geometry Group 16-layer network)(Simonyan和Zisserman,2014)、MobileNetV2(Sandler等,2018)和ShuffleNetV2(Ma等,2018)。这3种模型涵盖了大多数现有的深度学习技术,其中VGG16采用小卷积核结构和深层堆叠方式,有效提高了模型性能,但参数量较大,对硬件要求较高;MobileNetV2和ShuffleNetV2则追求轻量化和高效率,采用了残差模块、批归一化处理和分组卷积等先进的网络优化思想。训练过程中,根据本文提出的数据增强方法,对于每种输入尺寸,通过批量训练方式以提高训练速度,通过大量实验发现,每个小批量为16幅图像时训练效果最好,当同时输入的图像很少时,预训练模型中的批归一化层参数将不再改变。本文模型只在GAICD训练集上进行训练,从每幅图像预定义的候选裁图中随机挑选最多64个预测美学分数,相比通过滑窗预设候选裁图的方法,模型的训练速度大幅提高。为了公平对比所有方法,主干网络均使用ImageNet预训练参数进行初始化,所有模型都在同一台服务器上运行,采用相同的复杂度计算方法。
3.3 消融实验与分析
为了验证细粒度特征聚合(FFA)模块的有效性,本文在GAICD数据集上进行消融实验,结果如图5所示。可以看出,随着细粒度的增加,各项指标呈上升趋势,相比于单一细粒度,多重细粒度的结果更好,其中使用5种不同细粒度特征聚合的效果最佳,客观上说明细粒度特征聚合模块使模型学习到了更多构图细节特征。
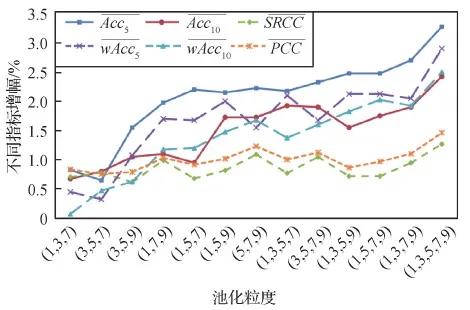
图5 不同细粒度特征组合的消融实验结果Fig.5 Ablation experimental results of different fine-grained combinations
同时,选取不同细粒度的特征图进行上下文注意力融合(CAF)模块的消融实验,以探究特征重编码的作用,验证上下文注意力融合模块对最终模型性能的影响,结果如表1所示。
