类脑计算研究简述
2022-02-27陈芝协
陈芝协,王 存
(中国电子科技南湖研究院,浙江 嘉兴 314002)
0 引言
人工智能是引领新一轮科技革命和产业变革的前沿技术。在新基建的三大领域中,信息基础设施和融合基础设施两大领域都直接提及人工智能。从1956年以麦卡锡、明斯基等为首的年轻科学家首次提出了人工智能这一术语,六十多年来人工智能领域的理论和技术都得到了迅速发展,形成了符号主义(Symbolicism)、联结主义(Connectionism)和行为主义(Actionism)三大流派[1]。其中联结主义学派又称为仿生学派,在当前研究中占据主导地位。该学派认为人工智能源于仿生学,应以工程技术手段模拟人脑神经系统的结构和功能。联结主义学派从神经生物学和认知科学的研究成果出发,主张智能活动是由大量简单的单元通过复杂的相互联结和并行运行的结果。类脑计算被业内专家认为可能提供一条通向通用人工智能的途径[2],正在悄然兴起。
不少发达国家也已在布局类脑计算。美国于2013年启动“BRAIN计划”,将大脑结构图建立、类脑相关理论建模、脑机接口等列为研发重点;欧盟于2013年启动人脑计划(Human Brain Project,HBP),由洛桑理工学院统筹协调、欧盟130家有关科研机构组成,利用30个月的时间建设涉及神经信息学、大脑模拟、高性能计算、医学信息学、神经形态计算和神经机器人等6个平台,重点研究人脑模拟、神经形态计算、神经机器人等;日本于2008年提出“脑科学战略研究项目”,重点开展脑机接口、脑计算机研发和神经信息学相关的理论构建;韩国在2016年发布《脑科学研究战略》,重点开展脑神经信息学、脑工程学、人工神经网络、大脑仿真计算机等领域的研发。
我国正在积极推进类脑计算研究,在2016年国务院印发的《“十三五”国家科技创新规划》中也将脑科学与类脑研究列入科技创新2030重大项目。2017年、2018年分别成立的类脑智能技术及应用国家工程实验室、北京脑科学与类脑研究中心,形成了“南脑北脑”共同快速发展的格局。《科技部关于发布科技创新2030——“脑科学与类脑研究”重大项目2021年度项目申报指南》将类脑计算与脑机智能技术及应用作为主要的研究方向。
针对类脑计算领域,本文从技术框架、理论、硬件、软件、应用等方面展开阐述,并对类脑计算的未来进行一些思考。
1 类脑计算的概念与技术框架
1.1 概念
目前,学术界对类脑计算并没有统一的概念。有的认为类脑计算是借鉴生物神经系统信息处理模式和结构的计算理论、体系结构、芯片设计以及应用模型与算法的总称[3];也有认为类脑计算是以计算建模为手段,受脑神经机制和认知行为机制启发,并通过软硬件协同实现的机器智能[4]。分析这些观点,得出共通之处:类脑计算是借鉴脑信息处理方式,具备自主学习能力并擅于实时处理非结构化信息的新型计算智能。
类脑计算的目标是使机器能够通过类似于脑信息处理的方式实现仿生物的认知能力、学习能力和处理问题能力,最终接近、达到甚至超越人类智能水平。相较于以模型学习、数据样本为驱动的传统人工智能方法,类脑技术具有其独特的优势,分析见表1。

