融合高级与低级视觉特征的农业图像显著性区域预测方法研究
2022-02-25孟庆岩阴旭强宋怀波
孟庆岩,阴旭强,宋怀波
(1 烟台黄金职业学院 信息工程系,山东 烟台 265400;2 西北农林科技大学 机械与电子工程学院,陕西 杨凌 712100)
显著性区域检测在图像分割[1-3]、图像匹配[4-5]、物体识别[6]和视觉跟踪[7]等领域具有重要的研究意义。农业生产往往处于非结构化的复杂背景之中,作物、畜禽等目标图像显著性区域的快速准确预测可为其识别和监测奠定基础,对于提升农业生产的智能化水平具有重要的促进作用[8-9]。
在农业图像显著性检测领域,国内外学者已有了一定的研究成果。马翠花等[10]通过自动识别获取自然环境下果实图像中的未成熟果实,以实现自动化果实估产的目的,提出了基于密集和稀疏重构(dense and sparse reconstruction,DSR)的显著性检测方法,对图像中的未成熟番茄果实的正确识别率达77.6%,为估产机器人的多种果实自动化识别提供了参考。钱蓉等[11]提出一种基于显著性检测的害虫图像自动分割算法,对5种鳞翅目幼虫图像的平均分割精确度为88.22%。任守纲等[12]提出了一种基于超像素分割联合显著性检测的黄瓜叶部病害图像分割算法,对常见的黄瓜病害(白粉病、褐斑病、霜霉病、炭疽病)图像进行测试,有效解决了冗余分割问题,错分率在5%以内,算法平均执行时间均小于4 000 ms,分割效果更加精确,为后续构建黄瓜病害自动识别系统奠定了基础。目前农业领域显著性区域预测研究多基于传统分割算法开展,但其模型参数易受非结构化农业环境的影响,分割精度也有待提高。在非结构化的农业环境下,复杂背景会对传统显著性区域预测算法造成干扰,导致无法实现显著性区域的准确提取[13-14]。
深度学习技术的发展为实现农业图像显著性区域的快速、准确预测提供了技术支撑。王书志等[15]提出了一种融合图像局部和全局信息显著性目标检测的病斑分割方法,所建立的方法对病斑分割性能指标马修斯相关系数为0.625,略低于对照算法全卷积神经网络(FCN)(0.689),但在衡量泛化性能的测试集上,所建立方法的马修斯相关系数为0.338,远高于FCN(0.072),说明所建立方法在分割精度和泛化性方面具有较好的平衡性。基于深度学习的农业图像显著性检测算法具有更好的环境鲁棒性,可以有效地避免人工设计特征,全面有效地对图像信息进行挖掘。但是现有基于深度学习的显著性区域预测网络主要集中在底层显著性特征的设计上,缺乏对高层视觉特征的学习,导致信息缺失,不利于显著性区域的精确提取。因此,为实现自然场景下农业目标的准确快速提取,应将显著性区域检测视为高级与低级视觉特征融合的语义认知任务[16]。本研究拟提出一种基于高级与低级视觉特征融合的显著性区域预测深度学习框架,以期为实现农业图像显著性区域的快速准确提取提供参考。
