嵌入Transformer结构的多尺度点云补全
2022-02-28刘心溥马燕新许可万建伟郭裕兰
刘心溥,马燕新,许可,万建伟,郭裕兰
1.国防科技大学电子科学学院, 长沙 410005; 2.国防科技大学气象海洋学院, 长沙 410005
0 引 言
3维视觉已经成为当今计算机视觉乃至人工智能领域的研究热点之一。点云(point cloud)凭借其能保持3维空间原有几何信息的优势,成为许多3维场景理解任务(目标分类、目标检测和目标分割等)的首选数据格式(Guo等,2021b)。然而实际应用中,由于物体遮挡、目标表面材料反光度差异以及视觉传感器分辨率和视角限制等原因,采集到的点云数据往往不完整,缺失部分几何和语义信息,影响后续3维场景理解任务的效果(龙霄潇 等,2021)。因此,对残缺的点云进行补全是一项重要的基础工作,是进行高效3维场景理解的前提。
传统的形状补全工作主要有几何规律补全和模板匹配补全两种方法。几何规律补全方法中,Zhao等人(2007)利用平滑插值算法来补全3维形状中的缺失部分。Mitra等人(2013)识别输入形状中的对称轴和重复结构,以便利用对称性和重复性规律进行形状补全。模板匹配补全方法中,Li等人(2015)通过将输入形状与形状数据库中的模型进行匹配以实现补全操作。这些传统形状补全方法要求输入必须是尽量完整的,即对形状的残缺度有一个较高的下限要求,并且对新物体和环境噪声的鲁棒性较差。
3维点云补全工作大多利用深度学习的方法。PointNet(Charles等,2017a)是将神经网络直接作用在点云数据上的开创性工作,其采用具有置换不变性的池化操作,解决了输入点的排列不变性问题。PointNet++(Charles等,2017b)则在PointNet的基础上增加了采样和邻域聚合操作,使得网络更好地提取物体的局部信息。Achlioptas等人(2018)首次将深度学习方法应用到点云补全任务,构建了LGAN-AE(latent-space GAN autoencoder)网络模型。该网络模型在自编码器的基础上加入了生成对抗网络(generative adversarial networks,GAN)模块,有效地对点云进行了补全,但其解码器往往不能恢复稀有的几何结构,如带有空隙的椅背等。Yuan等人(2018)设计了PCN(point completion network)网络,其在PointNet结构和FoldingNet(Yang等,2018)的基础上提出了由粗略到精细的点云补全方法,但是无法提取物体的细微结构特征。Huang等人(2020)提出了PF-Net(point fractal network)网络结构,创新性地设计了多分辨率编码器和金字塔点解码器,并且加入了对抗损失函数,使得点云补全更加精细化。2020年,Transformer结构因其具有提取点之间相关性特征的优势,被引入到点云处理任务中。Guo等人(2021b)提出了PCT(point cloud transformer)网络结构,优化了自注意力模块,使得Transformer结构更适合于点云学习,在形状分类、部件分割等任务上取得了很好的性能。
基于上述问题和思路,本文提出了一种基于注意力模块的多尺度点云补全算法。具体贡献为:
