基于深度学习的有遮挡人脸识别方法研究
2022-02-27程晓雅
程晓雅,张 雷
(运城学院 数学与信息技术学院,山西 运城 044000)
在模式识别和计算机视觉中,人脸识别是非常重要的研究领域。人脸识别技术可实现身份识别,具有非打扰性、直接性以及唯一性的特点。目前人脸识别技术在多个领域,特别是智能家居领域被广泛应用,例如采用人脸识别认证的智能门锁。然而人脸识别技术仍存在一些问题,在实际应用中,各种不可控因素导致获取的人脸图像可能带有遮挡,特别是新冠疫情以来,人们在各种场合中佩戴口罩,对人脸识别系统的识别率造成了较大的影响[1-2]。
由于人脸特征复杂,采取人工选择匹配的方法比较困难,因此采用深度学习方法来提取人脸特征是一种理想的选择[3-4]。作为一种经典的深度学习模型,具有卷积层和池化层的卷积神经网络(Convolutional Neural Networks,CNN)在有遮挡人脸识别任务中取得了理想的效果[5]。然而,CNN仍存在不足,例如在CNN模型的训练过程中,需要获取大量的参数,从而导致计算量过大。
为解决这一问题,研究人员致力于找到一个简单的CNN模型,希望仅通过少量的参数即可实现应用。文献[6]提出了PCANet,它是一个简单的基于无监督学习的深度学习网络。PCANet使用主成成分分析(Principal Component Analysis,PCA)来学习过滤器,并部署简单的二进制哈希和块柱状图来实现索引与合并。与其他通过反向传播学习滤波器的CNN不同,PCANet使用PCA方法来学习滤波器,因此PCANet只需要较少的计算成本,以及较少的运行时间和存储空间。
PCANet使用的PCA方法基于一维向量。在应用PCA之前,需要将二维图像矩阵转换成一维向量,这将导致两个问题:(1)图像的二维结构中隐含了一些图像的空间信息。在将图像矩阵转换为一维矢量时,会忽略图像的内在信息;(2)由于一维向量较长,计算特征向量需要较长的计算时间和较大的存储空间。为了解决这些问题,文献[7~8]提出了二维主成分分析网络(Two-dimensional Principal Component Analysis Net,2DPCANet),采用2DPCA代替PCA。
然而,PCA和2DPCA均基于L2范数方法。对异常值较为敏感,因此含有异常值的数据会破坏期望方法的结果[9-11]。为了解决这个问题,文献[12]提出了一种基于L1范数的PCA方法。L1范数被认为对异常值更加稳健[13]。L1-PCA采用L1范数来测量重建误差。在此基础上,文献[14~15]提出了基于L1范数的2DPCA。
本文将L1范数引入PCANet,得到L1-PCANet,然后通过L1-2DPCA学习滤波器,产生了改进的PCANet,其和2DPCANet共享相同的结构来生成输入数据的特征。另外,本文使用支持向量机(Support Vector Machines,SVM)作为网络特征的分类器。本文分别在AR和RMFD人脸数据库上测试了所提出的基于L1范数的PCANet的识别性能,并与其他3个网络(PCANet、2DPCANet和L1-PCANet)进行了比较分析。
1 L1-PCANet
本文提出了一个基于PCA的深度学习网络L1-PCANet。为克服PCANet中由于使用L2范数而造成的对异常值的敏感性,本文使用PCA-L1替代PCA来学习滤波器。L1-PCANet和PCANet[9]共享相同的网络架构,如图1所示。
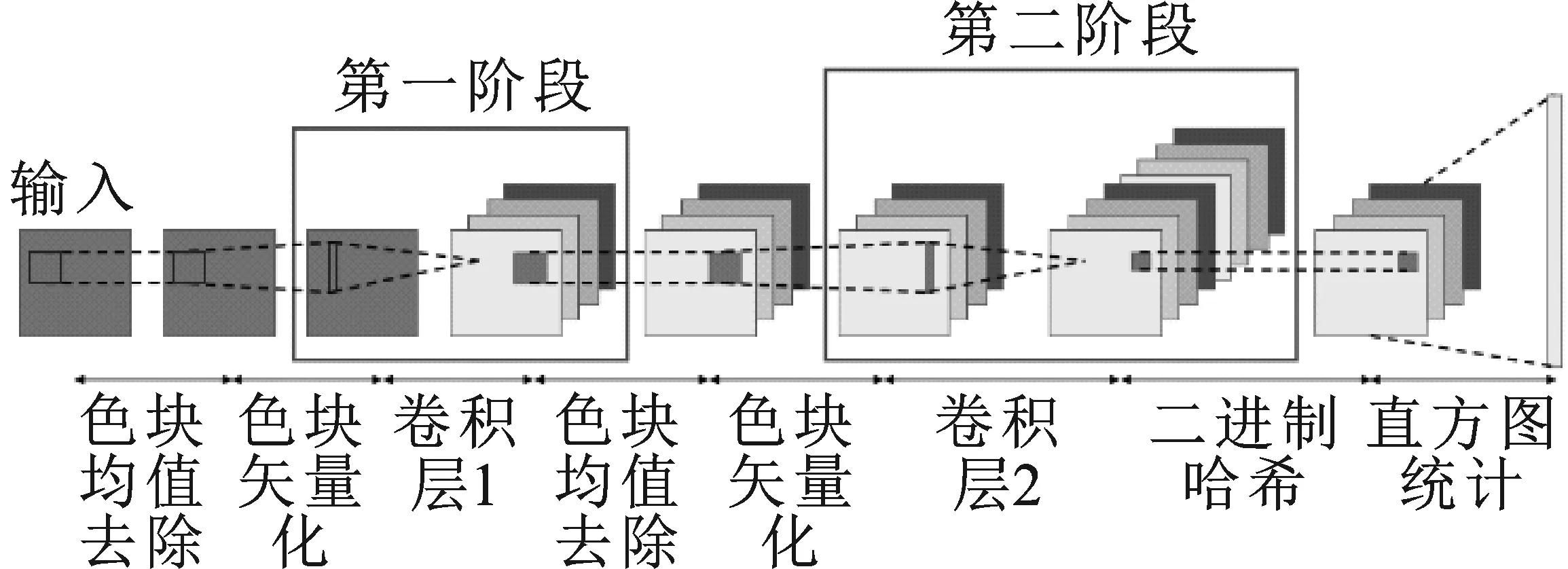
图1 两层L1-PCANet架构图Figure 1. The illustration of two-layer L1-PCANet
假设有N个训练图像Ii(i= 1,2,…,N),大小为m×n,在Ii的每个像素周围可以得到D=m×n个大小为k×k的色块。取所有不重叠的色块并映射为向量,可得
[xi,1,xi,2,…,xi,mn]∈Rk2×mn
(1)
从每个色块中删除色块均值得到式(2)。
(2)
对于所有的输入图像,构造相同的向量并将它们组合为一个矩阵
(3)
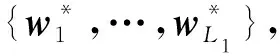
(4)
式中,p=1,2,…,L1。
第1阶段的输出可以表示为
(5)

