特征融合与分割引导的弱监督目标检测
2022-02-25柴文光蔡春波
柴文光,蔡春波
(广东工业大学 计算机学院,广东 广州 510006)
0 引言
近十年来,卷积神经网络(Convolutional Neural Networks,CNN)的发展与大规模、带精确实例级注释的训练数据集(PASCAI VOC[1])的应用,极大地推动了计算机视觉领域的进步。其中,目标检测方向更是在获得飞速发展的同时被广泛应用于AR、人脸识别等具体场景中[2-3]。然而,获取此类数据集往往费时费力,这就阻碍了目标检测技术的进一步发展。故相较于实例级注释,更容易被收集的图像级注释被提出并被进一步运用于目标检测中。因此,利用图像级注释训练检测器的弱监督目标检测(Weakly Supervised Object Detection,WSOD)[4-5]方法成为近年来目标检测领域的研究热点。众多研究者的加入使得WSOD 方法不断地被改进、优化,令其在识别速度或是识别精度上都得到了大幅提升。
最初的WSOD 方法大多基于多实例学习(Multiple-Instance Learning,MIL)[6],其主要是将图像作为一个包(其中一个正包中至少包含一个正实例,而一个负包中的所有实例皆为负实例)、对象建议作为实例,利用这些包训练实现弱监督目标检测器。但是在MIL 中,对于来自同一类的多个对象实例中特定分数较低的对象实例极有可能被判为负实例。此类情况下,所选择的对象实例外观变化与大小差异较小,不足以训练出具有较强辨别能力的检测分类器。此外,在训练过程中,缺失的实例同样可能会被选择为负实例,这将进一步降低检测分类器的识别能力。针对这一问题,近期研究者依据CNN 强大的表征学习能力,提出端到端MIL 网络,如OICR(Online Instance Classifier Refinement)、PCL(Proposal Cluster Learning)等。在 端 到 端MIL 网络中,其将实例分类检测问题视为潜在的包内模型学习(图像分类)问题,通过实例级标签训练分类器以区分正负实例,提取得分最高的正实例。但由于在WSOD 中图像缺乏对象实例级标签,使得WSOD 与全监督目标检测(Fully Supervised Object Detection ,FSOD)方法之间存在巨大的性能差异。
当前,主流的WSOD 方法是利用区域建议生成包含对象的建议,而后根据该建议的特征进行实例学习,实现图像分类与定位。因此,如何获取高质量的区域建议成为目前WSOD 的一大挑战。针对这一挑战,本文提出基于卷积特征多层融合以及分割引导策略的候选建议框生成方法用于获取高质量的区域建议,使得这些建议尽可能多地包含目标。该方法具体过程如图1 所示:①结合EdgeBoxes 选取初始候选框,同时对VGG16 网络各层的特征映射进行融合,利用其边缘结构特征过滤掉无关的建议框;②结合2 阶段获取的建议框经过弱监督语义分割网络,计算分割映射每个建议框得分。此处考虑到一致性准则(只要建议框在目标边界内,则所有建议框的得分应一致),本文给出一种新的目标一致性表示方式。具体地,将分割置信映射投影到水平和垂直两个方向,通过计算得到目标一致性表示。在新的表示中,只要建议框不超过目标边界,得分就始终保持一致。最后,进行MIL 以完成图像定位及分类。相比当前的弱监督目标检测方法,本文方法在具备优秀性能的同时能够轻易地嵌入到其他弱监督目标检测中。
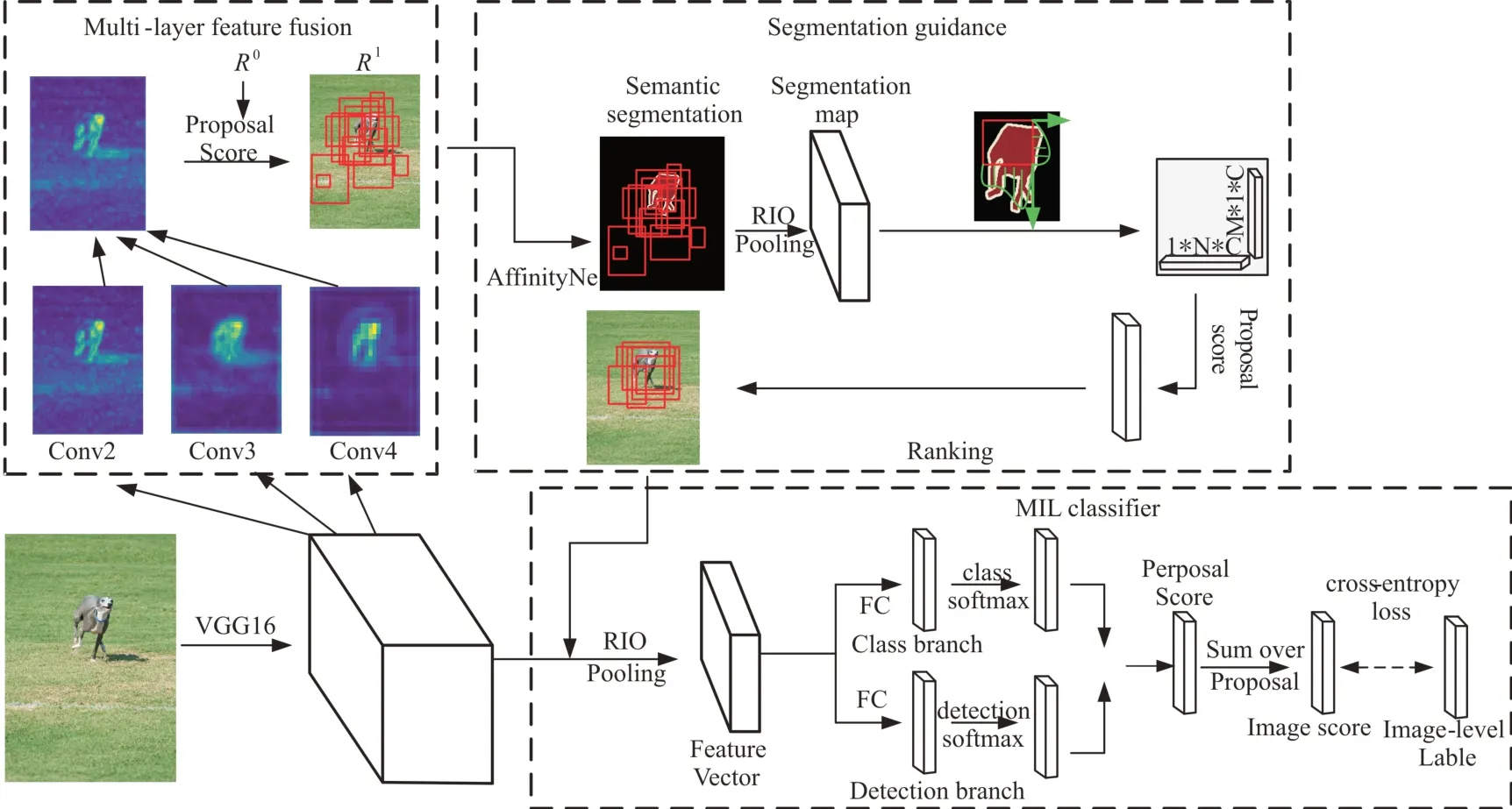
Fig.1 Specific process of the proposed method图1 本文方法具体过程
1 相关工作
1.1 弱监督目标检测
