基于节点相似度的无监督属性图嵌入模型
2022-02-26吴安彪赵琳琳王国仁
李 扬,吴安彪,袁 野,赵琳琳,王国仁
(1.东北大学计算机科学与工程学院,沈阳 110169;2.北京理工大学计算机学院,北京 100081)
0 引言
图,也叫网络,作为一种常见的数据结构,广泛地出现在人们的日常生活中,例如社交网络、万维网等。在大数据时代,图已经成为有效存储和建模实体关系的重要媒介。在各种图中,属性图引发了很多关注,属性图不仅保留了节点间的拓扑结构,而且还具有丰富的属性信息。在实际应用中,属性信息在许多任务中起着重要作用。例如,在社交网络中,用户是否要购买某产品不仅与他的社交状况有关,而且与用户最近的购买记录密切相关。此外,有关社会科学的一些相关研究还表明,节点的属性可以反映和影响其社区结构[1]。因此,关于属性图的研究是必要且有意义的。
许多属性图嵌入工作(例如图卷积网络(Graph Convolutional Network,GCN)[2])都取得了巨大的成功,可以利用它们去解决多数图上的深度学习问题。半监督算法在保证实验效果的基础上极大减少了需要标记数据的数量,这是一个巨大的进步。但是在大数据时代,图的规模非常大,具有十亿个节点的大图并不少见。以一个有十亿个节点的图为例,按照文献[2]中最低的标记率0.001 计算,需要标记一百万个节点。而且,由于数据标记率如此低,无法保证在图上进行的各种下游任务都能取得良好的效果。因此,需要在大图上标记的数据量很大。与此同时,数据标注的难度很高。以上情况导致标注过程会消耗大量的人力物力,一定程度上阻碍了有监督或半监督图嵌入算法的实际应用。
而且,许多现有的属性图嵌入方法是端到端的。输入是图中节点的特征,输出是下游任务的最终结果。换句话说,端到端算法所得到的嵌入向量是与标签相关的。标签是依赖于专家或经验标注的,如果基于经验的数据标注出现问题,将会对最终结果产生影响。同时,端到端算法违背了图嵌入的初衷。图嵌入的目的是将图中的每个节点都表示为低维向量,并使用该向量执行一系列下游任务。端到端使嵌入变得不可见。当下游任务发生变化时,需要调整整个模型。在实际应用中,图上的任务往往不是单一的,在满足各种任务的同时需要调整整个模型所需的代价使得端到端算法会消耗更多的成本。
诸如GCN 一类的属性图嵌入方法更加关注节点的属性信息。现有的图嵌入理论认为,图上的信息主要包括拓扑信息(例如哪些节点是该节点的邻居)和属性信息(例如节点的特征)。GCN 一类方法的思想是沿图上的路径传播属性。与属性信息相比,拓扑信息在GCN 的输出中反映较少,灵活地调整属性信息和拓扑信息对嵌入的影响是必要的。
为了解决上述问题,本文提出了一种无监督的两阶段模型:第一阶段将已存在的无属性图嵌入方法(以DeepwalkDeepWalk 为例)作用在属性图上得到包含拓扑信息的嵌入向量,利用该向量可以得到属性图的拓扑相似度矩阵,并利用属性图的属性得到属性相似度矩阵,第二阶段利用已存在的属性图嵌入方法(以GCN 为例)作用在属性图上得到低维向量,利用该向量得到的相似度矩阵以及第一阶段已经得到的拓扑相似度矩阵和属性相似度矩阵计算损失,从而反向更新GCN 的权重,最终得到属性图的嵌入向量。本质上,本文方法是提取图中节点之间的拓扑相似度和属性相似度,然后基于这些相似度嵌入节点,并通过现有的无属性图嵌入方法和属性图嵌入方法来学习这种嵌入。更具体地说,本文的主要工作如下:
