利用隐式解码器的三维模型簇协同分割
2022-02-28杨军张敏敏
杨军,张敏敏
1.兰州交通大学测绘与地理信息学院, 兰州 730070; 2.兰州交通大学自动化与电气工程学院, 兰州 730070
0 引 言
随着计算机视觉和计算机图形学中数据驱动和深度学习技术的进步,3维模型分割得到了较快发展,并广泛应用于影视动画、增强现实、生物医学和机器人研究等领域。但目前还没有完美的3维模型分割算法,主要原因是单个模型无法提供足够的几何多样性来识别有意义的部件(Chen等,2009;Guo等,2019),且模型分割结果与人们对模型的理解密切相关。研究人员发现,受同质模型间潜在联系的影响,同时分割同类模型簇中的若干个模型,更有利于提高模型分割精度。这种将一组给定的3维模型簇分割成一致的、有意义的部件的方法,即为3维模型簇协同分割方法,广泛应用于对应关系计算、模型检索和纹理生成等领域(Huang 等,2019)。近年来,许多用于分割的深度神经网络(deep neural networks,DNN)得到了快速发展,而用于协同分割的研究相对较少。因此,基于DNN探索3维模型簇的协同分割是当前计算机图形学和计算机视觉领域极具挑战性且意义深远的研究内容之一。
激光点云作为最具代表性的3维数据,为刻画3维现实世界和提高场景理解效率提供了最直接的表达方式。然而在大型图像数据集处理方面表现出色的卷积神经网络(convolutional neural network, CNN)无法直接处理点云数据,所以目前3维点云模型分割主要依赖专门设计的可处理原始点云的网络或通过体素化CNN和多视图CNN方法进行(牛辰庚 等,2019)。自PointNet(Charles等,2017)提出以来,研究直接处理3维点云模型,实现模型识别分类、语义分割及部件分割的深度学习网络结构层出不穷,但由于点云数据缺乏拓扑及表面信息,且存在大型数据集标注困难等问题,导致网络无法以部件重构的方式实现高效的模型簇协同分割。
协同分割方法致力于寻求对整个模型簇的结构理解和规划,受Isola等人(2017)和Park等人(2019)的启发,遵循人们基于部件进行物体识别的观念,并考虑到多视图方法由于遮挡、光照及投影角度等影响导致的分割不稳定问题,本文选择对点云数据进行体素化处理,提出了一种利用隐式解码器(implicit decoder, IM-decoder)的无监督3维模型簇协同分割方法。主要创新点和贡献有:1)使用分层表面预测(hierarchical surface prediction,HSP)法对模型进行采样,以平衡3D-R2N2(3D recurrent reconstruction neural network)(Choy等,2016)及TL-embedding(Girdhar等,2016)等预测方法导致的体素模型分辨率低和网络处理高分辨率模型引起的高成本问题;2)利用在点坐标上Lipschitz连续的隐函数构建一个特殊解码器,以高效学习模型的部件表示;3)加入注意力模块自动学习重要的局部特征,在减少模型参数量的同时减少信息丢失。
1 相关研究工作