1)提出了一种特征嵌入模块,该模块在传统点云数据采用MLP模块进行特征升维的基础上,增加了多次的最远点采样和邻域聚合操作,并将聚合前后的特征密集连接,有效地增加了模型对于点云局部特征信息的提取能力。
2)优化了点云Transformer结构并加入到点云补全任务中,通过多尺度注意力层特征提取和金字塔结构点云生成操作,构建了新颖的端到端点云补全网络,并将注意力层加入到计算对抗损失的鉴别器中,进一步提升了网络的性能。
3)本文方法在3维物体数据集ShapeNet(Chang等,2015)和ModelNet(Wu等,2015)中取得了更优的补全效果。
1 相关研究工作
1.1 基于深度学习方法的点云补全算法
基于深度学习的点云补全算法大致可以分为两类:基于体素网格的补全方法和基于点卷积的补全方法。
采用基于体素网格的方法处理点云,初衷是为了更方便地应用3维卷积神经网络(three dimensional convolutional neural networks,3D-CNN)操作。Dai等人(2017)提出的由3D卷积层组成的3D编码预测卷积神经网络(3D-encoder-predictor CNNs,3D-EPN)是体素网格法的代表,其通过体积深度神经网络和3D形状的组合来补全3维点云。Han等人(2017)提出了一种由全局结构推理网络和局部几何精化网络组合而成的新网络,全局结构推理网络结合了长短期记忆上下文融合模块,其根据输入的多视点深度信息来推断形状的全局结构,而后交由局部几何细化网络,通过体积编解码结构逐步生成高分辨率、完整的点云形状。Nguyen等人(2016)提出了一种马尔可夫随机场模型,其利用局部先验信息捕捉目标形状的局部结构,然后使用卷积深度置信网络从3D形状模板中学习残缺的点云结构。Xie等人(2020)为了解决多层感知机无法很好地获得点云的几何结构和上下文信息的问题,提出了GRNet(gridding residual network),其网络中的grid结构可以很好地捕获点云的局部信息和结构,便于进行3维卷积操作,可以使用卷积神经网络对点云的局部特征信息进行提取。
基于点卷积的补全方法始于Yuan等人(2018)提出的PCN网络。PCN直接对原始点云进行操作,而不需要任何点云数据结构的先验信息。其采用编解码网络的设计,编码器采用两层堆叠的PointNet结构,以获取输入点云并输出点云的特征向量,解码器将特征向量转换为粗略和精细的点云。PF-Net由Huang等人(2020)提出,与现有网络所不同的是,PF-Net将不完整的点云作为输入,仅输出缺失部分的点云。整个网络采用自编码器结构,通过多尺度的编码和解码,较好地提取了点云的局部信息。Wen等人(2020)提出了SA-Net(skip-attention network)网络来完成点云补全任务,其设计了一种跳跃注意力机制来有效地利用不完整点云的局部结构细节,跳跃注意力机制选择性地从不完整点云的局部区域传递几何信息,以生成不同分辨率的完整点云。
1.2 Transformer注意力机制算法
