基于知识和数据融合驱动的设备故障诊断方法
2022-02-25高立超孙跃华冯显宗季海鹏
刘 晶, 高立超, 孙跃华, 冯显宗, 季海鹏
(1.河北工业大学 人工智能与数据科学学院 天津 300400;2.河北省数据驱动工业智能工程研究中心 天津 300400;3.天津开发区精诺瀚海数据科技有限公司 天津 300400;4.北京起重运输机械设计研究院有限公司 索道工程事业部 北京 100007;5.河北工业大学 材料科学与工程学院 天津 300400)
0 引言
工业4.0背景下,机械设备日趋大型化、结构复杂化、运行自动化和智能化,一旦某些部件出现故障,可能导致整个设备出现问题,因此准确的故障诊断和预测日益重要,成为智能制造领域的研究热点。目前设备故障诊断通常分为机理建模方法和数据驱动方法。郑近德等[1]提出了一种适合非线性和非平稳信号分析的自适应经验傅里叶分解方法,解决了经验模态分解与傅里叶分解方法在分析非平稳信号方面的不足。刘晶等[2]提出了基于过采样决策树的冷风阀调节预测模型和基于LSTM-BP共享权值神经网络入口阀与旁通阀调节预测模型,实现了数据融合驱动的余热锅炉阀门调节。上述方法都取得了较好的效果,但是在实际应用中单一利用设备机理知识或设备运行数据难以解决多复杂工况、多故障类型、数据关联的设备故障问题。目前经常将基于知识图谱的方法用于复杂关联挖掘与表示问题,因其知识关联性强以及查询便捷等优点被广泛应用于语义网络训练。但在故障诊断领域,存在数据离散无法构建图谱、结构化设备数据与非结构化技术工人经验难以结合等问题。
为解决上述问题,提出一种基于知识和数据融合驱动的设备故障诊断方法,该方法通过提取设备机理、经验知识规则建立故障知识图谱,利用优化的长短期记忆网络(long short-term memory,LSTM)进行数据分类,最终形成知识和数据融合驱动的故障诊断模型。与现有方法相比,该方法实现了从单纯依赖机理知识或数据驱动的模型到数据驱动与知识引导相融合驱动的故障诊断,进一步形成故障图谱诊断系统,可以进行辅助决策以及故障详细信息展示。
1 双融合驱动的设备故障诊断方法
目前,已有国内外专家将知识图谱与深度学习融合的方法应用于不同领域。陈彦光等[3]利用文本分类和信息抽取技术构建面向刑事案例的知识图谱,基于所构建的知识图谱,可实现对相关案件关键情节和判决结果的统计应用,为司法文书的智能化处理提供数据基础。昝红英等[4]通过收集多来源医疗文本,在人工标注的基础上,进行实体及关系自动抽取,构建了中文医学知识图谱CMeKG1.0版。Wang等[5]提出了一种知识图注意力网络的方法,以端到端的方式显式地对图谱中的高阶连接关系进行建模,从而将多个具有链接属性的项目连接以提高推荐准确率。