2 改进PCANet
本文提出的改进的PCANet网络架构如图2所示。
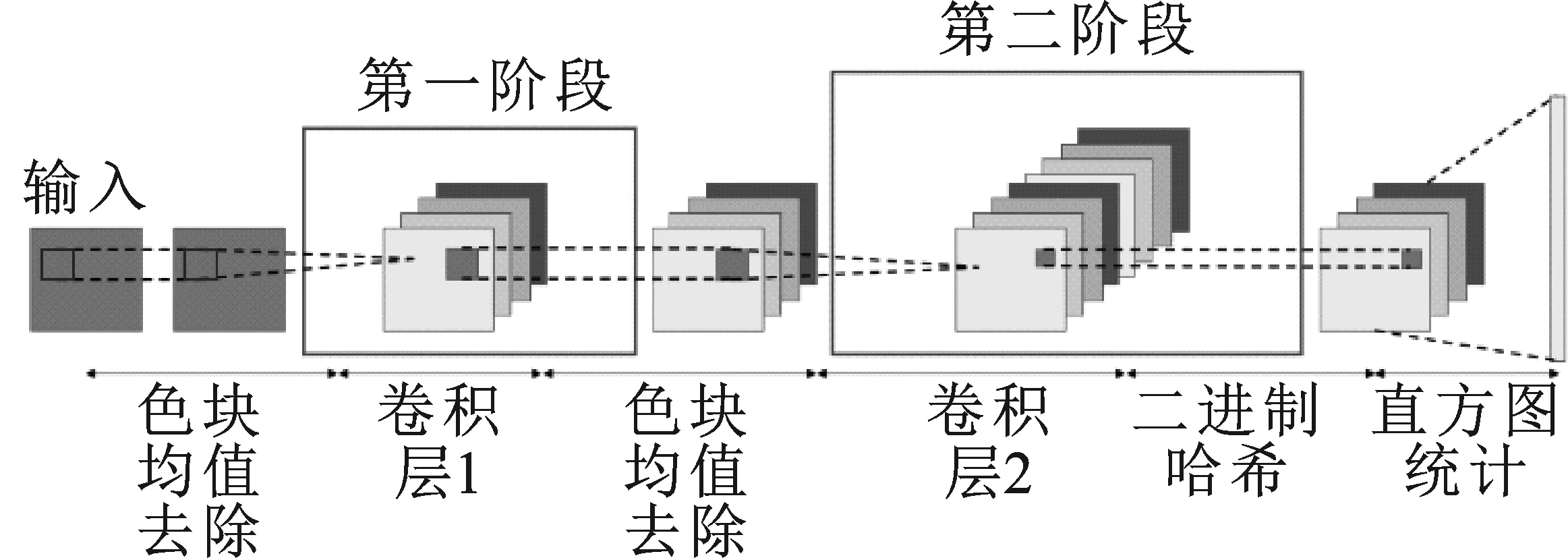
图2 改进PCANet示意图Figure 2. The schematic diagram of the improved PCANet
2.1 第一阶段
令所有假设与上文相同,可以得到所有不重叠的色块
xi,j∈Rk×k,j=1,2,…,mn
(6)
从每个色块中减去总体的均值,形成一个矩阵
(7)
然后用转置运算形成矩阵
(8)
对于所有输入图像,以相同的方式构造矩阵并将其置于同一个矩阵中,可得
(9)

