一种基于区块链与联邦学习的数据隐私保护方法
2022-02-20杨通来黄家铭罗小杰钟连连
张 桉,杨通来,黄家铭,罗小杰,钟连连
(广西壮族自治区信息中心,广西 南宁 530020)
0 引言
在过去的几年里,大数据已经发展成为一个新兴领域。在大数据时代,随着信息量与日俱增,数据价值也得到越来越多人的认可。在人工智能领域,机器学习技术创新允许以新的方式处理各种实时创建的海量数据(物联网传感设备、M2M通信、社交应用、移动视频等)。为重复利用非结构化信息和从信息中提取价值提供新的机会,需摆脱结构化数据库的限制,识别相关性,构思新的、意想不到的用途。
大数据在迅猛发展的同时也带来不少问题,如管理数据、实现数据价值最大化等,这些问题始终未得到完美的解答[1]。例如,当它们支持对气候变化、流行病传播或药物副作用的预测,它们往往会对隐私和个人数据保护构成严重挑战[2]。此外,由于各个企业和部门之间相互独立,数据所在的系统甚至数据存储结构存在较大差异,因此数据之间难以进行信息共享,造成信息孤岛这一普遍现象。同时,互联网庞大的使用群体,也使得互联网数据在实现共享时,难以保障数据的安全性及数据隐私。尽管大数据分析带来了好处,但是人们不能接受大数据是以隐私为代价的。因此,在利用大数据技术和个人数据隐私保护之间取得适当的平衡是至关重要的[3]。为了解决这些问题,大数据治理与隐私保护技术成为当下学术界与工业界最热门的研究领域之一。
联邦学习(FL)是一种分布式机器学习(ML)框架,其中数据所有者/客户端在中央服务器的协调下联合训练模型,而客户端的原始数据保留在本地,它们不与任何其他方传输或共享[4]。在智慧医疗中,个性化模型需要保护个人健康信息。FL可以集成来自私有来源的数据,而无须共享私有数据本身。具体来说,FL保护用户隐私主要通过交换作为学习的主体(客户端)之间的更新模型。由于FL不涉及从所有数据服务收集数据并将其存储在服务器上,因此它被视为在保护用户隐私的同时进行机器学习的一种有前途的解决方案。
然而,在传统的FL设置中,大多数FL部署都遵循集中式的星型拓扑结构。全局模型聚合服务器分发模型供客户端训练,收集客户端的模型更新,然后重新分发更新的全局模型,直到训练完成。中央服务器可能成为整个系统安全和性能的单点故障,存在模型中毒、隐私泄露、网络延迟和模型收敛延迟挑战等问题[5],从而限制了联邦学习在大数据分析广泛使用。为了大规模利用人工智能进行大数据分析,我们需要一个自动化和可执行的协作机制,确保参与者之间的执行完整性,并防止恶意企图。
