基于主成分分析和差异表达基因构建口腔鳞状细胞癌诊断模型
2022-02-21温凌杜王子弘张国明赖茜杨宏宇
温凌杜, 王子弘, 张国明, 赖茜, 杨宏宇
1.广州医科大学研究生院,广东 广州(510000); 2.深圳市宝安中医院(集团)口腔科,广东 深圳(518000);3.深圳市宝安妇幼保健院口腔科,广东 深圳(518000); 4.北京大学深圳医院口腔科,广东 深圳(518000)
口腔鳞状细胞癌(oral squamous cell carcinoma,OSCC)为头颈部最常见的肿瘤之一,具有较强的侵袭性,常可导致局部浸润以及颈部早期淋巴结转移的发生[1⁃2]。鉴于OSCC 独特的解剖位置以及分子发病机制的多样性,目前临床对于OSCC 的治疗通常由外科、肿瘤内科或放疗科等组成的多学科团队来实施个性化的综合治疗方案,尽管在包括放化疗、靶向或手术治疗等方式中取得了较大的进展,但OSCC 的发病率和死亡率在过去十年并没有得到显著改善,患者的总体5 年生存率依然较低[3],因此在OSCC 早期诊断或筛查方面需要新的肿瘤标志物。主成分分析(principal component analysis,PCA)为一种广泛用于医学领域识别模式的多元统计方法,可对影响特定现象的因素进行分类,或通过切割方差较小的主成分(principal component,PC)以降低维数,从而筛选出可用于开发新模型的PC,而PC 的权重则可用于计算每个因素在数据中的贡献[4⁃5]。本研究拟通过TCGA 数据库筛选出OSCC 患者的差异表达基因(differentially expressed genes,DEGs)数据,并应用PCA 法来确定可用于OSCC 诊断的主要因素并以此构建诊断模型,以期为OSCC 的早期基因诊断以及PCA 模型在临床诊断中的应用提供理论依据。
1 资料和方法
1.1 微阵列数据收集与处理
从TCGA 数据库中,选择HTSeq⁃FPKM 工作流程,并以“other and unspecified parts of tongue、other and unspecified parts of mouth、floor of mouth、gum、lip、palate、base of tongue、other and ill⁃defined sites in lip、oral cavity and pharynx”为检索条件,获取截止于2021 年6 月2 日数据库中OSCC 样本与正常对照样本的RNA⁃seq 表达数据。通过Ensembl 数据库提供的“Homo_sapiens.GRCh38.104.chr.gtf.gz”文件行基因名称注释。
1.2 DEGs 的筛选
应用limma R 软件包对RNA⁃seq 表达数据行归一化处理,并以错误发现率(false discovery rate,FDR)<0.001 和|log2FC|>4 为具有统计学意义的阈值,行差异基因表达分析筛选出DEGs,结果通过ggplot2 R 软件包绘制火山图可视化。
1.3 DEGs 的富集分析
应用基因本体论(gene ontology,GO)和京都基因与基因组百科全书(Kyoto Encyclopedia of Genes and Genomes,KEGG)数据库,通过clusterProfiler、org.Hs.eg.db、enrichplot 和ggplot2 R 软件包,取P.ad⁃just<0.05 和Q<0.05 为筛选条件对DEGs 行富集分析,以发现DEGs 的主要生物学特征并绘制气泡图将结果可视化。
1.4 PCA 分析与OSCC 诊断模型的构建
将DEGs 拟作为诊断OSCC 的肿瘤标志物,随机选取RNA⁃seq 中DEGs 表达数据的70%作为训练集和30%作为测试集。训练集数据通过prcomp R函数行PCA 分析,明确PC 的特征向量和权重信息并构建OSCC 的诊断模型,其中PC 权重碎石图由ggplot2 R 软件包绘制。最后通过pROC R 软件包分别绘制训练集、测试集PCA 模型的受试者工作特征(receiver operating characteristic,ROC)曲线并计算曲线下面积(area under curve,AUC),其中AUC 在0.5~0.7 时为低准确性,AUC 在0.7~0.9 时为较高准确性,AUC 在0.9 以上时为高准确性[6],以评估PCA 模型对OSCC 的诊断优势。