第1阶段中需要的过滤器最终可以表示为
(10)
第1阶段的输出为式(11)。
(11)
2.2 第二阶段
与第一阶段类似,由不重叠色块开始,从每个色块中删除均值,得到
(12)
(13)
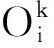
(14)
(15)
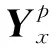
(16)
(17)
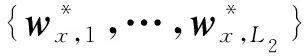
(18)
式中,q=1,2,…,L2。
(19)
值得注意的是,第2阶段的输出数量为L1×L2。
2.3 池化阶段
首先,使用类似Heaviside的阶跃函数对第2阶段的输出进行二值化。函数可以表示为

(20)
每个像素由以下函数进行编码
(21)
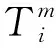

(22)
使用上述2DPCA-L1模型,可以将输入图像转换为特征向量,作为该改进PCANet的输出。
3 实验测试
本文分别测试了PCANet、2DPCANet以及以PCANet和2DPCANet为基准的L1-PCANet和本文所提的改进PCANet在AR和RMFD(Real-World Masked Face Dataset)人脸数据库上的性能。参数设置为:k=5,B=8,L1=L2=4。LibSVM中的SVM用作实现默认设置的分类器。重复进行10次实验,计算出平均识别精度和均方根误差(Root Mean Square Error,RMSE)。
3.1 AR
AR人脸数据集包含2 600张彩色图像,对应于100个人的面孔(50位男性和50位女性)。该数据集具有来自两个不同日期的两个类型图像数据,每个类型中的每个人都有13张图像,其中7张只有照明和表情变化,其余为3张戴墨镜和3张戴围巾的图像。数据集中的图像显示了具有不同面部表情、照明条件和遮挡物(太阳镜和围巾)的正面,如图3所示。对这些图片经过预处理,以使其具有相同的尺寸(40×30)。