上述方法在不同领域取得了良好结果,但在设备故障诊断领域,由于设备具有较强的机理知识,且运行数据之间存在关联性,因此传统的图谱构建方法对于构建设备故障诊断领域图谱适用性较差。基于设备故障诊断的特殊性,本文提出基于知识和数据融合驱动的设备故障诊断方法(fault diagnosis method for equipment driven by knowledge and data fusion,FDM-KDF),该方法有效地将机理知识与设备运行数据相结合,构建了设备故障诊断领域图谱,并提高了多类型故障情况下的诊断准确率和收敛速度,实现了机理知识与数据驱动相融合的多故障类型诊断模型优化。
1.1 FDM-DF方法框架
FDM-KDF方法框架如图1所示,整体结构分为两部分:基于融合规则链知识图谱模型(knowledge graph model based on fusion rule chain,KG-FRC)和优化的双向长短时记忆网络模型(optimized bidirectional long-short memory network model,OBiLSTM)。第一部分针对设备运行数据提取最值、平均值等特征作为节点属性,针对设备机理、经验知识提取规则,符号化知识作为规则节点,并将节点属性与规则节点结合完成KG-FRC中的实体提取;第二部分将规则节点作为分类依据,结合设备运行数据进行数据标注,通过OBiLSTM模型进行分类训练,完成KG-FRC中的关系抽取。根据图谱实体节点之间关系构建三元组,通过关系三元组连接构建KG-FRC故障图谱。
1.2 基于融合规则链的知识图谱模型
基于融合规则链的知识图谱模型将实体化故障机理知识作为图谱节点,提取设备运行数据传统特征作为节点属性,并通过OBiLSTM模型获取故障分类作为KG-FRC中不同层级节点的分类关系,最后将分类关系和规则节点融合构建KG-FRC,构建过程如图2所示。
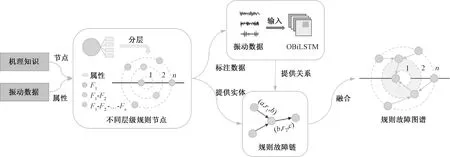
图2 KG-FRC模型构建过程Figure 2 KG-FRC model building process
首先,针对机理知识进行规则总结,提取出可作为分类依据的指标1(f1)、指标2(f2)…,直到指标n(fn),选用不同数量的指标组合生成相应层级的一级故障节点F1、二级故障节点F1-F2、n级故障节点F1-F2-…-Fn,同时提取设备运行数据特征作为节点属性。其次,针对设备运行数据依据规则节点进行标注,通过OBiLSTM模型对设备运行数据进行故障分类,预测生成不同层级节点关系;再次,以下级故障节点、关系、上级故障节点三元组形式保存规则节点以及节点关系,将1级至n级故障节点连接,构建包含了节点信息以及节点间关系规则故障链;最后依据节点层级间关系,将多条规则故障链融合成完整的规则故障图谱。