表1 传统人工智能方法与类脑智能的对比Table 1 Comparison of traditional AI methods and brain like intelligence
1.2 技术框架
类脑计算技术体系可分四层:理论层、硬件层、软件层、应用层,如图1所示。

图1 类脑计算技术体系图Figure 1 Brain computing technology architecture
理论层是指类脑计算相关理论,包括基础理论、计算框架、神经网络可解释原理等。类脑计算理论基于认知神经科学、计算神经科学等脑科学,研究大脑可塑性、大脑网络结构、脑图谱等大脑信息处理机制,从计算角度理解、重现这些机制,进而实现类脑智能。
硬件层主要是实现类脑功能神经形态的硬件平台,它通常采用“计算核→芯片→板卡→计算平台”的可扩展架构。而神经形态硬件平台的核心就是非冯·诺依曼架构的神经形态芯片。
软件层包含芯片工具链、系统管理软件、数据库软件、核心算法和通用技术等。工具链为芯片编程提供集开发环境、编译、汇编、链接、库函数、调试等一整套工具,是最基础的系统软件;核心算法主要是弱监督学习和无监督学习机器学习机制,如脉冲神经网络、卷积神经网络等;通用技术主要是包含多模态融合感知、目标检测与跟踪、自然语言理解、推理与决策等。
应用层主要是指类脑技术应用的产品与领域。产品包括脑机接口、脑控设备、类脑计算机、类脑机器人等;应用领域包括安防、自动驾驶、智能无人装备、智能手机等。
2 类脑计算相关理论介绍
2.1 脑科学
脑科学是研究脑的结构和功能的科学,旨在研究脑认知、意识与智能的本质与规律。脑科学研究的核心问题是人类认知、智能乃至智慧的本质以及意识的起源,包括从较为初级的感觉、知觉,到较为高级的学习、社会认知、情绪、思维与意识等各个层面的脑认知功能[5]。目前大脑在处理复杂任务时的低功耗和鲁棒性仍远超现有的人工智能系统。通过脑科学研究,认识大脑的工作原理,不仅有助于提升脑重大疾病的诊治水平,也为发展新的类脑计算理论、器件和类脑计算系统提供了重要的依据[6]。
蒲慕明(2019)指出中国脑科学未来的三大发展方向[7]:第一,理解大脑,构建大脑的图谱结构,弄清楚联接图谱、结构图谱,并在此基础上搭建各种平台,帮助解析上述图谱的功能;第二,研究脑疾病的诊断与治疗,形成各种新型的医疗产业;第三,研究类脑人工智能、类脑计算、脑机接口等与人工智能相关的新技术。
2.2 脑图谱
脑图谱一直以来都是研究脑结构和功能及脑疾病的重要手段。作为脑科学基础研究的重要战略制高点之一的脑图谱解析能够为脑疾病提供更多新的诊疗方法,也能够为未来类脑智能技术提供重要的线索和研发途径。
2016年,中国科学院自动化研究所脑网络组研究中心借助新技术,成功绘制出全新的人类脑图谱——脑网络组图谱[8],如图2所示。该图谱包括246个精细脑区亚区,不仅包含了精细的大脑皮层脑区与皮层下核团亚区结构,而且在体定量描绘了不同脑区亚区的解剖与功能连接模式,并对每个亚区进行了细致的功能描述。

图2 脑网络组图谱图Figure 2 Brain Network Diagram Spectrum
在2021年7月26日发表于《自然·生物技术》的一项研究中,毕国强、刘北明团队与国内外其他学者合作,通过自主研发的高通量三维荧光成像VISoR技术,实现了对猕猴大脑的微米级分辨率三维解析[9]。据悉,这是目前世界上最高精度的灵长类动物脑图谱,如图3所示。