Transformer结构起源于自然语言处理领域,由Vaswani等人(2017)提出并应用于机器翻译任务。其完全抛弃了循环神经网络和卷积神经网络等结构,而仅仅采用注意力机制来进行编解码操作,取得了很好的效果,注意力机制也成为了近期的研究热点。随后Transformer结构逐步向视觉领域跨界融合,ViT(vision transformer)模型(Dosovitskiy等,2021)的提出证实了在2维图像处理中,注意力层可以不再依赖于卷积神经网络,直接应用于图像块序列的纯Transformer结构也可以很好地完成图像分类和分割等任务。Guo等人(2021a)和Zhao等人(2021)将Transformer结构应用到3维点云数据处理中,其分别设计了偏移注意力模块和自注意力模块并应用于点特征提取,在点云目标分类、场景分割中取得了当时最好的效果。
2 本文方法
2.1 网络框架
图1是本文提出的基于Tranformer结构的多尺度点云补全网络(multi-scale transformer based completion network,MSTCN) 模型整体框架。网络整体采用编码器—解码器结构,由多尺度特征提取器E、金字塔点生成器G和注意力鉴别器D3部分组成。MSTCN的输入为3个不同尺度的原始点云,然后分别送入到对应尺度的特征提取器E,生成该原始点云所对应的特征向量V。随后将特征向量V作为金字塔点生成器G的输入,输出3个尺度的生成点云。损失函数主要由生成损失和对抗损失两部分组成,生成损失由3个尺度的生成点云和与之对应的真实点云之间计算CD值(Chamfer distance)得到,对抗损失则由注意力鉴别器D计算得到。注意力鉴别器D借鉴了GAN的思想(Goodfellow等,2014),其输入为第1尺度生成点云,输出为真实(real)或虚假(fake)的二分类值。引入注意力鉴别器D是为了和金字塔点生成器G联合训练,从而间接地提高点生成器的点云补全性能。
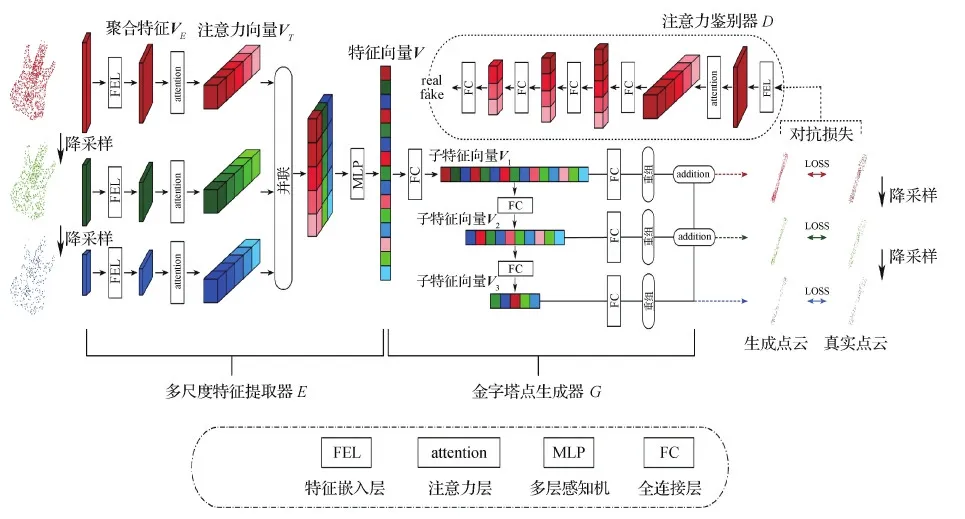
图1 基于Transformer结构的多尺度点云补全算法(MSTCN)框架图Fig.1 The framework of point cloud multi-scale transformer based completion network (MSTCN)
2.2 多尺度特征提取器E
多尺度特征提取器E的输入由3个不同尺度的原始点云组成,其点云点数分别为pnum= [N,N/4,N/8]=[2 048,512,256],其中N为原始点云点数,后两个尺度的点云由原始点云进行最远点采样(farthest point sampling,FPS)得到。然后分别依次通过特征嵌入层(feature embedding layer,FEL)和注意力层(attention),输出对应尺度的注意力向量VT,经串联后通过多层感知机(multilayer perception,MLP)得到特征向量V。