1 显著性区域预测算法的构建
本研究提出了一种用于显著性区域预测的高级视觉特征与低级视觉特征融合的深度学习框架,如图1所示,该框架共由5部分组成:第1部分由ResNet网络中的第1个卷积层构成,用于抽取输入图像的64个卷积特征图(ResNet中的Conv1卷积核数量为64);第2部分由ResNet剩余网络层构成,用于抽取输入图像卷积特征图的高级视觉特征;第3部分由3个卷积层和1个全连接层构成,用于抽取输入图像卷积特征图的低级视觉特征;第4部分是特征融合模块,用于高级视觉特征与低级视觉特征的融合;第5部分是由10个SVM二值分类器组成的集成分类器,用于预测显著性区域图。
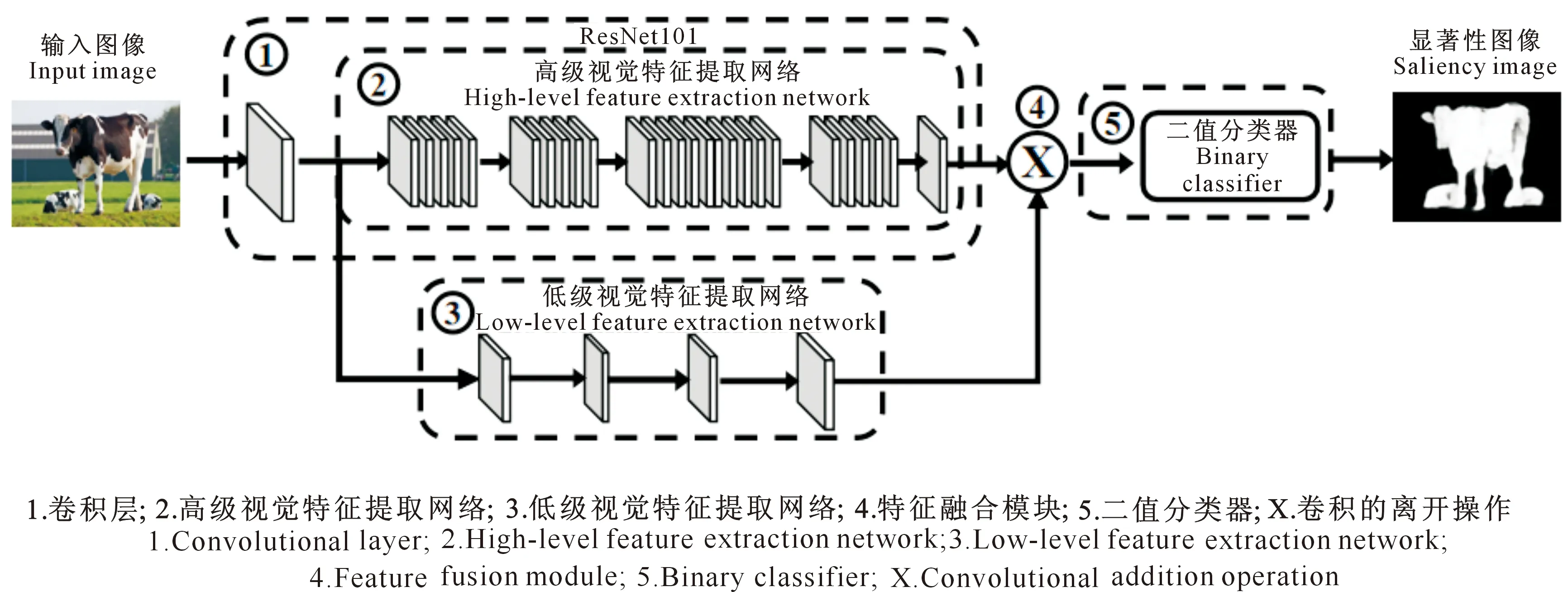
图1 显著性区域图像视觉特征融合框架Fig.1 Visual feature fusion frame diagram of salient area image
1.1 特征提取
该框架使用ResNet101作为基线模型实现高级视觉特征的提取,ResNet101中共有101层(激活层与池化层不被计算在内),其中包含100个卷积层和1个全连接层。在基线模型的基础上引入了低级视觉特征提取网络,共有4层(激活层与池化层不被计算在内),其中包含3个卷积层和1个全连接层,详细参数如表1所示,例如超参数64(7×7)表示64个通道7×7的卷积,其他同理。除了ResNet101模型外,在计算机视觉任务中,还有一些优秀的特征提取网络模型,如AlexNet[17]、GoogleNet[18]和ResNet50[19]。在试验部分,本研究将这些模型融入到所建算法框架之中,并进行显著性区域预测性能的对比。
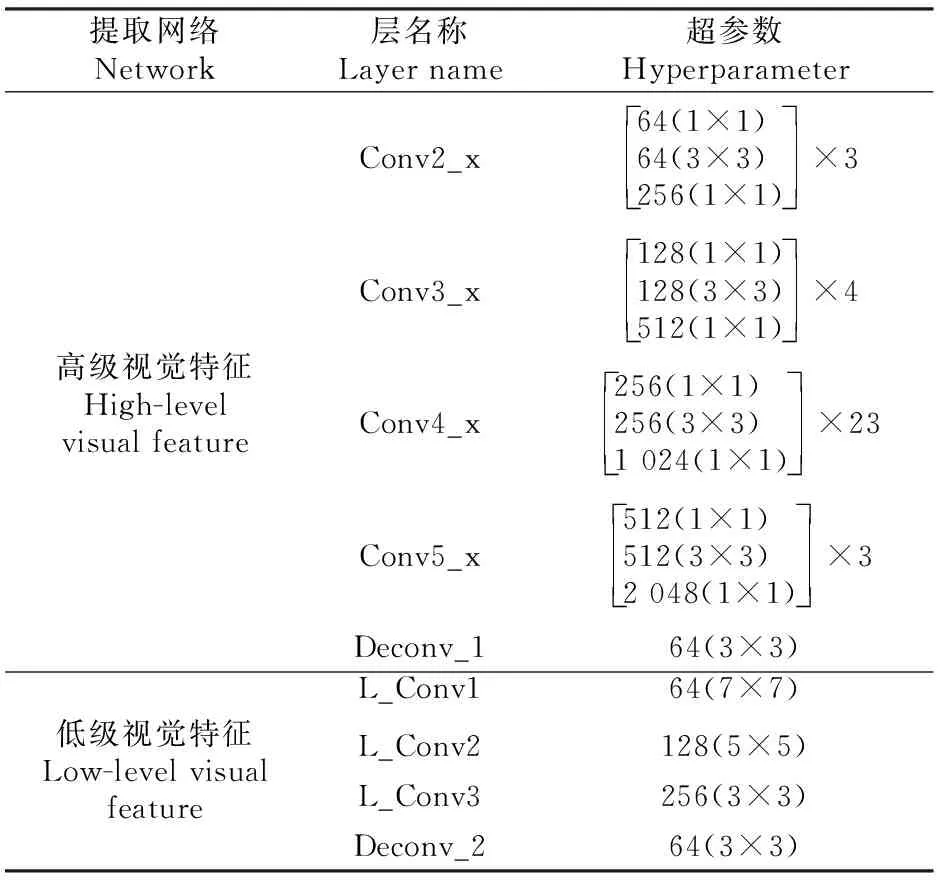
表1 高级与低级视觉特征提取网络框架的网络参数(Conv为卷积层)Table 1 Parameters used in the high- and low-level visual feature extraction network (Conv is convolution layer)
1.2 特征整合
图1中的高级视觉特征提取网络通过深层网络来提取特征,目的是检测图像中包含的语义区域信息;而低级视觉特征提取网络则利用浅层网络抽取特征,更侧重于颜色、形状、亮度等低级信息的检测。在本研究中,高级视觉特征提取网络采用与低级视觉特征提取网络中相同形式的输入。LFENet与HFENet由于采用不同的深层网络结构,故两者具有独立的参数。其他深层网络结构(如AlexNet)也可以灵活地与LFENet结合在显著性区域预测算法中。总而言之,通过高级视觉特征与低级视觉特征整合来估计显著性区域概率,从而实现对显著性区域的预测。其计算公式为:
score(xIf)=p(xlabel=1|xIf;θ1)。
(1)
式中:score为显著性区域预测概率;xIf为高级视觉特征与低级视觉特征的整合特征;p为概率分布;xlabel表示根据整合特征对显著性区域的预测,label为图像像素,xlabel=1表示当前整合特征是显著性区域的特征,xlabel=0表示当前整合特征是非显著性区域的特征;θ1为当前网络结构权重参数。
在高级视觉特征与低级视觉特征整合中,本研究将高级视觉特征视为语义视觉中心,低级视觉特征视为图像的底层视觉描述。为了在一定程度上刻画图像底层视觉描述围绕语义视觉中心的紧密程度,本研究按照下式的形式进行整合与描述。有:
(2)
式中:xLf和xHf分别为低级视觉特征提取网络和高级视觉特征提取网络中最后一层网络的输出;i、j表示视觉描述的个体;N为图像底层视觉描述的数量;M为语义视觉中心的数量。
10个二值分类器(SVM分类器)组成了一个分类器集,每个二值分类器通过随机抽取90%的整合特征进行训练,目的是提高显著性区域预测的置信度,可用下式表示:
(3)
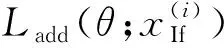

(4)
式中:T是转置符号。
本研究根据文献[22]定义显著性区域预测分数fu(t),其表达式为:
(5)
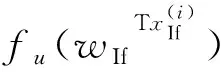
1.3 数据集预处理及训练流程
1.3.1 数据集 本研究使用MSRA10k数据集[20]来训练显著性区域预测算法,数据集包含不同领域的10 000幅图像,包括准确像素级的显著目标标注图,将其按照6∶2∶2的比例划分为训练集、验证集和测试集。在算法的对比分析模块,采用6个显著性检测领域常用公共测试集(SOD、ASD、SED2、ECSSD、HKU-IS和THUR)进行评价分析。为进一步验证所提框架在农业场景应用的可行性,本研究利用源于网络的100幅典型农业场景图像数据集作为测试集进行算法评估,人工筛选典型果实、农作物及畜禽目标。不同于普遍的显著性公共评估数据集,人工筛选时保留多目标及重叠目标以保证测试数据集的复杂性,利用Labelme软件进行人工显著性区域标注,以对算法的预测结果进行客观评价。
1.3.2 训练流程 卷积神经网络产生的若干特征图中会存在显著性区域图像。本研究提出的基于整合特征的显著性区域预测算法,是通过高级视觉特征与低级视觉特征的融合,使得抽取的语义图像特征更加丰富,最终将整合特征通过集成分类器,在本研究设定的损失函数下,利用自适应梯度下降寻优得到最接近于基准标注图的特征图集合,并最终得到显著性区域预测图。其具体训练流程如下:
1) 对深度CNN模型进行预训练,以显著提高目标任务的检测性能[21]。首先使用大规模图像分类数据集ImageNet[22]上预训练的ResNet101权重进行迁移,以更好地进行图像特征的挖掘,节省训练时间,提高效率。为进行预训练模型的自我评价,与其他3种深度学习领域常用深层网络结构模型(AlexNet、GoogleNet、ResNet50)进行对比评估。
2) 采用随机采样技术提升分类器的稳定性。卷积操作会产生较多的冗余特征,即不同数量级的显著性区域特征和非显著性区域特征,因此,这是一个典型的类别不平衡问题。本研究采取Tao等[23]的方式进行采样,其流程如图2所示。通过图2的随机采样技术既解决了分类器的不稳定问题,又有效提升了基线分类器的差异度。
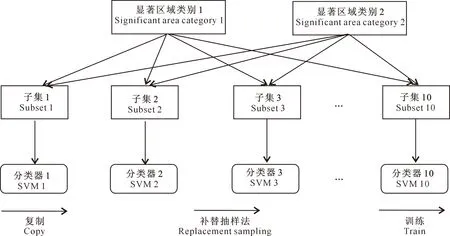
图2 随机降采样技术处理流程图Fig.2 Processing chart of random down sampling technology
3) 基于PyTorch库实现融合高级视觉特征与低级视觉特征的显著性区域预测深度学习框架。采用Adam优化器对损失函数式(3)进行优化,以获得与基准标注图更接近的显著性区域预测结果。初始学习率为5×10-4,共进行100 000次迭代。预处理仅使用简单的随机水平翻转来扩充数据,且在训练和测试中保持输入图像的大小不变。
4) 预训练模型评估。为进行预训练模型对显著性区域预测结果的评估,在保证试验条件相同的前提下,仅将模型中的ResNet101模型结构替换为其他3种深层网络结构模型(AlexNet、GoogleNet、ResNet50)以进行评估,进行100 000次迭代,进行F-Measure指标对比。
5) 有效性验证。为进一步验证本研究所提框架的有效性,在6个显著性检测领域常用公共测试集(SOD、ASD、SED2、ECSSD、HKU-IS和THUR)对4种最新的显著性检测框架(MWS[24]、IMS[25]、FSN[26]、P-Net[27])进行F-Measure及MAE指标的对比分析,以验证与显著性检测领域常见算法相比,融合高级视觉特征与低级视觉特征的显著性区域预测深度学习框架的有效性。
本试验在具有Intel I5 3.4 GHz GPU,16 GB RAM和GTX 1050Ti GPU的PC上进行100 000次迭代训练,需时14.4 h。
1.4 算法性能评价
在显著性评价指标中,本研究采用F-Measure分数作为评价指标之一。F-Measure分数常被用来评价算法是否有效,其为准确率与召回率的加权调和平均值。F-Measure越高,代表显著性区域预测结果越接近基准标注标签图像。具体操作步骤为:先将显著性区域图像进行二值化(每一个分割阈值均属于[0,255]),然后进行F-Measure分数的评估。计算公式为:
(6)