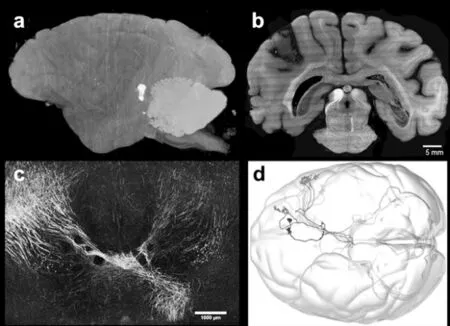
图3 猕猴大脑的三维高分辨重建图a)截面图;b)内部神经纤维展示;c)部分神经纤维的全脑示踪;d)部分神经纤维的全脑示踪可视化Figure 3 Three dimensional high-resolution reconstruction of rhesus monkey braina)Section drawing;b)Internal nerve fiber display;c)Whole brain tracing of some nerve fibers d)Whole brain tracing visualization of some nerve fibers
2.3 大脑仿真与脑仿真框架
大脑仿真就是通过计算机等方式对大脑的微观单元进行仿真建模,进而模拟更高一级的神经网络系统,乃至对整个大脑进行仿真,验证大脑工作原理的理论。
大脑仿真模拟平台是计算神经科学的实验平台,可以理解为在虚拟世界中用于实验与验证的大脑模型。同时,通过在大脑仿真模拟平台上的实现,可以进一步改良或简化模型,抽象出最为本质的大脑工作机理,并应用于其他领域(如人工智能)。
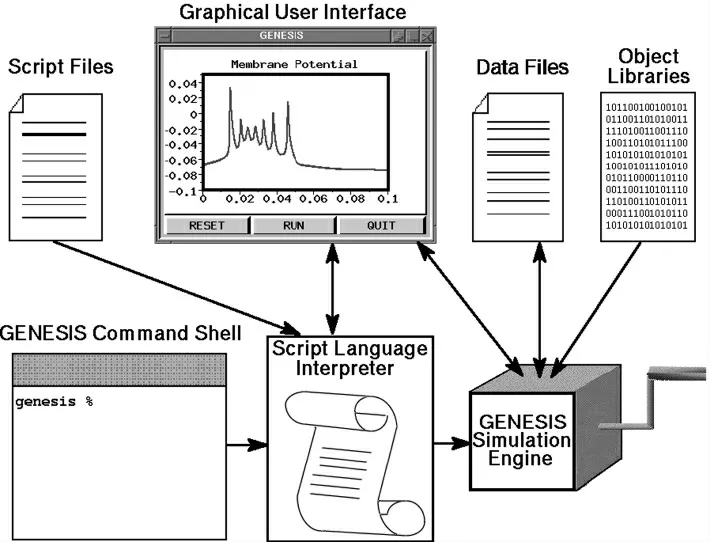
在学术界,目前的专用类脑平台对比见表2。经典的类脑仿真框架如图4所示。

图4 类脑仿真框架示意图a)NEURON的用户界面;b)Genesis全局;c)Brian的示例代码和仿真结果;d)NEST的示例代码和仿真结果;e)NiMiBrain类脑计算平台界面Figure 4 Schematic Diagram of Brain Simulation Frameworka)User interface of NEURON;b)Genesis Global;c)Brian's sample code and simulation results;d)NEST sample code and simulation results;e)NiMiBrain Brain like Computing Platform Interface

表2 目前的专用类脑平台对比Table 2 Comparison of current dedicated brain like platforms
类脑研究初创公司上海西井信息科技有限公司通过自主研发取得类脑研究重大科研成果——全球首台100亿规模“神经元”人脑模拟器“Westwell Brain”(西井大脑),如图5所示。该人脑模拟器是目前公开已知的模拟“神经元”数量最多的人脑模拟器,也是目前唯一由硬件设计完成的人脑模拟器。
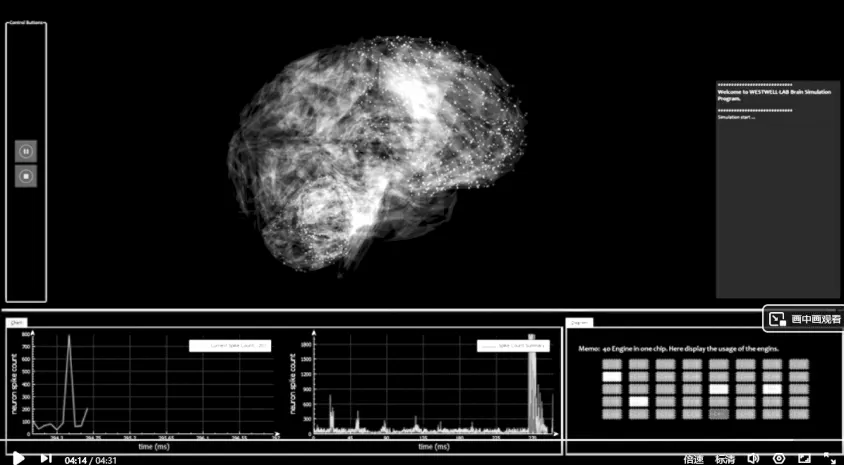
图5 Westwell Brain示意图Figure 5 Schematic Diagram of Westwell Brain
3 类脑计算芯片及其平台
3.1 神经形态芯片
