基于有责量和免责量的谣言溯源算法
2022-02-22叶增炜王友国
叶增炜,王友国,柴 允
(1.南京邮电大学 理学院,江苏 南京 210023;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
随着通信和互联网技术的不断发展,人与人之间的联系愈加频繁和紧密,社交网络也成为人类生活中重要组成的一部分。在社交网络大环境影响下,信息的传播速度、扩散规模和影响力都显著增加,一方面给予人们极大的便利,另一方面,谣言等不良信息在社交网络上的肆意传播,也对社会造成严重的危害,从而影响社会稳定。因此结合相应的社交网络信息传播模型,对不同场景下的谣言溯源问题进行挖掘和定位,进而确定谣言源位置和谣言传播的关键信息,及时有效地遏制谣言发展显得尤其重要。
目前,关于谣言溯源问题,通常是通过观察整个感染子图,在获得某些信息的前提下,如网络拓扑及节点状态信息等,构建源节点估计量,最大化谣言源检测概率。Shah和Zaman首次通过构建谣言源的极大似然估计量(谣言中心性)研究网络上的单源溯源问题,并以此为基础,假定按照广度优先搜索的传播机制,将谣言中心性推广到一般树和一般图上。同时Shah和Zaman证明了在树形网络中谣言中心性和距离中心性完全等效,在几何树中,随着传播时间增长,正确检测概率趋于1。Zhu等人基于采样路径,定义感染离心率为一个节点到所有感染节点最短路径的最大值,提出Jordan中心估计量,即具备最小的感染离心率节点,用以解决SIR传播模型下的谣言溯源问题。Luo等人在有限观察的前提下,提出一种反向贪婪算法迅速寻找到网络中的Jordan中心,即单Jordan中心估计算法(SJC)。Ali等人认为在没有任何先验知识的情况下,可以假设每个节点成为源的概率相等,因此实际的谣言源节点可能不是Jordan中心,并通过考虑邻居节点的状态计算出节点年龄从而估计可能的谣言源节点。也有研究者通过在网络中设置传感器节点,收集节点感染状态和感染时间信息,从而探寻可能的谣言源节点。例如,Pinto等人通过传感器节点所收集到的节点实际时延信息,对比信息到达的理论时延,计算时间矩阵的相似度进行信源估计。Spinelli等人在信息传播过程中设置动态传感器,可以在信息传播结束或仍在传播的时候定位到信源节点,并通过实验分析出使用动态传感器将大幅减少传感器节点数量,即使具有高方差传输延迟,也可以使用少量传感节点有效地进行溯源工作。
在真实网络中,谣言源往往不唯一,为此,Luo等人提出多Jordan中心估计算法(MJC),用于解决SI传播模型中节点显式状态和隐式状态的多源溯源问题,使用Voronoi划分算法将所有显式状态节点划分成多个社区,并使用SJC算法估计各自的谣言源节点。Fioriti等人考虑网络邻接矩阵最大特征值在移除每个节点后的下降量,定义了动态年龄的概念,并视动态年龄值排名靠前的节点为源节点。Ali等人基于K-Means划分方法和连续源识别方法将单源估计算法推广至多源情况。Prakash等人针对多源问题提出基于最小描述长度的NetSleuth算法,该算法是自适应的谣言溯源算法,无须事先已知谣言源数。
在已有研究的基础上,该文考虑基于有责量和免责量的谣言源溯源算法,通过可疑集选取的思想,采用谱优化的模块度划分算法,将双源感染网络划分为两个社区,在各个社区内进行单源溯源工作,从而解决双源溯源问题。最后,在多个网络拓扑结构中进行了仿真实验,对比不同溯源算法的性能。
1 基于有责量和免责量的谣言溯源算法
1.1 谣言传播模型
信息扩散网络可以模拟为一个无向图G
={V
,E
},其中V
代表可数点集,E
代表可数边集,在异构SI传播模型中,网络中的节点状态包括:易感态S
和感染态I
(见图1),一旦一个节点由于从其被感染的邻居节点处接收到感染或者仅仅是作为感染源而被感染,则它将永远处于感染态。感染节点以概率p
感染其易感邻居,概率p
取决于相邻节点之间的关系强度,即边的权重w
(e
),e
∈E
。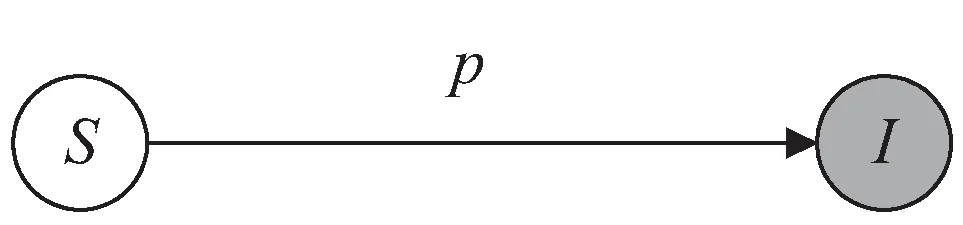
图1 异构SI传播模型状态转移图
1.2 节点年龄
在信息扩散网络中,使用节点年龄来衡量节点加入感染网络的先后程度,其中最早被感染的节点拥有最大的年龄。如图2所示,当网络发生扩散时,1号节点作为最早感染的节点,在扩散过程中,感染了2号和3号节点,此外4号节点被2号节点感染,那么在这个感染网络中,1号节点拥有最大的年龄。