1)提出了一种无监督的属性图嵌入方法。与现有的有监督和半监督方法不同,该方法可以在不依赖任何标签的情况下使图中的每个节点获得相应的嵌入向量。
2)设计了一个损失函数,该函数是属性信息与嵌入向量信息差值以及拓扑信息与嵌入向量信息差值的和,通过调整这两项的权重可以灵活地调整属性和拓扑结构对嵌入向量的影响,并最终使得到的嵌入向量尽可能地保留拓扑和属性信息。
3)在真实数据集进行实验,评估本文所提出的方法。实验结果表明,在没有任何标签的情况下,该方法就可以实现优异的性能。
1 相关工作
图嵌入是一个热门的研究方向,在此方向上已经有一系列的经典工作。下面将从图嵌入和属性图嵌入两方面来介绍相关工作。
1.1 图嵌入
大多数图嵌入方法属于以下三类:基于分解的方法、基于随机游走的方法、基于深度学习的方法。
基于分解的方法受矩阵分解方法的启发,该方法假定数据位于低维流形。拉普拉斯特征图(Laplacian Eigenmaps,LE)[3]和局部保留投影(Locality Preserving Projections,LPP)算法[4]依靠特征分解来保留局部流形结构。由于特征分解操作代价高昂,这些方法在处理大规模图时面临困难。为了缓解这个问题,已经提出了几种方法,有代表性的是图分解(Graph Factorization,GF)[5]、GraRep(Graph Representation)[6]和HOPE(High-Order Proximity Preserved Embedding)[7]。这些方法的主要区别在于它们所采用的节点相似度计算方法。GF 直接从邻接矩阵中提取一阶邻近度来计算节点相似度,而GraRep 和HOPE 分别利用邻接矩阵和相似度度量(即余弦相似度)的不同幂获得高阶邻近度以捕获更准确的节点相似度。
基于随机游走的方法假定如果一对节点经常同时出现在图的模拟随机游走的路径中,那么这对节点很相似。因此与基于因式分解的方法所使用的确定性方法相比,节点相似性的计算更加随机。DeepWalk[8]和node2vec[9]是该类方法中较为成功的方法,它们的区别在于随机游走的方式不同。DeepWalk 模拟均匀的随机游走,而node2vec 依赖于有偏的随机游走。Perozzi 等[10]扩展了DeepWalk 在图中编码了多尺度的节点关系。与DeepWalk 和node2vec 将节点嵌入到欧几里得空间不同,Chamberlain 等[11]将节点嵌入到双曲空间。
基于分解和随机游走的方法往往采用浅层模型,这导致其捕获复杂图结构的能力严重不足。为了解决这个问题,一些研究人员引入了深度学习技术。Tian 等[12]提出了一个堆叠的稀疏自编码器通过重构邻接矩阵来嵌入节点。Wang等[13]提出了一个堆叠的自编码器,其通过使用一阶邻近度作为正则项来重构二阶邻近度。Cao 等[14]使用堆叠的去噪自编码器来重构互信息矩阵。
尽管大部分图嵌入方法都属于上述三种类型,但仍有例外 。例 如,LINE(Large-scale Information Network Embedding)[15-16]是一个成功的浅层嵌入方法,其通过保存图的局部和全局结构来获得嵌入。
1.2 属性图嵌入