通过在卷积神经网络(CNN)中加入多实例学习(MIL),近年来WSOD 性能得到了显著提高。Bilen 等[4]率先在MIL 中引入端到端弱监督深度检测网络(Weakly Supervised Deep Detection Networks,WSDDN),这激发了许多研究者的兴趣;Tang 等[7]通过引入在线实例分类器优化(OICR),进一步改善了WSOD 的工作,但是其在优化过程中容易陷入局部优化;Tang 等[8]基于图中心聚类和平均MIL 损失函数的方法进一步改进了OICR,以提高WSOD 的检测性能;Wan 等[9]提出一种最小熵潜模型,通过最小化全局和局部熵实现对目标进行分类和定位;Wan 等[10]将连续优化方法引入MIL 中,利用一组平滑的损失函数松弛原始损失函数,成功解决了MIL 中的非凸优化问题。相比之下,本文采用特征融合及目标一致性表示的方法,仅获取少数高质量的建议框就能完成目标检测器训练,并且该目标检测器同样具备优秀的检测性能。
1.2 区域建议生成
关于区域建议生成常用的两种方法是选择性搜索(SS)[11]和边缘盒(EB)[12]。其中,SS 基于超像素合并方法生成建议,但其生成的建议对物体真实边界框的拟合效果普遍不佳。而EB 则通过提取图像边缘,然后评估滑动窗口框的客观得分并生成建议。目前,已有的全监督目标检测都是基于CNN 的区域建议生成方法[13],使用边界框注释作为监督以训练建议网络,利用其精确的注释将边界框回归到真实的目标位置。但是为了保证其高性能,这些方法需要通过有效的边框注释甚至像素级标注[14]以训练网络模型,这与WSOD 在训练时只使用图像级注释的要求有所差异。因此,弱监督训练下生成高质量的建议框更具有挑战性。针对这一挑战,本文基于EB 方法,利用CNN 中的低层信息生成的边缘反馈映射进行多层融合[15],并结合语义分割[16]引导获取高质量的区域建议。实验结果表明,该方法取得了良好的WSOD 性能。
1.3 弱监督语义分割
鉴于弱监督语义分割的优秀特性,Diba 等[17]首次将语义分割嵌入WSOD 中,提出利用分段知识对目标分数较低的建议框进行过滤的级联卷积网络,但其无法有效地对仅包含部分对象的高置信框进行过滤;Wei 等[18]则通过引入两种分割度量,高纯度和完整地完成对建议框的挖掘;Gao等[19]利用分割映射生成具有丰富上下文信息的实例建议;Li 等[20]将弱监督目标检测和分割任务整合到检测—分割循环协同这一多任务学习框架中。本文采用语义分割引导,对分割置信映射进行了修正,以减少外部无关信息的影响,从而获取高质量的候选建议框。具体而言,通过特征融合得到候选建议框,而后采用Ahn 等[21]提出的AffinityNet 提前生成弱监督语义分割结果,结合目标一致性计算每个建议框的客观分数,再将计算结果进行排序,选取得分高的建议作为输入,并将其输入到弱监督目标检测网络训练分类器。
2 高质量候选区域生成
2.1 特征融合
多层特征融合:给定图像,一方面通过EdgeBoxes(EB)获得初始的候选建议框R0={R01,R02,…,R0n},另一方面,利用VGG16[22]网络结构前向传播计算不同卷积层在通道维度上的平均值进而得到卷积的响应映射,并将其调整到原始图像大小进行多层信息融合,得到图像的特征映射;而后将R0映射到图像特征,评估初始建议的客观分数,剔除大部分和背景相应的框。如图2 所示,后面的层往往会响应更多的语义特征,提供局部对象的有用信息,这些层的响应映射与显著图相似。利用第二层到第四层特征为建议框生成类似边缘的响应映射。基于卷积层输出的特征映射F∈ℝC×W×H,其中C、W、H 分别代表通道、宽、高,响应映射M∈RW×H由式(1)计算所得,fcwh、mwh分别代表F、M,计算每个通道的平均值,然后归一化。

