基于局部对比度和相位保持降噪的古籍图像二值化算法
2022-02-19冯炎
冯 炎
(西藏大学信息科学技术学院 西藏 拉萨 850000)
0 引 言
古籍具有重要的学术价值和文化价值,古籍数字化修复是解决古籍保护与文化传播的重要途径,二值化是数字化修复的关键预处理步骤,同时二值化算法也是学者们研究的热点问题。受自然环境和人为因素的破坏,多数古籍具有不同程度的页面污渍、褪化和油墨印迹等复杂背景,给古籍二值化带来极大的挑战。
为提高图像二值化算法性能,学者们提出了大量的算法,最关键的问题是阈值计算,二值化算法可以分为全局阈值法和局部阈值法。经典的全局阈值算法是Otsu算法[1],经典的局部阈值算法是Niblack算法[2]和Sauvola算法[3],局部阈值方法相对于全局阈值方法来说二值化准确度较高。Otsu算法使用聚类的思想,提出了一个最优化阈值计算方法,选择一个阈值使得两个类内的方差尽可能小,类间的方差尽可能大,该算法适用于直方图具有明显双峰模型的图像,缺点是在低对比度和光照不均的条件下效果不好。Niblack算法根据局部均值和局部标准差为每个像素计算阈值,该算法能很好地将对比度低的字符分割出来并保持文字细节,该算法对局部窗口大小的选择敏感,窗口太大会丢失文字局部细节,窗口太小会有残留噪声。Sauvola是Niblack算法的改进版本,以局部均值为基准再根据标准差做些微调,从而过滤掉背景中一些干扰的纹理噪声,算法缺点是在对比度较低的情况下效果仍然不好。
Lu等[4]提出了基于背景估计和笔划宽度估计的二值化方法,算法首先通过迭代多项式平滑算法来估计古籍文档图像背景,然后用所估计背景去补偿因不同退化类型造成的古籍文档退化情况,对补偿后的文档图像计算L1范数图像梯度来获得文本笔划边缘,最后在局部相邻窗口内计算补偿后的像素均值和笔划边缘个数来对文档图像进行二值化处理。接着,Su等[5]提出了一种改进算法,该算法使用局部图像对比度和局部图像梯度来组成自适应图像对比度算法,然后用自适应图像对比度算法和Canny边缘检测算法来计算文字笔划边缘,从而较准确地计算出文本笔划边缘并估计出文本笔划宽度。