基于标记数据的可用性,3维模型簇协同分割方法分为有监督分割和无监督分割两类(Li等,2018),介于二者之间还衍生出半监督分割及弱监督分割方法。其中,有监督分割方法通常能获得较好的分割结果,结合深度学习可进一步提高此类方法的分割性能。Kalogerakis等人(2010)提出了一种在3维网格中同时分割和标注部件的数据驱动方法,将目标函数表述为从一组带标记的训练网格中学习的条件随机场(conditional random field, CRF)模型,主要通过利用CRF模型中的单数据项区分网格中面片的几何相似度,而利用成对数据项区分分割边界及其内部,获得了较好的分割结果,但此方法需要大量带标签的训练数据,且对测地线距离有较大的依赖性。van Kaick等人(2011)引入一种基于部件对应的模型分割方法,首先对一组预先分割的标记模型进行训练,提取对应的先验知识,然后将先验知识与基于匹配模型之间几何相似性的内容驱动分析相结合,能够获得较为准确的分割结果,但是受低级特征描述符的影响较大,分割性能不稳定。
上述方法均需对每个语义部件进行标注,不仅烦琐耗时且标注成本极高,所以在深度学习框架中将注意力机制引入3维模型无监督或弱监督协同分割中是非常有必要的。与有监督分割方法相对的是无监督协同分割方法。Huang等人(2011)提出一种基于整数二次规划的无监督协同分割方法,首先使用线性规划松弛法求解整数二次规划,然后采用块坐标下降法(block coordinate descent,BCD)进行一系列约束优化来解决全局最优问题,最后通过联合优化单个分割模型与组中其他模型的一致性实现3维模型簇的协同分割。在PSB(princeton shape benchmark)数据集上的实验表明,该方法的分割效果明显优于单体模型分割技术,但是分割结果依赖于最初计算的Patch, 如果某个分割部件没有被Patch很好地捕获,那么就不会出现在最终的分割结果中,这将导致整体的分割准确率下降。Shu等人(2016)提出一种无监督算法自动分割单个3维模型或协同分割一簇3维模型。其协同分割部分并没有使用DNN,而是将分割过程严格限制在自动编码器学习部分,在一定程度上节省了训练时间,但该阶段无法自动辨别特征的重要性,因此即使有足够多的低层几何特征,也无法保证一定有好的分割结果。Tulsiani等人(2017)提出使用少量的原始部件(长方体)近似一个复杂的3维模型,进而利用简化模型间的一致性实现模型簇协同分割的无监督方法,可通过施加重构损失使长方体组件更接近原始模型以获得较优的分割结果。然而由于长方体无法表示复杂的和非凸的几何模型,所以此方法对网络分割性能的提升具有一定的局限性。杨军等人(2018)提出了一种基于拓扑持续性和热亲和度矩阵的3维模型分割方法,该方法可在给定分割部件数的情况下,自动选取显著特征点从而得到恰当的分割边界。但此方法所获取的分割边界有时存在锯齿,需要进一步优化。半监督学习介于监督学习与无监督学习之间,可在使用少量标记样本和大量未标记样本的情况下完成分割任务。此外,针对分割任务中某些标签信息量不足的问题,弱监督分割方法应运而生。Muralikrishnan等人(2018)提出一种标签驱动的半监督3维模型簇协同分割方法,其网络模型通过一个预定义的标签集进行训练,可获得较为精细的分割结果,但适用场景有限。Zhu等人(2020)提出一种用于3维模型簇协同分割的弱监督方法CoSegNet,以一簇未分割的3维点云模型为输入,通过迭代最小化组一致性损失(group consistency loss)生成模型部件标签,并结合一个预先训练好的部件优化网络进行细化和去噪,可获得理想的分割性能,但在异质3维模型分割方面还有较大的提升空间。综上所述,有监督学习方法分割精确度高,但需要大量带有准确语义标签的数据集;弱监督分割方法依赖预定义的标签集,对新模型的处理存在一定的局限性;无监督分割方法对初始参数的设置及初始阶段分割的依赖性较高。为此,本文以实现高精度3维模型自动分割为主要研究目标,对利用IM-decoder的无监督3维模型簇协同分割方法进行探索。
2 点云数据体素化及模型特征提取