1.1 节中描述的图嵌入方法仅利用图的结构来学习节点表示,但是现实世界图中的节点通常带有一组丰富的属性,为了利用节点特征,已经提出了许多属性图嵌入方法,这些方法分为两大类:有监督方法和无监督方法。
有监督的属性图嵌入通过利用标签信息来嵌入节点。例如,Huang 等[17]提出了一种利用频谱技术将邻接矩阵、节点特征矩阵和节点标签矩阵映射到同一个向量空间中的监督方法。Hamilton 等[18]提出了GraphSAGE(Graph Sample and AGgrEgate)的四个变体,这是一种以归纳方式计算节点嵌入的框架。许多方法使用部分标签信息来处理图。例如,GCN[2]将频谱卷积合并到神经网络中。图注意力网络(Graph ATtention network,GAT)[19]利用注意力机制来确定相邻节点在最终节点表示中的影响。
无监督的属性图嵌入方法可解决缺少标签信息的问题,这种情况在许多实际应用中都存在。Yang 等[20]和Huang等[21]提出了矩阵分解的方法来结合图的结构信息和节点的属性信息。此外Kipf 等[22]提出了两种利用图卷积网络的图自动编码器(Graph Auto-Encoder,GAE)。Pan 等[23]还介绍了一种基于对抗方法的图形编码器。对于图聚类,Wang 等[24]提出了一种图形自动编码器,它能够重构节点特征;然而,这种自编码器只能重构图的结构或图的属性而不能同时重构两者。Gao 等[25]提出了一个框架,该框架由两个常规的自动编码器组成,它们分别重构了图的结构和节点的属性。
2 问题定义
本章介绍论文中所使用的主要变量,以及属性图嵌入问题的相关定义。表1 总结了文中所使用的主要变量。

表1 主要变量Tab.1 Main parameters
定义1属性图。属性图是一种数据结构,可以表示为G={V,E,A},其中V={v1,v2,…,vn}表示图中的|V|个节点组成的集合,E表示节点之间的边的集合。A∈R|V|×m表示节点的属性信息,其中m是属性向量的维数,Ai是与节点vi对应的属性向量(例如,社交网络中用户的年龄和性别或蛋白质-蛋白质相互作用网络上的蛋白质类别)。
值得注意的是,这些属性是来自应用程序域的属性。它们不是由专家手工制作或通过嵌入技术产生的合成特征。因此,它们不包括任何拓扑信息。
在各种应用程序中,将属性图嵌入到低维向量空间中很有用。为了获得嵌入,必须保留图的拓扑结构。局部图结构,即两个节点是否相邻,必须在嵌入向量中得到反映。以下定义度量了两个节点之间的局部结构。
定义2一阶邻近度。图中两个节点之间的一阶邻近度是局部的成对邻近度。对于由边(u,v)链接的每对节点,定义u和v之间的一阶邻近度为1。如果无法观察到u和v之间的边,则它们的一阶邻近度为0。
一阶邻近度可以在一定程度上反映图中两个节点的相似性。例如,在网络购物平台上彼此成为朋友的人们倾向于购买类似的产品;在万维网上彼此连接的用户往往会浏览相似的主题。许多现有的嵌入方法(例如等距特征映射(Isometric feature Mapping,IsoMap)、局部线性嵌入(Locally Linear Embedding,LLE)、LE 和GF)都旨在保留一阶邻近度。
仅仅衡量两个节点是否是邻居还远远不够。因为许多节点不是彼此相邻的,所以无法根据两个节点是否是邻居来确定两个节点的嵌入是否相似。一种直觉是共享邻居的节点也可能是相似的。例如,与某人同时成为朋友的两个人可能具有相同的爱好,并且在社交网络中更可能成为朋友;在推荐系统中,与某人同时是好友的两个用户也可能会购买类似的产品。因此,一些方法还定义了二阶邻近度以保留此类信息。