区块链(blockchain)本质上是一种分布式、防篡改的账本,不依赖一个集中的权威机构来建立信任,通过共识机制进行分布式信任管理[6]。自从比特币问世以来,区块链被用于加密货币、安全存储和资产转移等应用。区块链可以在联邦学习中充当一个不变的、去中心化的账本,很好地解决中央服务器单点故障的问题。目前,学术界已经提出了几种利用区块链取代中央服务器的方法[5]。然而,这些方法假定客户端诚实,不打算破坏全局聚合模型,并可以将资源投入到在线和本地模型训练上。但是,恶意客户端可能会以多种方式损害全局模型的性能。例如,它们可能会退出训练,拒绝上传模型更新,使用低质量或虚假数据训练模型,或者只是用随机向系统发送模型更新。
为了解决以上提到的问题,本文提出了一种安全可靠的基于区块链的分布式联邦学习架构(Fchain)。在FL模型聚合过程中,用区块链智能合约取代传统的中央聚合服务器,以减少对服务器/其他客户端的信任依赖。将区块链的共识机制与去中心化评分机制相结合,保持机器学习性能和去中心化,防止恶意客户端进行模型中毒攻击。
1 相关工作
1.1 联邦学习
联邦学习涉及从存储在数千万台可能数百万台远程设备上的数据中学习单一的全局统计模型。具体而言,通常是最小化以下目标函数[7]:
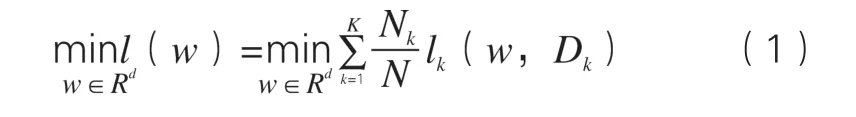
形式上,FL算法的目标是以分布式(联邦)方式解决监督学习优化问题。为此,一组客户端K={1,2,…,K}试图通过使用其大小为Nk本地数据Dk同时优化全局模型参数w∈Rd。由给出的客户的局部损失被组合以最小化全局成本函数l(w,Dk)。为了解决公式(1)中的优化问题,在传统FL中,服务器迭代地与客户端交互,在每次迭代中,客户端提供根据对本地(非共享)数据集的训练而产生的本地模型更新。在FL迭代中,服务器将全局模型(例如,参数)推送到一组客户端,所述一组客户端执行设备上的训练(例如基于不同的本地数据分区训练神经网络几个历元)并上载其模型更新。一旦服务器收集和聚合了模型更新,就会计算新的全局更新。运行更多的迭代直到收敛(如图1),客户端将本地模型提交给服务器,然后通过平均聚合这些模型。
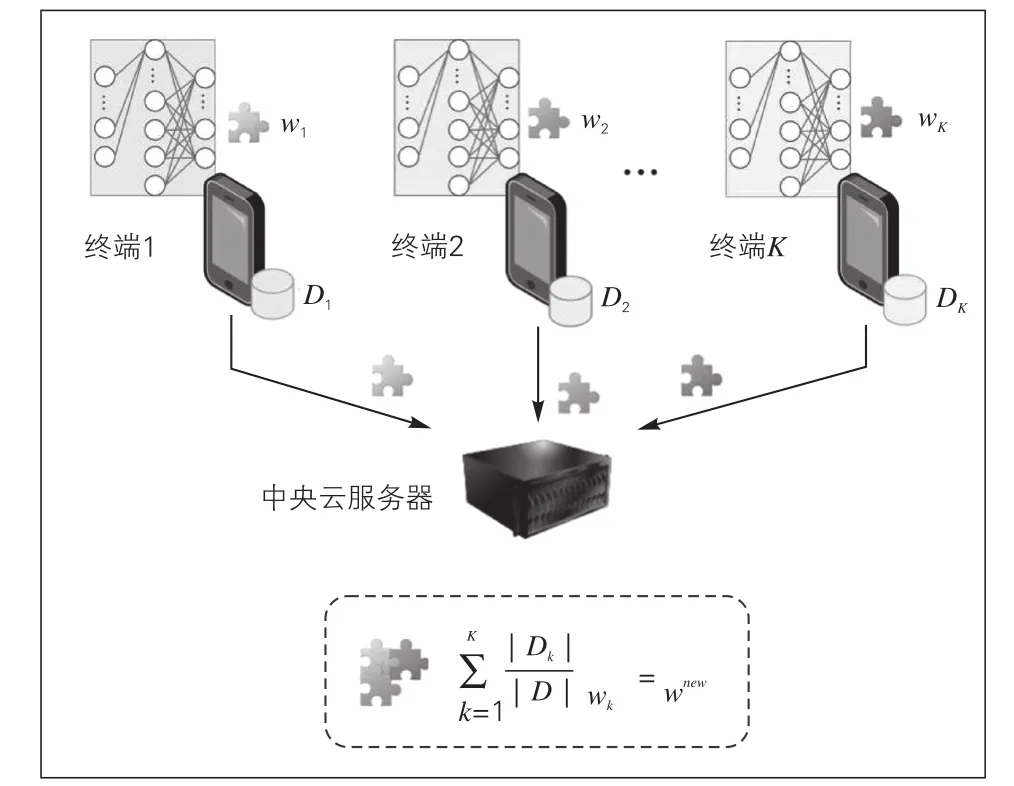
图1 传统联邦学习训练框架