图2 节点年龄示意图
1.3 免责量
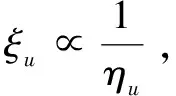

图3 免责量
1.4 有责量

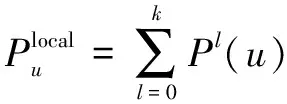
(1)
其中,l
是距离节点u
的距离,P
(u
)是距离u
节点l
跳的所有节点的有责量之和。同时,容易得到在估计源节点时,必须计算直至距离节点比网络半径少一个层级的有责量,即k
最佳的取值为r
-1,r
是网络的半径。1.5 源估计量

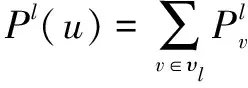
(2)

(3)
其中,I
和O
分别是v
节点对应感染图和底层图的度。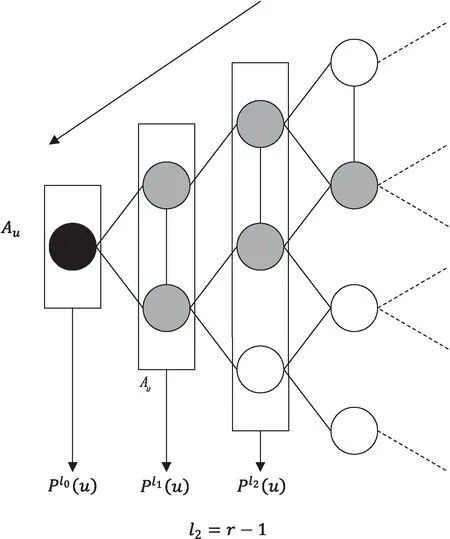
图4 水平有责量
由上文易得,当BFS遍历到达网络半径时停止,即生成属于r
水平的用以计算免责量节点和属于r
-1水平的用以计算有责量节点。因此,节点u
的年龄可由0至r
-1水平的水平有责量之和计算得出,用公式表示为: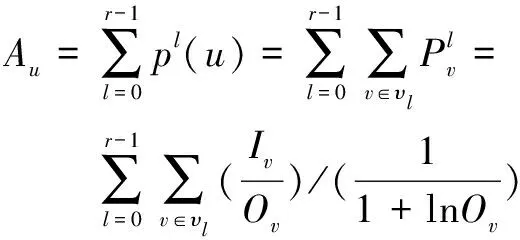
(4)
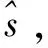

(5)

(6)
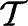
(7)
该文所陈述的谣言溯源方法可由以下算法实现。
算法1:基于免责量和有责量的谣言溯源算法(EPA_B)
G
度矩阵D
D
对应于D
的子阵D
=D
[rownames(D
),colnames(D
)]
d
←D
的对角线元素d
←D
的对角线元素level←0,U
←u
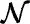

}
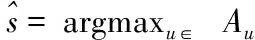
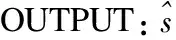
算法2:节点年龄估计算法。
if level>radius-1{
return(0)
}
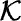
u
∈U
{lage←lage+P
(u
)
}
A
2 基于谱优化社区划分的双源溯源算法
考虑到真实网络谣言传播过程中谣言源不唯一,针对双源情况,考虑基于谱优化社区划分算法将双源问题转化为单源问题,主要内容将在以下部分进行说明。
2.1 基于谱优化社区划分的双源溯源算法
在真实网络中,普遍存在社区结构特性,即同组内的节点相似性较大,异组间的节点相似性较小。其中,Newman提出用以度量网络社区划分优劣的模块度概念,并结合谱分析法优化社区划分算法。谱分析法是利用拉普拉斯矩阵的特征向量将连接紧密的节点划分到一个社区。对比传统社区划分算法,谱分析法不易陷入局部最优解。