最后采用Niblack二值化算法结合所估计的文本笔划宽度来估计局部阈值并从古籍文档图像中分离文本。Howe[6]提出了一个基于拉普拉斯图像的全局能量函数最优化方法,该方法采用一系列的训练图像用于最优化算法,在DIBCO 2013[7]会议所提交的23个算法中该算法获得了第二名,该算法的缺点是对退化严重的图像效果不理想。
虽然学者们提出了众多的算法,然而这些方法都不能很好地解决在低对比度和重污渍等复杂背景下的古籍图像二值化问题。
1 本文的算法
本文针对古籍图像所存在的复杂背景,提出一种二值化算法,算法流程如图1所示,分为三个步骤:(1) 文本笔划像素识别,根据归一化局部最大值最小值来构造局部对比度图像,同时对古籍图像进行相位保持降噪,将局部对比度图像与降噪图像相结合来识别文本笔划像素;(2) 古籍背景估计,通过局部窗口内所检测的文本笔划像素估计局部阈值来计算古籍背景修复模板,用图像修复算法和形态学闭操作估计古籍背景;(3) 古籍图像增强及最终二值化,用所估计背景来增强图像文本对比度,并用Howe算法对增强后的古籍图像二值化求得最终结果。算法过程如图2所示,示例图片选自DIBCO2018数据集。
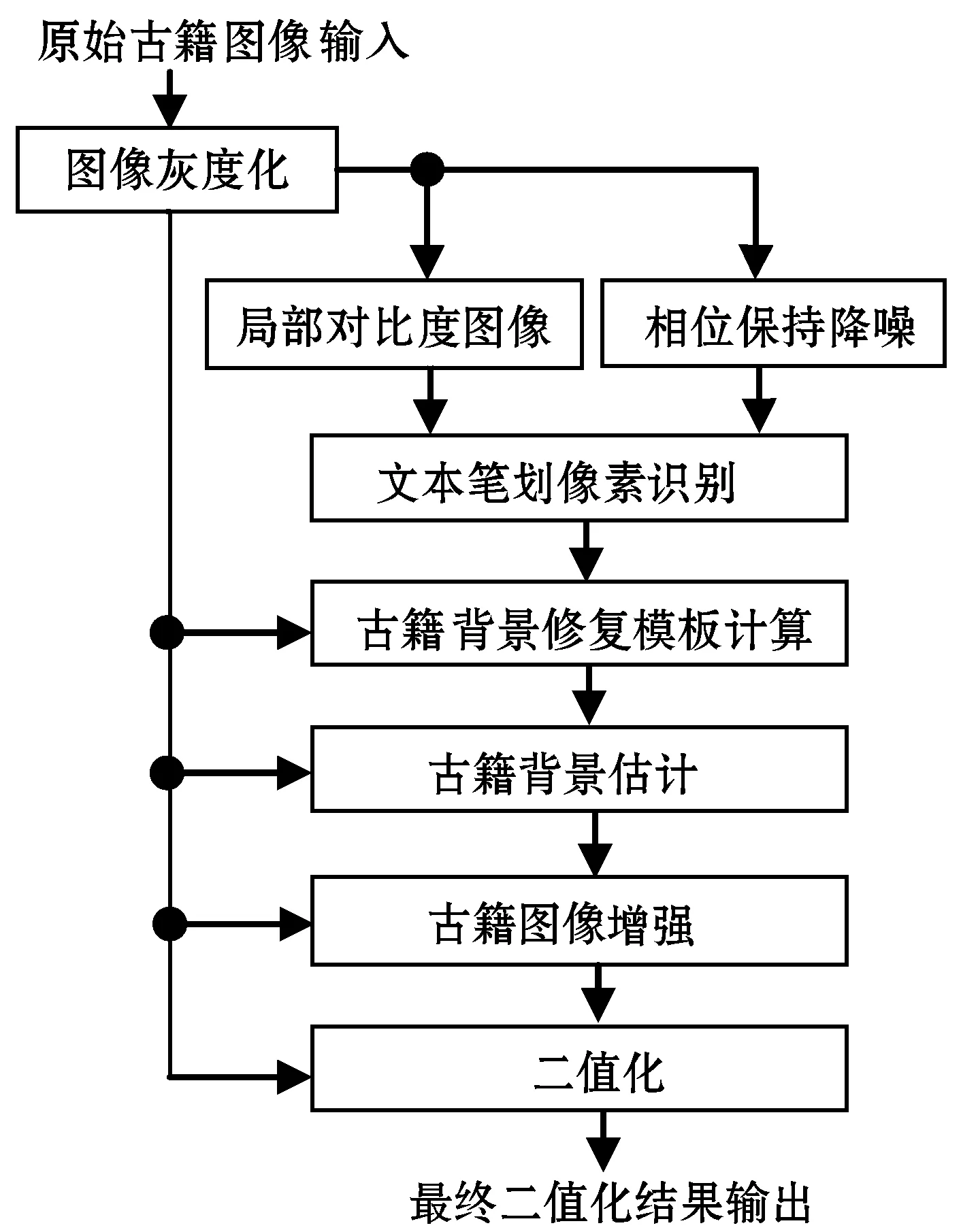
图1 本文算法流程

图2 本文算法过程展示
1.1 文本笔划像素识别
前期研究中发现两个问题,第一是文献[5]算法通过局部对比度和局部梯度来检测文本笔划边缘,但无法处理细弱笔划和低对比度区域的文本笔划;第二是Kovesi[8]的相位保持降噪算法结果会保留细弱笔划区域和低对比度区域的文本笔划,然而受古籍退化的影响,该方法容易将文本笔划边缘丢失。为了更准确地识别文本笔划像素,本文结合文献[5]算法和Kovesi相位保持降噪算法的优缺点,将局部对比度图像与降噪图像相结合设计一种文本笔划像素识别算法。
首先,根据文献[5]算法,本文设计了基于最大值最小值的局部对比度改进算法,改进后的局部对比度图像C计算如下:
(1)
然后,算法采用Kovesi[8]提出的相位保持降噪算法对古籍图像进行降噪并归一化处理,计算方法如下:
D=normalization(kovesi(I))
(2)