实验中,模型在无任何上下文注意力融合模块的情况下,均采用全卷积回归层直接产生区域特征的分数映射。从表1可以看出,随着重编码特征的细粒度增加,模型在相关性指标上保持相当的水平,而在排名准确性指标上有明显上升趋势,这是由于特征重编码提高了模型对区域特征的判别敏感度。整体判别能力的提升对相关性指标的影响较小,较难突出其作用。但其他指标更关注排名靠前的部分候选裁图,更容易受到特征重编码的影响。
此外,损失函数在模型训练过程中也起着至关重要的作用,不同损失的叠加对模型产生不同的效果。本文研究了多任务损失函数中各分量的影响,消融实验结果如表2所示,所有客观指标结果均为ShuffleNetV2在GAICD验证集上的结果。采用网格超参数优化方法并结合实验验证,最终设置ω1=1、ω2=0.5和ω3=1。从表2可以看出,对单一损失函数,LC对排名相关性指标的提升较大,这是由于LC更加关注元素之间的关系,即便两个元素间距很小也可能产生很大的区分度。LR控制所有元素的绝对误差,使得总体误差缩小,相比LC对模型的要求更加严格,更有利于提升最佳回报率和排名加权最佳回报率指标。当LP作为辅助损失函数时,LR+LP和LC+LP对模型性能均有所提升,这是因为引入LP之后,训练的模型不仅要关注所有裁图的预测分数与真实分数的差异,还要考虑裁图与裁图之间的细微变化,显式地学习更多具有区分度的特征,进一步提高预测准确性。当同时使用3种损失函数时,模型在所有客观指标上均值最高,客观说明了模型在多项损失函数的引导下,得到的裁图效果最好。
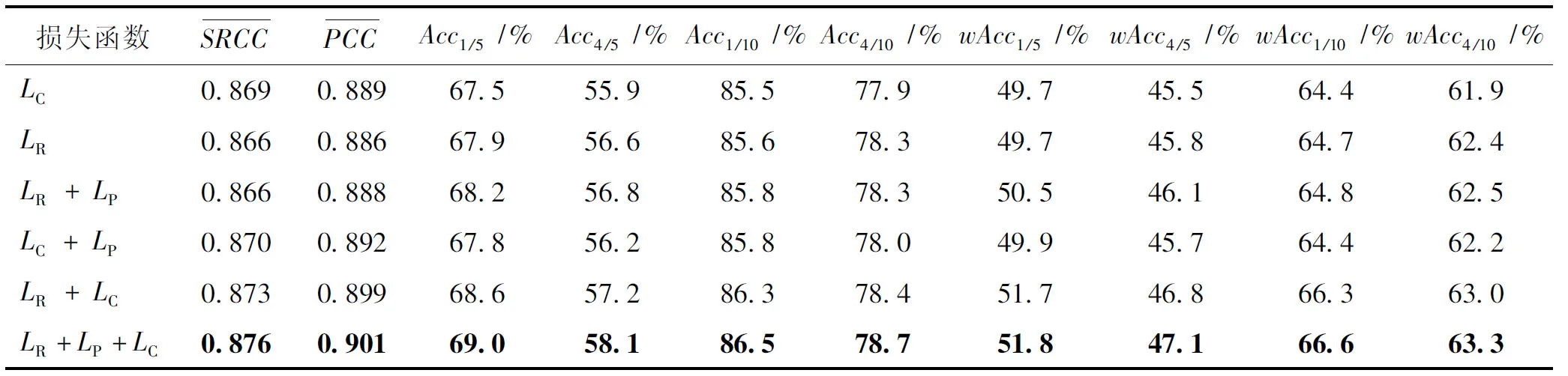
表2 不同损失函数的消融实验结果Table 2 Ablation experimental results of different loss function
3.4 对比实验与方法评估