神经形态芯片就是采用一种模仿人类神经系统计算框架、计算模式的芯片。其核心点是构建可以进行相互通信的计算核,单个计算核能够模拟一定数量神经元和所对应突触的功能行为。其主要由轴突输入缓存、突触权重存储器、树突输入加权积分、胞体神经元模型、神经元模型参数缓存、连接路由网络等部分组成[15],如图6所示。计算核之间、计算核与芯片之间,芯片与芯片之间均可以通过路由网络交换中间结果数据。由于每个计算核拥有独立的存储空间,芯片就可以不依赖于外部存储器,能够实现高效的并行计算和访存效率,从而实现存算一体化。
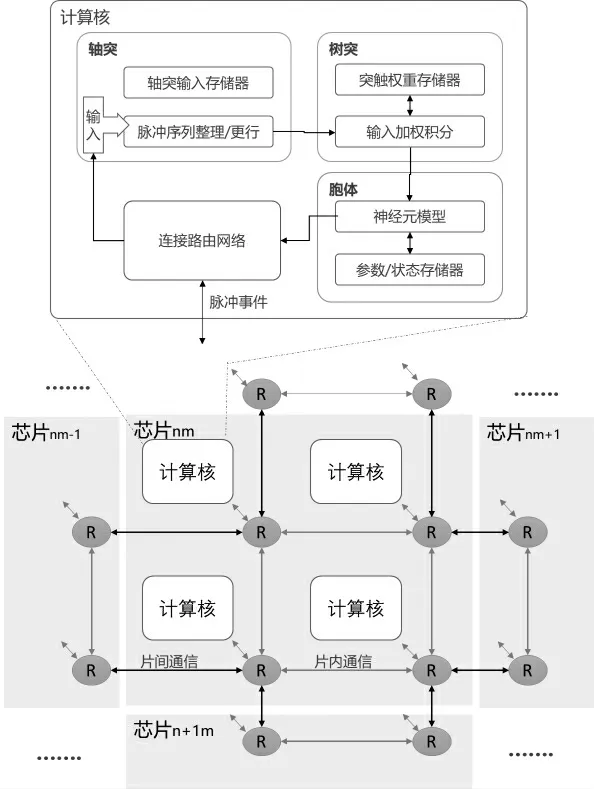
图6 典型的网格状路由神经形态芯片架构图Figure 6 Typical architecture of grid routing neural morphology chip
德国海德堡大学BrainScaleS[16]是使用晶圆级集成技术开发的混合信号神经形态芯片,可以实现比生物大脑快1 000~100 000倍的运行速度。每个晶圆包含384个模拟芯片,每个芯片可模拟大约20万个神经元和4000多万个突触。第二代的BrainScaleS芯片具备可自由编程的片上学习功能,以及拥有活动树突树的复杂神经元模型,支持非线性突触和定制结构的神经元。
IBM用三星28nm工艺技术开发了TrueNorth芯片[17]。单个芯片由54亿个晶体管组成,包含4096个计算核,每个计算核包括256个神经元和256×256尺寸的突触阵列,单个芯片实时功耗仅为70mW。TrueNorth团队还开发了硬件仿真器Compass[18],并设计了神经形态网络设计语言Corelet[19],应用于多目标跟踪识别、图像识别、语音识别、事件预测、智能避障等领域。
断路器控制回路功能:1、实时指示断路器分合闸位置状态;2、显示分合闸回路的完好性;3、当分合闸完成后,能及时断开分合闸电源;4、根据给定的整定电流值,当发生过流时,控制断路器跳闸报警。
英国曼彻斯特大学SpiNNaker[20]为SNN(Spiking Neural Network)的硬件实现提供ASIC(Application Specific Integrated Circuit)解决方案。单个芯片含有18个ARM处理器核和128兆字节的片外DRAM(Dynamic Random Access Memory)存储器,单个ARM核能够仿真近1 000个神经元。第二代的SpiNNaker芯片基于众核架构,包含144个ARM Cortex M4内核,计算速度可达到360亿条指令/(s·W)。该芯片主要应用于多尺度大脑模型的实时模拟。
美国斯坦福大学Neurogrid[21]中的计算核由256×256 CMOS (Complementary Metal-Oxide-Semiconductor)阵列构成,该阵列可实现SNN的混合模数实现。每块电路板的16个计算核通过树形路由网络进行连接。Neurogrid能够以数百万个神经元和数十亿个突触的能力提供计算能力。
浙江大学计算机学院、微电子学院及杭州电子科技大学联合研究团队于2015年研发了一款基于CMOS数字逻辑的脉冲神经网络芯片“达尔文”[22],支持基于LIF(Leaky Integrate and Fire)神经元模型的脉冲神经网络建模。2020年,该团队推出了第二代达尔文芯片,支持集成14.8万神经元和1000万突触。