体素是图像像素的自然延伸,允许将最先进的技术从图像处理迁移到模型处理(杨军 等,2019)。现阶段图像处理技术已相当成熟,然而利用深度学习技术进行3维模型簇协同分割的研究极少,这也是本文选择将点云数据体素化的主要原因。体素化操作中每个数据点都是一个3维观测点,由其位置、颜色强度和法向量等信息组成。体素化操作首先要定义一个包含3维观测点的常规3维网格,将3维网格中的每个单元表示为体素域。由于3维输入中的大部分空间是空的,并没有关联的特征,所以需要设置一个通道用于表示该空间的占用率(Maturana和Scherer,2015),其中1表示非空,0表示空。点云模型体素化示意图如图1所示。
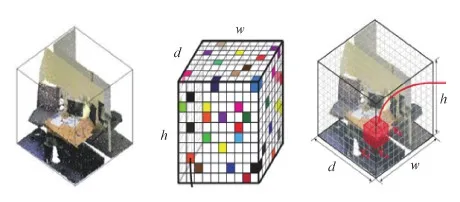
图1 点云模型体素化示意图(Maturana和Scherer, 2015)Fig.1 Voxelization diagram of point cloud model(Maturana and Scherer, 2015)
由于后续隐式模型的训练需要点值对,为了方便均匀采样,首先对模型进行体素化或栅格化是很好的选择。然而,体素表示通常受到GPU内存大小的限制,导致目前的方法只能处理低分辨率模型且计算成本较高,所以本文采用与 Häne等人(2017)类似的方法进行采样。基本原理是在靠近体素模型表面的地方采集更多的点,而忽略大部分远离模型表面的点。该采样方法可以根据分辨率和模型类别而变化,不仅加强了对高分辨率模型的处理能力,还降低了计算成本,加速了训练进程。
点云数据的特征提取是计算机可视化、数字几何处理及逆向工程等领域中的一项重要研究内容(王晓辉 等,2018),由于使用的3维点云模型被体素化为规则的数据结构,而CNN对规则数据的处理已经相当成熟,故以传统CNN为基础设计一个编码器网络,并以非线性函数ReLU为激活函数提取模型特征。具体来说,CNN通过学习对分割任务有用的局部空间卷积核,对输入级空间结构进行编码。经过多层叠加处理,网络可构建一个代表更大空间区域的层次结构,以输出一个更复杂的高级特征。CNN-encoder网络结构如图2(a)左侧框所示,主要包含3维卷积层和批归一化(batch normalization, BN)处理两个操作,二者连续5层的叠加使用可有效提取模型特征。其中批归一化处理主要是为了防止出现训练过程中数据分布不一致问题,此部分借鉴Choy等人(2016)判别器的设计思想,将其与激活函数结合使用,进一步提高了所提取特征的质量。图2(a)的右侧框是卷积神经网络的主要构成组件(神经元)根据输入和网络权值进行非线性计算的过程。
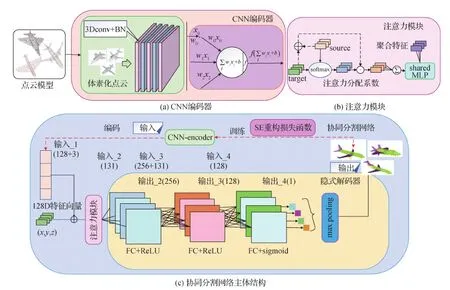
图2 3维模型簇协同分割网络结构图Fig.2 3D model cluster co-segmentation network structure diagram ((a) CNN-encoder; (b) attention module; (c) main structure of co-segmentation network)
现有研究大多使用最大池化或平均池化来集成相邻点特征,但此类方法在增大感受野的同时也会导致重要信息丢失,使分割的准确度下降,所以本文使用注意力模块来汇总相邻点特征,其结构如图2(b)所示。该模块首先将模型特征连接起来,并通过点乘操作给不同特征分配不同的注意力系数来完成重要特征的选择。表达式为
(1)
(2)
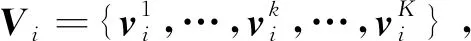
3 3维模型簇协同分割网络
