基于双塔结构的场景文字检测模型
2022-02-24施漪涵仝明磊姚宏扬
施漪涵,仝明磊,张 魁,姚宏扬
上海电力大学 电子与信息工程学院,上海 200090
在自然场景中,文字通常能传递重要的视觉信息,通过对图像中文字区域的检测和识别,能更有效地获取场景中的语义信息,并应用于图像搜索、无人驾驶、工业自动化等领域,文字区域检测作为文字识别的前期工作,其结果将直接影响后期识别的精准度。不同于传统OCR(optical character recognition)字符识别,自然场景中的背景较复杂,且受文字本身及其他干扰因素的影响,较印刷制品而言,检测难度更大。因此文字区域检测的研究仍有较大的提升空间[1-2]。
文字检测的方法通常分为两大类:基于传统方法和神经网络。在传统方法分类中,一类是基于滑动窗口的方法,根据图像的纹理随机生成不同大小的窗口,使其在原图像中滑动,再用分类模型判断该窗口内是否含有文字区域,其典型算法有文献[3];另一类是基于连通域的方法,根据图像的低级特征,比如光强、颜色等,将图像的像素分为不同的连通域,再用分类模型对其进行判断,较为典型的方法有笔画宽度变换[4](stroke with transform,SWT)和最大稳定极值区域[5](maximally stable extremal regions,MSER)。传统方法虽简单、易于设计,但对于倾斜、弯曲文字或不均匀照明区域文字的检测效果不佳[6-7],因此很难应用于含自然场景的图像。
目前,主流的场景文字检测大多基于深度神经网络,其中,基于目标检测技术的算法采用整体性思想,将文字区域视为待检测目标。一些方法如R-CNN[8](regions with CNN features),先提取一系列的候选区域,再对其边界框进行调整、分类及回归;也可直接使用回归算法,如YOLO[9](you only look one)和SSD[10](single shot multibox detector),得到物体的类别概率和具体位置。基于目标检测技术的算法虽在运算速度上较有优势,但其锚点位置估计不够精确,无法得到最准确的检测结果。另一类算法主要针对自然场景中的非水平文字,利用图像分割技术,提高检测准确度。其方法主要是将文字区域视为一个需要被分割的类别,通过语义分割[11]或实例分割[12]方法,生成像素级别的文字/非文字图像,最后通过图像后处理技术,准确定位文字区域,其典型算法有CCTN[13](cascaded convolutional text network)、PixelLink[14]、InceptText[15]等。基于分割技术的文字区域检测,其实质是对像素的分类工作,虽然准确度较高,但耗时较长。
本文使用图像分割技术检测文字区域,在PixelLink算法基础上,增加具有双金字塔结构的特征融合模型,并在损失函数设计中,扩大负样本选取量,通过γ参数调整正负样本权重。算法能在不增加运算速度的同时,优化文字检测的各项实验评估指标。
1 PixelLink检测算法
PixelLink算法整体实现过程如下,首先利用深度学习网络提取特征,并生成2通道的像素预测和16通道的连接预测,即对每个像素点进行文字/非文字的像素分类;接着判断该像素点的8个邻域是否存在文本像素连接,以此得到文本实例分割图;最后提取文本实例的边界框,得到最终检测区域。
该算法的特征融合模块如图1所示,主要基于FPN[16](feature pyramid network),即特征金字塔网络,该网络是目前各类图像处理任务中最常见的特征融合网络。左侧通道可视为神经网络普通的前向传播过程,右侧通道将更加抽象、语义更强的高层特征图经上采样输出,并通过横向卷积与左侧通道中相同大小的特征图融合。这类特征融合网络能很好地传递高层特征中的语义信息,但忽略了由于多次深度卷积造成的特征信息缺失。本文针对特征融合模块,综合考虑网络深度、运算速度、检测效果等多方面因素,对FPN网络补充和改进,提出一种具有双塔结构的特征融合模型。

图1 PixelLink算法的特征融合模块Fig.1 Feature-fusion structure of PixelLink
2 网络结构
本文的整体算法框架采用图像分割思想,其框架流程如图2所示,该算法主要由三个部分组成:特征融合网络、生成实例分割图和图像后处理。