瑞士苏黎世大学研究人员开发的DYNAPs[23]结合了异步数字逻辑和模拟电路,以实现模拟SNN。它的配置为单板含9块芯片,单芯片含4个计算核,单核含256个神经元。
英特尔Loihi[24]芯片,具有超过20亿个晶体管和128个计算核,能够实现13万个LIF神经元和1.3亿个突触。2021年,英特尔推出Loihi 2,其共有128个神经拟态核心,单个内核都有192kB的内存。Loihi 2拥有100万个神经元,神经元数量是第一代的8倍,处理速度是第一代的10倍,且Loihi 2每个神经元可以根据模型分配多达4096个状态,而之前的限制只有24个。
清华大学的研究人员成功设计了混合型天机芯片[25],突破了ANN&SNN融合编码技术、权重索引压缩技术、可重构神经计算核等关键技术,集成了3.9万神经元和1000万神经突触,峰值算力为1.3TSOPS(Tera Synaptic Operations Per Second)。
主要的神经形态芯片如图7所示。

图7 神经形态芯片示意图a)BrainScaleS芯片;b)TrueNorth计算核;c)SpiNNaker芯片;d)Neurogrid芯片;e)达尔文二代芯片;f)DYNAPs芯片;g)英特尔Loihi芯片;h)Tianjic芯片Figure 7 Schematic diagram of neural morphology chipa)BrainScaleSchip;b)TrueNorth computing core;c)SpiNNaker chip;d)Neurogrid chip;e)Darwin second generation chip;f)DYNAPs chip;g)Intel Loihi chip;h)Tianjic chip
3.2 类脑计算平台
类脑计算平台是采用神经形态芯片,通过模拟大脑神经网络运行,具备超大规模脉冲实时通信的新型计算机模型。它主要借鉴大脑进行信息处理的基本规律,在硬件、软件算法层面上做出变革,以期在处理复杂任务时的低功耗和鲁棒性的大幅度改进。目前的专用类脑平台对比见表3。

表3 目前的专用类脑平台对比Table 3 Comparison of current dedicated brain like platforms
德国海德堡大学为欧洲人类大脑计划构建的Brain ScaleS神经形态计算机由20个晶圆子系统级联而成,共计拥有4百万神经元和10亿突触。Brain ScaleS的类脑系统具有良好的生物可解释性和可配置性,能加快仿真速度,减少人脑仿真的实验时间。
IBM团队利用True North芯片搭建了低功耗的类脑计算系统Blue Raven。该系统处理能力相当于6400万个神经元和160亿个神经突触,能耗为40W。
2020年3月,Intel发布了Pohoiki Springs类脑系统。Pohoiki Springs是一个数据中心机架式系统,在一个5台标准服务器大小的机箱中,集成了多达768块Loihi神经拟态研究芯片,规模比以往扩展了750倍以上,同时功耗不到500W。