式中:I为古籍图像;nomalization为归一化函数;kovesi为相位保持降噪算法。采用Otsu算法对归一化后的降噪图像D二值化,二值化后的结果表示为Db。
最后,将局部对比度图像二值化结果Cb与相位保持降噪图像二值化结果Db相结合来识别文本笔划像素T,方法如下:
T(i,j)=Cb(i,j)×Db(i,j)
(3)
1.2 古籍背景估计
本文采用背景修复算法来消除修复模板中确定的文本信息从而获得古籍背景,要求背景修复模板中的文本信息尽可能准确并且不包含背景信息。然而,前面所识别的文本笔划中残留背景噪点太多,因此,本文采用局部阈值算法从原始古籍图像中提取文本信息来计算背景修复模板M,局部阈值的计算是根据局部窗口内所检测的文本笔划像素T估计局部阈值,背景修复模板M计算方法如下:
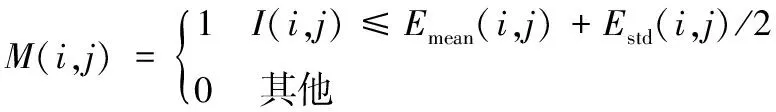
(4)
式中:I(i,j)为古籍图像像素;Emean(i,j)和Estd(i,j)分别是局部窗口内所检测文本笔划像素T(i,j)的局部均值和局部标准方差;窗口大小为2×Ewith,Ewith为古籍文档笔划宽度。
跟前面的文本笔划像素T相比,背景修复模板M估计的文本信息更准确,但引入了其他背景噪声,需要进一步消除这些噪声,方法如下:
Mdenoise(i,j)=1-(1-M(i,j)×(1-T(i,j)))
(5)
另外,背景修复模板中会出现断裂笔划并且文字中有空洞,还需要用图像腐蚀操作对Mdenoise处理从而获得较为准确的文本区域,腐蚀后的背景修复模板表示为Merode,腐蚀操作采用半径为Ewith的菱形结构元素,Ewith为古籍文档笔划宽度。
接下来采用Ntirogiannis等[9]的背景修复算法对原始古籍图像I操作来估计古籍背景BG,修复模板为前面计算得到的Merode。最后通过形态学闭操作进行背景平滑消除背景中存在的较弱或断裂笔划的文本信息,从而获得更准确的古籍背景BGsmooth,闭运算操作时采用的结构元素半径为2×Ewith。
1.3 古籍图像增强及最终二值化
