基于人工智能机器学习的文字识别技术分析
2022-02-22沈冲
沈冲
关键词:人工智能;深度学习;文字;识别;神经网络
随着信息技术发展,以图像为主的多媒体信息迅速成为了重要的消息传播手段。而准确有效地提取图片中的信息能有助于社会在工业自动化、机器人导航、人机交互、多媒体检索领域获得长远发展。目前文字识别已经成为智能机器深度学习的重要内容,具有一定的研究价值。基于此,本文将对基于人工智能机器学习的文字识别技术为论点,对现有的文字识别技术进行研究,以期能为同行产生几点借鉴意义。
一、传统文字识别技术与现代文字识别技术的特点研究
传统的文字识别技术有笔输入、专用OCR、手写体OCR、印刷体OCR四类[1]。现代文字识别技术依靠Matlab技术实现,大致应用步骤为调取原始图像、处理图像获得灰度图像、图像二值处理,调动计算函数,输出目标文字。
二、现有文字识别技术仍存在的问题
(一)网络文字图片标注成本高,训练数据集小
人工智能机器学习功能需要在复杂模型的监督训练下开展,因此,需要以海量数据集作为学习初始支持。针对网络图片中的文字,进行深度学习前,要对图片中的所有字符串进行标注,并需要对某个区域内是否包含文字进行检测。相较于一般的物体识别任务,网络图片文字识别所花费的任务成本更高。但从当前来看,现开放的有关文字识别技术开放性源代码数据集较少,图片数量也较少,故开展深度学习的前期支持数据不足。
(二)序列建模常用的循环网络无法并行计算
当前文字序列识别的常用技术为依靠卷积循环神经网络,技术支撑主体为LSTM技术。虽然該技术序列建模能力较为优秀,但在建模过长的文字序列时,信息发出与收到反馈的用时较长,有可能增加系统深度学习的最终用时,进而对模型的识别效率造成影响。
(三)复杂场景图片文字识别准确率不足
现有的文字识别模型大多依靠普通的单层卷积网络,针对背景较为简单的文字进行识别时,准确率较高。但当识别复杂场景文字时,需要加深提取模块层数,从而出现梯度发散问题,最终导致机器学习内容不足的现象。
三、基于人工智能机器学习的文字识别技术分析
(一)分类器识别
基于深度学习的文字识别工作开展前,首先要对文字识别的分类器进行识别。以BP神经网络分类器为例,其学习训练步骤如下:输入模式顺传播→输出误差逆传播→循环记忆训练→学习结果判别。在应用BP神经网络分类器前,首先需构建神经网络,设计代表3大不同数据的通道。采用net函数构建神经网络,则可将3大数据通道用net1、net2及net3、表示,每一通道内包含的数据数量分别为64与128、24与48、60与128,每一个数量分别代表一个节点。满足上述技术支持后即可对神经网络进行初始化。当前最常用的初始化方式为Initnw,每一次运行都能将数据运行时的权值及偏移量合理的初始,在后续进行单个文字的识别时,数据的输入能更加便捷,同时也能减少神经元网络节点的冗余[2]。
(二)规则文字识别相关技术
(1)卷积神经网络法:该结构属于前馈型神经网络结构类型,对规则文字类型具有较高的文字识别灵敏度。即使针对已经经过平移或旋转变换后的图片,也可利用该技术较为灵敏地识别出。该技术文字识别步骤如下:输入→预处理→识别→识别后处理四大流程。各流程中所包含的数据层级也有所差别,现将具体内容介绍如下:①输入层。截取需要处理后的单字图像,并转换为64*64像素的灰度文字图片,调整文字为白色,调整背景为黑色,如此处理以避免无关因素对文字识别的影响。
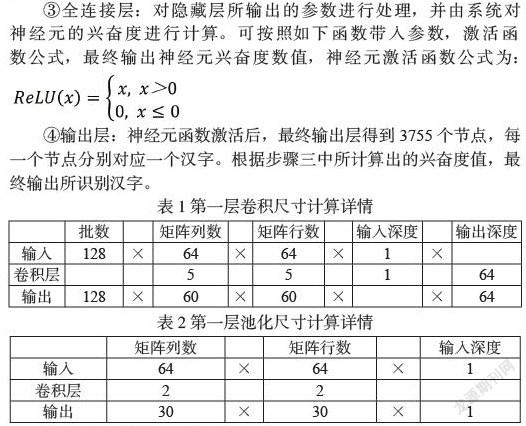
②隐藏层。共包含三个池化层与三个卷积层,卷积层与乳化层交替构成,处理数据。a、卷积层1:计算第一层卷积尺寸,以64*64像素文字处理为例,最终输出卷积尺寸详见表1;b、池化层1:对第一卷积层输出的图像进行最大池化运算处理。并计算出第一次池化结果。以60*60像素文字处理为例,最终输出的池化尺寸详见表2;c、卷积层2:采用5*5的卷积(共计128)个,对池化层1输出的图像再次进行卷积运算:d、池化层2:采用2*2的池化器对卷积层2输出的图像进行池化最高值运算:e、卷积层3:采用4*4的卷积对图像进行卷积运算;f、池化层3:采用2*2的(256个)池化器对卷积层图像进行池化最高运算[3]。