定义3二阶邻近度。图中一对节点(u,v)之间的二阶接近度是它们的邻居之间的相似度。即fpu=(fpu,1,fpu,2,…,fpu,u-1,fpu,u+1,…fpu,v-1,fpu,v+1,…,fpu,n-1,fpu,n)表示u与所有其他节点(不包括节点u和v)的一阶邻近度,则fpu和fpv之间的相似性决定了u和v之间的二阶邻近度。如果没有节点是u和v的公共邻居,则u和v之间的二阶接近度为0。
通过保存图中成对节点的拓扑相似度,可以极大地保留图中的拓扑信息。利用这些拓扑信息,可以针对图中的每个节点生成一个低维嵌入向量。值得注意的是,这个低维嵌入向量只包含拓扑信息而不包含其他信息。下面给出图的拓扑相似度矩阵的定义。
定义4图的拓扑相似度矩阵。图的拓扑相似度矩阵是一个方阵,其行数和列数为图的节点个数。其中的每一个位置对应于图中两个节点之间的拓扑相似度,即:
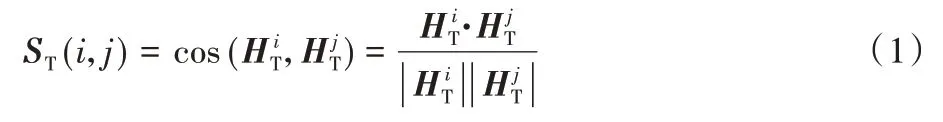
其中:ST(i,j)表示第i个节点与第j个节点间的拓扑相似度;表示节点i和节点j的拓扑嵌入;“·”表示向量的点积;| |表示向量的范数。
定义5图的属性相似度矩阵。图的属性相似度矩阵是一个方阵,其行数和列数为图的节点个数。其中的每一个位置对应于图中两个节点之间的属性相似度,即:
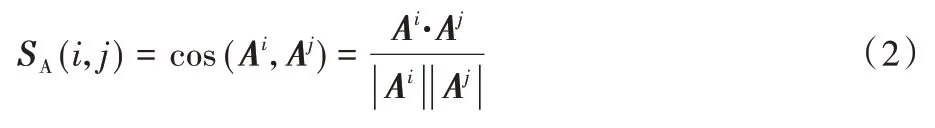
其中:SA(i,j)表示第i个节点与第j个节点间的属性相似度;Ai和Aj表示节点i和节点j的属性向量。
定义6图的相似度矩阵。图的相似度矩阵是一个方阵,其行数和列数为图的节点个数。其中的每一个位置对应于图中两个节点之间的相似度,即:

其中:S(i,j)表示第i个节点与第j个节点间的相似度;Hi和Hj表示节点i和节点j的嵌入向量。
式(1)~(3)分别定义了图的拓扑相似度矩阵、属性相似度矩阵和相似度矩阵。根据上述公式计算所需的时间复杂度为O(n2),n为节点的个数。在本文中不单独针对成对节点计算相似度而是针对整个图计算图上各节点之间的相似度,即首先对拓扑嵌入矩阵、属性矩阵、嵌入矩阵作规范化,然后使用该矩阵与该矩阵的转置作矩阵乘法,得到的结果与使用式(1)~(3)运算结果相同。计算过程如式(4)~(6)所示:

其中,HT、A、H分别为属性图的拓扑嵌入、属性向量和属性图的嵌入。、AT、HT分别为属性图拓扑嵌入、属性向量和属性图嵌入的转置。normalize()是矩阵规范化函数。
问题定义无监督属性图嵌入。给定属性图G={V,E,A},属性图嵌入旨在通过无监督学习将节点vi映射成一个低维向量Hi∈Rd,且该向量可以同时保留节点的拓扑和属性信息,其中d是嵌入向量的维数,d≪|V|。
接下来,本文将介绍两阶段的无监督属性图嵌入模型,利用该模型所得到的嵌入向量可以同时保留图的拓扑和属性信息。
3 算法框架
一个理想的属性图嵌入模型需要满足几个要求:第一,其生成的嵌入向量必须能够保留图的拓扑信息,例如节点之间的一阶邻近度或二阶邻近度;第二,其生成的嵌入向量必须保留图的属性信息;第三,它可以在不依赖标签的情况下生成嵌入,并且该嵌入向量可以保存大部分信息。在本章中,提出一个属性图嵌入模型,该模型可以满足所有这三个要求。