首先,上述每层卷积特征调整到原始图像大小并将它们相加,得到类似边缘的特征映射;然后,计算每个初始建议框中存在的边的数量以评估初始建议框R0的客观得分,并执行非极大值抑制(Non-Maximum Suppression,NMS);最后,根据客观得分对候选建议框进行排序,选取得分高的框,得到新的集合
2.2 目标一致性表示
通过多层融合生成的候选框仍具有一定的非相关域,因为类边缘的影响映射在背景区域上也有较高响应。为了解决该问题,本文结合分割图像映射选取高质量目标建议,将第一阶段生成的候选框作为输入,经过AffinityNet 生成语义分割结果,从而获得目标建议的集合R2=表示第i个目标建议的宽和高,C表示目标类别。计算分割映射目标建议的客观分数ORi如式(2)所示。


Fig.2 Response and fusion of different convolutional layers of VGG16 network图2 VGG16 网络不同卷积层的响应及融合
f()是计算目标分数的关键因素,f函数的不同表示方法主要有两种:一种是基于分割的上下文方法,一种是目标一致性表示方法。为了获得更多完整目标,文献[17]选择边界框内具有较高建议分数和周围上下文区域较低分数的框。

是Ri周围上下文区域,当框靠近目标的边界时,尤其是对于不规则的目标,上下文客观分数可以忽略不计,即使框在目标边界内,ORi依然会开始减少。
如图3 所示,当R1、R2、R3 同时包围目标区域时,它们的客观得分会随着框的增大而缩小,即OR1<OR2<OR3。为了完善此问题,只要候选框在目标边界内,就需要上下文一致的客观得分,即OR1=OR2=OR3。因此,本文提出了目标一致性表示OCR,将Ri投影到与边界框水平垂直的方向,以获得目标一致的分数OCRSi:
OCRSi=分别表示Si水平垂直方向的投影。Maxy(Ri)分别表示获取水平、垂直方向的最大值。