为利用模型间潜在联系实现3维模型簇协同分割,本文提出以均方差(squared error, SE)损失作为重构损失函数,通过线性组合CNN-encoder和IM-decoder进行训练来学习3维点相对模型部件的内外状态。分割结果即为各个分支的部件组合。
3.1 协同分割框架结构
本文协同分割网络的核心是一组编解码器,其中解码器首先通过融合模型特征和3维点坐标增大感受野,进而对模型空间关系和3维点特征进行协同分析来完成分割任务。本文解码器与Tulsiani等人(2017)方法中的解码器相比,最大的不同在于该解码器是被分支的,每个分支学习模型簇中一个常见重复部件的紧凑表示,而其分支特性与一个Lipschitz连续的带符号距离函数(signed distance functions,SDF)密切相关,该函数可将相近的点映射为相似的输出值,进而学习一个连续的可代表一整类模型的隐式场(Girdhar等,2016)。图3为2维空间中兔子模型的SDF表示示意图,其中SDF = 0表示通过训练来区分采样点属于模型内部或外部的决策边界,SDF>0表示采样点在模型外部,SDF<0则表示采样点在模型内部。
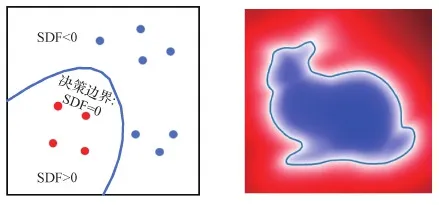
图3 SDF表示示意图Fig.3 Schematic diagram of SDF
为充分利用SDF函数的连续特性,从而得到各分支输出的准确部件对应关系,首先对于一组给定的模型S,以注意力模块的聚合特征ui和模型3维点坐标m组成的联合向量作为输入,经由MLP和激活函数的有机组合构建IM-decoder来学习fσ()以更好地逼近连续SDF,从而得到数据集中某类模型的紧凑部件表示,表达式为
(3)
式中,sj表示第i个模型样本中第j个点到模型表面的距离值(SDF值),σ为网络的训练参数,Fi(mj)表示第i个模型样本中第j个点相对某个部件的真实内外状态,ui为第i个模型的特征向量。
本文结合连续函数SDF的固有特性及空间样本的特征分布,隐式地将模型边界编码为学习函数的零点集合,同时显式地表示潜在空间的分类,最终生成的隐式场主要通过输出一个二进制值来表征对应的输入点相对模型部件的状态,表达式为
(4)
在此过程中,将点坐标附加到解码器的输入中是至关重要的,因为它为重构过程增加了空间感知,而这在CNN编码器的卷积特性中经常丢失。
图2(c)为本文网络的主体结构。IM-decoder主要通过组合使用全连接层,在模型特征和点位置的联合空间中关联信息场,由此建立模型特征空间中潜在对应关系以完成协同分析,并最终输出所学习的部件表示。在第1层,同类模型的3维点坐标和模型特征向量经由一个带梯度的线性空间分割器完成初始分割;在第2层,每个神经元线性地组合前层的场以形成基本形状,该层神经元计算的是前层神经元中值的加权和,所以前层每个神经元的变化都会带来第2层的全局变化,即每个样本的处理都会引起组合形状的改变,其间主要通过共享的权值来完成信息场的传递和关联;在第3层进一步组合各个模型样本的特征向量,并建立各个模型之间的联系,完成对输入3维模型簇的协同分析。其间需要对每个神经元进行训练,学习3维点相对各个模型部件的内外状态,在该层还对网络参数增加了一个L1正则项来避免部件重叠,进而形成不同的分支以输出其相对应的部件表示;最后使用一个最大池化层来聚合特征场,该模块可通过重构网络中不同分支的输出实现3维模型簇协同分割。此外,IM-decoder网络在模型训练过程中加入自适应矩估计优化器(adaptive moment estimation,Adam)来控制学习速度,并优化神经网络模型,以得到最优的模型簇协同分割结果。
