引入短时记忆的Siamese网络目标跟踪算法
2022-02-24王希鹏梁起明
王希鹏,李 永,李 智,梁起明
武警工程大学 信息工程学院,西安 710086
目标跟踪是计算机视觉研究领域的热点之一,目标跟踪技术被广泛应用于自动驾驶、智能视频监控、军事侦察、人机交互等多个方面。单目标跟踪是指在给定第一帧目标框的情况下,在视频的后续帧中自动地标出该目标的位置和大小。早期的单目标跟踪算法以相关滤波为主,当视频场景中出现感兴趣目标时,滤波器会产生相关响应峰值,而对于背景产生较低的响应值,这类滤波器非常适用于目标定位的应用场景。KCF[1]算法在CSK[2]算法的基础上做出了改进,KCF扩展了多通道特征,采用HOG特征。直到现在,KCF算法依然凭借其速度方面的优势,在工业界被广泛使用。2012年的AlexNet[3]网络的提出是深度学习的开端,之后,深度学习被广泛应用于目标识别和目标检测领域。而在目标跟踪领域,基于深度学习的方法一直无法超过传统算法。近几年,随着目标检测数据集的扩充,跟踪标准的完善,深度学习模型的不断优化,使得基于深度学习的目标跟踪方法取得了很好的成绩。随着深度学习方法的广泛应用,目标跟踪领域也开始考虑引入深度学习模型建立全新的跟踪框架。SINT[4]是第一个使用Siamese网络解决目标跟踪问题的算法。SiamFC[5]算法由于是端到端的跟踪网络,速度方面有了很大的提升,这使得基于Siamese神经网络的跟踪器真正地流行了起来。CFNet[6]与SiamFC中的思路相似,不同之处在于将相关滤波(CF)整合为一个网络层,并将其嵌入到基于Siamese网络的框架中。Dsiam[7]在SiamFC框架的基础上添加了目标外观变换转换层和背景抑制变换层来提升网络的判别能力,增强了模型在线更新的能力。SINT++[8]使用了自编码器和生成式对抗网络来生成多样性的输入正样本块。SA-Siam[9]使用双网络分别学习不同的特征,在网络分支添加注意力机制和多层特征的融合。RASNet[10]同样使用了注意力机制,使得网络可以根据目标的变化而自适应地进行调整。
目前的目标跟踪大多是短时跟踪,而在实际应用场景中,长时间目标跟踪的应用更广泛。近年来,随着LaSOT[11]、TrackingNet[12]等几个数据集的公布,长时跟踪开始受到更多的关注。与短时跟踪相比,长时跟踪中一个视频序列的帧数更多,场景更复杂。大多数长期视觉跟踪前期采用离线训练的Siamese网络结构,因此无法从在线更新得到性能提升。但是,由于长期的不确定性,直接引入在线更新策略是非常冒险的,不一定会得到更好的性能。
长时视觉跟踪比短期跟踪更接近实际应用。在基于相关滤波的目标跟踪算法中,LCMF[13]算法提出利用跟踪置信度APCE进行模板更新,之后的很多基于模型更新的目标跟踪器在APCE的基础上进行改进[14-15]。Wang等[16]提出将相关滤波跟踪器和重检测模块组合成长时跟踪器。Zhang等[17]提出了一种时空感知的相关滤波器,对时空信息进行建模,同时设计重检测机制对大量候选目标框进行采样和评估以优化跟踪结果。基于相关滤波的长时跟踪算法中的重检测机制大多采用粒子滤波采样,计算量大,很难达到实时性要求。
本文针对长时跟踪问题对Siamese网络进行改进,在SiamFC算法的基础上,对网络多层特征进行融合,提升网络对目标的判别性,设计一个短时记忆模块,将响应图加权叠加,使算法更适应目标的动态变化,减少目标的跟踪漂移。为验证本文算法的性能,在OTB2015和GOT-10K数据集上进行测试,与当前6种主流跟踪算法比较,本文算法能够有效提升跟踪性能,在跟踪成功率和精确度上均高于其他对比算法。
1 本文算法
本文在SiamFC的基础上,对AlexNet网络进行多层特征融合,提高了网络的特征提取能力。同时,引入了短时记忆模块,通过视频局部信息增强算法对跟踪目标的判别性,提升目标跟踪性能。
1.1 基于特征融合的Siamese网络
Siamese网络主要用来衡量输入样本的相似性。SiamFC分为模板分支和搜索区域分支,模板分支是输入x大小为127×127×3,经过特征提取网络φ,可以得到一个6×6×128的卷积核φ(x)。搜索区域分支输入z大小为255×255×3,经过特征提取网络φ,得到一个22×22×128的候选区域φ(z)。φ(x)与φ(z)进行互相关操作,得到一个17×17×1的响应图,如公式(1)所示,*代表互相关运算。从响应图中选取响应最大的位置,作为目标当前的位置,进行多尺度测试,得到目标当前的尺度,如公式(2)所示:
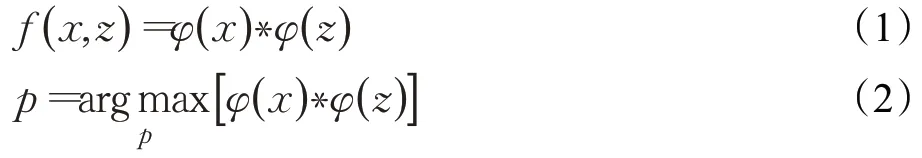
SiamFC损失函数采用logistic损失函数,对于输出响应图中每个点的损失,计算公式如下:
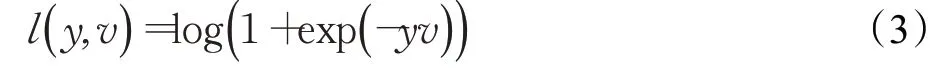
v为网络输出的响应图中每个点的值,y为该点的标签,表示该点是否属于标注的目标,y∈{-1,1}。公式(3)为响应图中每个点的对应loss值,而对于响应图整体的loss,则采用所有点loss的均值,即:

其中,D是得到的响应图,u为D中的某一值,||D为响应图的大小。
特征提取对于目标跟踪非常重要,网络特征提取能力的增强可以提升跟踪精度[18-19]。近些年中,DenseNet[20]和SENet[21]均采用了特征融合的思想,将高层特征和底层特征结合在一起,提升了特征提取能力。将SiamFC算法中AlexNet网络的第三个卷积层得到的底层特征和第五个卷积层得到的高级语义特征进行融合,使最后经网络提取的特征既包含了底层特征,也包含了高级语义特征。表1中列出了网络中各层参数、特征的大小和特征维度,过渡层C6的作用是改变C3层输出特征大小,深度不变,通过步长为1的卷积核使宽和高与C5层输出一致,通过通道数可以看出,输出通道数为C5和C6通道数相加得到的。网络结构示意图如图1所示。

表1 基于多层特征融合的SiamFC网络结构Table 1 SiamFC network structure based on multi-layer feature fusion
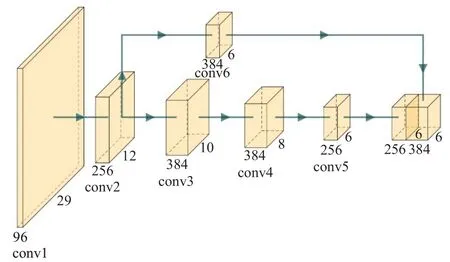
图1 基于多层特征融合的SiamFC网络结构Fig.1 SiamFC network structure based on multi-layer feature fusion
图2 为各层卷积特征图可视化结果,分别取Box、Basketball、David3视频序列中的某一帧搜索区域进行特征提取。第二个卷积层的底层特征通过修改维度与第五个卷积层输出高层特征拼接。多层特征的融合,增强了网络对跟踪目标的判别性,提高了跟踪算法的跟踪性能。
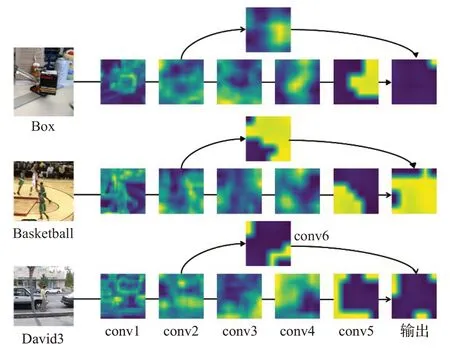
图2 各层卷积特征图可视化Fig.2 Visualization of convolutional feature maps of each layer
1.2 短时记忆模块