式中:Fβ为F-Measure分数,其中β为固定参数,用于调节F-Measure中P和R的占比,本研究中β2设置为0.3;P为算法精度;R为算法召回率。
第2个评价指标为平均绝对误差(MAE),计算公式为:
(7)
式中:W和H分别为图像的宽度和高度,S为预测的显著性矩阵,GT为真实二进制掩模矩阵。
2 结果与分析
2.1 所提算法的融合效果
本研究将拟采用的预测框架中的整个显著性区域预测算法拆分为两个独立的部分:(1)基于高级视觉特征提取网络预测显著性区域算法;(2)基于低级视觉特征提取网络预测显著性区域算法。在MSRA10k数据集下,分别利用基于整合特征、低级视觉特征、高级视觉特征的显著性区域算法进行100 000次迭代训练,在保证相同预处理和超参数的试验前提下,利用所有6个数据集(SOD、ASD、SED2、ECSSD、HKU-IS和THUR)作为测试集进行F-Measure指标对比,以验证特征融合的重要性,结果见图3。
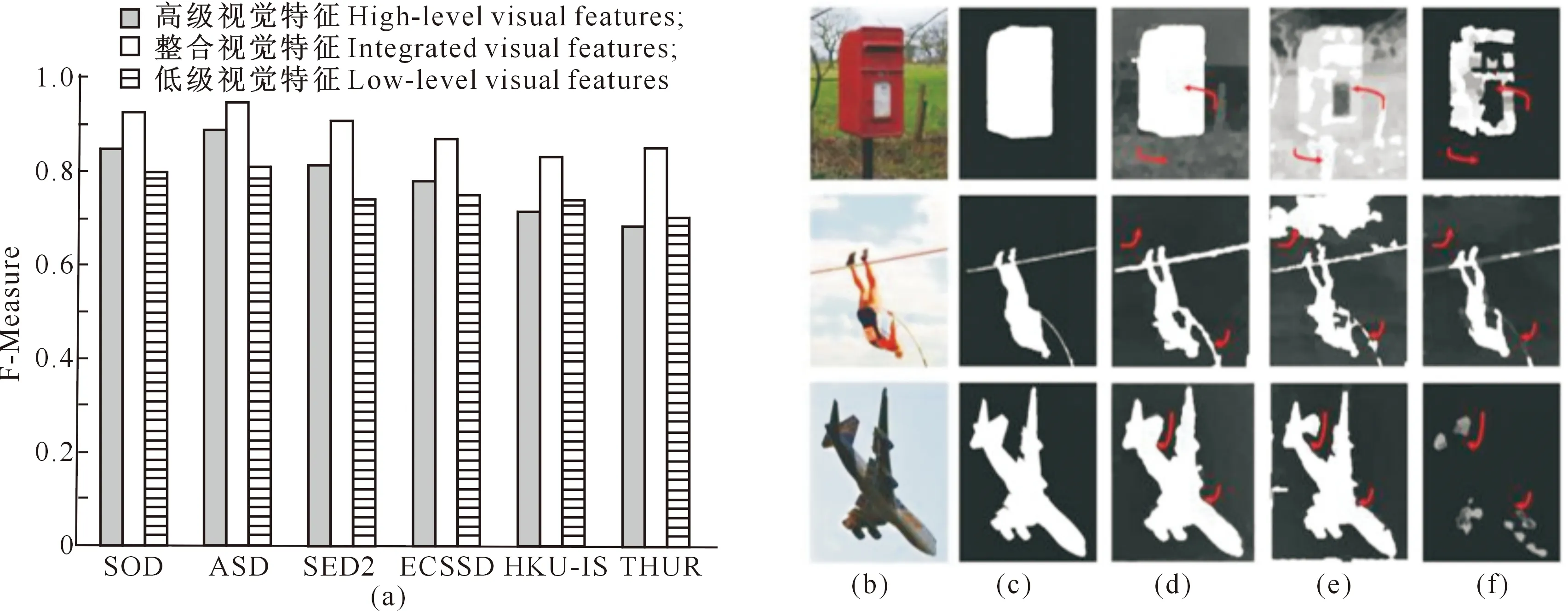
a.F-Measure;b.原始图像;c.人工标注的基准标注图;d-f.使用整合视觉特征、低级视觉特征和高级视觉特征的显著性区域预测结果a.F-Measure;b.The original image;c.The benchmark annotation map of manual annotation;d-f.The significant region prediction results using integrated visual features,low-level visual features and high-level visual features respectively图3 6种数据集基于整合特征、低级视觉特征和高级视觉特征的显著性区域预测性能比较Fig.3 Performance comparison of salient regions predicted by integration features,low- and high-level visual features based on 6 data sets
如图3-a所示,基于整合特征的显著性区域检测算法,在所有6个数据集(SOD、ASD、SED2、ECSSD、HKU-IS和THUR)上的F-Measure分数均高于单独基于低级视觉特征或高级视觉特征的显著性区域预测算法。特别是在THUR数据集上,基于整合特征的显著性区域检测算法的F-Measure得分较基于高级视觉特征算法提高了0.170,较基于低级视觉特征算法提高了0.150。
此外,部分显著性区域预测结果如图3-b-f所示,其中图3-b是原始图像,图3-c是人工标注的基准标注图,图3-d-f分别为使用整合视觉特征、低级视觉特征及高级视觉特征的显著性区域预测结果。从图3-b-f可以看出,由于整合了高级视觉特征与低级视觉特征,整合特征算法的预测结果较基于高级视觉特征或低级视觉特征的算法更加完整,更接近于基准标签,进一步验证了特征融合对显著性区域预测的有效性。