2 结 果
2.1 微阵列数据的整理与DEGs 的筛选
从TCGA 数据库中共获取OSCC 样本RNA⁃seq表达数据330 例,正常对照RNA⁃seq 表达数据32例。对表达文件的原始微阵列数据进行处理和差异表达分析后,基于FDR<0.001 和|log2FC|>4 的截止标准总共筛选出组蛋白1(histatin 1,HTN1)、富含脯氨酸27(proline rich 27,PRR27)、组蛋白3(histatin 3,HTN3)、包含A 族成员2 的BPI 折叠(BPI fold containing family A member 2,BPIFA2)、胱抑素D(cystatin D,CST5)和富含脯氨酸的蛋白质HaeIII 亚家族2(proline rich protein Hae Ⅲsubfami⁃ly 2,PRH2)等159 个下调DEGs 和MAGE 家族成员A10(MAGE family member A10,MAGEA10)、溴域睾丸相关(bromodomain testis associated,BRDT)、G2/M 期特异性E3 泛素蛋白连接酶(G2/M⁃phase specific E3 ubiquitin protein ligase,G2E3)、亚精胺/精胺N1⁃乙酰转移酶像1(spermidine/spermine N1⁃acetyl transferase like 1,SATL1)、脂肪酰基辅酶A 还原酶2 假基因1(fatty acyl⁃CoA reductase 2 pseudo⁃gene 1,FAR2P1)和钙结合蛋白1(calbindin 1,CALB1)等248 个上调DEGs,数据结果由火山图行可视化处理(图1)。

Figure 1 Volcano map of DEGs distribution in OSCC图1 OSCC 中DEGs 分布的火山图
2.2 DEGs 的GO 与KEGG 富集分析
GO 注释(图2)显示HTN1、PRR27、HTN3、BPI⁃FA2、CST5 和PRH2 等407 个DEGs 主要富集的细胞成分(cellular component,CC)为中间纤维、黑素体膜、几丁质酶体和色素颗粒膜,以及色素和唾液相关的生物过程(biological process,BP),如发育性色素沉着、黑色素生物合成、黑色素代谢和唾液分泌。KEGG 通路富集分析(图3)显示DEGs 主要参与唾液分泌、酪氨酸代谢、淀粉和蔗糖代谢通路。结果均P.adjust<0.05 和Q<0.05。

Figure 2 GO enrichment analysis of DEGs图2 DEGs 的GO 富集分析

Figure 3 KEGG pathway enrichment anal⁃ysis of DEGs图3 DEGs 的KEGG 通路富集分析
2.3 PCA 分析与OSCC 诊断模型的构建
将DEGs 拟作为诊断OSCC 的肿瘤标志物,对训练集行PCA 分析。由PC 所占权重可见(表1、图4),PC1、PC2、PC3 方差的贡献率分别为0.873、0.100、0.023,三者累计方差的贡献率为0.996,而随着PC 的增多其累计方差的贡献率改变较小,故研究选取主成分前三,即PC1、PC2 和PC3 用于构建OSCC 的诊断模型。

Figure 4 Gravel graph of principal component weight图4 主成分权重碎石图
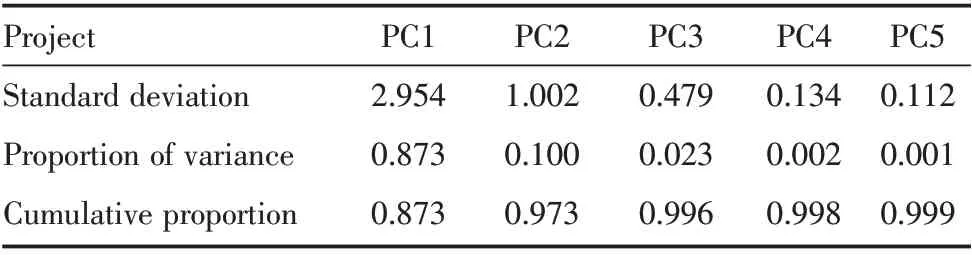
表1 主成分权重信息前五位Table 1 Weight information about the top five principal components