针对设备机理知识,将设备数据的尺寸、位置、损伤深度等指标作为分类依据进行规则总结,并将总结出的指标与属性名称符号化,把指标符号进行组合,作为规则节点。一级故障节点F1取最小数量指标作为节点划分的依据,代表实体描述抽象且分类数少;在F1基础上增加设备指标得到更准确的二级故障节点F1-F2,乃至加入所有指标组合的n级故障节点F1-F2-…-Fn,上级故障节点即代表实体节点,则更加具体且分类数多。相同等级的故障节点划分为同一层级,节点等级取决于数据指标种类数量,下级节点和上级节点是隶属的关系,代表上级节点进一步分类为下级节点,多层级节点组合形成树型结构。
通过OBiLSTM模型对标注的设备运行数据分类后,得到准确的故障类型,并以此为依据确定不同层级的故障规则节点间的关系。节点实体与关系通过三元组形式表达,各实体通过关系R互相连接成规则故障链,以此串联不同层级的节点,连续的三元组(F1,R1,F1-F2)、…、(F1-F2-…-Fn-1,Rn,F1-F2-…-Fn)组合成为层级1~n的规则故障链。作为分类依据的设备指标均有多种取值,同层级的节点为指标类型相同、指标取值不同,依次将不同指标取值的同层节点与对应的上一级节点关联,实现多条故障链融合为完整的知识图谱。
基于KG-FRC图谱进一步构建故障图谱诊断系统,该系统不仅可以对设备运行数据进行故障诊断,还可以展示该故障节点的详细信息以及与该节点有关联的故障节点。
1.3 优化的双向长短时记忆网络模型
相比其他神经网络结构,LSTM属于时间序列模型,能够有效地提取设备运行数据的时间和空间特征,因此选取LSTM作为诊断模型比CNN等其他神经网络对于设备故障诊断更有优势。但是随着LSTM模型分类数量上升,其准确度会降低,本文提出使用双层双向LSTM模型进行强化学习。针对特征图谱分类过多导致传统模型准确率下降以及收敛速度较慢等问题,提出使用CNN、注意力机制(Attention)进行特征提取强化。加入Dropout层防止模型出现过拟合问题,并加入批归一化(BN)层提升模型训练时的迭代速度。综上所述,针对时序设备运行数据,存在传统模型训练时间过久、分类准确率低、迭代速度低、过拟合等问题,提出优化的双向长短时记忆网络模型(OBiLSTM)。通过分类模型进行故障分类、关系提取,输入是KG-FRC模型不同层节点的标注数据,经由第一层CNN卷积特征提取以加快迭代、提升准确率;第二层BiGRU_1层传播学习权值;第三层BN+Dropout层正则化权值并预防过拟合;第四层注意力机制以强化特征提取;第五层BiLSTM_2 层进行强化训练;第六层重复正则化预防过拟合;最后通过Softmax层进行分类结果映射,具体模型参数如表1所示。
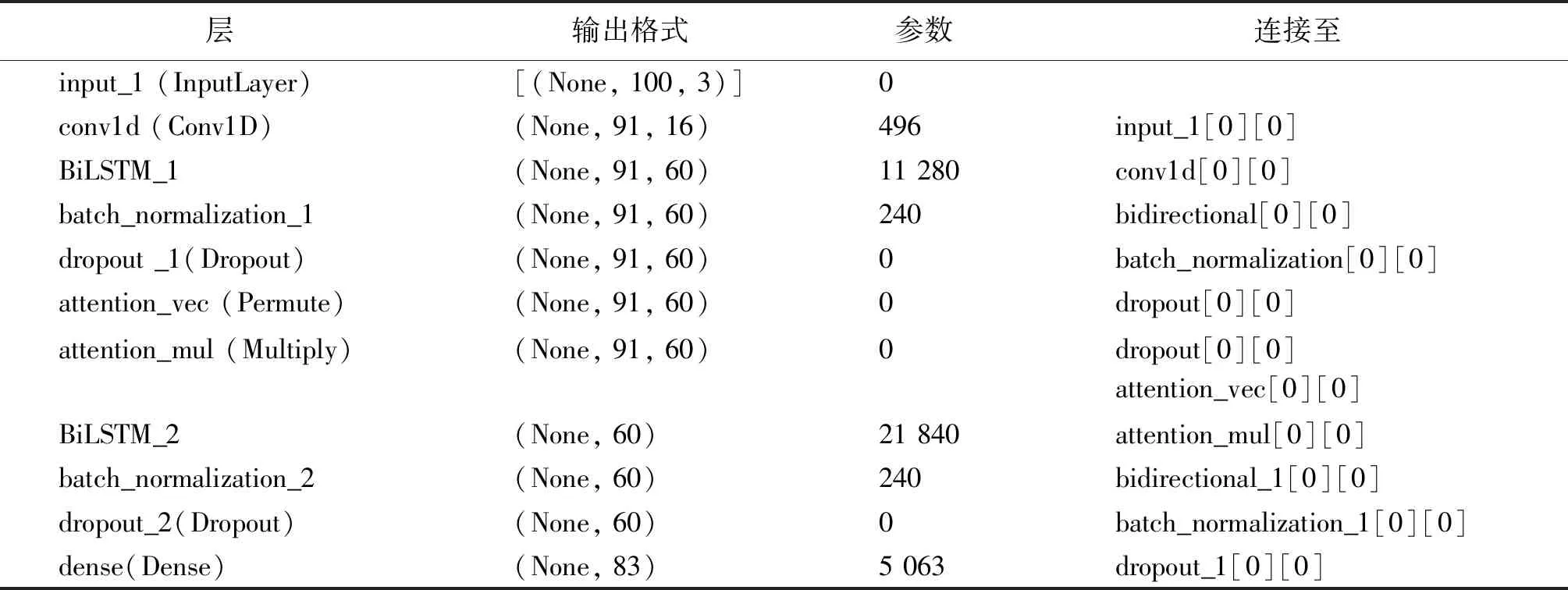