为了获得更准确的二值化结果,本文用所估计古籍背景BGsmooth来增强古籍图像的文本对比度,接着用Howe[6]的binarizeImageAlg3算法对增强后的二值化处理获得最终结果。
其次,教师行为的集体化问题。现代教学中教师的含义变得广泛了,不仅包含了传统意义的教师,也包含了教学设计员等。在执行某一课程时,不是某一位教师可以完成的,必须是多名教师发展各自的特长,共同完成课程任务。教师与教师的合作必然导致教师行为的集体化。课程的编制将是集体劳动的结晶。此时,学生面对的不再是一位教师,而是一个专家组,要求教师的教学行为更进一步协调。
2 实 验
2.1 实验环境及评估方法
本文的实验测试数据采用了DIBCO2016[10]、DIBCO2017[11]和DIBCO2018[12]提供的古籍图像数据集。其中:DIBCO2016数据集包含10个手写体古籍图像;DIBCO2017数据集有10个印刷体和10个手写体古籍图像;DIBCO 2018数据集包含10个手写体古籍图像。这些古籍图像是具有不同退化类型的低质量图像,并有相应的基准图像,使用这些数据集可以有效地检验本文算法是否有效。
实验采用了5种图像客观评价指标对本文算法进行评估,具体是F值(Fmeasure)、峰值信噪比(Peak Signal to Noise Ratio, PSNR)、精确度(Precision)、距离倒数失真度量(Distance Reciprocal Distortion, DRD)和错误分类处罚指标(Misclassification Penalty Metric, MPM)。Fmeasure值是一种兼顾准确率和召回率的图像二值化度量方法,Fmeasure值越大说明二值化结果越接近于基准图像。 PSNR是基于对应像素点间的误差质量评价, PSNR越大说明图像二值化效果越好。Precision是二值化结果的正确率,指的是二值化结果中文本像素个数占的比例,指标值越大说明算法精确度越高。DRD是图像失真度量方法,DRD值越小说明图像失真越小。MPM惩罚分类错误的像素,MPM得分越小表示分类错误越少。