(8)
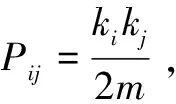
s
是一个含有n
个元素的索引向量,有:
(9)
那么模块度Q
改写成矩阵形式如下: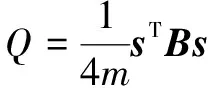
(10)
B
=A
-P
(11)


(12)
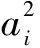

(13)
综上,该文得到通过计算模块化矩阵的主特征向量以获得最优s
,从而根据s
值的正负情况划分两个社区的基于谱分析的模块度社区划分算法。2.2 算法展示
算法3:基于社区划分的双源溯源算法(EPA_DC)。
DO:初始化空集newcenters
u
≥0{part[1]←node
}
else{
part[2]←node
}
}
forpa
in part{foru
∈pa
{
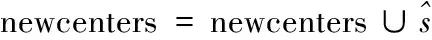
}
}
return newcenters
3 仿真与分析
3.1 数据集
该文在7种不同网络拓扑结构下分别验证单源和双源算法的性能,包括2种合成网络:ER随机网络(ER)、4-正则树网络(Regular)和5种真实网络:Facebook社交网络(Facebook)、美国电网(USPG)、爵士音乐人合作网络(Jazz)、美国空手道俱乐部网络(Karate)、《悲惨世界》主要人物关系网络(Lesmis)。它们的相关数据在表1中给出。
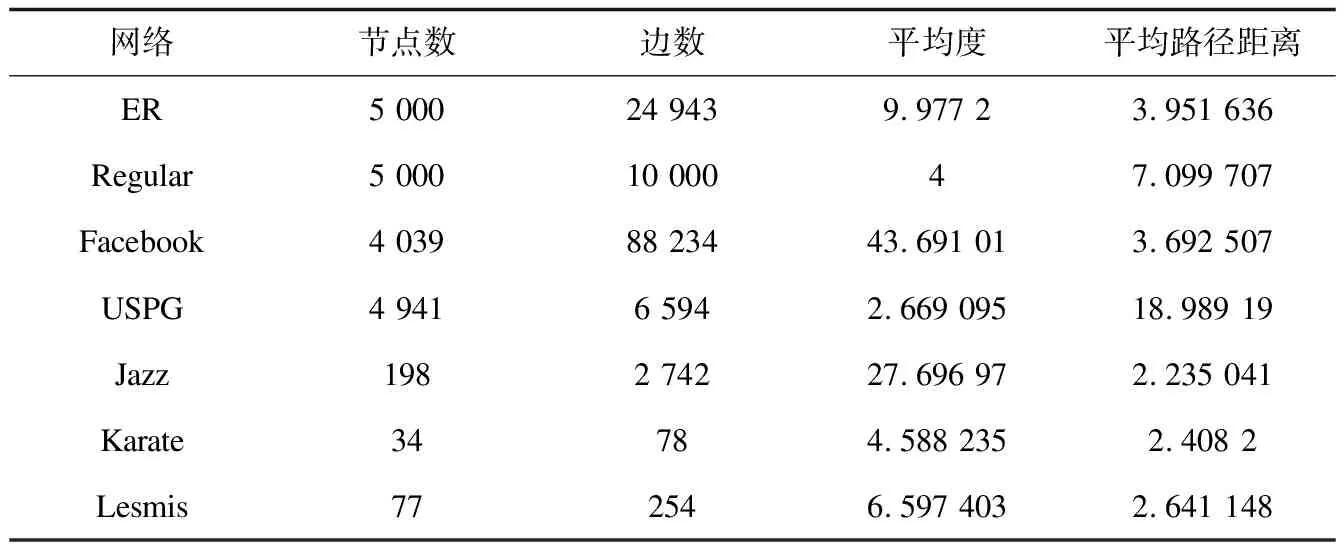
表1 不同网络拓扑结构的统计性质
3.2 仿真实验设置
通过分析不同估计量在上文所提及的7种不同网络拓扑结构下的误差距离信息和正确检测概率来评估文中算法的检测性能和优劣。误差距离为估计谣言源与真实源节点之间的最小路径距离,正确检测概率是实验中正确识别谣言源的比例。在单源仿真实验中,分别在ER、Regular、Facebook、USPG网络上随机选择一个节点作为谣言源,并以异构SI传播模型进行传播,每个网络的感染节点比例设置在2%~5%之间。在双源仿真实验中,分别在Jazz、Karate、Lesmis网络上随机选取两个节点作为谣言源,同时以异构SI传播模型进行传播,考虑到每个网络的规模情况,它们的感染节点比例设置在60%~70%之间。为减少随机误差的影响,所有仿真实验均独立进行了100次并取均值。文中实验过程在R 4.0.3环境中进行。
3.3 单源仿真结果
本部分主要分析单源溯源仿真实验结果,通过该文提出的基于有责量和免责量的谣言溯源算法(EPA_B)与基于动态年龄(DA)、最小描述长度(MDL)两种常用的谣言源估计算法进行比较分析,同时加入采取度较大节点作为可疑集的EPA_D算法进行对比,来评价各算法性能的优劣。仿真结果如图5、图6所示。
图5显示了不同算法在4种网络拓扑结构下的误差距离频率,结果表明,在合成网络中,基于有责量和免责量的谣言溯源算法表现都相当不错。如图5(a)所示,在ER网络上,EPA_B有97%的频率完全正确地找到源节点或误差距离仅仅1跳,大幅度领先于其他算法。图5(b)显示,在Regular网络上,除了MDL算法之外,其余3个算法表现相差不大,EPA_B与EPA_D算法略优于DA算法,同时EPA_B算法的误差距离均在3跳之内,而EPA_D算法存在超过3跳的误差距离。在Facebook网络上,各算法的表现也可由图5(c)中看出,EPA_D和DA算法的表现比较亮眼,但EPA_B算法也有81%的频率在1跳之内找到源节点。由图5(d)可知,在USPG网络上,由于USPG网络的高度稀疏性,各个算法都很难精确地找到源节点。