Fig.3 Object consistency representation图3 目标一致性表示
2.3 弱监督目标检测网络
本文使用弱监督目标检测网络(WSDDN)获取建议分数,用于后续的建议框选择和目标检测器优化。主要工作如下:给一张图像I 及图像注释y= [y1,y2,…,yC],通过区域生成方法获取目标候选框或0 表示图像I 中有或没有目标类别c,C表示类别数量。然后目标候选框经过RIO pooling 得到特征建议向量,经过两个全连接层分别摄入到分类和检测两个平行分支,得到两个矩阵向量,Xcls、Xde t,X∈ℝC×N,然后通过Softmax 层σ(·)沿着纵向类别和横向目标对两个矩阵进行归一化,获取每个目标建议的分类和检测分数。


目标建议的实例级分数按元素乘积计算得到X=σ(Xcls)⊙σ(Xde t),其用于建议选择和目标检测器优化。最后,计算第c个类的图像级预测分数。

对于WSDDN 模型训练,将式(7)中的pc作为第c 类图像的预测概率,采用随机梯度下降方法优化损失函数,分类损失函数为:

3 实验
本文主要在PASCAL VOC2007 数据集进行实验,共9 963 张图像包含20 个目标类别。将数据集切分为包含5 009 张图像的训练集(验证集)与包含4 954 张图像的测试集。实验过程中只使用图像级标签进行训练。以两种指标评估性能:①测试集的平均精度(Average Precision,AP)和所有类别的平均AP(mean of AP,mAP);②CorLoc 对trainval 集进行定位精度评估,即预测框与真实框的重叠率超过50%。本文采用EdgeBoxes 生成初始的目标候选框,将ImageNet 上预训练的VGG16 网络作为主干网络获取图像信息,通过特征融合和分割目标一致的表示方法,在获取高质量候选建议框实验中,证明了其方法的有效性,同时采用WSDDN 进行模型训练。
采用本文方法可以更好地处理对象边界处的情况,产生更完整的检测区域。为验证其有效性,本文将(Intersection over Union)IoU 阈值(预测边界框与真实边界框的IoU)设置不同的参数,观察其性能差距。当IoU 阈值从0.5 提高到0.7 时,结果变化如表1 所示,由这些结果可以得出结论,本文方法能够选择更精确边界的高质量区域框。同时选择近年来优秀的检测方法进行比较,WSDDN[4]、OCIR[6]、PCL[7]、SLV[8]、C-MIL[10]、WCCN[16]、TS2C[17],如表2、表3、表4 所示。与当前优秀的WSOD 方法比较,本文方法在VOC2007 测试集的AP(%)和验证集的CorLoc(%)上展示了其良好结果。同时,如表4 所示,本文方法在定位准确率上展现出非常优秀的性能,能定位更完整的目标对象。图4 也展示了本文方法在图像中的定位效果,图中绿色的框为真实注释框,红色的框为本文检测的定位结果(即IOU>0.5)(彩图扫OSID 码可见)。

Table 1 mAP of different thresholds on the VOC2007 test set表1 VOC2007 测试集上不同阈值的mAP

Table 2 Category detection precision of VOC2007 test set表2 VOC2007 测试集类别检测精度(%)

Table 3 Localization detection precision of VOC2007 validation set表3 VOC2007 验证集定位检测精度(%)

Table 4 mAP of the VOC2007 test set and the localization precision CorLoc of validation set表4 VOC2007 测试集的mAP 和验证集的定位精度CorLoc

Fig.4 Example of object detection图4 目标检测示例
4 结语
本文提出了一种基于特征融合和分割引导的弱监督目标检测,主要通过CNN 网络的底层信息进行特征融合和分割引导的一致性表示方法获取高质量的候选框。同时,提出一种新的评估建议标准,即目标一致性表示,不仅能获取更完整的目标建议框,而且可以很容易地嵌入到流行的弱监督目标检测框架中。与当前优秀的方法相比,在VOC2007 数据集上的定位准确率达到了非常优秀的性能,类别检测精度也达到了同等性能,甚至在单个类别的精度上有显著提升。尽管当前弱监督学习已经取得了不错的性能,但与完全监督学习相比还存在很大差距,但完全监督学习又依赖于精确的注释数据,因此弱监督目标检测研究在生活场景中更具有实用性。下一步研究中,将考虑轻量级的网络结构,增加模型训练速率。