本文实验选取了Howe[6]、Niblack[2]、Sauvola[3]、Bernsen[13]、Otsu[1]、Mesquita[14]等6个有代表性的二值化算法与本文算法进行比较。算法中Kovesi[8]保持相位降噪算法参数为:k=1,nscale=5,mult=2,norient=3,softness=1。本文二值化算法是在图像增强的基础上进行二值化,未采用Howe提供的参数,而是根据实验值设置为:thilist=[0.3 0.6]。
2.2 实验结果分析
为直观地展示本文算法与其他二值化算法的优缺点,显示本文算法的优越性,从DIBCO2017和DIBCO2018选取了2幅有代表性的测试图像,图3给出了本文算法与其他算法的对比结果。

图3 不同二值化算法结果对比
图3 (a)的原始图像左边是纤细笔划图像,右边是墨迹浸润图像,可以看出,文献[1]算法对于对比度较高的区域二值化效果较好,但无法处理页面线条、有污渍的低对比度区域以及细弱笔划文本;文献[3]算法、文献[2]算法和文献[13]算法残留噪声太多,更容易将较深的背景污渍和浸润墨迹错判为文本;文献[14]算法和文献[6]算法虽然能抑制噪声,但对于页面线条、有墨迹浸润的低对比度区域的处理结果不理想;本文提出的二值化算法能够很好地解决复杂背景噪声的干扰问题,能有效地处理页面线条和有浸润墨迹的低对比度区域,总的来说,本文算法结果比较满意。
表1给出了各二值化算法在DIBCO2016数据集中10个图像的二值化结果平均值对比。Fmeasure和PSNR以及 Precision的值是越大越好,而DRD和MPM值是越小越好。如表1所示,本文算法的平均PSNR值、平均Fmeasure值、平均Precision值、平均DRD值和平均DRD值都是最优。与次优的文献[14]算法相比较,本文算法的Fmeasure、PSNR和 Precision分别提高了1.0%、1.4%和1.5%,DRD降低了18.1%,尤其是MPM值降低了46.2%。
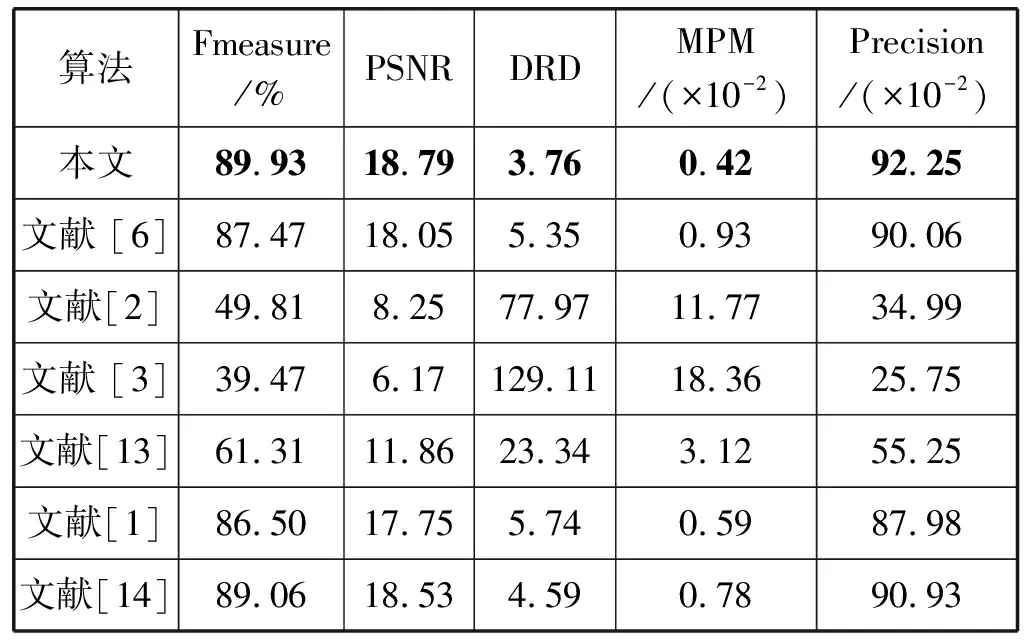
表1 各二值化算法在DIBCO2016的评估结果(平均值)