3.2 重构损失及激活函数
由于本文网络的最终输出是各分支组合的结果,而初始的组合无法保证分割结果的准确性,故损失函数对基于深度学习方法实现3维模型簇协同分割的任务起着至关重要的作用。交叉熵(cross entropy,CE)函数和均方差SE函数是深度学习中较常见的两种损失函数,前者由于其配合输出层激活函数如sigmoid或softmax函数可加快网络收敛速度,常用于分类及分割任务中,而后者在多分类任务中可能会导致梯度消失问题的产生,故使其应用场景受到限制。然而考虑到本文网络的输出是连续的隐式场,且与CE函数相比,SE函数更适合用于回归问题,故本文选用SE重构损失函数来衡量目标模型与源模型之间的相似度,实验结果也表明将SE函数作为本文的重构损失函数效果更好,其表达式为
unsup(fσ(ui,mj),sj)=
ES~P(S)Em~P(m|S)(fσ(ui,mj)-Fi(mj))2
(5)
式中,P(S)为训练模型的分布,P(m|S)为给定模型S中采样点m的分布,E表示期望,Fi(mj)为点m内外状态的真值表示。在没有真实标签(ground truth)的情况下,该网络通过最小化模型重构损失得到用隐式场表示的最接近源模型的输出。
激活函数的选择对分割精度也有一定影响。通过实验对比,本文选择在CNN-encoder和IM-decoder的前两层使用ReLU激活函数,而在解码器最后一层使用sigmoid函数进行神经网络的去线性化操作。通常情况下,在神经网络中选择 sigmoid函数作为激活函数并不是一个很好的选择,但对于二元分类的输出层,由于其分类标签要么是0,要么是1,故可利用sigmoid函数值域在区间[0, 1]的特性,选其作为输出层的激活函数。
4 实验结果与分析
本文基于Linux Ubuntu 16.04操作系统,在配置为 Intel(R) Core(TM) i9-9900k CPU和GeForce RTX 2080Ti GPU (11 GB)处理器的图形工作站上,搭建Tensorflow深度学习框架进行实验。
4.1 实验数据集
本文在一个包含16个类别的大型数据集Shape-Net Part上进行实验,该数据集是在ShapeNetCore的基础上,对Yi等人(2016)的方法进行改进,得到包含16 881个模型的点云数据集,是3维模型部件分割常用的数据集之一,其部件注释图如图4所示。虽然目前还很少用于模型簇协同分割方法中,但随着点云数据处理技术的成熟和对3维点云模型分割方法深入探究,逐渐有学者开始基于ShapeNet Part数据集进行3维模型簇协同分割研究。
4.2 评价指标及参数设置
针对不同的分割任务选择相对应的评价指标至关重要。通常情况下,以COSEG(co-segmentation)(Wang等,2012)和PSB为目标数据集的3维模型分割方法一般选用兰德指数(Rand index)、汉明距离(Hamming distance)、分割差异(cut discrepancy)和一致性误差(consistency error)作为评价指标,而对应PartNet、S3DIS、KITTI(Karlsruhe Institute of Technology and Toyota Technolgical at Chicago)和ShapeNet Part等数据集的评估指标通常是平均交并比(mean intersection over union,mIoU)、平均准确率(mean accuracy,mAcc)和整体准确度(overall accuracy,OA)。本文选用IoU及mIoU作为分割任务的主要评价指标。IoU是训练模型对某一类别的预测分割和真实分割的交集与并集之比,mIoU主要根据每类模型出现的频率设置相应的权重,并对所有类别的加权值进行求和,最终所得的计算值越大表示模型的分割效果越好。二者的表达式为