表1 OBiLSTM模型参数Table 1 OBiLSTM model parameter
OBiLSTM模型与传统的CNN和LSTM模型相比,优势在于加入BiLSTM对数据的上下文信息进行权重计算,比传统LSTM神经网络能学习到更多的数据特征,提高了对时序数据的特征提取和分类诊断准确率;加入Dropout层和批量归一化层,规范特征数据并避免模型出现过拟合;引入注意力机制,使得数据特征提取过程中,对中间层产生的多维特征数据通道进行加权,从而提高OBiLSTM模型训练收敛速度及故障诊断效率要求。模型算法如下。
算法1 OBiLSTM模型提取振动数据关系
输入:TrainList=[{x1,y1},{x2,y2},…,{xn,yn}],batch
输出:GQ
1)FUNCTION Relationship classification (TrainList,batch)
2) FOR X IN TrainList do
3) (x1,x2,…,xn)←process.slice(X)
4) {Xtrain,Ytrain},{Xval,Yval}←random.sample((x1,x2,…,xn),sampleNum)
5) FOR i IN batch do
6) ArrtTrain←OBILSTM(Xtrain,Ytrain)
7) {Gx,Gy}←update(ArrtTrain,Xval,Yval)
8) END FOR
9) GQ.append({Gx,Gy})
10) END FOR
11)RETURN GQ
12)RETURN FUNCTION
算法输入是不同分类数下的标注振动数据集合TrainList和训练轮次batch,输出是不同分类数下对应的数据分类类别集合列表GQ;算法第2)行表示遍历所有不同分类数的振动数据集;第3)~4)行表示对振动数据进行处理,将连续的数据切割为长短相同的时序片段,并划分训练集和验证集;第5)~8)行表示对训练集进行迭代训练batch次,通过OBiLSTM模型获取数据分类关系{Gx,Gy};第9)行表示向分类关系列表中添加当前分类数下各振动数据的分类关系。
2 实验
2.1 实验数据
本实验主要分为KG-FRC的构建和OBiLSTM分类预测两部分。KG-FRC方面采用Neo4j图数据库进行存储,并通过py2neo实现python程序对Neo4j的操作。OBiLSTM方面使用TensorFlow-CPU和keras包进行模型训练。