图2 场景文字检测整体框架图Fig.2 Overall frame of scene text detection
首先将输入图像送入特征提取模型,利用VGG16[17]的前向传播通道,提取网络中的文字特征层,并输送至特征融合模块,如图2虚线框所示,该模块包含双金字塔型结构,通过融合更多层网络的特征映射,得到更精细的特征细节,优化输出的特征信息;然后获取相应通道的文字/非文字预测及连接预测后,生成实例分割图;最后在图像后处理部分中,利用传统数字图像处理技术如图像滤波、去噪处理等优化图像分割效果,同时调整一些参数如滑动平均衰减率、正则化衰减率等,提升被检出文本行的准确率,并对分割出的文本区域进行边界框划定。
2.1 特征融合网络
在对原始图像的特征不断浓缩的过程中会损失一定的图像信息,并且边界区域像素的特征相对较弱,极易造成分辨率低、边界分割错误等后果,因此经特征融合模块输出的特征信息会直接影响最终的检测准确度。
FPN网络仅通过一次自下而上的融合路径,传递最高层特征图的强语义信息,经PANet[18](path aggregation network)启发,本文提出一种特征融合方式,具体网络结构如图3所示,主要由三个部分组成:第一,利用FPN网络的融合结果,并增加一条自上而下的新路径。首先通过1×1卷积操作保持左侧四层特征图的尺寸大小不变,即在不损失分辨率的前提下大幅度提高非线性特性;接着使用上采样对上述四层特征图自下而上地进行第一次融合;然后重复对其融合结果做1×1卷积;最后使用降采样将相同尺寸的特征图进行自上而下的第二次融合。这部分网络包含形如金字塔和倒金字塔的组合结构,通过增加网络深度,加强网络对语义信息的获取和提炼。第二,在卷积操作的过程中,利用膨胀卷积,扩大像素的感受野。膨胀卷积起源于语义分割,是为了解决普通卷积神经网络容易存在内部数据结构丢失或空间层级化信息丢失的问题,而使用池化操作容易损失部分信息,膨胀卷积的提出让图像尺寸在不缩减的情况下仍保持其泛化特征,通过将第一次融合结果后的横向卷积替换为膨胀卷积,令卷积输出结果包含更大范围的信息,以更好地保存内部数据结构。第三,在网络中新增一条路径缩短较底层与最高层特征之间的距离。

图3 具有双塔结构的特征融合模块Fig.3 Feature-fusion module with double tower structure
将特征融合的最后一次融合结果Fuse Piont5,与VGG16网络中选取的初层特征Conv3_3相加,以解决在主流特征融合模块中,由于定位信息的丢失,而造成特征无法精准传递的缺陷,充分利用浅层特征层,将特征图的位置信息和语义信息更好地结合并输出。
输入图像的尺寸为512×512,在VGG16网络中提取的各层特征层中,Conv1_1及Conv2_2虽包含更准确的位置信息,但由于其尺寸较大,内存占用较多,会直接影响网络的运行速度,因此仅选取Conv3_3、Conv4_3、Conv5_3进行后续融合工作。特征图尺寸分别为输入图像的1/4、1/8、1/16,第四层卷积层Fc_7被替换为全连接层,大小为输入图像的1/16。
在本文中,简单将该特征融合网络称为“双塔结构”,主要用于改善特征融合结果。传统金字塔结构的网络模型经过较多网络层的传递,特征信息丢失情况较明显,而浅层网络层往往具有较多边缘、形状、定位等特征,对于分割结果意义较大,具有双塔结构的网络模型可以充分补充网络各级特征信息,聚合出更好的特征融合结果。
2.2 损失函数
损失函数用于评价模型中预测值和真实值的差异程度。在图像中,文字通常占据较小的空间,面积越小的文字区域,检测难度越大。为准确检测文字区域,在损失函数的设计过程中需要考虑其特殊性。
文字/非文字的判别,简单来说就是一个二分类任务,但由于文本实例的尺寸各不相同,若对每个像素赋予相同的权重会造成网络检测偏向大面积的文本行,而忽略小面积的文字区域。针对上述问题,本文引用Focal Loss[19]的平衡参数,对正负样本失衡的图像进行损失计算,计算公式如式(1)所示:

其中,y为真实值数据,y′为预测区域经过激活函数的输出,其值在0到1之间。对于普通交叉熵函数,正样本的输出概率越大则损失值越小,反之负样本的输出概率越小则损失值越大。γ参数的引入使得函数不同于普通交叉熵损失函数,能更关注困难、易错分的样本。本文令γ=2,则对于正样本而言,(1-y′)γ的值很小,那么损失函数值也很小;对于负样本而言,预测概率为0.1的结果远比预测概率为0.7的样本损失值小很多,γ参数的引入,令损失函数更加关注难以区分的困难样本。
Pixel Link算法中采用的OHEM[20](online har d example mining)对正负样本数量按1∶3选取并进行训练,仅保留损失值较大的负样本,将一些损失值较小的简单负样本置零,而focal loss的设计将这类损失值也融入到整体损失函数中计算,虽然这些简单样本的损失值较小,但数量较多,其值对最终损失函数具有一定的影响力。通过新增参数对困难样本进行权重分配,满足令损失函数更关注困难样本的要求,并通过对困难样本的不断训练,优化整体网络模型的性能。
在对每个像素进行文字/非文字判别后,分别对其8领域的连接像素进行损失计算。对于连接预测,仅计算判别结果为正的样本损失值,这种判别问题仍是简单的二分类任务,因此选用最基础的交叉熵函数,如式(2)所示。y为真实值数据,y′为预测区域经激活函数的输出。
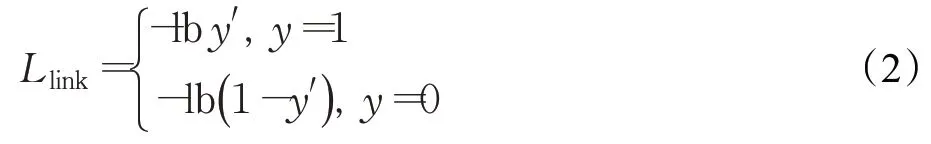
3 实验结果与分析
3.1 实验环境
本文算法使用的实验系统为配置1个GPU型号为GTX Titan X的Ubuntu16.04,显存为12 GB,核心频率为1 075 MHz,CPU型号为Intel Xeon E5-1620@3.6 GHz×8,学习框架选用Tensorflow1.1.0,与PixelLink论文实验环境中含3个同型号的GPU相比,配置较低。根据显存大小将每次迭代输入图像的数量设置为4,该值过小会使网络收敛不稳定,影响实验结果。
3.2 实验用数据集
本算法使用的数据集ICDAR2015及ICDAR2017-MLT均属于ICDAR基准数据集[21],是ICDAR鲁棒性阅读比赛的官方数据集,其中包括文字定位数据库、文字分割数据库、单词识别数据库、端对端识别数据库等。ICDAR2015数据集为自然场景中含文字区域的图片,共有1 000张训练图片与500张测试图片,文字语言为英文,其文字尺度与方向任意,ICDAR2017-MLT数据集同为含自然场景的图片,共有7 200张训练图片和1 800张测试图片,是目前语种最多且包含真实场景噪声的数据集,该数据集较ICDAR2015难度较大。ICDAR数据集在场景文字区域检测的领域中较为流行,因此本文测试结果具有较强的参考意义。
3.3 评估指标
文字区域检测领域内有三项重要评估指标,分别是准确率(Precision,P)、召回率(Recall,R)和综合指标(F-score,F)[22]。其中,准确率为可匹配真值框的预测框占所有预测框的比例,简而言之就是表示预测为正的样本中有多少是真正的正样本,其定义式如式(3)所示:
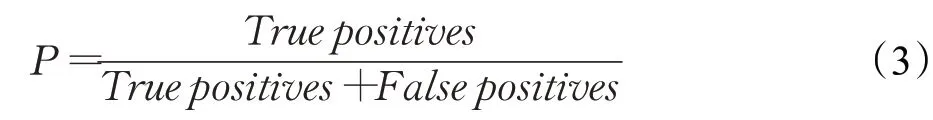
召回率是指可以与预测框匹配的真值框占所有真值框的比例,该评估指标是针对原来的样本,其含义是样本中的正例有多少被正确预测了,其定义式如式(4)所示:
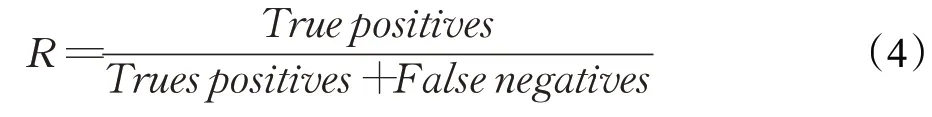
F-score作为综合评估指标,其定义式如式(5)所示,通常,该数值越高,则表示该算法模型越稳定。