如图1 所示,所提模型主要分为两阶段。第一阶段,利用已有的无属性图嵌入方法(以DeepWalk 为例)提取节点的拓扑信息和节点的属性来计算各节点之间的拓扑相似度和属性相似度。第二阶段,利用现有的属性图嵌入方法(以GCN 为例)获得属性图的嵌入并计算相似度矩阵,根据损失函数来更新属性图嵌入模型的参数,最后利用更新的参数来获得属性图嵌入向量。下面,分别详细地描述算法的两个阶段。
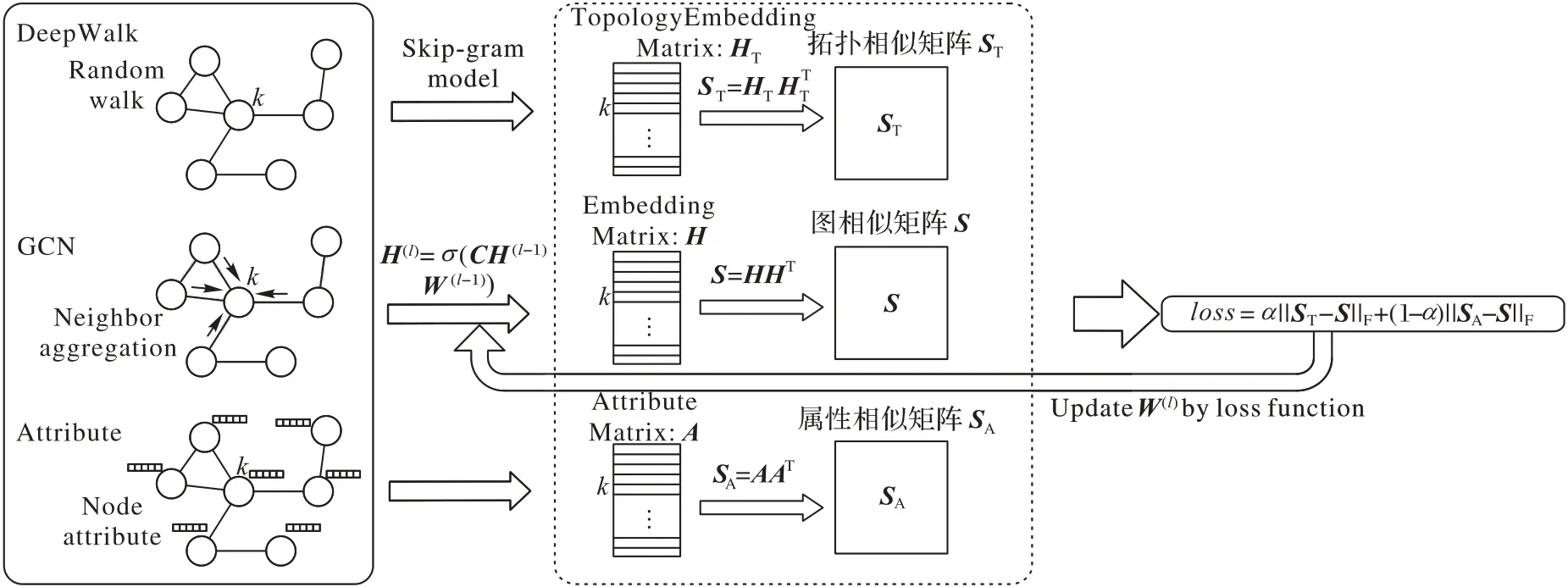
图1 无监督属性图嵌入模型Fig.1 Unsupervised attributed graph embedding model
3.1 拓扑信息和属性信息
由第2 章可知,图上的拓扑信息和属性信息可以被独立表达,因此可以使用现有的无属性图嵌入方法来提取图上的拓扑信息,然后计算图的拓扑相似度矩阵。
对于无属性图嵌入,已经有一系列成熟的方法可用于提取图中的局部和全局信息。这些方法主要由三类组成:基于矩阵分解的方法、基于随机游走技术、基于深度学习的方法。其中包含一系列有影响力的方法,例如局部线性嵌入(LLE)、LE、GF、GraRep、HOPE、DeepWalk、node2vec、结构深度网络嵌入(Structural Deep Network Embedding,SDNE)、深度递归网络嵌入(Deep Recursive Network Embedding,DRNE)、LINE 等。这些方法均可以应用在本文框架中。在本文中,以DeepWalk 为例来获得属性图的拓扑相似度矩阵,如算法1 所示。其中,ω、d、γ、t均为DeepWalk 算法中的参数,分别为窗口大小、嵌入向量大小、每个节点为起点所走的路径个数、路径长度。第1)~9)行为DeepWalk 算法的实现,第10)行是DeepWalk 算法得到的拓扑嵌入向量,第11)行利用第10)行所得到的结果根据式(4)计算出图的拓扑相似度矩阵。最终,根据算法1,可得图的拓扑相似度矩阵。
算法1 Topology Similarity。

对于属性图的属性信息,可以通过节点之间的属性相似度来度量。算法2 展示了如何根据属性计算属性图的属性信息。经过上述步骤可以获得属性图的拓扑信息和属性信息。下面介绍如何获得属性图的嵌入。
算法2 Attributed Similarity。

3.2 属性图嵌入模型
通过算法1 和算法2,可以得到属性图的拓扑相似度和属性相似度矩阵。接下来,使用现有的属性图嵌入技术来进行嵌入。可以在此框架中使用的算法包括但不限于GCN 及其一系列变体、图注意力网络、图自动编码器等。
本节以GCN 为例,下面给出GCN 模型。
GCN 模型是一个k层深度模型,可以表示为,其中W={W(1),W(2),…,W(k)},通常用于节点的端到端学习。给定一个具有节点属性和拓扑结构的属性图G,GCN 同时将这两种类型的信息编码为每层的隐藏特征,用作网络节点的单独信息 。形式上,GCN的前向传播过程为f(k)(f(k-1)(…f(1)(G)…))。GCN 的每一层都使用了邻居聚合函数f(·),进而通过前一层的特征来生成下一层的特征,如式(7)所示:


从呈现节点属性的最低嵌入H(0)开始,模型迭代地聚合一层中每个节点的隐藏特征与其相邻节点的特征,以在下一层H(1)中为该节点生成隐藏特征。依此类推(见式(7))。
通过使用上述模型可以获得属性图的嵌入S,一个自然的直觉是使属性图的嵌入尽可能与属性图的拓扑信息和属性信息一致。因此,本文提出了一种损失函数,如式(8)所示:
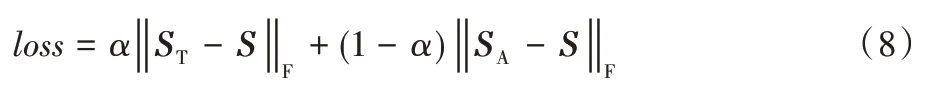
其中,本文设置α为超参数用以控制节点拓扑信息和属性信息在损失函数中的比例,因为节点的拓扑信息和属性信息对不同的数据集以及在不同的任务中影响是不同的,通过该参数可以直接控制拓扑信息和属性信息对于最终嵌入的生成。对于不同的任务,不同的属性会导致超参数的设置有差异。这里,“‖a‖F”为向量a的Frob enius 范数。算法3 详细描述了如何通过GCN 模型得到最终的嵌入向量。第1)~2)行是GCN 模型的构建及初始化过程,以属性图的属性矩阵为输入。第3)~4)行为GCN 模型的前向传播过程。第5)行是利用GCN 最后一层的输出计算相似度矩阵(见式(6))。第6)行是根据相似度矩阵、拓扑相似度矩阵、属性相似度矩阵和超参数α来计算损失函数。第7)行是根据损失函数更新GCN 中每一层的权重W(l)。第9)~10)行,通过迭代epoch次后,确定GCN 模型中各层的权重W(l),最后将属性图G输入到已训练好的GCN 模型中输出各个节点所对应的嵌入向量,如式(7)所示。
算法3 Attributed graph embedding。

4 实验与结果分析
本章使用多个基准数据集定性和定量地评估所提出的方法。
4.1 数据集及实验配置
本文使用3 个基准数据集(Cora、Citeseer 和Pubmed[26]),它们被广泛用于评估属性图嵌入方法。表2 给出了数据集的统计数据。
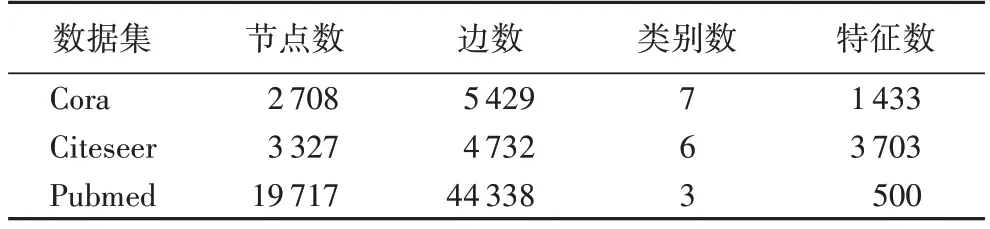
表2 数据集统计信息Tab.2 Dataset statistical information
在此实验中,使用Adam 优化器[27]来学习模型参数,初始学习率为0.1。对于Cora 和Citeseer,超参数α设置为0.4;对于Pubmed,超参数α设置为0.5。对于Cora 和Citeseer,epoch被设置为2 500;对于Pubmed,将epoch设置为2 000。对于模型中使用的GCN,其层数设置为2,隐藏层大小为1 000,嵌入向量维数d为64。
4.2 基线方法
下面将本文提出的属性图嵌入方法与以下最新的有监督和无监督的方法进行比较。
DeepWalk[8]:DeepWalk 是一种图嵌入方法,可在图上模拟随机游走,进而利用随机游走得到的路径训练SkipGram模型[28]。
增强的DeepWalk(DeepWalk+features):此基准将原始节点的属性和DeepWalk 的嵌入向量连接在一起,以利用节点属性。
标签传播(Label Propagation,LP)[29]:LP 将图中的可用标签传播给未标记的节点。
图自动编码器(GAE)[22]:GAE 使用图卷积网络作为编码器,并在编码器中重建图结构。
变图自动编码器(Variational Graph Auto-Encoder,VGAE)[22]:VGAE 是GAE 的变体版本。