实验采用美国凯斯西储大学(CWRU)滚动轴承故障数据集(http:∥csegroups.case.edu/bearingdatacenter/home),已有国内外数篇论文通过该轴承数据集验证其算法[6-7]。该数据集的机理知识主要为对振动数据的介绍,振动数据分别通过加速度传感器在轴承驱动端和风扇端以及电机基座采集振动信号数据,机理知识中的设备特征有:电机负载分别为0 hp、1 hp、2 hp、3 hp;所对应的电机旋转速度分别为1 797 r/min、1 772 r/min、1 750 r/min、1 730 r/min。通过人为电火花加工分别在轴承内圈(Inner race)、滚珠(Ball)、轴承外圈(Out race)制作出单点损伤故障,每种故障包含故障尺寸为 0.007 inches(轻度损伤)、0.014 inches(中度损伤)、0.021 inches(重度损伤)。轴承外圈的损伤点分别设在3点钟、6点钟、12点钟三个位置。振动频率有12 kHz和48 kHz两种。本次实验将以上振动数据的机理知识作为FDM-KDF方法的文本描述部分进行图谱实体抽取,不同特征下对应的轴承振动数据作为结构化数据进行故障分类以及关系抽取。轴承正常数据只提取了驱动端加速度传感器和风扇端加速度传感器样本,传感器的采样频率为12 kHz。
2.2 KG-FRC模型实体提取
本次实验只选取12 kHz数据,分类特征包括振动端(end)、轴承零件位置(location)、损伤深度(size)、电机旋转速度(电机负载load)、损伤点钟(clock)共计5种轴承特征,根据轴承数据集进行规则总结,总结的规则如下:
① 故障分为驱动端和风扇端两大部分;
② 驱动端和风扇端都有着滚动体、内圈、外圈故障;
③ 滚动体、内圈、外圈故障数据都有损伤深度、损伤点钟、运转负载等特征;
④ 每份振动数据都是由轴承驱动端和风扇端以及电机基座三通道数据组成。
根据规则进行名称符号化,如表2所示,“-”表示无下级分类。
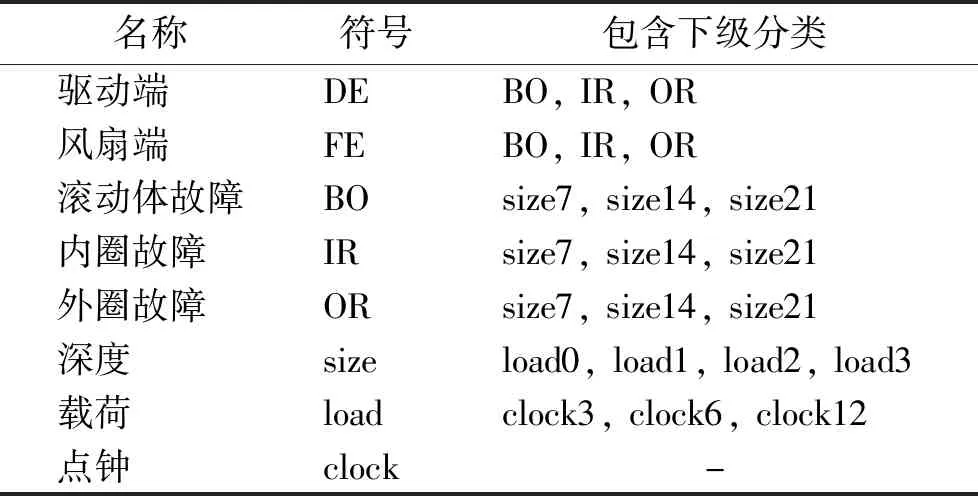
表2 规则名称对应表Table 2 Rule name correspondence table
据以上规则,则有五层故障节点如下。
一级故障节点(fault_level_1):end,共2类;二级故障节点(fault_level_2):end_location,共6类;三级故障节点(fault_level_3):end_location_size,共18类;四级故障节点(fault_level_4):end_location_size_load,共72类;五级故障节点(fault_level_5):end_location_size_load_clock,共97类。此处五级故障节点应有216类,因CWRU数据中部分数据缺少点钟(clock)这一轴承特征,97类真实数据节点可通过训练数据分类得到,剩余119类代表预设节点,可通过后续增加对应的训练数据填充,另外加入故障(fault)节点作为所有节点的最上级节点。