2020年9月,浙江大学联合之江实验室宣布成功研制出我国首台基于自主知识产权类脑芯片的类脑计算机Darwin Mouse。这台类脑计算机由3个高约1.6m的标准机柜组成,包含792颗由浙江大学研制的达尔文2代类脑芯片,支持1.2亿脉冲神经元和近千亿神经突触,与小鼠大脑神经元数量规模相当,典型运行功耗只需要350~500W。与此同时,团队还研制了专门面向类脑计算机的操作系统——达尔文类脑操作系统(DarwinOS),实现对类脑计算机硬件资源的有效管理与调度,支撑了类脑计算机的运行与应用。
4 脉冲神经网络
脉冲神经网络(Spiking Neural Network,SNN)是目前最具有生物解释性的人工神经网络,是类脑计算领域的核心组成部分[26]。SNN将脉冲神经元作为计算单元,通过脉冲序列(discrete)中每个脉冲发射时间(temporal)进行信息的传递[27],能够模仿人类大脑的信息编码和处理过程。当输入电量累积到一定阈值时,脉冲神经元发射出脉冲,实现以事件驱动的计算模式。鉴于脉冲序列的稀疏性以及事件驱动的特点,SNN具备很低的能耗比。SNN的特点如下:
①采用了生物神经元模型如IF(Integrate and Fire)和LIF等,具有更高的生物可解释性;
②信息的传递是基于脉冲序列,增加了时间概念,更有稀疏性;
③基于脉冲序列的编码,可以拥有更多的信息;
④事件驱动,SNN能耗比低。
当前,SNN领域的研究主要围绕神经元模型与脉冲编码、学习算法、编程框架、数据集以及芯片五大方向进行[15]。
4.1 神经元模型与脉冲编码
参考神经元树突、胞体、轴突等结构,一个神经元模型由输入信号、权值、偏置、加法器和激活函数构成,是一个多输入单输出的信息处理单元。脉冲神经元从模型机理上可分为4类,分别是基于电流输入输出的膜电势模型、自然信息输入模型、药理刺激模型和层级即时记忆模型。膜电势模型又分为IF(Integrated and Fire)模型、Hodgkin-Huxley模型、LIF模型、SRM(Spike Response Model)模型、分数阶LIF模型、Galves-Löcherbach模型、指数IAF模型、FizHugh-Nagumo模型、Morris-Lecar模型、Hindmarsh-Rose模型、Compartmental模型、Thorpe模型、Izhikevich模型。自然信息输入模型包括非齐次泊松过程模型、两状态马尔可夫模型、非马尔可夫模型等。药理刺激模型以突触传递模型为典型,层级即时记忆模型则是以HTM(Hierarchical Temporal Memory)模型为典型。以LIF模型为例,其电路设计示意图如图8所示。脉冲编码的作用是将原始的模拟数据通过编码方式以脉冲时间序列形式输入到脉冲神经网络中,主要有一维脉冲编码、稀疏脉冲编码、AER(Address Event Representation)脉冲编码等方法。

图8 LIF模型的电路设计示意图Figure 8 Schematic Diagram of Circuit Design of LIF Model
4.2 学习算法