进一步结合PC1、PC2 和PC3 的特征向量(表2),构建以颌下腺雄激素调节蛋白3B(submaxil⁃lary gland androgen regulated protein 3B,SMR3B)、PRR27、HTN3、抗凝素(statherin,STATH)、CST5、BPIFA2、PRH2、角蛋白35(keratin 35,KRT35)、HTN1 和淀粉酶α1B(amylase alpha 1B,AMY1B)表达水平为基础的OSCC 诊断模型,模型方程如下。
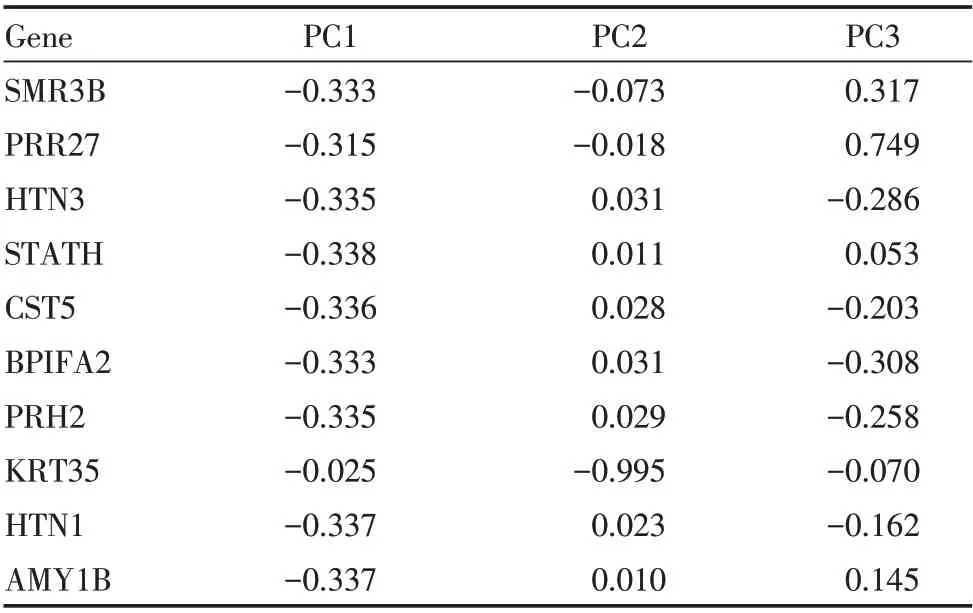
表2 PC1、PC2 和PC3 的特征向量Table 2 Feature vectors of PC1,PC2 and PC3
PC1=SMR3B×(⁃0.333)+PRR27×(⁃0.315)+HTN3×(⁃0.335)+STATH×(⁃0.338)+CST5×(⁃0.336)+BPIFA2×(⁃0.333)+PRH2×(⁃0.335)+KRT35×(⁃0.025)+HTN1×(⁃0.337)+AMY1B×(⁃0.337)
PC2=SMR3B×(⁃0.073)+PRR27×(⁃0.018)+HTN3×0.031+STATH×0.011+CST5×0.028+BPIFA2×0.031+PRH2×0.029+KRT35×(⁃0.995)+HTN1×0.023+AMY1B×0.010
PC3=SMR3B×(0.317)+PRR27×0.749+HTN3×(⁃0.286)+STATH×0.053+CST5×(⁃0.203)+BPIFA2×(⁃0.308)+PRH2×(⁃0.258)+KRT35×(⁃0.070)+HTN1×(⁃0.162)+AMY1B×0.145
PC综合得分=(PC1×0.873+PC2×0.100+PC3×0.023)/0.996
训练集ROC 曲线(图5a)显示PCA 模型的AUC值最高(0.852),并且在测试集ROC 曲线(图5b)中仍可看到该模型的AUC 值(0.844)较其他基因高,表明该模型在OSCC 的诊断中具有优势。

Figure 5 Training set and test set ROC curves图5 训练集、测试集ROC 曲线
3 讨 论
OSCC 是最常见的口腔癌类型,具有较高的发病率和恶性程度,可发生在口腔的任何部位,临床以舌前三分之二、上下牙龈以及颊部黏膜较为多见[7]。癌症的筛查或早期诊断被认为是改善预后和提高患者生存率的关键因素[8],口腔独特的解剖位置使临床医师可通过直接目视或触诊等常规检查来评估病变以便对可疑组织进行活检,但作为目前临床常规诊断方法,其对OSCC 检测的有效性仍存在争议。研究表明,基于该常规诊断方法仍有大多数OSCC 病例在早期阶段未被发现,而该病高死亡率的主要原因是超过50%的OSCC 患者首次就诊即被诊断为晚期[9]。在临床工作中也发现,有些患者无法完全张口进行检查,而且OSCC 和几种类型口腔潜在恶性疾病具有相似表现,OSCC 的诊断在很大程度上依赖于可以识别早期肿瘤变化的临床专业知识,但即便是高年资专业医师也难以完全准确区分口腔潜在恶性疾病和OSCC[10]。因此,需要提高OSCC 的早期确诊率以改善患者的治疗效果和预后。
以往研究发现脱落细胞DNA 计数、刷拭活检、微核分析等技术可用于OSCC 早期的诊断,但均存在一定的局限性[11]。肿瘤标志物可用作健康个体和口腔癌临床或组织学阴性患者的筛查工具[12],并且越来越多的研究表明OSCC 涉及多个致癌基因和抑癌基因。活化的蛋白激酶C1 受体(receptor for activated C kinase 1,RACK1)通过NF⁃κB 通路增加M2/M1 巨噬细胞比率从而促进OSCC 进展[13],KN 基序和锚蛋白重复结构域1(KN motif and an⁃kyrin repeat domains 1,Kank1)的异常表达调节Yes相关转录调节蛋白1(Yes1 associated transcriptional regulator,YAP)以促进OSCC 中的细胞凋亡并抑制增殖[14],MiR⁃92a 通过靶向叉头框蛋白P1(forkhead box P1,FOXP1)表达来调控OSCC 细胞的生长[15],这些基因的发现有助于更好地了解OSCC 在分子水平的发病机制,也为挖掘可用于早期诊断或筛查OSCC 的肿瘤标志物提供了基础。