在传统联邦学习训练框架中,分布式的恶意客户端针对数据的攻击对基于人工智能的系统产生了巨大影响。在模型训练阶段,潜在攻击者可以访问用于训练的数据集,并用对抗性样本污染数据集。通过利用人工智能模型对输入的微小变化的极端敏感性,可以在训练阶段危害数据,这些变化利用了模型的异常行为,分别称为中毒和逃避攻击。恶意对手还可以在测试阶段创建敌意输入欺骗分类器或逃避神经网络的检测。这些攻击可以是物理攻击,也可以是数据攻击。在这项研究中,将重点放在数据攻击上。数据方法直接在输入中引入微小的扰动。工业界和学术界为解决以上的问题提出了很多解决方案,区块链技术是其中一种很有前景的解决方案[8]。
1.2 区块链技术
区块链是一种工作在Peer-to-Peer网络上的分布式存储技术。网络节点也称为区块链节点,它们充当完全相同的角色,并根据系统中指定的智能合同执行相同的功能。
在区块链系统中,每个节点都保存着区块链存储的整个副本,其中事务被打包成块,每个块通过块散列链接到前一个块,参与者通过检查内容和伴随的散列指针来共同验证所有事务。节点的行为由区块链上定义的智能合约来监督,其中规定了共识机制和激励机制。共识机制是维护系统分散性和存储块的核心功能,它通过小心地将分隔权授予被称为挖掘器的节点之一。激励机制帮助共识机制分配工作报酬,激励节点诚实地继续工作[9]。因此,如果足够多的参与者是正确的,虚假交易就会被拒绝。这些机制确保了系统是防篡改的,因为恶意用户无法说服正确的参与者切换到区块链的错误分支。这也是区块链直观地建立去中心化信任的方式。区块链系统的典型分层架构如图2所示。
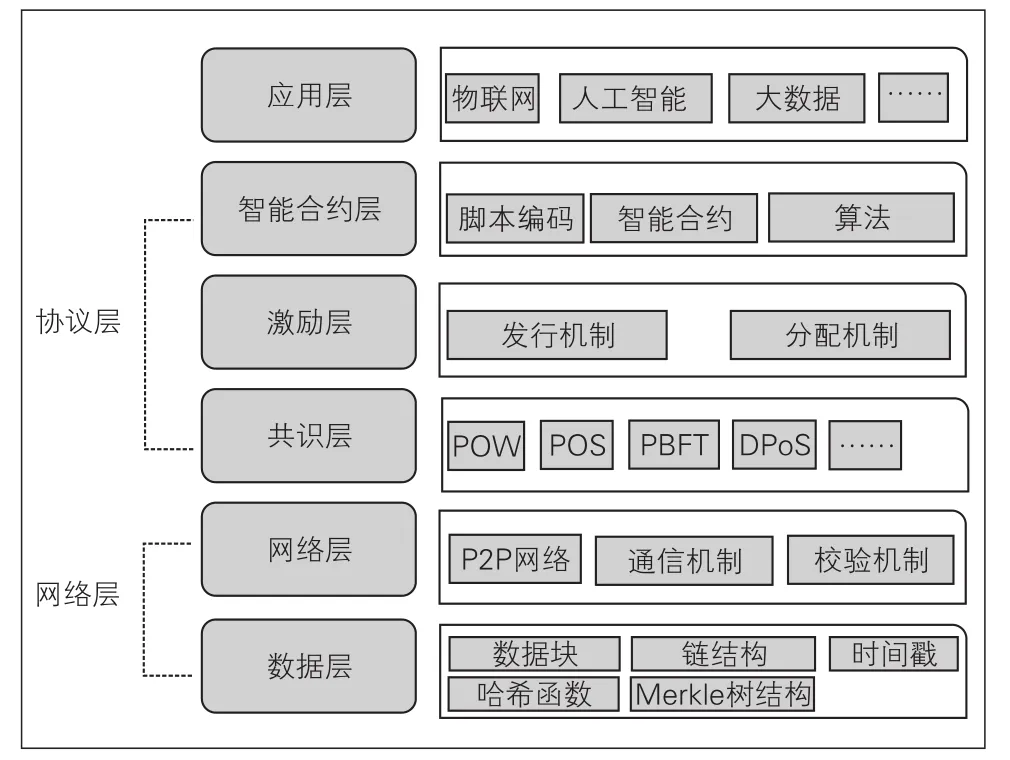
图2 区块链分层结构
区块链已被证明在比特币、以太坊、PeerCoin等加密货币应用中取得了显著的成功,区块链在其他许多领域的采用正在不断扩大现有的区块链生态系统。例如,已在金融分类账系统、物联网、云计算、公共管理、医疗保健和供应链等领域开发了支持区块链的系统[10-11]。区块链工作流程图如图3所示。
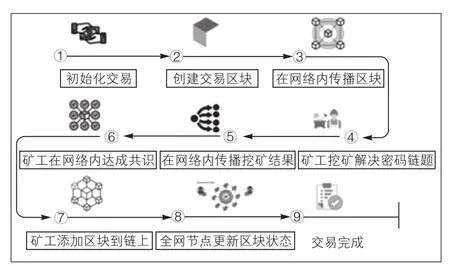
图3 区块链工作流程图
2 基于区块链与联邦学习的大数据分析系统
系统模型如图4所示。
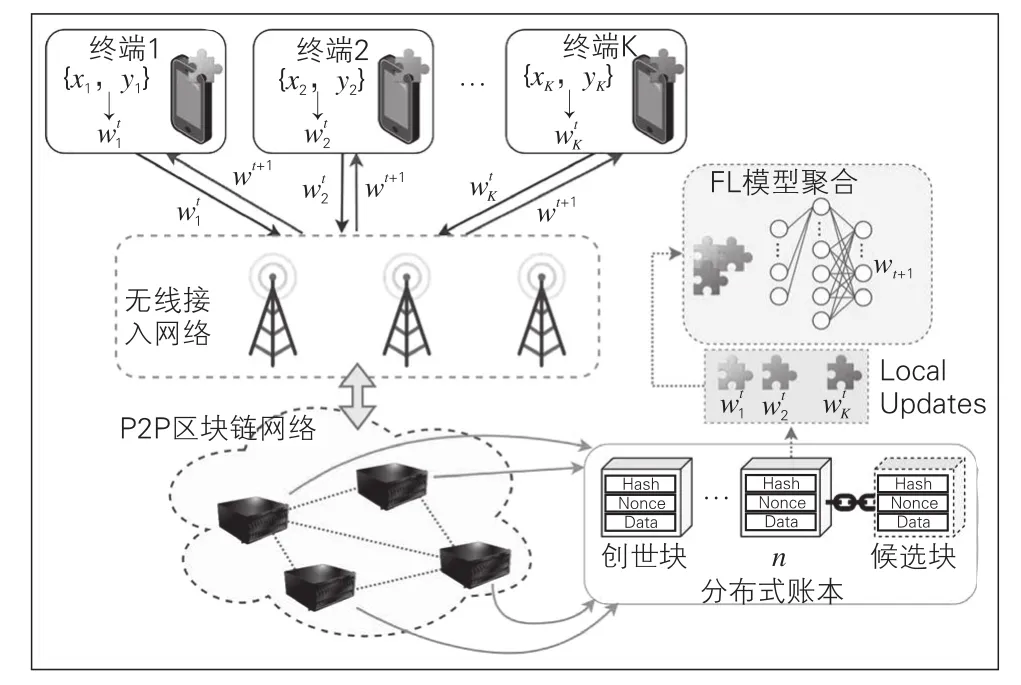
图4 基于区块链与联邦学习大数据分析系统模型
2.1 系统流程