GraphSAGE[18]:GraphSAGE 具有四个无监督的变体,其特征聚合器分为应用卷积样式聚合器(GraphSAGE-GCN)、属性向量中的元素逐项均值(GraphSAGE-mean)、通过将相邻节点的属性集成到LSTM 中进行汇总(Graph Sample and AGgrEgate-Long Short-Term Memory recurrent neural network,GraphSAGE-LSTM)和在应用全连接的神经网络后执行逐元素最大池操作(GraphSAGE-pool)。
4.3 节点分类
将本文所提出的方法与上述基线在节点分类任务上进行比较。DeepWalk和LP的精度可从Kipf &Welling[2]中获取。本文还重用了Veličković 等[30]报告中的增强型DeepWalk 的指标。此外,也将本文提出的方法与GAE 和VGAE 进行了比较。
本文所提出的方法在3 个数据集上都展现出了良好的性能,如表3 所示。其中在Cora 和Citeseer 数据集上,此方法超过了所有基线方法,可以观察到最佳无监督基线方法分别提高了1.2 个百分点和2.4 个百分点;在Pubmed 数据集上,本文方法没有超过最好的基线方法,与最好的基线方法相比,本文方法所取得的准确率低0.9 个百分点。可以注意到,Pubmed 数据集节点数是Cora 数据集和Citeseer 数据集节点数的6~7 倍,然而,Pubmed 数据集的属性向量长度只有Cora 数据集的1/3,只有Citeseer 数据集的1/7,这意味着与前两个数据集相比,Pubmed 数据集中的节点拥有更加丰富的拓扑信息和更加贫乏的属性信息,导致节点嵌入无法均衡地表达这两种信息,这或许是Pubmed 数据集上节点分类任务表现不佳的原因之一。
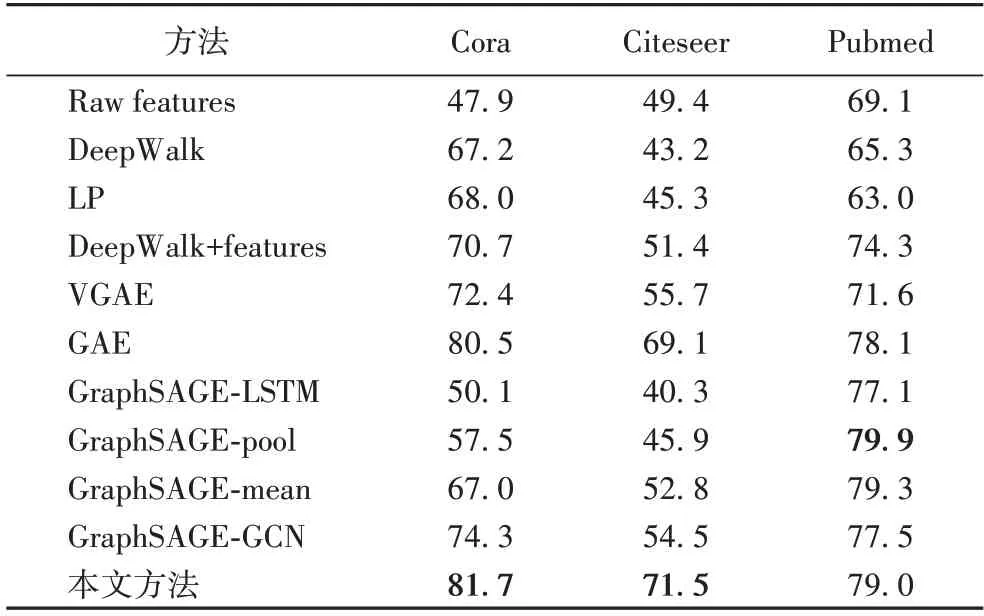
表3 不同数据集上的节点分类任务准确率比较Tab.3 Accuracy comparison of node classification task on different datasets
此外,Cora 数据集和Citeseer 数据集与Pubmed 数据集上的超参数设置是不同的。超参数α表明拓扑信息对于嵌入向量的贡献程度,同样,1-α表示属性信息对于嵌入向量的贡献程度。由4.1 节可知,Cora 和Citeseer 数据集上的超参数α设置为0.4,Pubmed 数据集上的超参数α设置为0.5。对于Pubmed 数据集上的节点来说,它们拥有更加丰富的拓扑信息,因此拓扑信息对于嵌入向量的贡献程度被设置得更大,最终导致嵌入向量对于属性信息没有完整地表达,使得准确率不高。
4.4 可视化
在可视化任务中,本文将Cora 数据集上的前400 个节点分别利用DeepWalk 算法所得到的嵌入向量和本文所提出的方法所得到的嵌入向量作为t-SNE(t-distributed Stochastic Neighbor Embedding)算法的输入,映射到二维空间上,结果如图2、3 所示。图上的每一种图形代表Cora 数据集上不同的分类。其中,t-SNE 算法的参数均使用默认设置。
图2 为利用DeepWalk 算法所得到的嵌入向量作为t-SNE算法输入的可视化结果。从图2 中可以看到,DeepWalk 算法的可视化结果并不是有意义的,许多并不属于同一类的节点聚集在一簇中,同时也存在大量的异常点独立于簇间。原因主要归结于DeepWalk 算法所得到的嵌入向量只能保存属性图中节点的拓扑信息,对于属性信息却完全没有表达。