录入知识图谱的属性有节点ID(nodeID)、名字(name)、节点类型(type)和节点描述(describe),部分节点节选如表3所示。

表3 部分故障节点Table 3 Partial fault nodes
根据分类导入CWRU数据并进行初步处理,分别提取三个通道数据的最值、平均值以及标准偏差。将提取的特征作为故障特征节点属性存入节点表格,并将表格存入csv文件。
2.3 OBiLSTM模型关系分类
通过OBiLSTM模型对故障类型进行准确分类,并根据分类结果构建KG-FRC图谱关系。根据上一小节KG-FRC提供的分类节点类型,将训练集分别划分为6类、18类、72类、97类进行数据标注,取100个数据点为一个时序片段。每个类型数据量约有12 000,即每个训练集取1 200个时序片段进行训练。
针对分类类别多、收敛速度慢问题,本文提出OBiLSTM模型,进行对比的传统模型有:单层LSTM和CNN+单层LSTM[8]。以上模型进行训练时采用参数一致,训练模型时将训练集分为多个批次,批次大小(batch_size)为128,每轮迭代训练输入一个批次的数据,损失函数为softmax的交叉熵,以Adam作为优化器来调整训练参数,一共迭代70轮。
训练集、验证集和测试集的比例为6∶2∶2,抽取的时候采取随机采样的方式切割各个集合,并采取从多余的样本中随机采样的方式进行数据平衡,使得每种分类训练样本量相同。评价标准采用以下参数:
① 准确率(Accuracy),表示在预测结果中,正确预测的数量/样本总数。
② 损失(Loss),损失函数在最后一轮时的大小。
③ 收敛速度(ConvergenceRate),训练过程中准确率提高的速度,本文以达到准确率90%的迭代次数作为评判收敛速度的标准。
OBiLSTM模型97类故障准确率如图3所示,OBiLSTM模型在训练集和测试集最多分类数(97类)时分类结果良好,波动较小并无较大差异,则此模型无过拟合、欠拟合等问题。

图3 OBiLSTM模型97类故障准确率Figure 3 Accuracy of class 97 fault of OBiLSTM model
图4和图5为不同分类数下LSTM与OBiLSTM模型的准确率,可知分类数越多时分类效果越差,LSTM模型收敛速度慢、分类数多时准确率降低。模型准确率对比如表4所示,对比可知OBiLSTM模型表现出不同分类下准确率相近的稳定性。收敛速度快且准确率高。其原因在于OBiLSTM使用双层双向LSTM强化特征学习,使得多分类下效果同样明显,并使用CNN和注意力机制提升收敛速度。
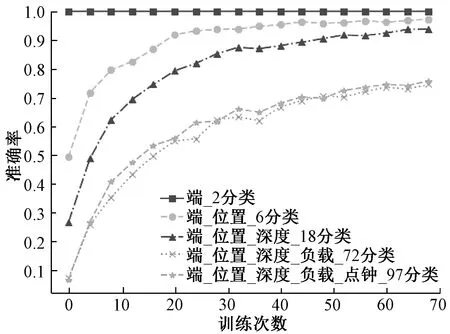
图4 LSTM各层分类准确率Figure 4 Accuracy of each layer of LSTM