基于区块链的联邦学习大数据分析系统由系统设置阶段和训练阶段两个阶段组成。参与者在设置阶段准备数据和代币,并在多个模型训练阶段以可审计的方式协作训练模型,每个训练阶段包括4个步骤:本地培训、链上聚合、委员会投票和奖励(如图5)。
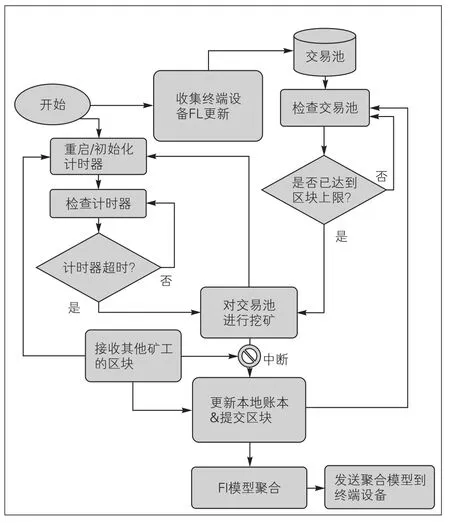
图5 基于区块链的联邦学习大数据分析流程图
2.2 模型训练流程
在区块链联邦学习集群系统中主要有3种参与者:①数据提供者,根据其本地私有数据集对模型进行训练,并报告权重更新。②投票者,在每个培训阶段审计聚合的模型权重,通过区块链选择委员会节点。③矿工,在区块链上主动存储交易并生产区块的节点。本文主要针对客户端的工作流程,而矿工部分与其他区块链系统中的类似。值得注意的是,现实世界中的一个人并不局限于充当集群系统中的一个参与者,这给整个系统增加了额外的安全要求,使在这种情况下恶意策略变得更加复杂。系统的机制设计也是为了防御这种复杂的恶意行为。
2.2.1 联邦学习任务设置阶段
任何参与者都应该首先将一些代币作为抵押品放入集群系统中,以表示他们的承诺。然后在奖励阶段,将使用代币奖励诚实的行为者,惩罚恶意行为者。对于矿工来说,更多的代币有助于被选为区块生产者并获得区块奖励的概率,即所谓的股权证明(POS)机制。为了参与模型训练,终端用户应该准备一个私有的训练数据集,并准备一个用于本地模型选择的验证数据集。任何想要成为委员会投票人的节点都应该准备一个本地测试数据集,用于全球模型权重审计。显然,投票者可以省略部分训练数据集作为测试数据集。在系统中应用了一种新颖的奖励机制来激励诚实的数据提供者和投票者,并惩罚恶意参与者。
2.2.2 联邦学习模型训练阶段
模型训练阶段包括以下4个步骤。
(1)本地局部模型训练:每个节点在每个训练阶段结束时接收相同的全局模型权重。在新的训练阶段开始时,从所有有资格训练模型的节点中随机选择几个节点作为该阶段的模型建议者。只有被选择的节点才被允许基于全局模型本地训练它们的模型,并向集群系统提出局部模型更新。
(2)区块链上模型聚合:在本轮中,被选中的生成块的挖掘器收到提议方的局部模型权重更新后,将通过FedAvg协议聚合权重,并将全局模型权重发布到区块链上。然而,由于矿工可能是恶意的,并审查特定的提名人以获得利益,因此需通过其他挖掘器验证模型聚合的正确性。因此,在全局模型权重提出后,其他挖掘者将在进入下一步之前开始一轮投票,以验证聚合结果的有效性。