为进一步验证本文方法的性能,选择A2-RL(aesthetics aware reinforcement learning)(Li等,2018)、VPN(view proposal net)(Wei等,2018)、VFN(view finding network)(Chen等,2017b)、VEN(view evaluation net)(Wei等,2018)、LVRN(listwise view ranking network)(Lu等,2019)和GAIC(grid anchor based image cropping)(Zeng等,2020)等6种具有代表性且可复现的裁图方法与本文方法进行对比。不同裁图方法的预测结果不同,VPN和A2-RL只能预测一个最优裁图,无法对所有裁图进行美学评分,因此只计算Acc1/5和Acc1/10两种评估指标;其他方法均可对所有裁图评分,可对比所有评估指标。
3.4.1 模型复杂度分析
本文比较了不同模型的时间复杂度和参数量,如表3所示。
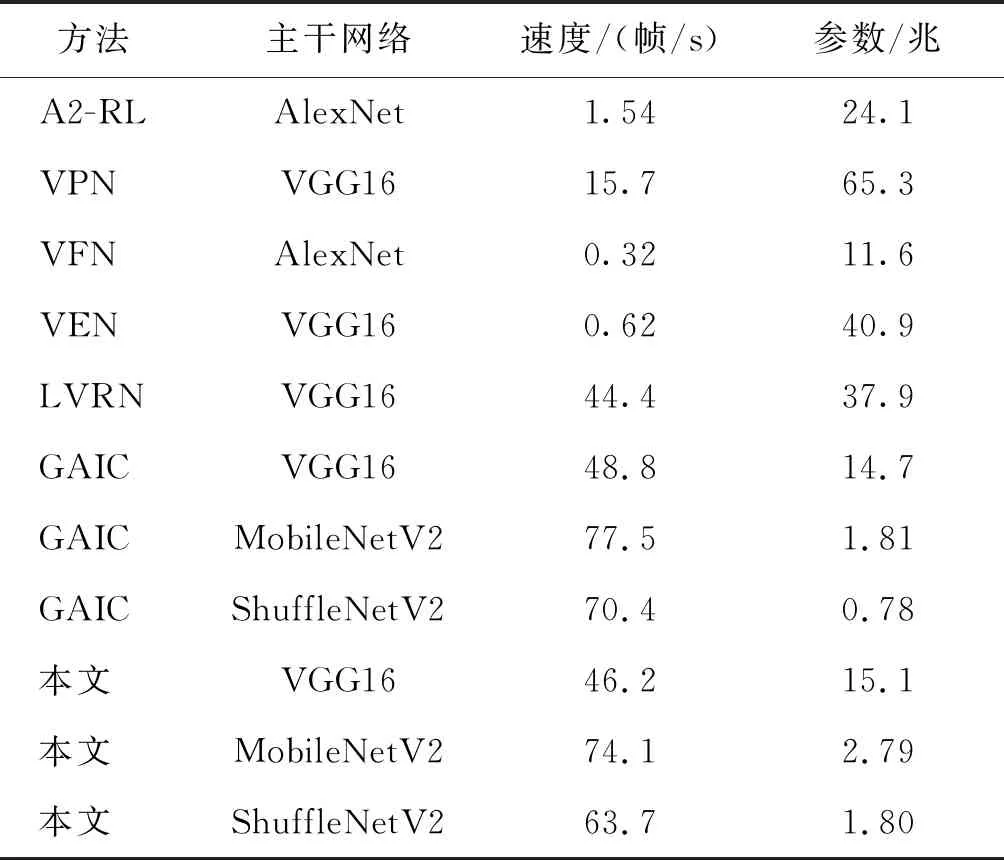
表3 模型复杂度分析Table 3 Complexity analysis of each model
由于GAICD数据集中每幅图像对应的候选裁图框均不超过90个,因而所有方法的运行效率都有提高。然而VFN和VEN需要对每个裁图端到端地运行整个网络,才能得到所有裁图的预测分数,因此复杂度会随着候选裁图框数量线性增长;VPN基于一个高效的目标检测网络,只对预设的候选框进行分类,其预测速度远高于VEN。A2-RL通过调整裁图大小进行有限次迭代优化,基于预测的美学分数计算每步的累积奖励,经少量的迭代步数即可找到模型认为的最优裁图。LVRN、GAIC和本文方法均采用区域特征提取操作,只需要对原图做一次特征提取,极大减少了冗余的前向次数。
3.4.2 主观定性分析