特征嵌入层(FEL)结构图如图2所示,原始点云[Batchsize,pnum,3]通过两次多层感知机(MLP)将逐点特征从3维升至64维,即[B,pnum,64]。随后网络借鉴了PointNet++(Charles等,2017b)和DGCNN(dynamic graph CNN)(Wang等,2019)的思想,依次进行采样和K最近邻(K-nearest neighbors,KNN)聚合操作,采样点数和邻域点数的设置与该尺度的原始点云的点数相适应,目的是使得网络更加具备提取物体局部特征信息的能力。同时为了避免点的绝对坐标信息给邻域聚合操作带来不利影响,将邻域聚合之后的点云特征与邻域中心点特征的差值作为初始特征,随后通过多层感知机(MLP)并与邻域聚合之前的点云特征进行串联操作,最终经过最大值池化后,输出聚合特征VT= [B,pnum/4,128]。具体计算如下
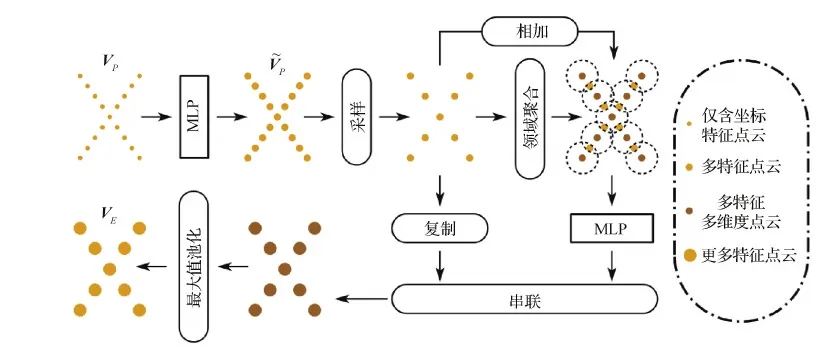
图2 特征嵌入层(FEL)结构图Fig.2 The framework of feature embedding layer(FEL)
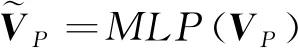
(1)
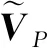
注意力层(attention)结构图如图3所示,优化了PCT(Guo等,2021a)的偏移注意力(offset-attention)方法,首先对输入VE进行线性变换,求取Query(Q)、Key(K)和Value(V)矩阵,即
(Q,K,V)=VE×(Wq,Wk,Wv)
Q,K∈RN×da,V∈RN×de
(2)
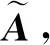
(3)
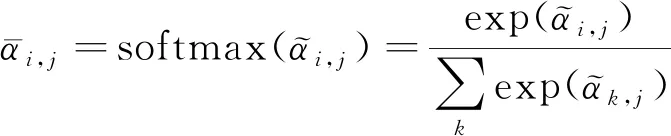
(4)
Vsa=A·V
(5)
受图卷积网络(Kipf和Welling,2017)的启发,将Transformer用于点云时,偏移注意力模块(offset-attention, OA)替换原有的自我注意力模块,可以获得更好的网络性能。具体来说,偏移注意力模块通过逐个元素之间的减法操作来计算Vsa特征和VE特征的偏差值。该偏差送入多层感知机(MLP)后与VE特征再次构成残差连接,避免训练过程中的梯度消失,经最大值池化后,完成一次attention操作。最终经多次attention操作后输出注意力向量VT,即
VT=OA(VE)=MLP(VE-Vsa)+VE
(6)
2.3 金字塔点生成器G
金字塔点生成器G以最终的特征向量V作为输入,输出为3种尺度与之前对应的生成点云,其网络架构主要由全连接层(fully connected layer,FC)和Reshape操作组成。根据以往的算法(Yuan等,2018)可以看出,全连接解码器善于预测点云的整体几何结构,但因为只是用最后一层特征来进行补全,很难提取到点云的局部结构特征。因此,本文借鉴特征金字塔网络(feature pyramid network,FPN)(Lin等,2017)和PF-Net(Huang等,2020)的金字塔逐层特征提取的思想,按照从粗略到精细的过程,逐步完成点云补全操作。
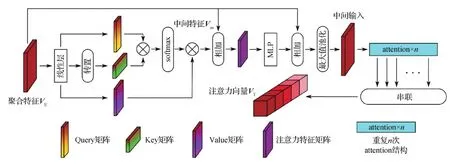
图3 注意力层(attention)结构图Fig.3 The framework of attention layer