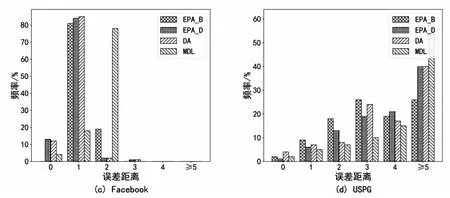
图5 不同网络和算法下的误差距离
图6显示了不同算法在4种网络拓扑结构下的平均误差距离,可以直观地观察到EPA_B算法相较于其他算法的表现。在ER网络中,EPA_B算法的平均误差距离仅为0.26,表现最好。在Regular和Facebook网络上,EPA_B算法的平均误差距离在1跳附近,与EPA_D和DA算法相差不大。总体而言,在给定的几个网络中,EPA_B算法表现较为优异且稳定。

图6 算法在不同网络中的平均误差距离
3.4 双源仿真结果
本部分主要分析双源溯源仿真实验结果,经过谱优化社区划分算法的感染子图分别使用基于有责量和免责量的谣言溯源算法(EPA_CD)、基于接近中心性的溯源算法(CC)和基于距离中心性的溯源算法(DC)进行仿真实验,同时加入基于K-Means感染网络划分的双源估计算法(EPA_K-Means)进行对比分析。
由图7(a)可知,在不同网络拓扑结构中,EPA_CD算法的平均误差距离均为最小且都在1跳之内,EPA_K-Means算法的平均误差距离在1跳左右,而CC和DC算法表现稍差一些。由于Karate网络的规模最小,因此每个算法在Karate网络中表现都是最好的。由图7(b)可知,就正确检测概率而言,EPA_CD和EPA_K-Means算法结果相差不大,且大幅优于CC和DC算法,在Jazz和Karate网络中,EPA_CD算法的正确检测概率略好于EPA_K-Means算法,在Lesmis网络中则相反,EPA_K-Means算法的结果为0.27,而EPA_CD算法的结果为0.225。

图7 平均误差距离和正确检测概率结果
4 结束语
该文利用谣言源是最早加入感染网络的节点这一思想,通过考虑感染节点的邻居节点状态,得到基于有责量和免责量的谣言溯源算法,并为了减少算法计算成本,采用高介数中心性节点作为源节点可疑集的思想,提出EPA_B算法。同时,针对双源问题,基于谱优化的社区划分算法,将双源感染子图划分为两个社区,从而将复杂的双源问题简化为单源问题。最后,分别在不同网络拓扑结构内进行单源和双源溯源的仿真实验,结果表明,单源问题中,在多数网络拓扑结构下,EPA_B算法的平均误差距离在1跳左右,在ER网络中甚至能达到0.26,在高度稀疏性网络中表现也最为稳定。针对双源问题,提出的EPA_CD算法在3个小规模真实网络中的平均误差距离均为最小,在Karate网络中,EPA_CD算法的正确检测概率高达0.595,相较于其他启发式谣言源估计算法,表现更为优异。