转录组测序(RNA sequencing,RNA⁃Seq)技术的出现使研究者可以获取OSCC 患者的基因表达数据,而当数据集包含大量变量时,PCA 作为探索性数据分析的工具,通常用于在构建预测模型之前进行的变量降维,通过数据协方差矩阵的特征值分解或数据矩阵的奇异值分解来执行,可将大量预测的变量减少到几个PC,特别是在嘈杂或具有强相关变量的数据集中[16]。PC 则是解释数据方差原始变量的线性组合,线性组合中每个变量对应的系数表示该变量在分量中的相对权重,系数的绝对值越大,对应的变量在计算分量中越重要[17]。Kang 等[18]研究发现PCA 法可通过对三维计算机断层扫描图像上的大量解剖标志变量分析中识别出最具特征的变量,从而可用于确定哪些解剖结构可最能表征患者的主要变异。秦明丽等[19]基于对132 例卵巢癌患者和211 例卵巢良性肿瘤患者的血清癌胚抗原(carcinoembryonic antigen,CEA)、糖类抗原125(carbohydrate antigen 125,CA125)、糖类抗原153(carbohydrate antigen 153,CA153)等8 项肿瘤标志物建立的PCA⁃多层感知器(multi perceptronlayer,MPL)⁃人工神经网络(artificial neural network,ANN)模型研究发现,该模型可有效提升卵巢癌的诊断效能,可为卵巢癌的智能化辅助诊断提供参考。
本研究前期通过TCGA 数据库筛选出OSCC与正常对照样本之间的DEGs,拟将其作为OSCC的肿瘤标志物以明确是否可用于其诊断。但即便研究中将DEGs 的筛选条件调整为FDR<0.001和| log2FC |>4,仍有159 个下调DEGs 和248 个上调DEGs,共407 个DEGs 被筛选出来。由于这些DEGs 中包含数据较大,难以确定哪些基因可作为最能体现诊断OSCC 的因素,故应用PCA 法对数据进行降维处理。发现PC1、PC2 和PC3 方差的贡献率分别为0.873、0.100、0.023,三者累计方差的贡献率为0.996。而自PC3 后,即便随着PC 的增加,累计方差的贡献率值较前三者叠加已变化不大,表明通过PCA 法处理后,PC1、PC2、PC3 即可代表原DEGs 的数据特征,从而可用于OSCC 的诊断。研究进一步通过PC1、PC2、PC3 累计方差的贡献率和特征向量构建以SMR3B、PRR27、HTN3、STATH、CST5、BPIFA2、PRH2、KRT35、HTN1 和AMY1B 表达水平为基础的OSCC PCA 诊断模型。在训练集和测试集的ROC 曲线中可以发现,该模型的AUC值分别为0.852、0.844,较模型内其他基因相比表现出明显的诊断优势,并且具有良好的稳定性。尽管该模型在OSCC 诊断方面显示出其优越性,但对于癌前病变或癌前状态尚未进行具体分析鉴别,且本研究仅基于TCGA数据库在生物信息学层面进行,而要应用到中国人群OSCC 诊断之前,建议结合国内患者人群的数据信息进行验证。
综上所述,本研究基于PCA 法和DEGs 构建的以SMR3B、PRR27、HTN3、STATH、CST5、BPIFA2、PRH2、KRT35、HTN1 和AMY1B 表达水平为基础的模型对OSCC 具有较高诊断优势,可为OSCC 的早期基因诊断以及PCA 模型在临床诊断中的应用提供理论依据。
【Author contributions】Wen LD, Wang ZH processed the research,analyzed the data, and wrote the article. Zhang GM, Lai Q assisted the data analysis. Yang HY revised the article and designed the study. All authors read and approved the final manuscript as submitted.
