基于云计算大数据分析技术的电动汽车充电监控系统
2022-02-22徐孟龙刘慧文伍文广马媛媛史晓磊
徐孟龙,李 俊,刘慧文,伍文广,马媛媛,史晓磊
(1.北京博电新力电气股份有限公司,北京 100176;2.国网电动汽车服务有限公司,北京 100052;3.长沙理工大学,湖南 长沙 410114)
0 引 言
2020年初新冠肺炎疫情爆发,世界经济被按下暂停键,我国2020年第一季度GDP增速为-6.8%,与2019年同期的6.4%相比下降了13.2%。工业生产增速经历了断崖式下跌,为提振经济,稳定就业,应对中美贸易摩擦带来的高科技禁用等一系列风险,以及我国为转型升级打造科技强国的内在需求驱动下,中共中央政治局常务委员会召开会议,会议强调加快“新基建”建设进度。“新基建”是国家在2018年中央经济工作会议上提出的,以科技产业升级为核心的配套基础设施建设计划,其核心内容包括:5G、特高压、城际高速铁路和城市轨道交通、新能源汽车充电桩、大数据中心、人工智能、工业互联网。
新能源汽车充电桩建设成为新基建风口,在新能源充电桩爆发式增长下,新的问题也随之而来,电动汽车充电故障率不断攀升,电气故障、通信故障,以及车桩兼容性问题突出,目前主要通过人工现场检测发现和处理故障,这种运维模式在目前充电桩数量暴增的情况下将难以为继。另一方面,虽然充电桩内部TCU单元可以与充电控制器进行CAN通信,并进行数据记录,但记录的信息十分简单,无法反映充电细节,更无法记录车桩之间真实的交互过程和信息,制约着新能源汽车的发展。
为解决上述问题,本文介绍了采用高速数据采集技术、机器学习技术来采集、识别故障,实现了直流充电桩故障在线诊断、故障预测功能。设计了一种安装在充电桩内部的电动汽车充电故障监控系统,该系统采集电压、电流、门禁、急停等信号后,通过IoT上传到云服务器。结合数据处理技术和随机森林分类算法可以构建一种直流充电桩在线诊断和故障预测方法。本文简要介绍了随机森林思想及其核心算法,以及拓扑和训练过程。分析了模型的均方误差和训练损耗。探讨了如何优化模型,提高精度,避免过度拟合。最后通过项目实际应用对比了故障预测与真实情况的误差,发现故障识别准确率超97%。
1 设备硬件设计
充电过程监测装置安装在充电桩内部,包括控制模块、监测采样模块、电源模块、存储模块和WiFi/4G模块,可满足最大1 000 V/250 A直流充电桩的要求。采样率为1 kS/s,支持多种触发模式。
装置采用高速数据采样和处理器技术,记录完整的充电过程中每个触点的工作状态。当监测装置检测到直流充电桩开始充电时,自动启动电压电流采集和CAN总线报文采集,从而记录整个充电过程的电压电流变化和CAN总线报文。文件、数据在本地存入SD卡的同时也通过4G网络上传到云平台,进行云端存储和分析等工作。功率监控单元总体框架如图1所示。