准确率与召回率是相对制衡的,随着准确率的增加,召回率会降低,而当召回值增加时,准确率会有所降低。在这类情况下,F-score的引入就显得十分必要,该项指标能直接判断算法的有效性。
3.4 实验参数
本文训练过程不使用预训练模型,设置前100次迭代的学习率为10-3,之后的学习率设置为10-4,使其能在训练初期拥有较大的学习率,加速收敛过程,而后通过较小的学习率,让收敛过程变慢,使网络在最优值附近的一个很小的区域里摆动,以此来优化因训练图像过少而易产生过拟合的问题。
其次,设置滑动平均衰减率为0.999 9,对网络进行滑动平均操作,使其得到的值在图像上更加平缓光滑,避免因某次异常取值而出现较大的波动。对于采用随机梯度下降算法的训练网络,滑动平均在一定程度上能提升最终模型的检测效果。其余的一些参数设置如表1所示。

表1 详细训练参数Table 1 Detailed training parameters
3.5 实验结果分析
相同实验环境和相同实验平台下,在两种数据集上进行测试,为验证各改进点的有效性,在ICDAR2015数据集上逐步对各项改进方法进行叠加测试,并将该实验结果分为三个部分分析,然后将经过不断补充优化的完整算法在ICDAR2017上进行补充实验,最后与目前较为流行的模型进行对比。本文方法的训练过程,未调用上一级实验模型及其他预训练模型,均对网络初始化后,训练相同步数进行对比。
逐步测试结果如表2所示,其中PixelLink*为该算法在本文实验设备环境中复现的实验结果。首先在FPN网络的基础上增加第二次融合路径得到本文方法实验数据,准确度达82.25%,较PixelLink*提升2%,F值也相继提高至79.43%;接着,将网络中后部分的横向卷积替换为膨胀卷积,并新增一条路径将低层强定位信息与高层强语义信息融合得到本文方法+实验数据,召回率提升至78.76%,较改进前提升3%,F值相应提高1.7%,网络稳定性更高;最后,在损失函数的设计中引用γ参数得本文方法++实验数据,准确率提高3.8%,召回率提高1.4%,F值提高2.5%。PixelLink*模型的运算速度为0.54 s/步,本文方法的运算速度为0.42 s/步,并且三次实验数据均优于PixelLink*模型,综合指标逐次提高,因此综合以上在ICDAR2015数据集上的测试对比,本文提出的各项改进方法均有效,且本文方法++在各项评判指标上均优于PixelLink算法,且整体检测效果最好。
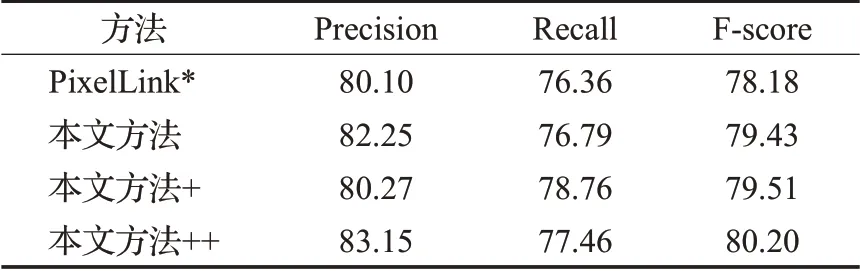
表2 数据集ICDAR2015实验数据Table 2 Experimental data on ICDAR2015%
为验证本文方法的普适性,在数据集ICDAR2017-MLT上进行验证对比,结合数据集ICDAR2015的实验数据分析,仅对测试结果最优的本文方法++进行测试。如表3所示本文方法的准确率为71.56%,召回率为67.8%,F值为70.1%,数据值较低是由于ICDAR2017数据集的数量、语言种类及图像尺寸更丰富,相比ICDAR2015数据集,难度较大,但各项评价指标分别提高3.6%、4.6%、4.8%,因此本文提出的改进算法在ICDAR2017数据集上的优化效果更好。