本文将测试分为4组:(1)在第1组中,随机选择5个图像,每个图像仅有光照和表情变化,将这些图像作为训练图像;(2)在第2组中,从每个人中随机选择4个仅具有照明和表情变化的图像以及1个戴着墨镜的图像作为训练图像;(3)在第3组中,从每个人中随机选择4个仅具有光照和表情变化的图像和1个戴围巾的图像作为训练图像,其余为测试样本;(4)在第4组中,从每个人中随机选择3个仅具有照明和表情变化的图像、1个戴着墨镜的图像和1个戴着围巾的图像作为训练图像,其余均用作测试图像。本文还测试了两层CNN以进行比较,并在测试图像上训练了2 000 epoch。CNN的架构与文献[10]中的架构相同。训练结果如表1所示。

表1 AR图像训练结果
为了分析人脸遮挡面积大小对识别率的影响,本文将块状噪声随机添加到测试图像中,生成具有遮挡的测试图像。在每个块状噪声内,像素值随机设置为0或255,占据图像的面积为10%、20%、30%和50%。最后将它们分别添加到图像的随机位置,如图4所示,训练结果如表2所示。

图3 AR人脸图像Figure 3. AR face images
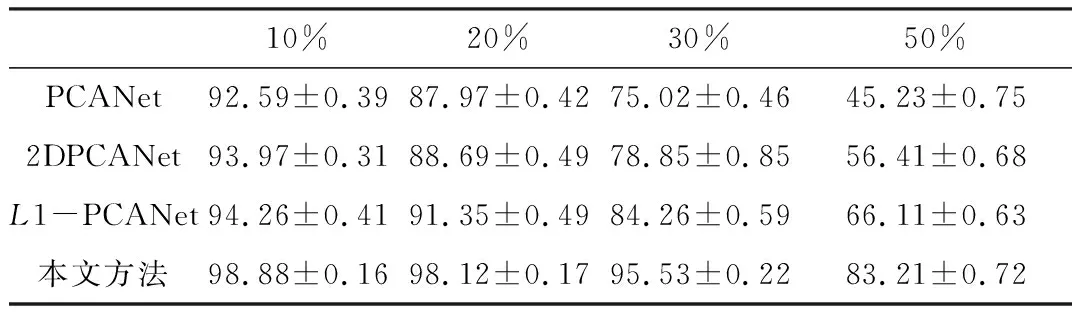
表2 不同遮挡面积图像训练结果
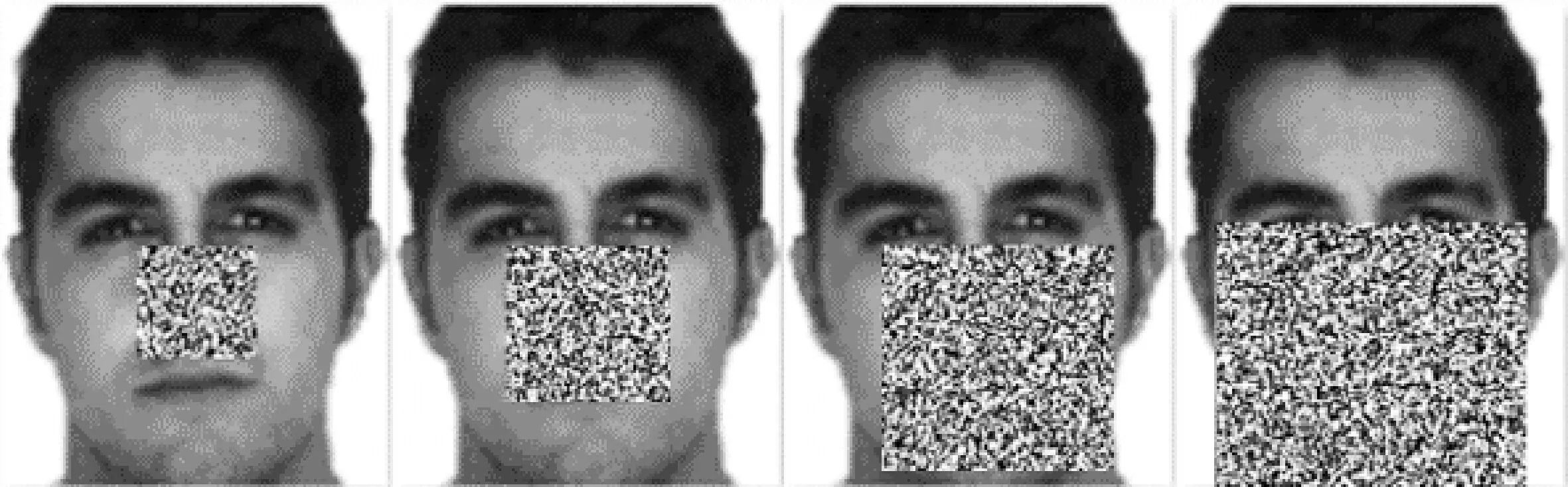
图4 添加块状噪声的人脸图像Figure 4.Face images with block noise
3.2 RMFD
口罩遮挡人脸数据集(Real-World Masked Face Dataset,RMFD)人脸数据库是武汉大学国家多媒体软件工程技术研究中心收集的戴口罩人脸数据集,包含了525人的5 000张戴口罩人脸和90 000张正常的人脸,每个人对应有不同角度和不同表情下不戴口罩以及戴口罩的照片,如图5所示。本文随机选取每个人的50张正常不戴口罩照片以及50张戴口罩照片进行训练,其余图片用作测试,试验重复7次,结果如表3所示。