2.2 预训练模型的贡献度评估
本研究提出的基于整合特征的显著性区域预测算法框架可以与常见的深层网络结构进行灵活结合。为进行预训练模型对显著性预测结果的评估,在保证试验条件相同的前提下,仅将算法中的ResNet101模型结构替换为其他3种深层网络结构模型(AlexNet、GoogleNet、ResNet50)进行评估。在进行100 000次迭代后,其F-Measure结果如表2所示。
由表2可见,在6种数据集上,ResNet101的预测结果均优于其他3种深层网络结构模型,进一步表明,利用ResNet101作为Backbone进行低级和高级视觉特征提取是有效的。
2.3 所构建算法与其他算法的性能比较
本研究使用基于整合特征的显著性区域预测框架与4种显著性检测框架(MWS、IMS、FSN、P-Net)进行了性能对比分析,结果见表3和表4。由表3和表4可见,本研究所用算法的F-Measure在2/3数据集(SOD、ASD、SED2和THUR)的F-Measure分数均高于其他4种算法,平均F-Measure分数为0.823,且MAE指标均较低,表明低级视觉特征和高级视觉特征整合显著性区域预测算法有效。

表3 6个公共数据集上5种算法的F-Measure分数Table 3 F-Measure scores of 5 algorithms based on 6 public datasets

表4 6个公共数据集上5种算法的MAE分数Table 4 MAE scores of 5 algorithms based on 6 public datasets
2.4 所构建算法的可视化效果及评估
本研究显著性区域预测可视化结果如图4所示。图4第2列为基准图像,第3列为本研究算法预测结果,第4~7列分别为4种显著性检测框架(P-Net、MWS、IMS、FSN)预测结果。由图4可以发现,本研究所构建算法能够更加连贯且相对准确地突出图像中的显著性区域,与人工标记的基准图像更相似,表明其具有更好的预测性能。此外,如图4第3行和第4行所示,在背景较为复杂的场景中,相比于其他4种显著性检测框架,本研究提出的算法有效地减少了误分割,其边界区域更加清晰,更加契合基准图像。上述研究结果表明,在存在复杂背景的场景中,本研究所用算法的预测效果更好。
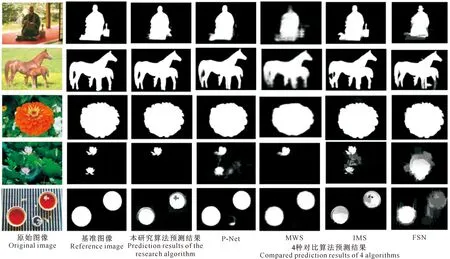
图4 在6种数据集上示例图像及其显著性区域预测结果的比较Fig.4 Comparison of example images and salient region prediction results based on 6 data sets