表3 数据集ICDAR2017实验数据Table 3 Experimental data on ICDAR2017%
将本文方法与近年来其他同类型文字检测方法在ICDAR2015数据集上的测试结果进行对比,进一步验证本文方法的有效性,为加强实验结果对比的公正性,这些方法都采用VGG16作为特征提取器,比对结果如表4所示。其中CTPN算法[23]、SegLink算法[24]及EAST[25]算法[23]均为文字检测领域中较为经典的算法,本文方法的F值分别提高31.6%、6.9%、4.9%,准确度及召回率方面的优势也较明显。PSENet*[26]为目前该算法在TensorFlow框架下训练与测试的最优结果,本文方法准确度提高2.7%,召回率提高3.8%,F值提高3.3%。然而与CARFT[27]算法相比,本文方法在各项指标上还有进一步提升的空间,实验数据差较大的主要原因是CARFT算法的实验过程,使用了经SynthText数据集训练的预训练模型,而本文方法未使用预训练模型。综合以上数据对比,本文方法具有较强的竞争力。
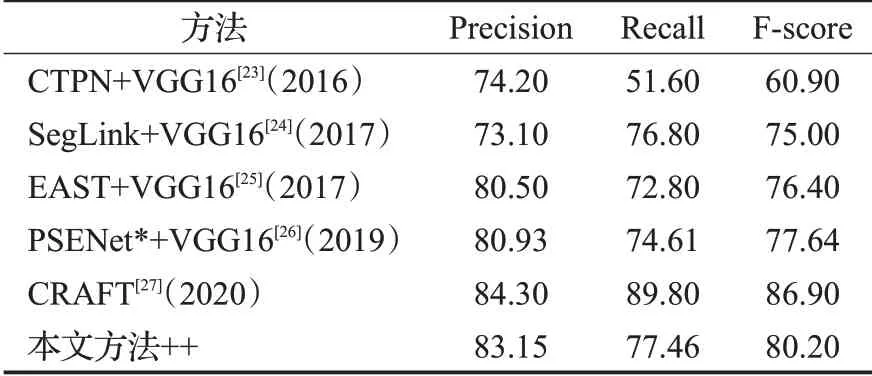
表4 各类文字检测方法实验结果对比Table 4 Experimental results of various text detection methods %
实验可视化结果表明,本文算法对于粘连单词的检测和对错误样本的误判程度均优于原PixelLink算法。如图4所示,对于右上角粘连文字,本文算法能清晰地将其分离成两个单词,图5所示为原算法将非文字区域检测为正样本的误判情况,在使用双塔结构算法的测试结果中得到明显改善。通过对测试图片可视化的对比可得,本文算法提出的利用具有双塔结构的特征融合模型并改进损失函数进行文字区域检测,在准确度和召回率上都有很好的表现,能有效提高自然场景下的文字区域检测准确度,该算法有效可行。

图4 测试图片可视化文字粘连情况对比图Fig.4 Visualization about adhesion of text area

图5 测试图片可视化误判情况对比图Fig.5 Visualization about misjudgment of text area
4 结束语
针对自然场景中的文字区域检测任务,本文提出一种具有双塔结构的特征融合模型,该算法包含两个金字塔型的网络通道,并利用膨胀卷积扩大像素的感受野,同时新增一条路径加强对定位信息和语义信息的融合;在损失函数设计中引入γ参数,增强模型对困难样本的学习能力。实验表明,本文算法能有效提升文字检测准确度,但该方法仍有不足:对中文及弯曲文字区域检测准确率不高。在未来的研究工作中,将进一步考虑对多语言及弯曲文字区域的检测能力,并将本文提出的特征融合模型应用于其他任务,例如行人重识别、立体匹配等,以进一步验证其有效性。