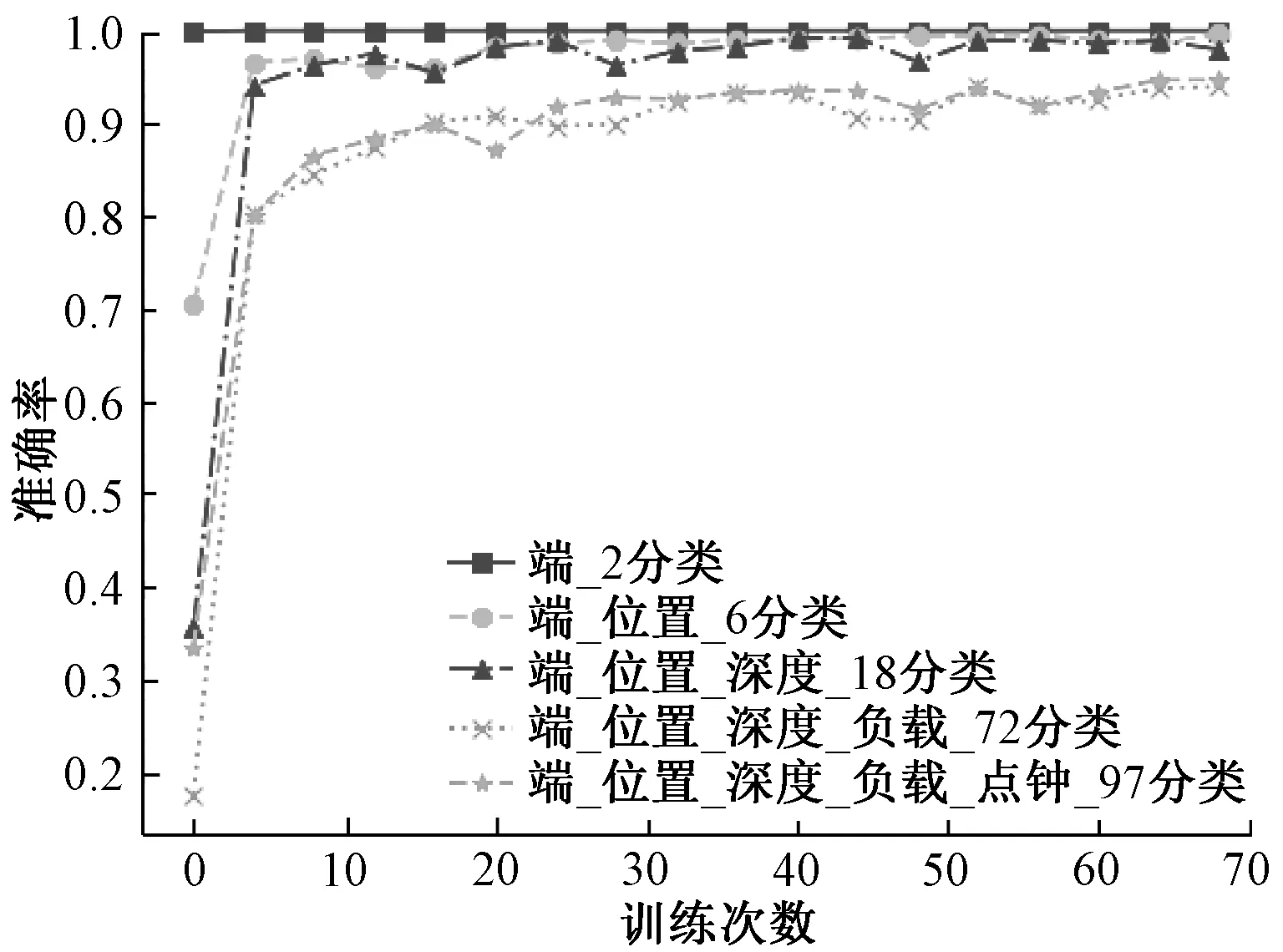
图5 OBiLSTM各层分类准确率Figure 5 OBiLSTM classification accuracy of each layer

表4 各分类准确率对比Table 4 Comparison of classification accuracy
选取分类数最多层(97类)进行比较,OBiLSTM模型与LSTM模型、CNN+LSTM的准确率如图6所示。各个模型的相应评价如表5所示,其中“-”表示无达到准确率90%的代数。
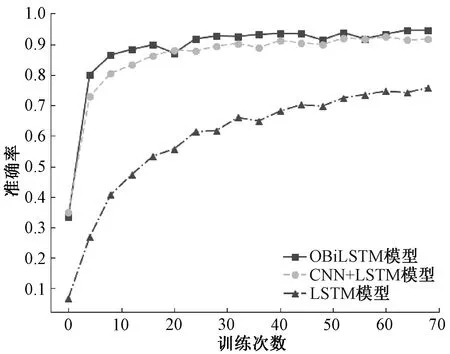
图6 97类故障分类损失Figure 6 Class 97 fault classification loss
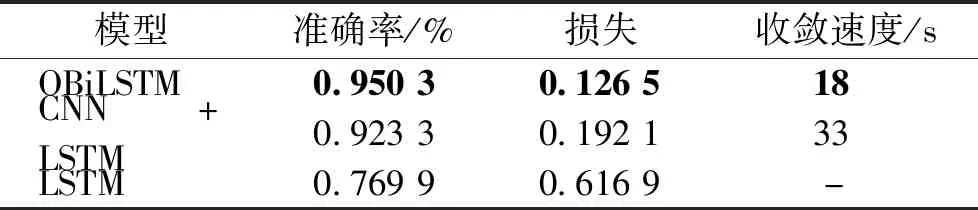
表5 各模型参数评价Table 5 Evaluation of model parameters
由图6及表5可知,与传统的CNN+LSTM以及LSTM模型相比,OBiLSTM模型准确率最高。收敛速度最快。
由此可知,OBiLSTM模型在多分类问题上有着准确率高、损失小、收敛速度快、分类稳定的综合优点,解决了上文提出的分类问题。具体分析,开始的CNN层起到了特征提取的作用,从而提高收敛速度和准确率;第二层的BiLSTM层起到了分类划分训练作用,在保证高准确率同时提高训练速度;第三层的注意力机制层通过分配权重进行特征提取,从而提高训练速度和收敛速度;第四层的BiLSTM层对注意力层的结果进行强化训练,在准确率和损失方面优化;两层BiLSTM层后的正则化与Dropout有效减轻过拟合问题,提高模型的泛化能力,保证了方法的稳定性。
2.4 KG-FRC模型故障链构建
实体化知识作为故障节点,并从运行数据中抽取节点关系后,进一步可构建基于融合规则链的知识图谱。其中故障节点包含该故障类型的文本信息和传统数据特征,节点关系包含不同指标参数下的运行数据之间的关联,并通过故障链的形式将两者结合起来,所有的故障链融合得到完整的故障图谱。以CWRU轴承故障数据为例,完整的一条故障链如图7所示。
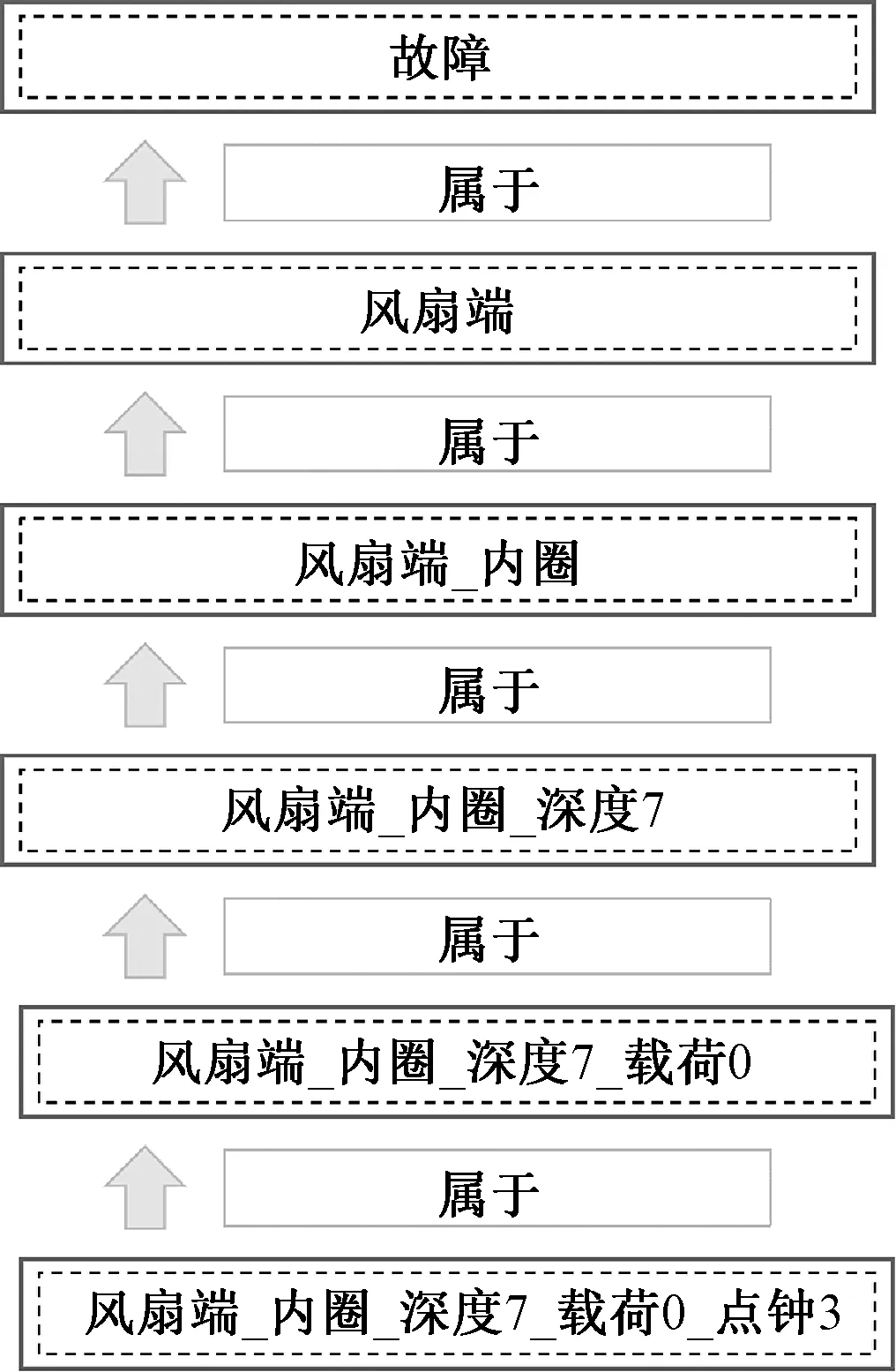
图7 故障链Figure 7 Example of rule fault chain
该故障链中节点分别为一到五级故障节点,下级故障节点与上级故障节点之间存在隶属关系,通过OBiLSTM模型分类结果确定。
抽取的规则故障链通过三元组进行表达,同样转化为csv表格存储,关系节点属性有起始实体节点(start_entity)、起始节点标签(start_label)、结束实体节点(end_entity)、结束节点标签(end_label)、关系类型(relationship),节选部分故障关系如表6所示。