图像自动裁图本质上是为了改善图像的美感,最终获得美学构图最佳的裁图结果。为了比较不同方法产生的裁剪结果的主观感受,本文在几种典型场景上,对不同方法裁图的结果进行了定性比较,如图6所示。分析可知,VPN和A2-RL整体裁图效果偏差,这两种方法无法对候选裁图框进行美学评分,易造成过度裁剪。VPN容易裁剪掉图像的主要目标物体,破坏重要内容;而A2-RL对同一幅图像可能得到不同的裁图结果,有时甚至无法对图像进行任何裁剪(将原图预测为最终裁图结果)。VFN生成的裁图基本保持内容完整性,但仍无法有效地移除非重要区域,构图效果一般。VEN和LVRN具备一定的美学评价能力,裁图效果相对较好,但缺乏构图细节。实验中所有模型均使用GAICD数据集中预设的候选裁图框。由于候选裁图框的选取规则,GAIC和本文方法在部分图像上的裁图效果相近,但从一些图像的裁图结果可知,本文模型结果能够更好地保留构图特征,更符合常见的构图方法(如第1—3行)。综合以上分析,本文方法可以更有效地移除原图中的非重要区域,并产生构图更佳的视觉效果。

图6 不同方法预测的最佳裁图效果对比Fig.6 Comparison of the best crops generated by the compared methods ((a)original images;(b)A2-RL;(c)VPN;(d)VFN;(e)VEN;(f)LVRN;(g)GAIC;(h)ours)
3.4.3 客观定量分析
为了有效对比数据驱动的主流裁图方法,将本文提出的方法与其他方法进行定量对比分析,通过大量实验证明模型预测结果的有效性。
表4和表5分别是所有对比方法在GAICD数据集的验证集和测试集上的实验结果。可以看出,本文提出的3种模型相比现有最先进的模型具有更良好的预测结果。对于排名相关性指标,平均SRCC和PCC较现有方法的最好结果分别提高了2.0%和1.9%,说明本文提出的模型能更好地区分裁图好坏并排序;对于最佳回报率指标,AccK/5和AccK/10均有较大提升,平均提高2.5%,最高提升4.1%,说明模型能更好地预测美学构图最佳的裁图结果。与GAIC相比,本文方法的性能在各项指标上均有提高,且训练测试速度和运行效率与GAIC相当,这也间接证明了本文模型结构设计的有效性。