图1 功率监控单元总体框架
装置主要分为以下几个部分:
(1)主控部分选用Xilinx ZYNQ7000系列CPU,其具备监测系统数据的采集、处理和通信等功能。
(2)电源模块负责为监测系统供电,数字电路和模拟电路分开供电,保证系统的稳定性和采集精度。
(3)CAN报文采集模块用于监测直流充电桩和电动汽车间的CAN通信数据,并对报文进行解析。WiFi/4G模块负责向云端服务器传输数据。
(4)存储模块负责存储采集的报文、电压电流数据及监测报告等。
(5)模拟采集模块负责采集充电过程中的充电电压、充电电流和辅助电源信号等模拟量,模拟采集模块共有5个采集通道,各通道相互隔离,分别采集充电电压、充电电流、辅助电源电压、CC1电压、CC2电压。
2 随机森林算法介绍
2.1 决策树的概念
决策树有很多种类,例如大家熟知的ID3(迭代二分频器3)、CART(回归分类树)、C45(ID3升级)等,均属于分类器范畴。如图2所示,决策树都有一个根节点,从根节点通过学习算法对每个结点递归分裂,最终得到决策节点。
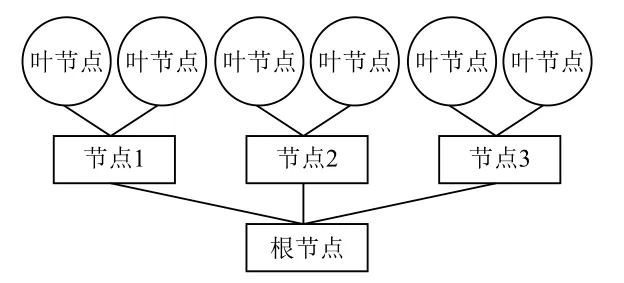
图2 决策树示意图
决策树学习算法是一种近似离散值目标函数的方法,其中学习的函数由决策树表示。决策树学习算法是归纳推理领域应用最广泛的方法之一。
2.2 分裂判据
对于决策树算法而言,分裂判据至关重要,它决定了决策树的节点如何向下分裂。目前有很多分裂判据被用来对节点进行分裂,这些分裂措施根据分裂前后记录的类分布来定义。
信息熵是1948年香农首先提出的,主要用来描述一个信号或者一个事件中有多少有效信息,它与一个已知概率分布事件的不确定度有关,通俗地说,一件事发生的概率越高,则其不确定度越低,信息熵就越低,必然事件和不可能事件的信息熵为0。信息熵定义为与随机结果相关的平均信息含量的度量。对于离散随机变量X,其信息熵表示为:
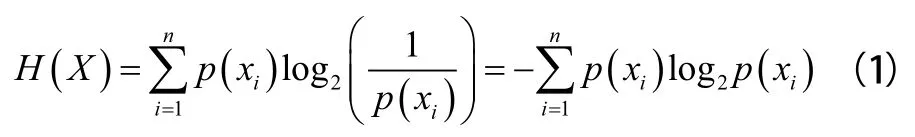
式中,p(x)=P(X=x)是随机变量X第i次结果的概率。信息熵也可以被用于一般概率分布,不限于离散值事件。
基尼系数是信息量的另一种度量,在决策树生成期间,数据的“不确定性”越小,则其可能性就越大。如果我们取S个随机变量,则基尼系数可以表示为:
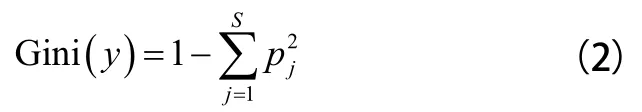
式中:p表示取第j个变量的概率;y为研究的变量,表明y不确定性越大,则Gini(y)越大。
2.3 终止判据
决策树根据分裂判据不断分裂生长,直到达到终止判据生效,最终形成叶节点。终止判据通常有如下条件:
(1)当训练集中所有个体都属于一个单一值y;
(2)达到决策树设定的最大深度;
(3)达到终止阈值。
2.4 随机森林
由于单棵决策树在训练过程中不可避免的会遇到过度拟合,即对本数据集可以进行高精度分类,但遇到其他数据集分类精度就会降低。为解决这一问题,提出了随机森林算法。随机森林算法是通过对随机森林中多棵决策树的结果进行统计或者平均,之后将许多决策树输出的结果汇集成为最终输出,以减少单棵决策树对某一数据集的过度拟合问题。
随机森林拓扑结构如图3所示。随机森林的建立便于对原始数据集D中个体进行随机可放回式n次提取,得到n个样本S,其中j=1,2,...,n,通过n个样本可以训练得到n棵决策树模型。对每一棵决策树通过分裂判据进行分裂生长,然后将每棵决策树的结果进行统一投票表决,输出最终结果。
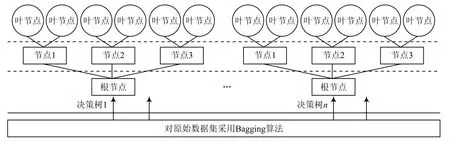
图3 随机森林拓扑结构
3 模型训练过程和优化探索
3.1 数据预处理
通过图1中的WiFi/4G模块将充电桩监控设备采集的数据上送至云服务器,数据包括:K1和K2驱动、电子锁反馈、急停信号、门禁反馈、THDV-M、THDI-M。通过这6个维度的特征来预测充电桩故障。由于现场环境复杂,通过IoT技术获取的数据不可避免存在各种问题,例如:采样环节由于电磁干扰、环境温湿度的变化等导致数据异常、噪声和数据不一致等问题。数据传输环节由于丢包、中断等原因导致数据缺失,这些问题在源头上给数据分析带来了困难,甚至造成了分析结果错误。为提高数据分析质量,必须在应用这些数据之前先对其进行数据预处理,如补充缺失的数据、清除异常数据等。
对清洗完成的数据进行归一化处理,如:Min-Max归一化(Min-Max Normalization),该方法是对原始数据的线性变换,使结果值映射到[0,1],转换函数如下:

式中:max为样本数据的最大值;min为样本数据的最小值。归一化是让不同维度之间的特征在数值上有一定的比较性,对于分类器而言,归一化处理可以提高分类的准确性和计算效率。数据预处理结果见表1所列。

表1 数据预处理结果
3.2 模型精度评估
随机森林算法对于分类问题具有较高的准确率,在较大的数据集上也能够稳定运行,对于多维特征的样本能够一次分类并且无需降维处理,而且可以对每个特征维度分类结果的重要性给予评估。
对于结果,使用平均绝对百分比误差(MAPE)和均方根误差(RMSE)进行评估。误差计算公式见式(4)和式(5):
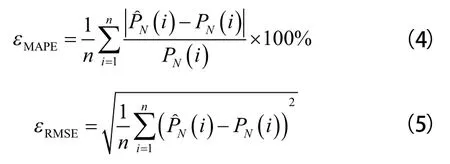
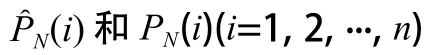
首先对数据集中122 144个样本进行划分,其中80%数据用作训练数据,20%数据作为验证数据,用于验证模型精度。通过训练,我们得到随机森林分类器模型TrainedRF_Model13(data),然后将20%的验证数据输入TrainedRF_Model13(data)即可得到图4所示结果。其中,True class表示验证数据真实的故障状态,Predicted class表示随机森林分类器模型TrainedRF_Model13(data)预测的结果。