图3 为利用本文所提出的方法得到的嵌入向量作为t-SNE 算法输入的可视化结果。与图2 相比,属于同一类的节点大多能够被分配在一个或几个簇中。同时,DeepWalk算法可视化结果中的异常点在图3 中也被分配到了各自的簇中。与DeepWalk 相比,本文所提出的方法生成的可视化结果是更有意义的。
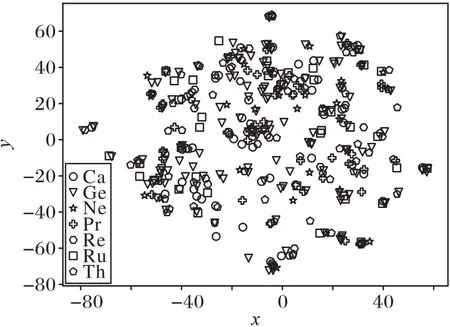
图2 DeepWalk算法在Cora数据集上的可视化结果Fig.2 Visualization result of DeepWalk algorithm on Cora dataset
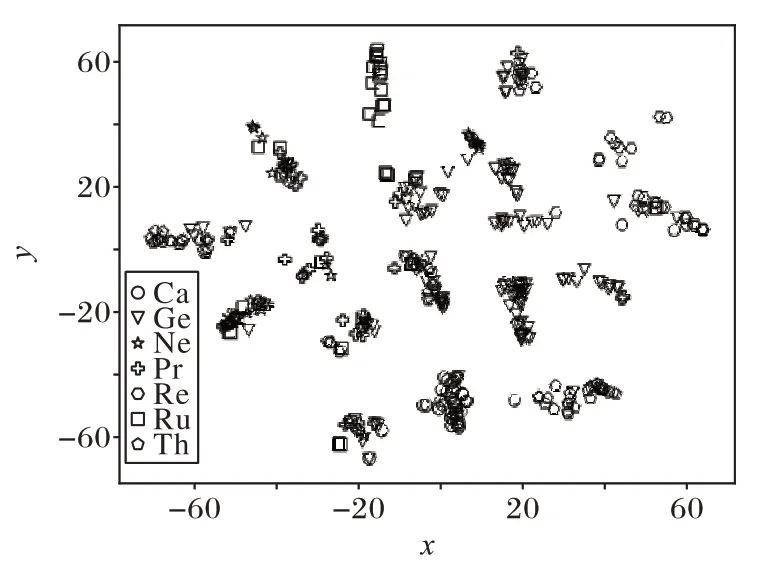
图3 本文方法在Cora数据集上的可视化结果Fig.3 Visualization result of the proposed method on Cora dataset
4.5 超参数实验
图4 展示了在Cora 数据集上超参数α的变化对节点分类任务准确率的影响。当α为0.4 时,节点分类的准确率最高,达到了81.7%。针对不同的数据集以及不同的任务,α的选取一般也是不同的,选择一个合适的α是任务质量的前提保证。
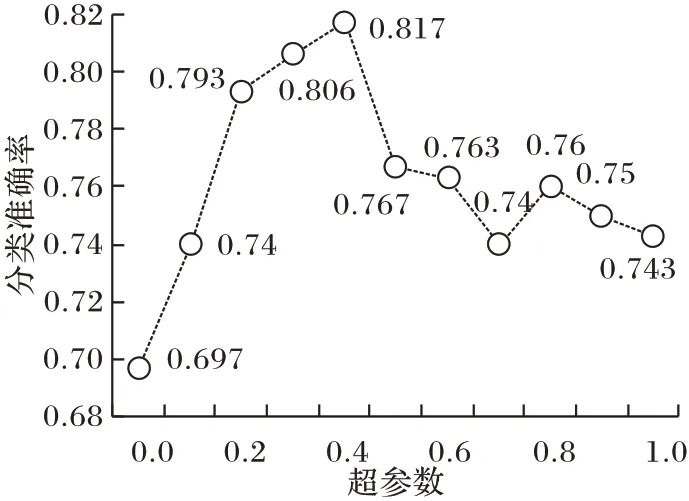
图4 不同超参数α下的节点分类准确率Fig.4 Node classification accuracy with different hyperparameter α
图5 展示了在Cora 数据集上嵌入向量维数d对节点分类准确率的影响。此实验分别记录了d为10、40、64、128、256时,节点分类准确率的变化情况。可以观察到,当嵌入向量维数过大时,本文所提出的方法在Cora 数据集上的节点分类准确率会下降。
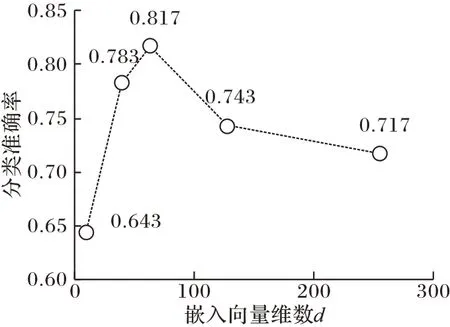
图5 不同嵌入向量维度d下的节点分类准确率Fig.5 Node classification accuracy with different embedding vector dimension d
5 结语
图数据广泛存在于实际场景中,例如社交网络平台、交通数据、生物医药网络等。本文提出了一种针对属性图的无监督嵌入方法,通过传统的无属性图嵌入方法和属性图有监督嵌入方法,利用提出的损失函数,可以获得能够保存属性图属性信息和拓扑信息的嵌入向量。在3 个基准数据集上的实验结果表明本文所提出的方法的有效性,它可以学习到高质量的嵌入向量。在大部分数据集上,本文所提出的方法所取得的效果已经可以超过最好的无监督基线方法。
本文所提出的方法的空间复杂度与图中节点个数的平方成正比,因为在损失函数中需要使用节点基于拓扑和属性信息的相似度矩阵,且使用的GCN 模型也需要计算图的拉普拉斯矩阵,这意味着本文的方法难以直接扩展到大图。此外,与一般的半监督或有监督属性图嵌入算法相比,本文方法的执行时间也较长,这是为了保证嵌入高质量的代价。因此,未来的工作是改进方法,使得该方法能够在较短的时间内,在占用更少的资源的同时,获得更高质量的嵌入向量。