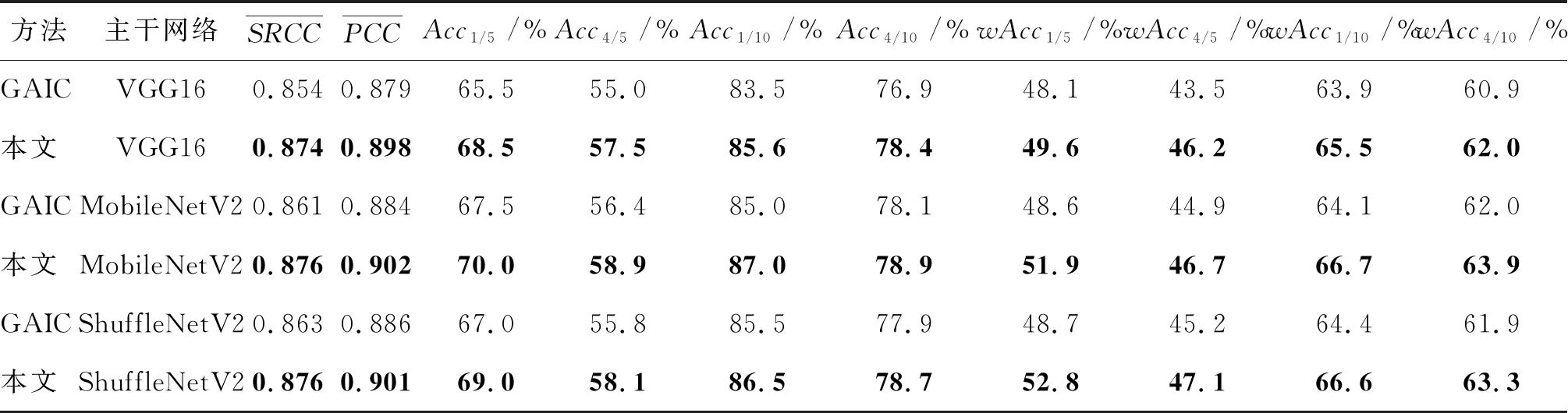
表4 GAICD验证集结果Table 4 The results on the validation set of GAICD
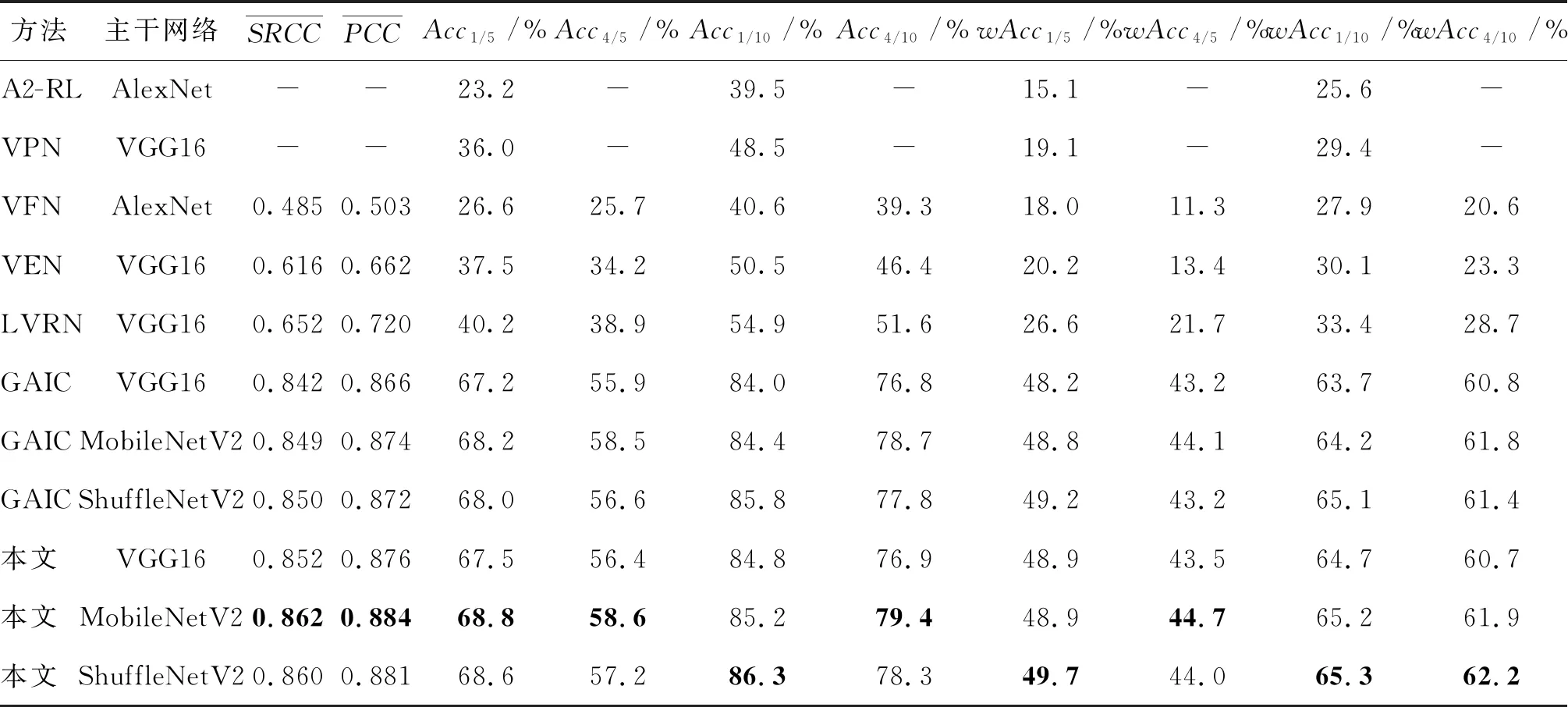
表5 GAICD测试集结果Table 5 The results on the test set of GAICD
表6是本文方法与其他方法在经典裁图数据集ICDB和FCDB上的IoU和BDE两项性能指标对比。按IoU和BDE的定义,IoU值越高,效果越好;BDE值越低,效果越好。所有方法均未使用这两个数据集的数据训练。实验结果表明,尽管本文方法在这两个数据集上的各项指标提升有限,但与现有最先进的方法相比,本文模型对大多数图像的预测结果与人为标注的最佳裁图更接近,IoU值高,BDE值小,在一定程度上反映出本文模型的裁图效果更符合人的主观审美判断。由于本文模型只在GAICD数据集上训练,跨数据集的测试结果表明本文模型具有较高的泛化性能。
3.4.4 用户主观实验
美学裁图具有很强的主观特性,为进一步验证本文所提方法在真实场景下的性能表现,进行用户主观实验。从GAICD测试集中随机挑选45幅原始图像,采用表6中的主干网络得到7种方法预测的最佳裁图结果,一轮主观实验中,邀请的15名受试者每次对7个裁图结果进行排序评分(由低到高1 5分),共评45次。每名受试者进行2轮主观实验,故一种方法的所有裁图结果共得到1 350次评分,最后统计各评分分值与对应次数占比的乘积得到加权平均分,作为7种方法的主观评分结果,实验结果如表7所示。可以看出,在所有对比的裁图方法中,本文方法能产生最符合人们主观审美的裁剪效果。由于人们在日常生活中对美的评判标准存在较大差异(祝汉城 等,2021),本文裁图方法在一定程度上能够满足大众化图像美学评价标准,但对精确到个体的审美偏好(个性化美学评价)仍然存在局限性。