图4 随机森林分类器TrainedRF_Model13(data)预测结果
True Class 0表示充电桩正常,即无任何故障,Predicted Class 1表示随机森林分类器TrainedRF_Model13(data)判断为充电桩异常,即预测发生了故障。可以看到,随机森林分类器TrainedRF_Model13(data)判断充电桩工作正常并与真实情况相符的准确度为89%,表明11%的数据被判断错误,即充电桩无故障但分类器却预测其发生故障,这部分样本数量为1 314。另一方面,True Class 1即充电桩工作确实存在异常,而分类器也判断为异常的准确度为89%,这表明有11%的数据判断错误,即存在故障但分类器却认为运行正常,这部分样本数量为1 356。可以看到,目前系统分类精度不高,有很多值被判断错误。我们汇总本次测试相关信息:随机森林模型由5棵决策树构成,特征维度为6,叶结点为2,训练时间为6.829 6 s,预测精度为89.1%。
3.3 模型优化探索
在本次训练和验证过程中我们可以看到6个特征维度对预测结果的影响力度,图5可以看出对预测结果影响最大,也是最重要的特征THDVM(电压总谐波畸变率),其次是THDIM(电流总谐波畸变率),这2个特征的重要性明显高于其他特征维度。
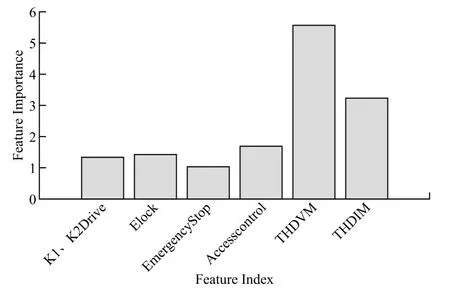
图5 特征维度对预测结果的重要性
为提高模型精度,对模型参数进行调整,将随机森林中决策树的数量由5棵提升至30棵,特征维度仍然为6,叶结点为2,得到图6所示预测结果。
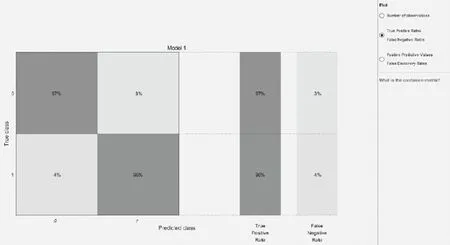
图6 随机森林分类器TrainedRF_Model13(data)预测结果
我们可以看到,True Class 0即充电桩工作正常情况下的准确度达97%,即3%的数据被判断错误,这部分样本数量为733。另一方面,True Class 1即充电桩工作异常情况下的准确度为96%,这表明4%的数据判断错误,即原本存在故障但分类器却认为系统运行正常,这部分数据为977。
不难看出,随机森林中决策树越多模型精度就越高,但相应的训练时间也越长,对硬件的算力要求也越高。而且提高决策树数量也存在瓶颈,起初增加决策树的数量可以极大地提高模型精度,但当决策树的数量达到一定程度后,再提高决策树的数量就无法大幅提高精度了,有的甚至会使精度下降。图7展示了决策树数量对精度的影响,可以看到,决策树的数量由1增加到10时,对模型精度有极大地提升,但超过10时,对模型精度的提升就变得非常有限,而且决策树越多模型越容易过拟合,模型灵活性将大大降低,同时模型训练时间也大幅增加。所以最佳模型是综合模型精度、训练时间、算力、避免过度拟合等各方面考虑后选取的最优方案。
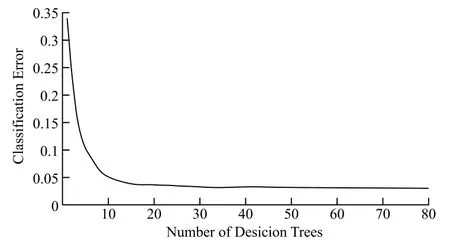
图7 决策树数量与模型精度关系
参看表2,我们可以将几组训练验证完成的模型进行比对,观察各模型在精度、训练时间、训练损耗等方面的优劣,更加直观地得出最优模型。

表2 模型优化结果对比表
ROC曲线的最佳工作点以1-by-2数组形式返回,其中包含最佳ROC工作点的误报率(FPR)和真正率(TPR)值。perfcurve仅计算标准ROC曲线的OPTROCPT,否则设置为NaN。为获得ROC曲线的最佳工作点,perfcurve首先需找到斜率S。
从图8可以看出,在分类器最佳工作点(0.04,0.97),对于正常状态的预测错误率为0.04,即4%的错误率,对于异常状态的预测正确率为0.97,即97%的异常状态能够被预测出来。

图8 随机森林分类器TrainedRF_Model13(data)预测结果
目前该设备已经开展试点应用,部分被安装在北京市新能源汽车充电桩中,通过较长时间的云上托管运维,故障识别准确率高于97%,极大降低了运维的时间成本和人力成本。设备现场安装调试如图9所示。

图9 设备现场安装调试图片
4 结 语
本文介绍了采用高速数据采集技术、机器学习技术对新能源汽车充电故障进行采集和识别,实现故障在线诊断和故障预测功能。通过安装在充电桩内部的故障监控系统采集电压、电流、门禁、急停等信号,借助IoT技术上传到云服务器,结合数据处理技术,随机森林分类算法构建了一种充电桩在线诊断、故障预测的方法,最终实现智能运维。本文同时介绍了随机森林思想以及核心算法、拓扑和训练过程。分析了训练结果的均方误差和训练损耗,对模型优化、提高精度、避免过度拟合等问题进行了探索,最后通过项目实际应用对比了故障预测与真实情况的误差,并且得到故障识别准确率高于97%的结论。