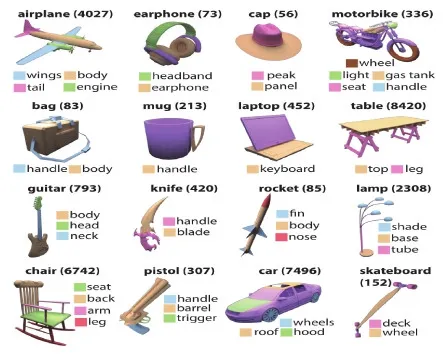
图4 ShapeNet Part数据集模型部件注释图(Yi等,2016)Fig.4 Part annotation diagrams of different shapes in ShapeNet Part database(Yi et al., 2016)
(6)
(7)
式中,z为类别数,TP表示真正,属于预测正确,指预测结果是正类,真实结果也是正类。FP表示假正,属于预测错误,指预测结果是正类,但真实结果是负类。FN表示假负,属于预测错误,指预测结果是负类,但真实结果是正类。TN表示真负,属于预测正确,指预测结果是负类,真实结果也是负类。
CNN-encoder的输入是分辨率为643的体素化模型,输出与PointNet(Charles等,2017)中融合后的点特征向量类似,为128维的特征向量。之后在分辨率为323的体素模型上采样8 192个点,并用这些点值对计算无监督损失,以优化模型分割结果。该实验结果是在初始学习率为0.000 1、动量为0.5、批尺寸为2的情况下迭代100 000次得到的。此外,在IM-decoder第3层还添加了系数为0.000 001的正则化项来避免部件重叠。
4.3 实验结果分析与讨论
本文算法在未分配标签时的分割结果如图5所示。可以看出,分割结果仅根据模型特征和3维点信息产生了初始的部件组合。由于没有任何带标签数据的指导,所以飞机模型各部件的颜色并未准确对应。此时网络无法分辨各个分支输出的部件类别,且由于每个模型的部件数未知,可能会导致网络生成较粗略的分割结果。

图5 未标记模型与其真值的对比结果Fig.5 Comparison of the unlabeled shapes with its ground truths((a)the unlabeled shapes;(b)ground truths)
模型的整个训练过程虽然是无监督的,但在测试评估阶段还是要借助标签得到最终的分割结果。鉴于ShapeNet Parts数据集中大多数模型都标记为2 6个部件,故分支总数必需大于6。为留有余量,本文将分支数设置为8。待训练完成后,首先需要可视化模型以查看分支输出,然后指定每个模型对应的分支数并手动分配标签。图6以椅子模型为例展示了可视化及标签分配过程。根据观察的可视化结果对椅子模型进行部件分组,可按顺序分为back、arm、seat和leg这4个分支,每个分支中具有最高值的点将被标记相对应的标签。
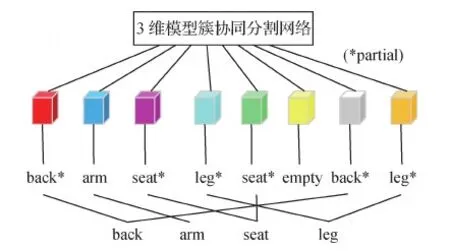
图6 椅子模型的可视化及标签分配示意图Fig.6 Diagram of chair model visualization and label assignment
4.3.1 注意力模块对模型簇协同分割的有效性
3维模型分割网络常用的最大池化虽然能减少网络参数,但同时也伴随着重要信息的丢失。与之不同的是,本文注意力模块可自动学习重要特征并保留。表1为使用不同方法聚合特征进行模型簇协同分割的实验结果,第1行最大池化表示使用最大池化学习模型特征并在各类模型上进行分割得到的IoU值,第2行注意力模块的IoU值为使用注意力模块选择重要特征所得的分割结果。可以看出,本文注意力模块对杯子、电脑等简单模型的特征聚合效果更好。在电脑模型上的分割IoU值比使用最大池化提高了2.9%,而在灯和滑板等部件差异较大模型上的分割IoU值与使用最大池化方法差不多,只有小幅提升。如在灯模型上的分割IoU值仅提高0.2%。综上所述,本文注意力模块可通过自动保留有用特征来提高网络分割性能。