③全连接层:对隐藏层所输出的参数进行处理,并由系统对神经元的兴奋度进行计算。可按照如下函数带入参数,激活函数公式,最终输出神经元兴奋度数值,神经元激活函数公式为:
④输出层:神经元函数激活后,最终输出层得到3755个节点,每一个节点分别对应一个汉字。根据步骤三中所计算出的兴奋度值,最终输出所识别汉字。
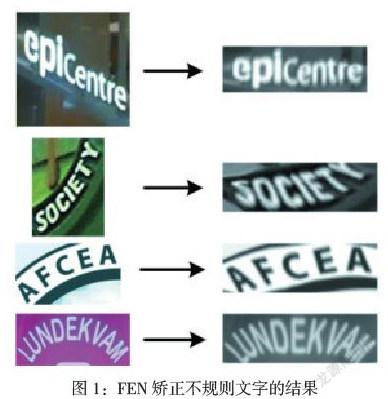
(1)FRAEN技术:该网络能够识别自然场景下拉伸或缩放的文字。技术核心架构由AEN识别网络与FEN灵活矫正网络所构成。在识别不规则文字时。FRN对图片中的文字进行识别并予以矫正,矫正至文字处于水平状态;随后AEN将矫正后的图像输入至AEN网络中,利用规则文字识别相关技术,如卷积神经网络算法进行文字识别,随后输出预测的单词。其中FRN技术为本节内容研究的重点。FRN技术为常用的文字矫正方法,但应用时对文字变形度的要求较为局限,仅包括平移、缩放、旋转等。因此,当前的文字识别技术为增强对变形文字的矫正能力,引入了CNN文字矫正加强网络,增强文字的矫正效果[4]。传统的FRN处理技术易产生图像解码过程中的噪点,故可在矫正前,在程序内输入最大池化层减少或避免噪点产生。FRN矫正不规则文字的结果详见图1。将矫正后的文字图片输入至卷积神经网络中,进行规则文字处理流程,即可完成文字的识别。
汉字属于词素音节类型文字,英文属于表音文字。汉字的个数要远远多于英文字母的个数。对于中文文字的识别而言,文字识别时需构建大量的图像,这导致了中文文字识别时的错误自检率要远高于英文字母。关于如何提升中文文字识别能力,笔者从分类器的选择上提出了改进建议有条件的最好选择包含所有字符的分类器,同时在其应用时,应对字符不同进行合理分类[5]。此过程中需对分类器进行训练,前期以小组文字选择的方式,将具有这一特征的文字类型进行整合,以便分类器更好的识别这一特征的字符。经过不断地深入学习,在识别文字时,系统将会在分类器中选出与所检测文字相似特征最多的字符。在对机器进行日常训练的过程中,采用文字交叉验证方式,使机器不断搜集到有关文字特征的共性,对文字识别准确度的提升有显著成效[6]。
结束语:
现如今,神经网络已经成为人工智能文字识别领域的重要组成模块,为当前文字识别的最常用手段。在未来,文字识别领域将向着对场景非拉丁文字的检测与识别、多语言混合的端到端文字识别、曲线型文字的检测与识别、文字图像的自动生成及提高算法的性能角度发展。随着科学社会的发展,文字识别技术将被更多的应用到虚拟现实、教育、车牌识别、无人驾驶等诸多领域,成为未来科学研究的主流。
参考文献:
[1] 冯琬婷. 基于文字识别视角分析人工智能机器学习中的文字识别方法[J]. 电子技术与软件工程,2019,8(13):253.
[2] 张龙坤,何舟桥,万武南. 基于机器学习的截图识别翻译应用研究[J]. 网络安全技术与应用,2020,5(8):54-56.
[3] 刘维维. 人工智能技术在移动终端自动化测试中的应用[J]. 软件导刊,2021,20(2):59-62.
[4] 劉子俊,王廷凰. 基于AR文字识别技术实现二次设备定值修改[J]. 自动化与仪器仪表,2019,6(2):161-164.
[5] 王祥旭,潘伟,张琼,等. 人工智能辅助恶性肿瘤诊断的应用进展[J]. 肿瘤防治研究,2020,47(10):788-792.
[6] 高强,靳其兵,程勇. 基于卷积神经网络探讨深度学习算法与应用[J]. 电脑知识与技术,2020,5(13):169-170.