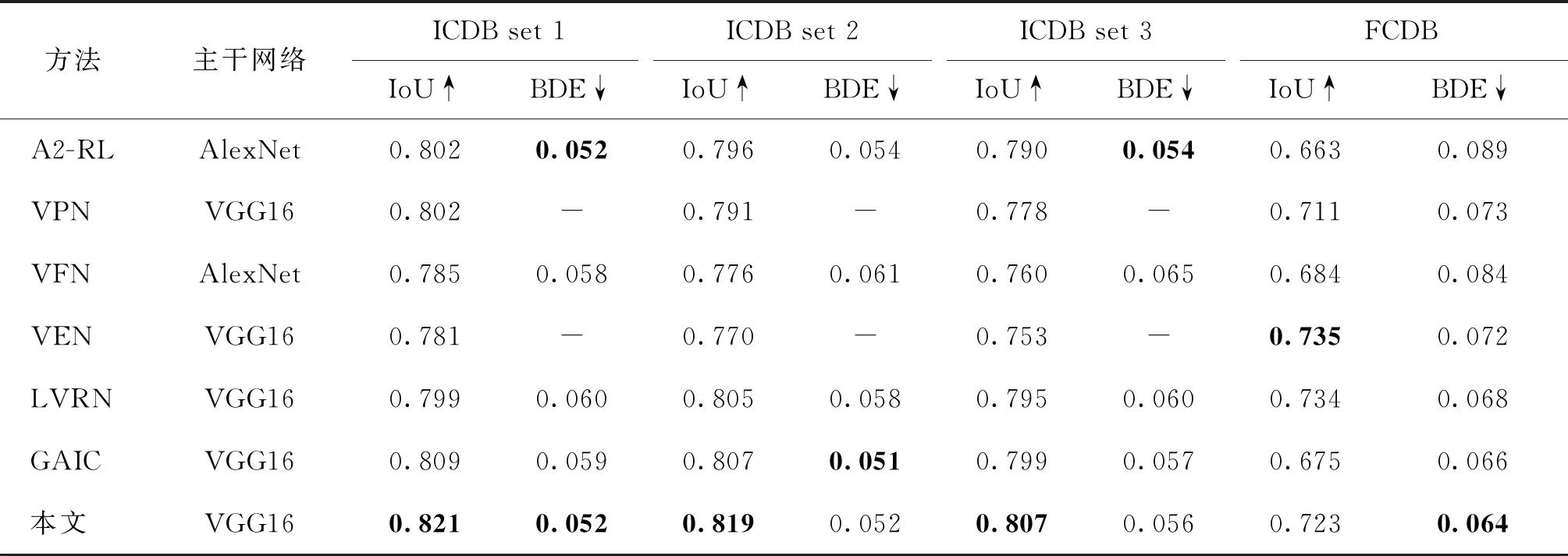
表6 不同方法在ICDB和FCDB数据集上的IoU和BDE指标比较Table 6 Comparison of IoU and BDE on the ICDB and FCDB datasets among different methods
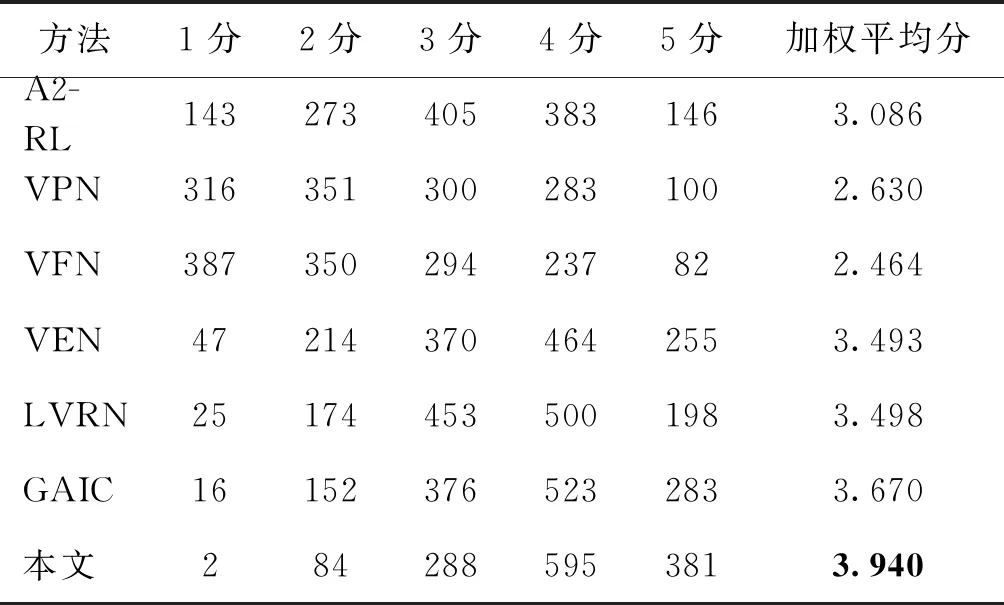
表7 不同方法的用户主观实验Table 7 User study to validate each method
4 结 论
本文提出一种聚合细粒度特征的深度注意力自动裁图方法DAIC-Net,基于空间金字塔思想和深度视觉注意力机制,逐级增强多尺度区域特征,融合全局和局部注意力特征,由粗到细地增强上下文语义信息表征。DAIC-Net主要由通道校准的语义特征提取、细粒度特征聚合和上下文注意力融合模块组成。通道校准的语义特征提取模块用于获取图像的深度语义特征,细粒度特征聚合模块增强互补语义信息并产生富含图像构成和空间位置信息的特征表示,上下文注意力融合模块在此基础上引入更多关系依赖信息,进一步增强对裁图特征的学习。此外,本文定义了多项损失函数以指导模型多任务监督学习。大量实验结果验证了DAIC-Net的有效性,跨数据集测试结果进一步表明了DAIC-Net良好的泛化能力,模型预测结果与专家标注结果更为接近。
但是,基于美学的自动裁图任务的准确率还有进一步的提升空间。解决裁图数据不足和稀疏标注问题、提高客观评价指标合理性、减少图像形变带来的精度损失,以及结合多任务训练策略进一步提高模型性能、基于个性化美学评价方法的候选裁图框生成策略等,都是未来的研究方向。