(a)

(b)图5 RMFD人脸图像 (a)正常人脸 (b)戴口罩人脸Figure 5. RMFD face image(b)Normal face (b)Face with mask

表3 RMFD图像训练结果
3.3 结果与分析
在上述实验中,本文通过随机选择来更改训练图像。从结果中可以看到,本文提出的方法在识别准确度和RMSE方面优于PCANet、2DPCANet和L1-PCANet,这是因为本文将L1范数引入了网络。就RMSE而言,本文所提出的两个基于L1范数的网络优于传统基于L2范数的网络,这意味着所提出的网络对训练图像的变化不敏感。也就是说,传统基于L2范数的网络的精度在很大程度上取决于训练图像的选择,而本文所提出基于L1范数的网络可以在任何训练图像下取得更高、更稳定的精度。实际上,图像中的表情、姿势、照明条件和遮挡可以被认为是面部识别中的干扰或噪声,而基于L2范数的网络对于噪声降级方面的效果比基于L1范数的网络更加明显。因此,当训练图像包含表情、姿势、照明条件和遮挡的某些变化时,本文所提出的网络将显示出其优越性。
表2为不同遮挡面积的训练结果。从结果可以看出,随着噪声块从图像大小的10%增加到50%,PCANet、2DPCANet和L1-PCANet的性能迅速下降,而本文提出的改进PCANet仍然具有良好的性能。因此,本文提出的改进PCANet具有比其他3个网络更好的鲁棒性,可以抵抗异常值和噪声,在有遮挡的人脸识别中精度更高。
4 结束语
本文提出了一种基于L1范数的PCANet深度学习网络。基于L1范数的优点,本文将基于L1范数的2DPCA用于过滤器学习,其比L2范数对异常值的鲁棒性更高。为了验证本文所提改进方法的性能,本文在AR和RMFD的人脸数据集上进行了测试。结果表明,与传统基于L2范数的网络相比,本文所提方法具有以下优势:(1)在统计结果方面,本文方法在所有测试数据集上的准确性都高于其他网络;(2)本文提出的网络与其他网络相比,对训练图像的更改具有更好的鲁棒性;(3)与其他网络相比,本文方法具有更好的抗噪声和离群值的鲁棒性。因此,本文所提的改进PCANet是一种实用且精度较高的人脸识别方法。