表1 使用最大池化与注意力模块的分割结果的IoU对比Table 1 Comparison of IoU of segmentation results between max pooling and attention module /%
图7为使用最大池化和注意力模块进行模型簇协同分割的可视化结果。圆圈标注了不同分割方法在每类模型中的一个分割效果不好的部分。可以看出,使用注意力模块的网络对模型的细节信息处理得更好,如第1行使用不同方法分割所得的椅子模型。与使用最大池化聚合模型特征并进行模型簇协同分割的方法相比,使用注意力模块选择重要特征进行协同分割的方法能更好地提取模型的细节信息,得到界限更清晰的模型分割部件。
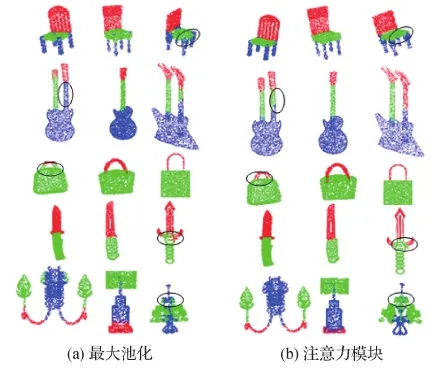
图7 使用最大池化和注意力模块时模型协同分割的可视化Fig.7 Visualization of shape co-segmentation using max pooling and attention module((a)max pooling;(b)attention module)
4.3.2 本文方法与其他方法的分割结果对比
本文方法是在完全无标签情况下训练的,因此直接与表现优良的有监督方法进行对比是不公平的,而直接进行3维点云模型簇无监督协同分割的方法极少,所以本文主要与无监督分割方法进行对比分析,同时选用部分有监督分割方法与本文分割结果进行比较。本文所用模型及其对应标准部件数分别为air(4)、bag(2)、cap(2)、car(4)、chair(4)、ear(3)、guitar(3)、knife(2)、lamp(4)、lap(2)、motor(6)、mug(2)、pistol(3)、rocket(3)、skate(3)和table(3)。本文算法(除特别说明外,均指以SE函数为本文重构损失函数)与Yi等人(2016)、Xu和Lee(2020)以及Klokov和Lempitsky(2017)的方法在ShapeNet Part数据集上的实验对比结果如表2所示。其中Kmeans和Ncut为Xu和Lee(2020)分别使用不同的聚类方法进行3维点云模型无监督分割所得的实验结果。
从表2可以看出,本文算法与上述两种无监督分割方法相比,mIoU分别提高了22.5%和18.9%,分割性能得到极大提升。本文算法利用隐式解码器进行3维模型簇无监督协同分割,相比于Yi等人(2016)根据点标签和面标签的一致性分配不同成本进行3维模型分割,Klokov和Lempitsky(2017)利用Kd-树结构构建计算图并共享可学习参数进行3维点云模型分割,mIoU分别降低了19.3%和20.2%,主要是因为Yi等人(2016)以及Klokov和Lempitsky(2017)均使用有监督分割方法,且其输入均为已标注的3维模型。本文算法使用SE函数进行模型分割的方法相比于使用CE的方法,mIoU提高了26.3%,这是由于CE函数主要刻画概率分布之间的距离,而本文隐式解码器最终的输出是一个连续的隐函数,故以适用于做线性回归的SE函数作为本文重构损失函数所得的分割效果更好。
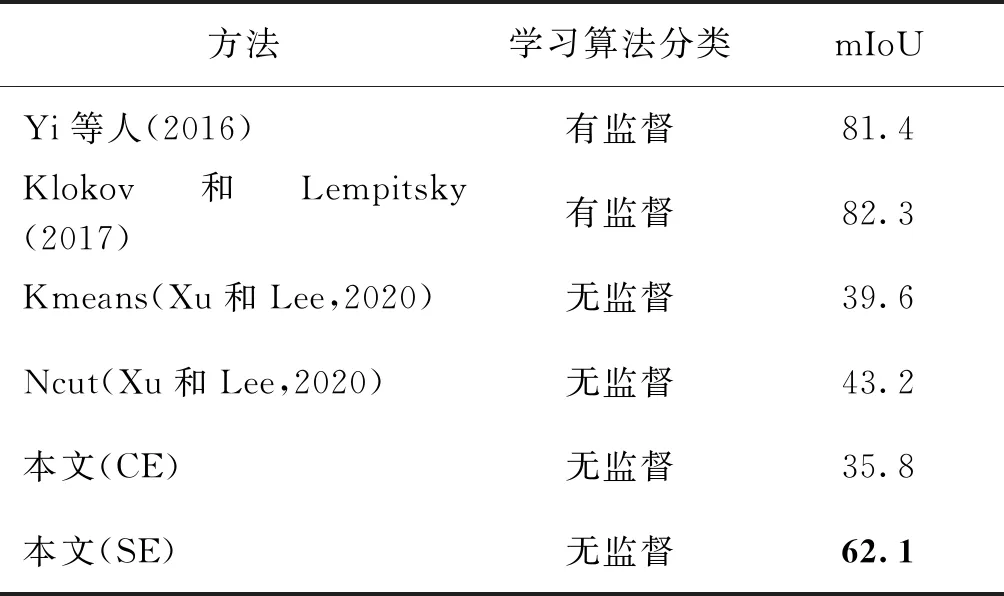