如图4所示,将特征向量V通过全连接层,获得3个子特征向量Vi(i=1,2,3)特征维度分别为1 024,512,256,每个子特征向量负责补全不同分辨率的点云。首先利用V3预测初级点云P3(M3×3),然后用V2预测次级点云P2距离P3中心点的相对坐标,通过reshape和加法(addition)操作可以根据P3生成次级点云P2(M2×3)。同理,利用V1和P2可以预测最终点云P1距离P2中心点的相对坐标,依此补全最终点云P1(M1×3),相关示意图见图4。
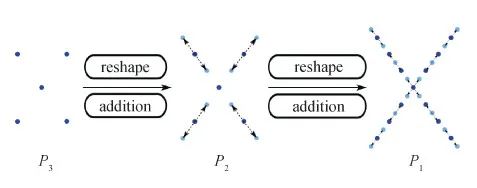
图4 从粗略到精细的点云补全过程图Fig.4 From sketchy to intact completion process diagram
2.4 注意力鉴别器D
点云补全任务隶属于生成式任务,借鉴生成对抗网络(GAN)中生成网络和鉴别网络相互促进训练的思想,本文也引入了注意力鉴别器D来提高点云补全的性能。注意力鉴别器D同样是自编码器的结构,编码器端采用了由特征嵌入层和注意力层组成的单尺度特征提取器,将生成点云P1和其对应的真实点云送入鉴别器D,经特征提取器计算后输出640维度的特征向量,随后通过连续的全连接层(FC)[640-512-256-128-16-1],最终为fake或者real的二值输出。
3 实 验
为了测试网络在不同类型数据集上的算法有效性,本文将MSTCN算法在两个公开数据集上进行了实验。这些数据集包括具有16个类别的ShapeNet数据集和具有10个类别的ModelNet10数据集。同时将本文算法与相关的点云补全深度学习方法进行对比,并完成了验证算法各模块有效性的消融实验。
3.1 数据集和实验参数设置
为训练本文模型并综合评价算法的点云补全性能,本文采用具有16个类别的ShapeNet数据集和具有10个类别的ModelNet10数据集。所有输入点云都是以原点为中心,其x,y,z三坐标数值均被规范化到区间[-1,1]内。每个完整点云均通过在每个样本上均匀采样2 048个点得到,而不完整点云则通过在预设的5个基准点中随机选择一个点作为中心,并从完整点云数据中按给定比例删除上述中心一定半径范围内的点来生成。
使用Pytorch深度学习平台,优化器选用了ADAM(adaptive moment estimation),初始学习率为0.000 1且每40轮衰减到原来的0.2倍,Batchsize设置为8,epoch设置为200,在多尺度特征提取器E和注意力鉴别器D中采用批归一化层(batch normalization)和ReLU激活函数,而在金字塔点生成器G中仅采用ReLU激活函数。在多尺度特征提取器E中,特征嵌入层(FEL)的采样与邻域聚合操作重复2次,注意力层操作重复4次。在金字塔点生成器G中,设置生成点云的点数为[M1,M2,M3]=[512,128,64]。
3.2 损失函数与评估指标
本文MSTCN算法的损失函数主要由生成损失和对抗损失两部分加权组成,生成损失用来衡量生成点云和真实点云之间的差异程度,对抗损失用来优化点云补全过程,使得生成点云看起来更加逼真。