在目标检测领域,Chen等[22]提出整合大量的全局信息和局部信息来辅助关键帧的检测,显著提升了视频物体检测器的性能。目前基于Siamese的目标跟踪算法大多以第一帧目标框为模板,之后将每一帧的搜索区域的特征和初始模板的特征进行互相关操作,确定跟踪目标的位置。而在视频目标跟踪中,目标不是静止不动的,这使得跟踪面临很多困难:目标遮挡,光照变化、目标快速运动等,这些都会造成目标特征的变化。但反过来,视频目标跟踪意味着可以利用时序上的相关性来辅助目标跟踪。人们可以根据一些历史信息,如位置、语义信息,来判断这个外观发生变化或者被遮挡的物体是否是跟踪目标。因此利用好时序信息辅助质量比较差的帧上的目标跟踪是一个重要的研究方向。
本文考虑时序信息辅助目标跟踪,设计了一个短时记忆模块。如图3算法流程所示,记忆模块将每一帧的跟踪目标的特征保存下来。历史帧数过多,会影响运算速度,占用内存,本文短时记忆模块中历史帧数为3,即保存当前帧的前3帧目标的深度特征。当前帧搜索区域特征φ(x)与历史帧特征φ(mt-1)、φ(mt-2)、φ(mt-3)分别进行相关运算,得到3个响应图f(x,mt-1)、f(x,mt-2)、f(x,mt-3)。短时记忆模块中的三个响应图代表当前帧与前三帧跟踪目标的相似度,而前三帧的跟踪目标可能由于跟踪错误和误差导致不是真实目标的位置,这就需要对响应图进行修正。max(f(x,mt))为当前的第t帧与初始帧的响应值最大值,数值在0到10之间,值越大,表示当前越可能是跟踪目标,本文为降低跟踪错误带来的影响,将此最大响应值映射到0和1之间,再进行平方,得到的值作为修正权值γt,如式(5)所示:
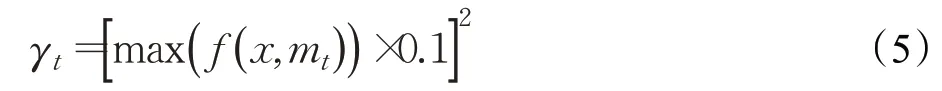
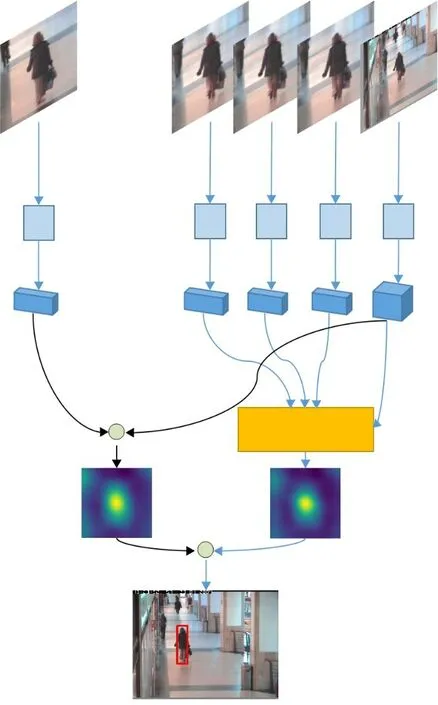
图3 算法流程Fig.3 Algorithm flow
修正权值γ的作用是避免被错误地跟踪目标污染短时记忆模块输出的响应图。R t-1表示t-1帧经过修正之后的响应图R t-1=γt-1f(x,mt-1)。如果历史帧跟踪错误,最大响应值会减小,与响应图相乘之后,可以减小当前搜索区域与错误目标的响应图在输出值中的权重。将修正过后的3个响应图进行平均后得到短时记忆模块输出的响应图f(x,mt),公式如下:

搜索区域特征x与初始模板特征互相关得到响应图f(x,z)。两个特征图进行加权融合,得到一个新的响应图F(x,m,z),此响应图的最大值即为目标最终的位置,公式如下:
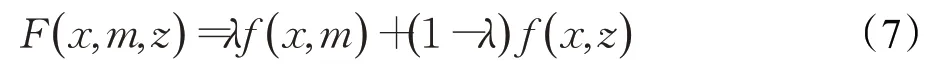
2 实验结果分析
2.1 实验环境与数据集
本文算法基于Python3.6实现,硬件实验环境为AMDRyzen7 2700X CPU、主频3.7 GHz、内存16 GB、显卡GeForce GTX1080配置的计算机。训练数据采用GOT-10K[23],epoch次数为50,批大小batchsize为8。测试数据集为OTB2015[24]和GOT-10K数据集。OTB2015数据集包含100段视频,每个视频序列包含了11个属性。GOT-10K评估数据集包含180段视频。
2.2 评估指标
评估指标采用跟踪精确度和跟踪成功率。跟踪精确度反映了跟踪算法估计的目标位置中心点与标注的中心点之间的距离。跟踪成功率反映了算法估计的目标位置与标注位置之间的重合程度。
(1)目标跟踪成功率
a为跟踪算法得到的目标框,b为标注的目标框,||·表示区域内的像素数目,当某一帧的os大于设定的阈值时,则该帧被视为成功的,成功帧的总数占所有帧的百分比即为成功率。os的取值范围为0~1,因此可以绘制出一条曲线。

(2)目标跟踪精确度
跟踪精确度计算了跟踪算法估计的目标位置中心点与标注的中心点之间的距离小于给定阈值的视频帧所占的百分比。不同的阈值得到的百分比不一样,因此可以得到一条曲线。
2.3 性能评估
对于公式(7)中的权值λ,太大或太小都会引起跟踪漂移。本文赋予基准跟踪器响应得分更大的权重,λ∈[0.7,1],本文通过在OTB2015数据集中的跟踪结果确定λ取值为0.85。表2为λ取不同值时的跟踪成功率和精确度。

表2 λ不同取值下的跟踪结果Table 2 Tracking results of different λvalues
本文算法在OTB2015数据集中与5个跟踪算法进行比较:SiamFC、SRDCF[25]、CFNet、Staple[26]、fDSST[27]。图4为6种算法在OTB2015数据集中的跟踪精确度和成功率。本文算法在OTB2015的跟踪精确度上排名第一,相比较于基准跟踪算法SiamFC(0.796),本文算法(0.807)提高了1.1%,在跟踪成功率上排名第二,相比较于SiamFC(0.588),本文算法(0.593)提升了0.8%。图5为本文算法与基准算法SiamFC在GOT-10K数据集上的跟踪成功率对比,在GOT-10K数据集的成功率指标上,本文算法(0.543)高于SiamFC(0.539)。

图4 在OTB2015中的跟踪精确度和成功率Fig.4 Tracking accuracy and success rate in OTB2015
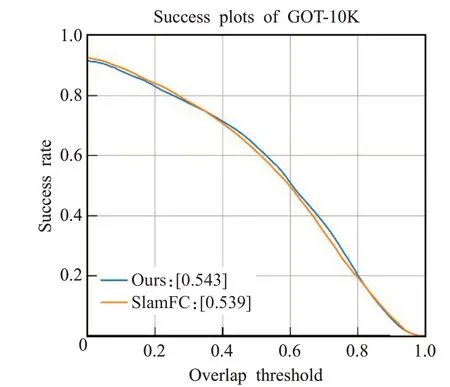
图5 在GOT-10K中的跟踪成功率对比Fig.5 Comparison of tracking success rate in GOT-10K
为更好地说明本文跟踪算法的性能,本文选择了OTB2015数据集中10个视频序列进行跟踪结果展示,如图6所示,视频序列由上到下依次为Soccer、Skating1、