表2 本文算法与其他算法分割结果的mIoU比较Table 2 mIoU comparison of segmentation results between our algorithm and other algorithms /%
表3为不同算法在每一类模型上的IoU对比结果,模型名称下方的数字表示各类模型对应的3维对象个数。可以看出,本文算法与Xu和Lee(2020)算法直接从空间和颜色的相似性推断模型间潜在联系并使用不同聚类方法实现3维模型簇协同分割的方法相比,大多数模型的IoU值都得到较大提高,且简单模型的提升效果尤为明显,如在电脑(lap)上的分割IoU与Kmeans和Ncut两种聚类方法相比,分别提高了26.6%和18.8%,但由于本文算法对整体呈现平面式的模型重构能力较差,导致在汽车(car)、耳机(ear)和吉他(guitar)等模型上的IoU值偏低。与Yi等人(2016)及Klokov和Lempitsky(2017)的有监督分割方法相比,虽然本文算法的mIoU偏低,但在部件数较少的模型上表现优异,如对马克杯(mug)的分割,相比Yi等人(2016)及Klokov和Lempitsky(2017)的方法,分别提升了4.8%和10.0%;对包(bag)的分割,相比二者分别提高了5.3%和9.1%。而Yi等人(2016)及Klokov和Lempitsky(2017)的方法很好地体现了有监督方法的优势所在,其明显对飞机(air)、摩托(motor)和手枪(pistol)等部件数多的模型有更好的分割效果。
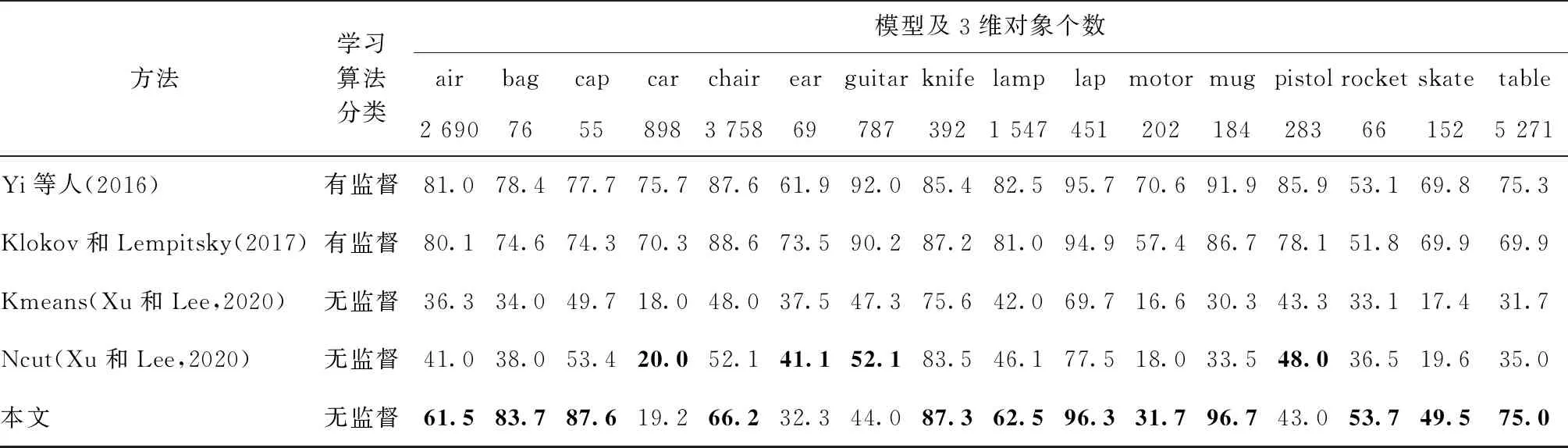
表3 不同算法在各类模型上的IoU比较Table 3 Comparison of IoU of different algorithms on various shapes /%
表4为本文算法与其他算法的分割时间对比结果。可以看出,本文与Yi等人(2016)的分割方法相比,分割效率较低,主要是因为本文算法数据预处理操作占用了部分时间。与Xu和Lee(2020)的方法相比,所用的分割时间多了12.6 ms,这是因为Xu和Lee(2020)的方法进行了数据增强操作,所以分割时间与本文算法较为接近。
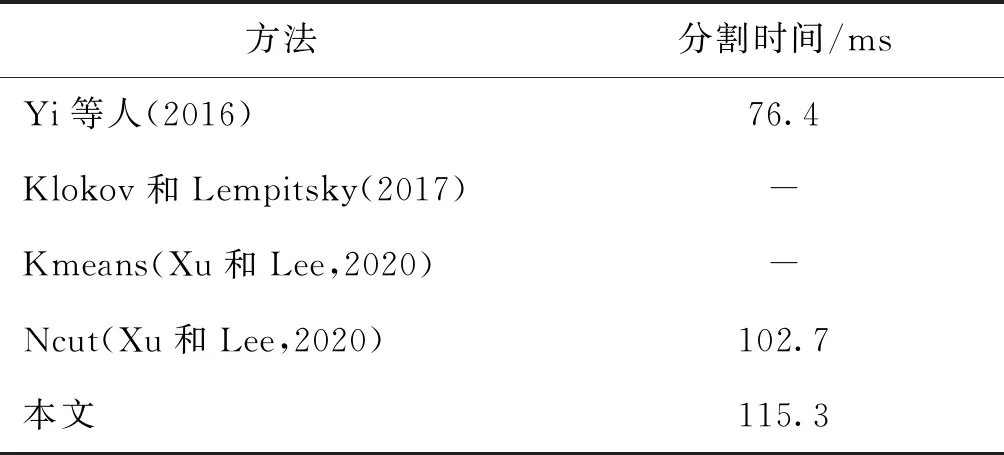
表4 本文算法与其他算法分割时间比较Table 4 Comparison of segmentation time between our algorithm and other algorithms
5 结 论
3维模型簇协同分割不仅揭示了每个模型的结构,而且反映了整个模型簇的结构对应关系,该问题的有效解决与其一致性的实现程度密不可分。为有效利用模型间的潜在联系,本文提出了利用IM-decoder的无监督3维模型簇协同分割方法。首先将体素化3维点云模型输入到CNN-encoder中,提取初始特征。然后利用注意力模块中的注意力系数进一步选择重要特征,并将所选取特征与3维点坐标相结合输入IM-decoder中。最后利用IM-decoder分别训练不同类别的模型,并将其各个分支输出的特定部件进行组合,实现3维模型簇协同分割。实验结果表明,本文算法在ShapeNet Part数据集上的模型簇协同分割表现出了良好的分割性能。然而由于本文是以无监督的方式来执行模型分割任务的,仅基于重构损失函数由IM-decoder输出分割结果往往会形成较粗的分割,不能保证初始分割产生与真实情况相同的部件数。所以将来可考虑将层次结构引入本文网络,产生一个由粗到细的分割,进一步提高分割准确率。