Fan等人(2017)提出了两种比较点云之间差异的度量指标:CD和EMD(earth mover’s distance),考虑到EMD的计算量较大,本文选择CD作为点云补全性能的评估指标,即
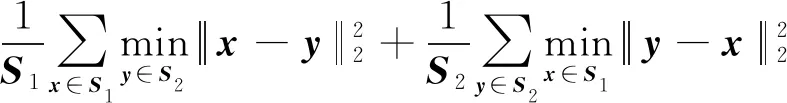
(7)
由式(7)可以看出,CD描述了生成点云S1和真实点云S2之间的平均最近平方距离,由于金字塔点生成器G有3个不同的尺度,总的生成损失也由3部分构成,dCD1,dCD2,dCD3分别计算了生成点云P1,P2,P3和与之对应的真实点云之间的CD值,总的生成损失的表达式为
Lcom=dCD1(P1,P1GT)+αdCD2(P2,P2GT)+
2αdCD3(P3,P3GT)
(8)
对抗损失的表达式为
Ladv=∑log(D(PGT))+
∑log(1-D(G(E(Pinc))))
(9)
式中,Pinc和PGT分别属于原始残缺点云和真实点云。E、G、D分别表示多尺度特征提取器、金字塔点生成器和注意力鉴别器。
总损失函数由生成损失和对抗损失两部分加权求和组成。其中α表示生成损失中的求和权重,随着训练轮次的增加,对物体精细化结构的补全要求越高,小尺度点云的训练比重越大,故本实验取α=0.01、0.05、0.1(对应epoch<30、30≤epoch<80、epoch≥80);β表示总损失函数中的求和权重,由于生成损失对于点云的补全起决定性作用,故本实验取β=0.95。
Ltotal=βLcom+(1-β)Ladv
(10)
3.3 实验结果分析
3.3.1 ShapeNet数据集
表1给出了本文算法MSTCN与现有点云补全模型的实验对比结果,评价指标包含dCD(S1→S2)和dCD(S2→S1)两部分,前者计算的是从生成点云中的每个点到其最接近的真实点云中的点的平均平方距离,它衡量的是生成点云较真实点云的差异程度;后者计算的是从真实点云中的每个点到其最接近的生成点云中的点的平均平方距离,它衡量的是生成点云覆盖真实点云的程度。
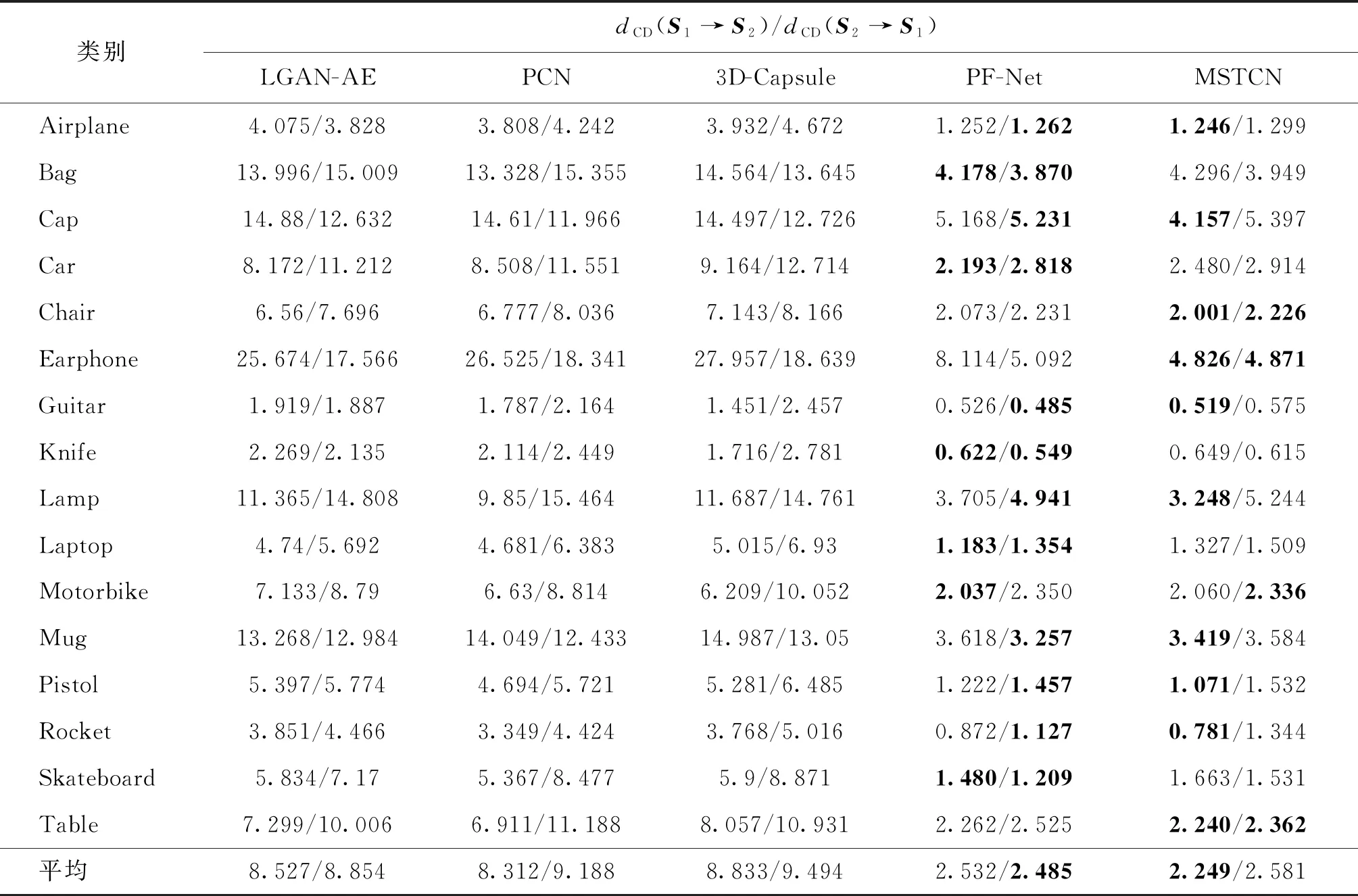
表1 本文算法与其他算法在ShapeNet数据集上的实验结果对比Table 1 Experimental results of different algorithms on ShapeNet dataset
图5给出了本文MSTCN算法与PF-Net算法在ShapeNet数据集部分类别中的可视化补全效果对比图。从图5中可以看出,MSTCN算法的优势体现在以下几个方面。
1)具有更精准的特殊结构补全能力。由图5的桌子(Table)类的补全效果图可以看出,这个桌子不同于普通的课桌,其下方有一个踏脚横梁,而残缺点云只是显示了该横梁的左边的一小段,将其进行补全操作后,PF-Net算法很好地补充上了桌面缺失的长边,但却忽略了踏脚横梁。而MSTCN算法在补全桌面的基础上,也可以有效地检测到残缺点云中左下部分突出的一小段,并将其按照踏脚横梁进行补全。相同的情况也出现在摩托车(Motorbike)这一类别的某些样本上。可以看出残缺点云缺少了摩托车的前轮,经算法补全操作后,PF-Net准确识别出前轮的缺失,但补全的前轮比后轮偏小,且没有体现出该轮胎与轴承所构成的圆环嵌套结构,反而更像是一个汽车轮胎。而MSTCN却能在识别前轮缺失的基础上,有效恢复摩托车轮胎的圆环嵌套结构。