图6 算法跟踪结果展示Fig.6 Visualization of tracking results
Girl2、DragonBaby、Couple、ClifBar、Car Dark、Box、Basketball,图中绿色框为标注的目标真实位置(Ground truth),蓝色框为SiamFC算法跟踪结果,黄色框为上文所提到的将多层特征进行融合的SiamFC跟踪算法(SiamFC multi-features,SiamFCMF),红色框为本文所提出的结合了多层特征融合和引入了短时记忆模块的跟踪算法。当视频中出现光照变化、目标遮挡、快速运动、相似目标干扰时,跟踪框容易出现跟踪漂移,如CarDark视频序列对夜间场景中的车辆进行跟踪,受路灯和车辆灯光的影响,光照变化较大,背景复杂,第263帧中,SiamFC算法首先出现了跟踪漂移,接着在第283帧,基于多层特征融合的SiamFCMF算法同样出现了跟踪漂移。在Box视频序列中,第300帧时出现了目标遮挡的现象,在308帧和320帧时SiamFC和SiamFCMF的跟踪框均漂移到了旁边的物体上,而本文算法保持了对目标的稳定跟踪,有效避免了跟踪漂移现象的出现。
表3和表4分别记录了SamFC、SiamFCMF和本文算法在图6中9个视频序列上的跟踪精确度和成功率,从表中可以看出,基于多层特征融合的SiamFCMF算法在7个序列的精确度和9个序列的成功率要优于Siam-FC算法,本文算法的精确度和成功率均要优于SiamFC和SiamFCMF算法,鲁棒性良好。

表3 在9个视频序列上的精确度Table 3 Accuracy on 9 video sequences

表4 在9个视频序列上的成功率Table 4 Success rate on 9 video sequences
图7 为OTB2015数据集中的Basketball视频序列,第二行为SiamFC算法输出的响应图,第三行为本文算法输出的响应图。在第635帧时,跟踪目标靠近一名穿着同样衣服,肤色相同的运动员。SiamFC响应图中干扰目标的响应值较大,与跟踪目标的响应形成双峰。在第645帧时,SiamFC算法已经错误跟踪了干扰目标,且响应值较大,而本文算法未出现跟踪错误。第655帧,SiamFC响应图出现多处峰值,而本文算法的响应值较为集中。

图7 跟踪响应图对比Fig.7 Comparison of tracking response map
图8为本文跟踪流程中各响应热力图的展示,左侧四张图分别为当前帧搜索区域与初始模板、t-1帧目标、t-2帧目标和t-3帧目标的相关响应热力图。从图中可以看出,受到相似目标干扰的影响,搜索区域与初始模板的响应已经偏移到了干扰目标上,而搜索区域与前三帧的响应还集中在被跟踪目标上,三个响应图通过修正系数进行修正后融合得到短时记忆模块输出的响应图,再将此响应图与初始模板的响应图进行加权融合得到最终的响应图,从而得到目标的位置。

图8 跟踪流程响应热力图展示Fig.8 Visualization of response heatmaps of tracking process
3 结论
针对长时目标跟踪中的复杂场景和目标遮挡等问题,本文在SiamFC的基础上,对AlexNet网络进行多层特征融合,提高了网络的特征提取能力。同时,引入了短时记忆模块,通过视频局部信息增强算法对跟踪目标的判别性。在短时记忆模块中,保存局部帧的目标深度特征,将当前帧的特征分别与初始模板特征和短时记忆的特征进行互相关,对得到的两个响应图加权融合,确定最终目标位置。本文算法在OTB2015和GOT-10K数据集上进行评估,跟踪结果均优于基准的SiamFC算法,表明本论文算法能有效提升的跟踪性能,并且达到了27帧/s的实时跟踪速度。本文的下一步工作将对短时记忆模块进行改进,并尝试融合到其他目标跟踪算法中。