通过导入neo4j表3实体节点和表6关系节点csv文件即可形成由上述故障链组成的知识图谱,通过py2neo包操作neo4j,使用python程序读取csv文件,将节点导入neo4j数据库。通过py2neo和Cypher语言进行图谱数据库的相关操作,将csv文件存储的三元组导入neo4j构建图谱。

表6 故障关系节点节选Table 6 Fault relation node excerpt
KG-FRC图谱可以对设备运行数据进行故障诊断,并可以展示该故障节点的详细信息以及与该节点有关联的故障节点,进一步可以基于此图谱构建设备故障诊断系统。
基于上述方法构建知识和数据融合驱动的设备故障诊断系统,该系统可以通过OBiLSTM模型对导入数据进行故障诊断,并通过KG-FRC模型进行辅助决策,返回故障相关信息进行展示。系统功能包括辅助故障诊断决策、故障数据可视化、图谱展示、相关故障展示等。通过输入上传需要诊断的振动数据文件,系统可通过图谱查询输出故障诊断结果,从而完成故障诊断的辅助决策,并将结果可视化。如图8所示,上传设备振动数据后点击查询,系统显示其故障类型为位于12点钟方向,深度为0.014 inches的风扇端轴承外圈故障。
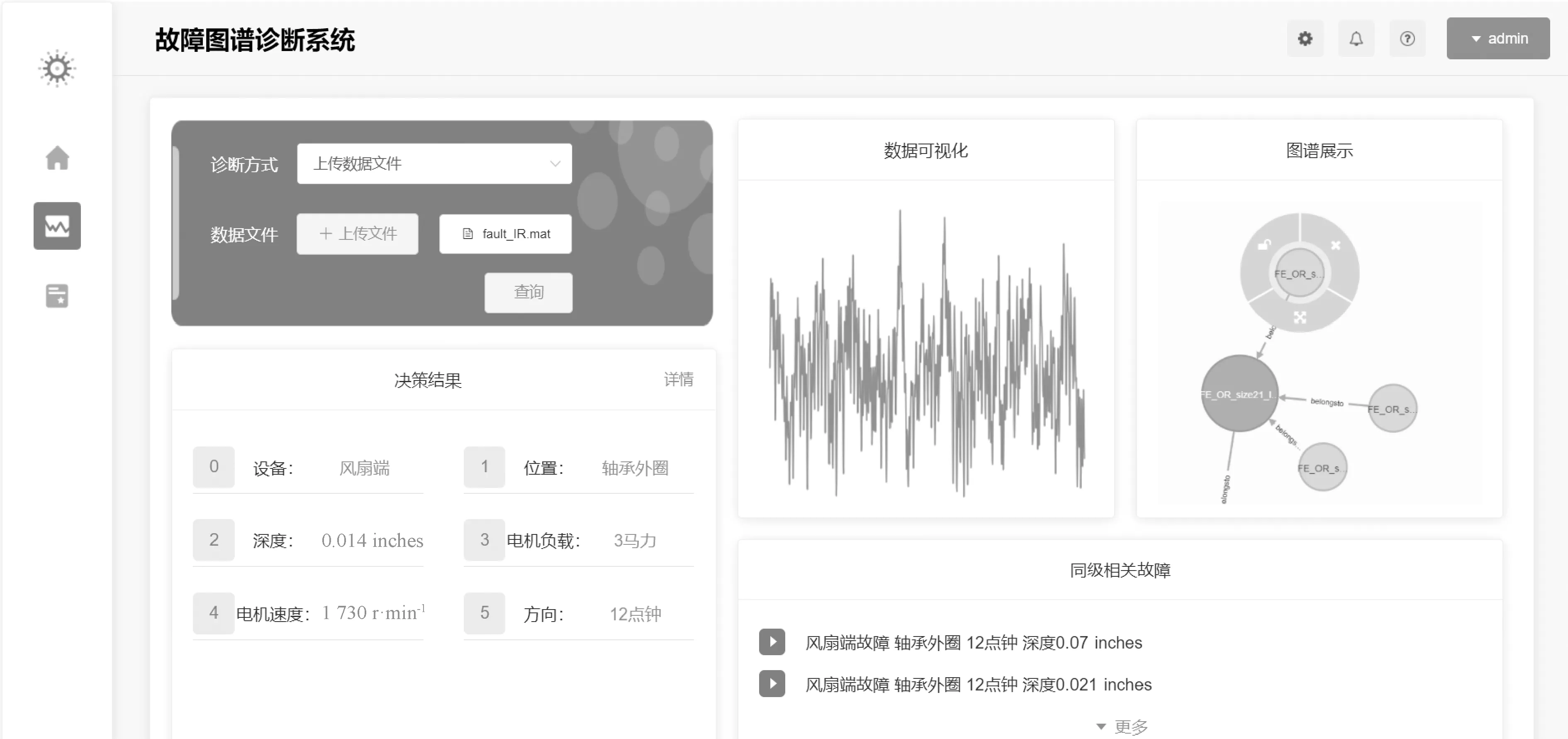
图8 系统分类决策结果Figure 8 System classification decision results
3 结论
针对传统设备故障诊断难以将机理知识与设备运行数据有效结合的问题,提出一种基于知识和数据融合驱动的设备故障诊断方法FDM-KDF。该方法主要分为两部分:第一部分针对设备机理、经验知识提取规则作为规则节点,提取了设备运行数据最值、平均值等特征作为节点属性与规则节点结合,实现KG-FRC中的实体抽取,并结合OBiLSTM模型抽取的数据关系构建基于融合规则链的知识图谱;第二部分将规则节点作为分类依据,结合设备运行数据进行数据标注,通过OBiLSTM模型进行分类训练,完成KG-FRC中的关系抽取。结合两部分得到的实体与关系构建FDM-KDF故障图谱,并基于FDM-KDF方法构建了知识和数据融合驱动的故障图谱诊断系统,该系统可针对设备运行数据进行故障诊断辅助决策,并可视化故障信息以及相似故障。最后,以CWRU轴承故障数据为例进行实验验证,构建了设备故障诊断领域图谱,对于轴承故障诊断多分类的平均准确率达到95.03%,并通过设备故障诊断系统对故障相关信息进行展示。该方法提高了故障诊断准确率和收敛速度,构建了设备故障诊断领域图谱,实现了机理知识与数据驱动相融合的多故障类型诊断。