2)面对类别中特殊样本具有更强的泛化能力。训练集同一类别中的大多样本都具有类似的结构,但也有一些样本结构特殊,因其训练样本较少,往往最后的补全效果不佳。如帽子(Cap)类的示例图,大多数的帽子都是鸭舌帽形状,其有较水平或者球面的上顶。但一旦面对如图的军官大檐帽形状,且缺失了帽子后檐,经算法补全操作后,PF-Net仍将其按照传统帽子补全了一个水平的上顶。而MSTCN虽也难以避免受大多数鸭舌帽样本的影响补全水平上顶,但其也关注到了该大檐帽缺失的倾斜上顶的后端,并尝试对其补全。同样的例子也体现在耳机(Earphone)类别中,MSTCN比PF-Net更有意识地对较宽耳机的横梁进行补全。
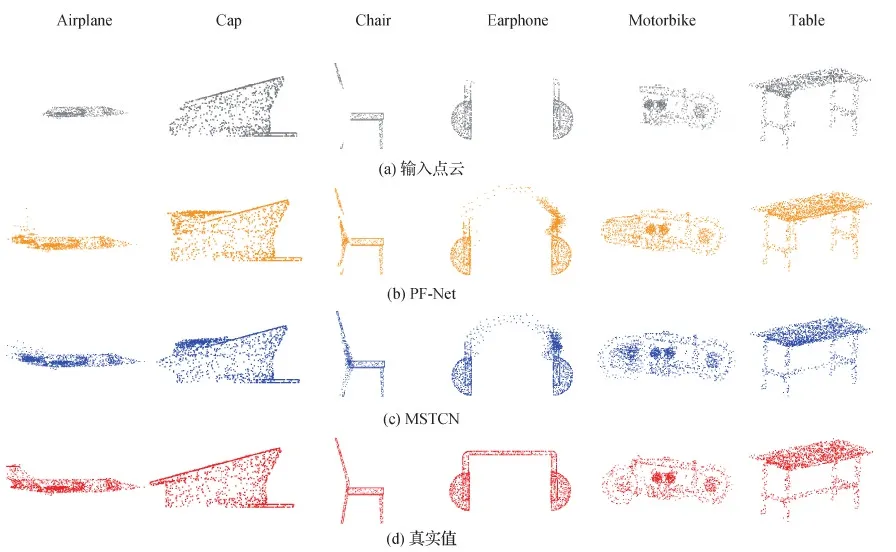
图5 本文算法与PF-Net算法在ShapeNet数据集部分类别上的补全效果图Fig.5 Comparison of the completion results achieved by MSTCN and PF-Net on some categories of ShapeNet dataset ((a) input point cloud; (b) PF-Net; (c) MSTCN; (d) ground truth)
3.3.2 ModelNet10数据集
3.3.3 消融实验
本文模型主要有特征嵌入层(FEL)、注意力层(attention)和注意力鉴别器(discriminator,D)3个模块。为了验证各模块的有效性,本文在ShapeNet数据集上进行了4组消融实验,其网络模型设置为完整的MSTCN模型和3个分别仅去除上述模块之一的对照模型。
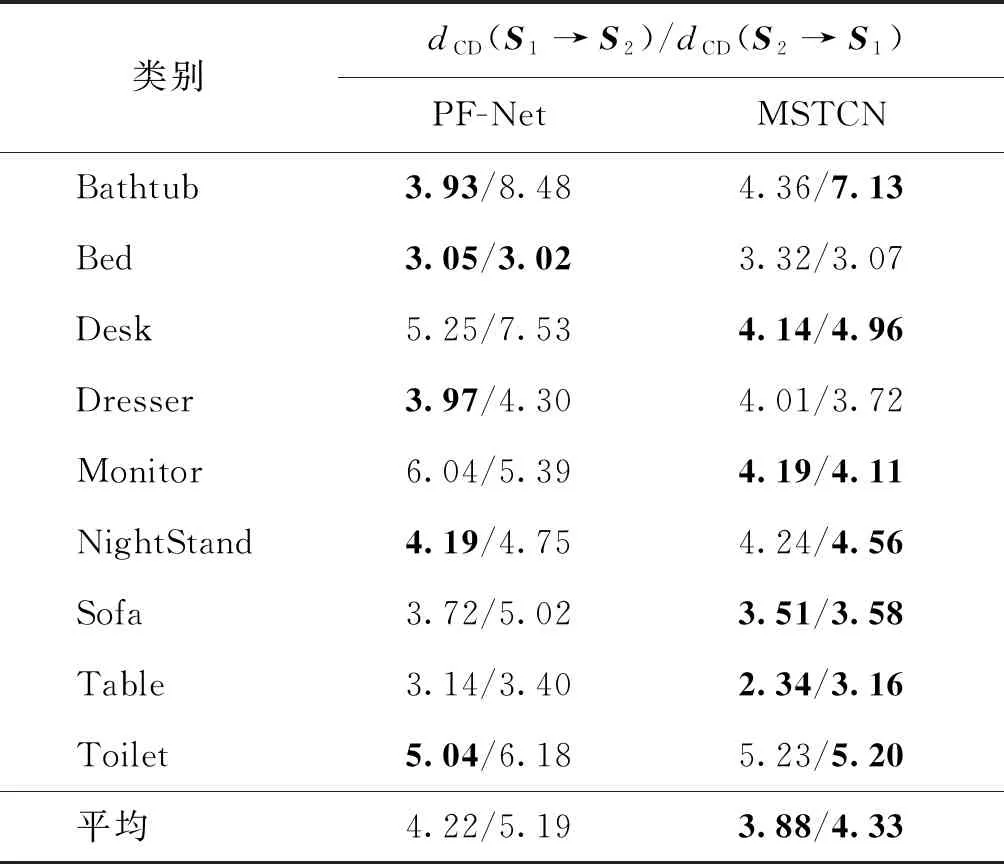
表2 本文算法与PF-Net在ModelNet10上的实验结果对比Table 2 Comparative results of MSTCN and PF-Net on ModelNet10
表3给出了消融实验的结果,图6给出了飞机类别的消融实验可视化结果图。从结果中可以看出,实验[M]取得了最低的类别平均CD值,并且是唯一补全了飞机光滑的机身和轮廓分明的左翼发动机的实验,说明完整的MSTCN模型在4组模型中具有最好的点云补全效果。
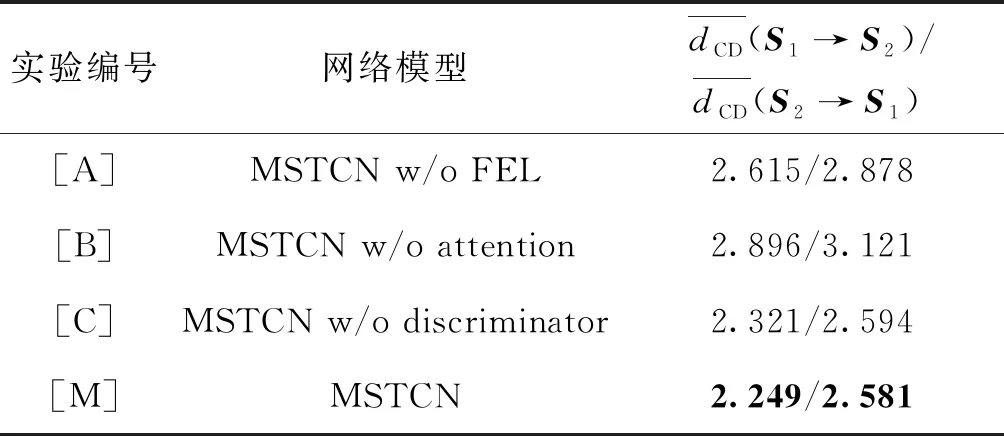
表3 消融实验对比结果Table 3 Comparison results of ablation studies
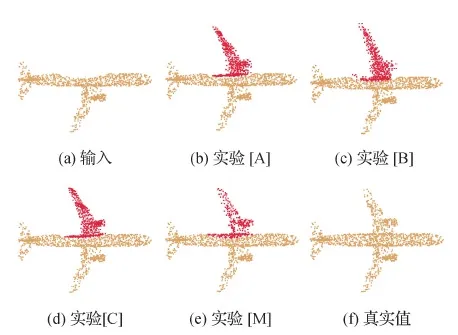
图6 飞机类别的消融实验可视化结果图Fig.6 The visualization of ablation studies of airplane ((a) input point cloud; (b) experiment [A]; (c) experiment [B]; (d) experiment [C]; (e) experiment [M]; (f) ground truth)