类似于传统的机器学习方法,脉冲神经网络的学习算法可分为无监督学习算法和监督学习算法两大类。
无监督学习算法起源于Hebb学习规则,模拟生物突触重塑规则,通过神经元发出脉冲时间和接收脉冲时间调整突触权值,进而训练神经网络实现聚类等任务。
监督学习算法分为梯度下降学习算法、监督STDP(Spike-timing-dependent-plasticity)学习算法、基于脉冲序列卷积学习算法和基于进化脉冲神经网络的次序学习算法[26]。其中,典型的梯度下降学习算法有SpikeProp算法、RProp和QuickProp算法、多参数的梯度下降法、Multi-SpikeProp算法、OnMSGDB算法、Tempotron算法、Chronotron ELearning算法等;常见的监督STDP学习算法有ReSuMe、DL-ReSuMe、SWAT、Reservoir-Based STDP、Recurrent STDP、PBSNLR、ASA(Accurate synaptic-efficiency Adjustment)等;基于脉冲序列卷积的学习算法目前有SPAN(Spike Pattern Association Neuron)、线性代数内积方法、PSD(Precise-spikedriven)等。
虽然现有SNN学习算法众多,但在面对超大超深层的训练网络时仍会普遍出现梯度消失、算法收敛性、资源消耗大等问题。
4.3 编程框架
在SNN领域,目前有NEST、MOOSE、Nengo、Nest、Brian、CISM、SNNAP、SpyKetorch、BindsNet以及2021年9月30日开源的Lava框架等可以支持大规模SNN的构建与训练。其中,Lava在跨传统和神经形态处理器的异构架构上无缝运行,支持跨平台执行和与各种人工智能、神经形态和机器人框架的互操作性。Lava作为一个开放的、模块化的和可扩展的框架,满足了SNN对通用软件框架的需求。当前主要的脉冲神经网络编程工具对比如表4所示。
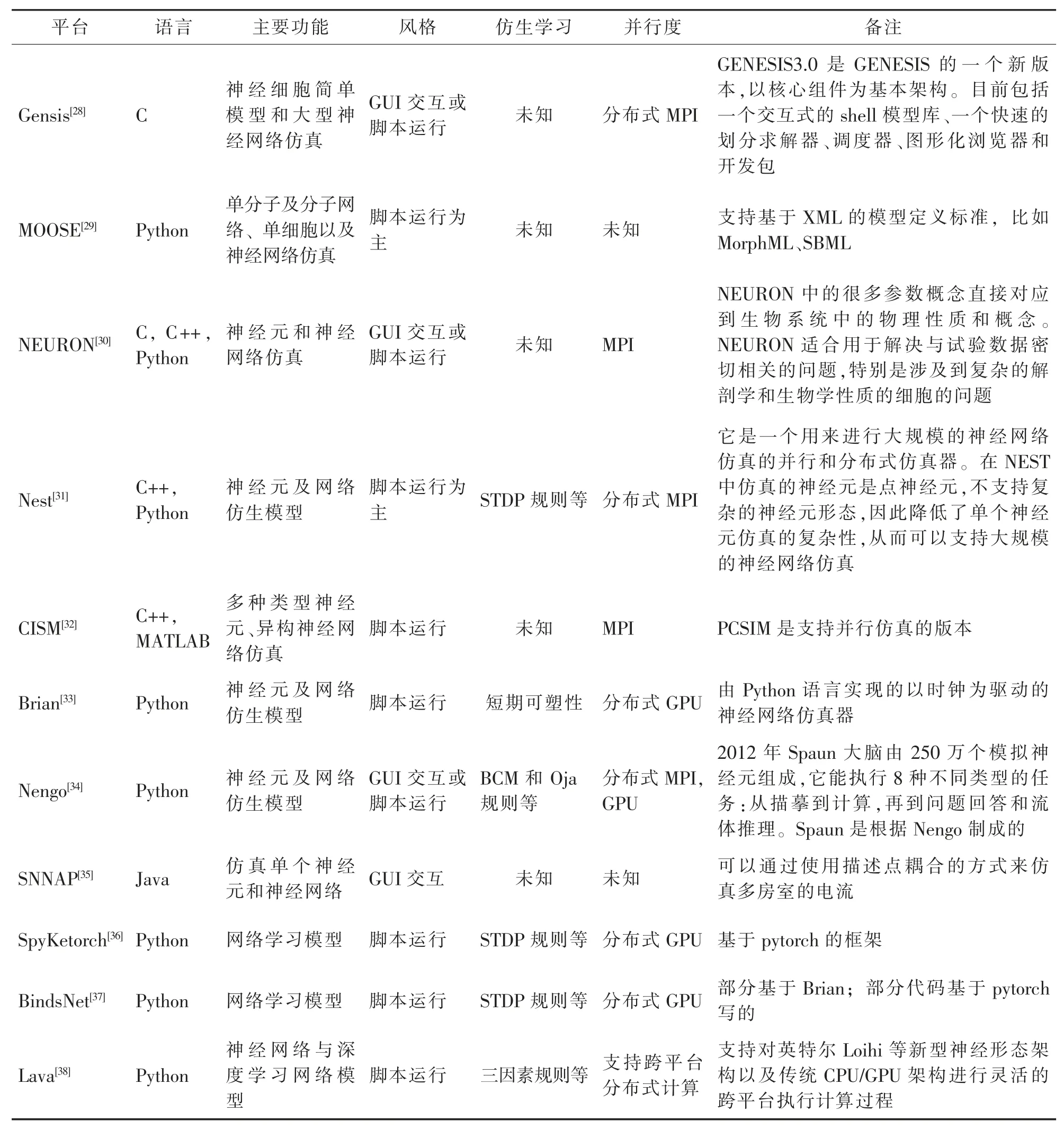
表4 当前脉冲神经网络编程工具对比Table 4 Comparison of current pulse neural network programming tools
4.4 数据集
数据集的发展对推动人工神经网络技术和深度学习的进步发挥了至关重要的作用。
鉴于脉冲神经网络的脉冲序列的稀疏性以及事件驱动特点,在构建SNN数据集时,需要收集事件驱动信息、时序特征信息,作为数据样本的数据特征。按照数据集构建方式的不同,分为3类:第一类是直接采集得到的数据集,其主要通过动态传感器直接捕捉而生成的数据集;第二类是通过转换数据集产生,即使用动态传感器对标签的静态图像数据集进行实拍而生成;第三类是对原有数据集增加模拟动态特征得到,通过算法模拟动态视觉传感器特性补充原有带标签数据集。但这3类数据集存在各自的局限性:第一类数据集的预处理方式没有统一规范,结果很难被公平地比较;第二和第三类数据集都是对原有数据集进行二次加工,可能缺乏真实的时序关联信息。