2.5 典型农业图像数据集的评估
在非结构化的农业领域,本研究算法利用高低级特征的有效融合,丰富地完善了显著性区域信息。本研究利用源于网络的100幅典型农业场景的图像数据集作为测试集进行算法评估,其显著性区域预测结果如图5所示。

图5 典型农业场景图像中显著性区域的预测Fig.5 Prediction results of salient regions in images of typical agricultural scenes
图5表明,本研究所用算法可以有效地应对不同农业场景下复杂背景(近景色、遮挡、光照)的干扰,可以有效忽略复杂背景而提取出目标图像的完整轮廓信息,为后续果实目标及畜禽目标的分割提供无监督参照信息,对农作物生长信息的监测和动物体况的自动评估研究具有一定的意义。
表5显示,本研究所用算法在典型农业场景图像数据集上的平均F-Measure分数为0.826,高于其他4种算法,表明该算法可以应用于典型的农业领域,以期可以有效捕捉农业场景的目标信息,为现代化农业果实采摘、畜牧业精准养殖的发展奠定良好基础。

表5 典型农业场景图像上5种算法F-Measure分数的比较Table 5 F-Measure scores of 5 algorithms based on typical agricultural images
2.6 不同算法运行时间
本研究采用新算法是为了解决显著性检测的精度和鲁棒性问题。一般而言,运行时间随着算法的复杂性而增加。在测试算法的精度和鲁棒性时,本研究在相同的软件和硬件环境下,比较了该算法与其他算法在时间复杂度上的差异,结果表明,在不同的数据集中,检测图像所需时间并不相同。其中MWS、P-Net框架用时较短,显著性区域预测时长分别为2.125和1.528 s,而本研究所用算法的显著性区域检测时长约为2.526 s。这主要是由于该网络结构更为复杂,且本研究更加注重于低级视觉和高级视觉特征的提取质量。因此网络的复杂度进一步加大,导致需时稍长。按图像需求改变网络结构的复杂性,以有效缩短检测时长,是以后研究的方向。
3 结 论
本研究提出了一种基于高级与低级视觉特征整合的显著性区域预测深度学习框架,并与其他的深度网络结构框架进行了测试与比较。结果表明,本研究提出的显著性区域预测算法优于其他4种显著性预测算法,在6种公共数据集上的平均F-Measure分数最高,为0.823,平均MAE分数最低,为0.099,显著性可视化结果边界完整,与人工标记的基准图像更相似;在典型农业场景图像数据集上的平均F-Measure分数为0.826,可以有效地应对农业场景下复杂背景的干扰,提取出目标的完整轮廓信息,证明所提出的算法可靠,可以应用于农业场景下的显著性区域预测。