(3)区块链委员会投票:为了避免错误的模型权重更新,惩罚恶意提出者,在所有符合条件的参与者中随机选择一个审计委员会对全局模型权重进行评估。每个委员会投票人在本地评估先前准备的测试数据集上的模型性能,并基于性能计算投票分数。之后,每个投票者只需将投票分数上报给区块链矿工进行计票即可。自动链上协议将根据投票分数确定本轮全局模型权重是否会被丢弃。
(4)奖励:为了激励诚实的行为,摆脱不良行为,研究人员在每个培训阶段结束时根据投票分数重新分配所押注的代币。对于提名者,奖励/斜杠是根据投票分数给予的。对于选民,我们根据他们的个人投票分数与最终汇总分数和投票方向之间的差异计算奖励/扣减的金额。我们对系统进行了配置,最终诚实的参与者将获得奖励,恶意的参与者将被砍掉。由于每个参与者都应该设置足够的令牌来参与,因此恶意参与者最终会在他们的令牌被砍掉时退出系统。通过这种方式,集群系统在不牺牲最终模型性能的情况下促进了安全和真实的联邦学习过程。
3 仿真与性能评估
为了评估Fchain解决方案,研究人员使用了一个流行的联合图像分类数据集:EMNIST。EMNIST数据集包含手写数字的图像,分布在不同用户中,它包括341 873个训练样本和40 832个用于评估的测试样本。研究人员使用简单的开箱即用前馈神经网络(FNN)和更复杂的卷积神经网络(CNN)解决EMNIST提出的手写图像识别问题。在评估中,将数据集分割为几个分区,关注K={10,50,100,200}个随机客户端(如图6)。
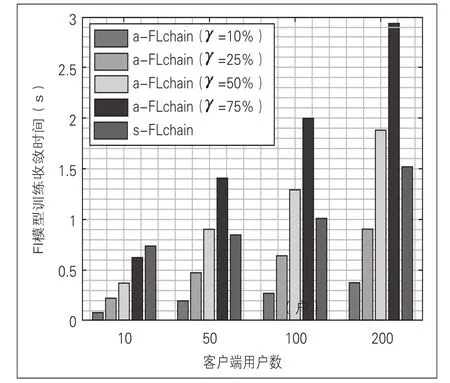
图6 客户端用户数对FL模型训练收敛影响
在每一轮FL中调整块大小,考虑较小的用户子集。因此,假设所有本地更新都具有相同的大小,我们将定义为构建块所需的用户百分比。同步的情况对应于Y=100%,这是因为考虑的所有客户端的更新都包含在单个块中。定时器被设置为任意高的值,以忽略其影响并仅关注块大小。
4 结论
本文讨论了分布式联邦学习这一新兴课题,并提出了使用区块链技术以安全、透明和可靠的方式实现分布式联合优化;重点研究了去中心的隐私保护FL框架,用于学习存储在不同终端中的数据的有效模型;提出了效用最大化和FL损失函数最小化的联合优化问题;利用区块链技术来实现抵抗分散的恶意客户端模型中毒攻击。
未来,研究人员希望考虑其他隐私保护技术,如安全多方计算或同态加密;希望致力于基于区块链的节能FL框架,以降低FL过程中的能耗。此外,将考虑最先进的神经网络结构和不同的数据增强技术观察隐私参数对准确率的影响。