当前,人工神经网络领域有很多被认可的大规模数据集,如MNIST、CIFAR-10、ImageNet等。而目前仅有Neuromorphic-MNIST、N-Caltech101(如图9所示)、DVS-CIFAR10、DVS-Gesture等比较小的具有时空事件流信息的数据集适合于SNN。
图9 N-Caltech101示意图Figure9 N-Caltech101
5 类脑计算的应用
当前类脑计算尚未进入大规模的商业应用,更多是处于实验探索应用阶段。如Loihi芯片被多位研究者用于控制无人机和机械臂等应用,部分机器人工作负载显示,Loihi的功耗是传统解决方案的1/40~1/100。其中包括一款自适应机械臂应用,它是一种触觉感知网络,能够处理新型人造皮肤技术的输入,还有一款应用是即时定位与地图构建工作负载,简称SLAM(Simultaneous Localization and Mapping)。在大规模Pohoiki Springs系统上演示了类似的搜索操作,相比CPU实施方法,其功耗约为原来的1/45,运行速度快100多倍。Loihi还可以解决较难的优化问题,如约束满足和图形搜索,其速度比CPU快100倍,但功耗约是CPU的1/1000。
清华大学施路平团队将天机芯应用于自动驾驶的自行车,该车独立完成自平衡和识别语音命令,同时能对前方目标进行探测追踪,还能自动避障和过障。
目前,浙江大学与之江实验室的科研人员基于Darwin Mouse类脑计算机已经实现了多种智能任务。他们将类脑计算机作为智能中枢,实现抗洪抢险场景下多个机器人的协同工作,涉及到语音识别、目标检测、路径规划等多项智能任务的同时处理以及机器人间的协同。
类脑计算是借鉴脑科学的基本原理,打破冯·诺依曼架构束缚,面向人工通用智能(也称类脑通用智能)的新型计算技术,继承了大脑低功耗、高并行、高容错、存算一体、事件驱动等特征,适合实时处理非结构化复杂信息,具有超高并行、超高速、超低功耗、高鲁棒等特性。类脑计算的特点决定了它将会在特定领域发挥重要作用。Loihi运行不同任务的结果也验证了这一结论。总体而言,类脑芯片Loihi在有生物激发性的RNN(例如LASSO、1D SLAM)任务中的优势最为突出,而在标准feedforward DNN(例如Keyword Spotter DNN和Image Segmentation)任务中优势不大(或相等)。
6 结语
类脑计算是科技竞争的战略高地。经过十余年的发展,类脑计算领域在芯片、工具链和开发框架、算法等方面已经取得了不少标志性成果。在芯片方面,美国、欧洲和中国都在全力推动这项研究,英国曼彻斯特大学的SpiNNaker芯片、IBM公司的TrueNorth芯片、德国海德堡大学的BrainScaleS芯片、美国斯坦福大学的Neurogrid芯片、英特尔公司的Loihi芯片以及中国的天机芯、达尔文II、灵汐KA200等都是具有代表性的成果。在工具链和开发框架方面,目前处于百花齐放阶段。由于研究目标以及实现手段的差异,现阶段存在多种脉冲神经网络编程平台,不同的平台在对脉冲神经元生物特性的描述粒度、网络的功能支持及模拟计算效率等方面有很大差异。在类脑算法方面,当前脉冲神经网络领域尚不存在公认的核心训练算法与技术,在生物合理性与任务表现间存在不同的侧重度,以及网络采用的神经元模型和编码方式各异,均造成了训练算法的多样化。