表2给出了不同二值化算法在DIBCO 2017数据集中20个图像的二值化结果平均值对比。如表2所示,本文的算法性能指标都排第一,文献[6]次之,文献[14]排第三,文献[3]性能最差。跟文献[6]算法比较,本文算法的平均Fmeasure、PSNR和 Precision分别提高了1.0 %、2.5%和1.8%,DRD和MPM值分别降低了13.1%和25.0%。
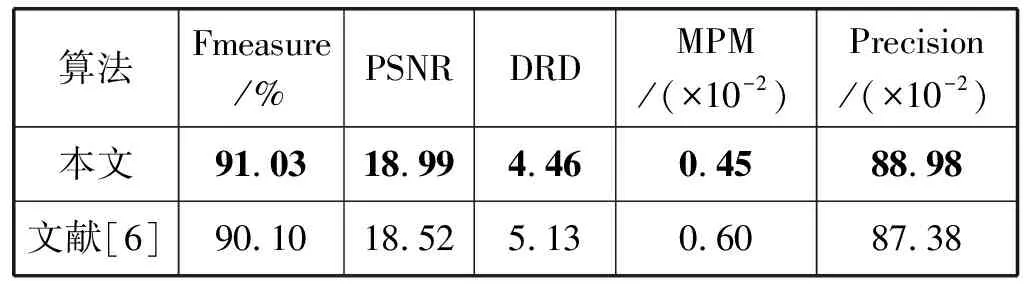
表2 各二值化算法在DIBCO2017的评估结果(平均值)
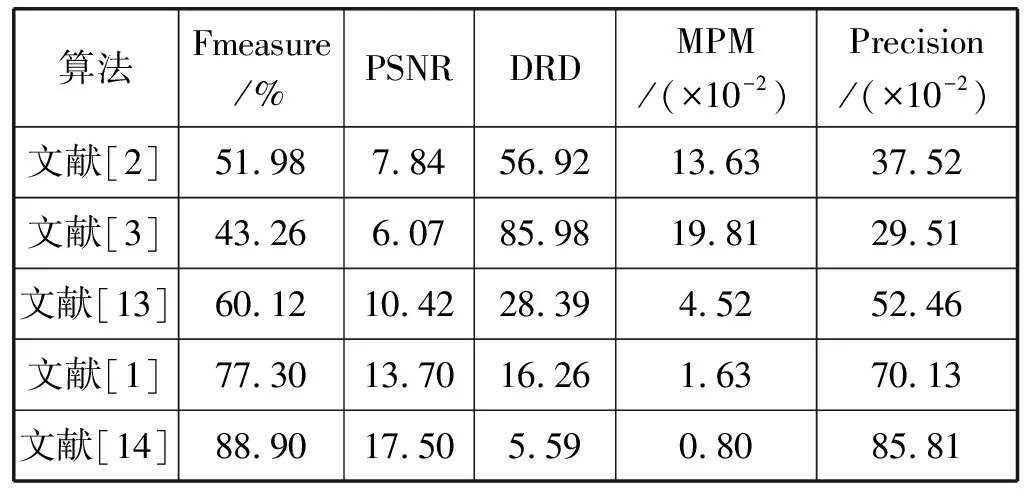
续表2
表3给出了各二值化算法在DIBCO2018数据集中10个图像的二值化结果平均值对比。可以看出,本文算法各项指标值最优,文献[6]次之,文献[14]排第三,文献[3]性能最差。跟文献[6]比较,本文算法的平均Fmeasure、PSNR和 Precision分别提高了6.3%、12.3%和7.2%,而DRD和MPM分别降低了49.3%、53.9%。DIBCO2018数据集更能体现本文算法的优越性能。
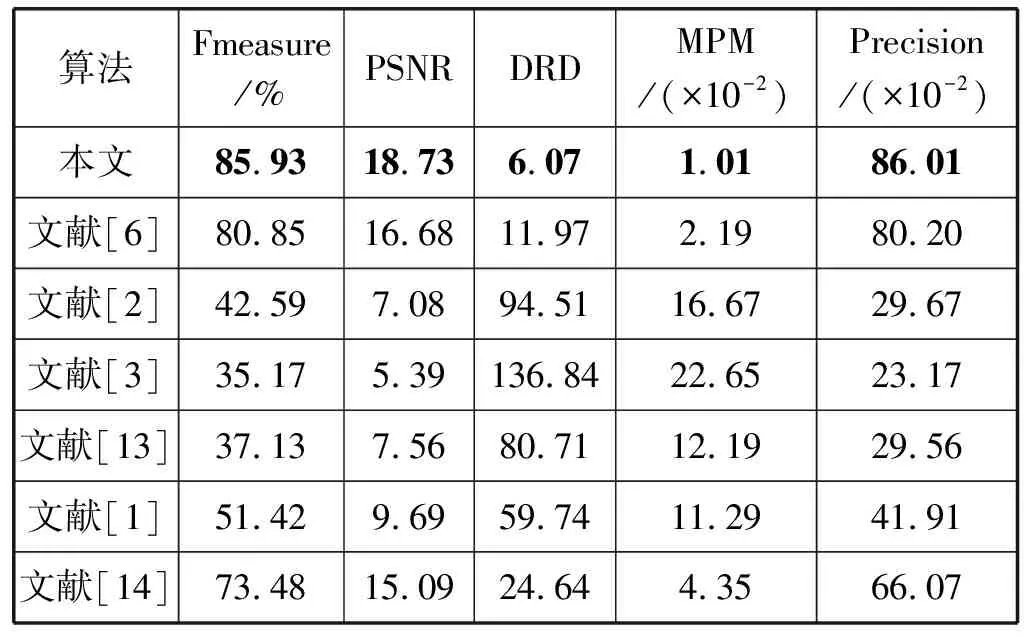
表3 各二值化算法在DIBCO2018的评估结果(平均值)
从表1、表2和表3的实验数据可以看出,本文算法的5种性能指标值都要好于其他二值化算法,说明本文算法结果与对应的基准图像相似度最高、失真度最小,整体性能优于文献[1-3,6,13-14]的算法,充分说明了本文算法的鲁棒性,表明本文算法可以处理多种退化类型的古籍图像。
3 结 语
本文针对古籍图像所存在的复杂背景,提出一种基于局部对比度和相位保持降噪的古籍图像二值化算法。算法首先根据归一化局部最大值最小值来构造局部对比度图像,同时对古籍图像进行相位保持降噪,将局部对比度图像与降噪图像相结合来识别文本笔划像素;然后通过局部窗口内所检测的文本笔划像素估计局部阈值来计算古籍背景修复模板,用图像修复算法和形态学闭操作估计古籍背景;最后用古籍背景增强古籍图像并计算最终二值化结果。本文算法能够解决复杂背景噪声的干扰问题,从而很好地抑制背景噪声,更有效地处理页面线条和有浸润墨迹的低对比度区域,达到精确分离古籍前景文本和背景的目的。