具体来看,实验 [A]在MSTCN的基础上去除了特征嵌入层,类别平均CD值上升到了2.615/2.878,对飞机左翼发动机轮廓的补全不够清晰,说明特征嵌入层的引入增加了模型对物体局部结构信息的提取能力。实验 [B]在MSTCN的基础上去除了注意力层,类别平均CD值激增到2.896/3.121,飞机左翼周围有“悬浮”的杂点,并且对于机身的补全也不够光滑,说明注意力层的引入可使得模型在物体补全时有选择性地参考输入点云的局部结构,比如,在补全飞机左翼时,完整且轮廓清晰的右翼就可作为很好的参考。实验 [C]在MSTCN的基础上去除了注意力鉴别器,类别平均CD值小幅上升到2.321/2.594,飞机左翼发动机补全效果较好,但机身的补全存在断层现象,说明注意力鉴别器的引入可提升网络模型的物体补全效果。综上所述,4组消融实验验证了特征嵌入层、注意力层和注意力鉴别器3个模块的有效性。
为了验证MSTCN模型对于不同缺失比例的输入点云的补全稳健性,本文在ShapeNet数据集基础上,通过改变输入点云和生成点云的点数,训练了3组针对不同缺失比例的点云补全子模型。实验结果如图7所示,选取椅子这一类别,分别给出了在不同缺失比例情况下,MSTCN模型的点云补全结果。其中25%、50%和75%表示3组输入点云相对于真实点云分别损失了25%、50%和75%比例的原始点。根据图7可以看出,虽然输入点云的点数逐渐减少,但MSTCN模型始终维持着较好的点云补全效果,其中25%和50%残缺比例的补全结果有着相近的CD值。即使缺失比例达到75%时,椅子类别的CD值也保持在2.074/2.456的较低水平,仅根据残缺的椅子腿,就可以识别并补全出完整的椅子形状。综上所述,该实验验证了MSTCN在处理不同缺失程度的输入点云时具有较强的补全稳健性。

图7 不同缺失比例点云补全稳健性测试Fig.7 Robustness test of different missing ratio of point cloud((a) ground truth point cloud; (b) 25% missing ratio; (c) 50% missing ratio; (d) 75% missing ratio)
4 结 论
本文提出一种新的点云补全框架,在自编码器结构的基础上,将Transformer注意力模块引入点云补全网络中,从而增加了各样本中点云逐点之间的相关性信息,可以更好地提取物体的局部细节特征。网络设计了多尺度并行处理结构,在编码端和解码端都按照3种分辨率来进行点云补全,提高了物体精细结构的补全效果。同时本文借鉴了GAN算法的思想,增添了注意力鉴别器,使之与点云生成器相互促进,提高了网络的点云补全性能。与多个相关的点云补全算法相比,本文算法在ShapeNet和ModelNet10两个数据集上的点云补全评估指标dCD取得了显著提升,与PF-Net算法相比分别提升了3.73%和12.75%。但值得注意的是,本文算法进行点云补全操作时,出现了局部点数过多,补全后物体局部的点云密度不一致的问题。因此设计一种新的、高效的点云间差异度评估算法,防止训练时损失函数陷入局部最优解,使得补全后的点云更加规整、光滑,将是未来点云补全的主要研究方向之一。
