基于BERT的智能问答系统
2022-02-19北方工业大学陈旻杰魏轩郑莹周世元
北方工业大学 陈旻杰 魏轩 郑莹 周世元
本文结合网络爬虫和深度学习模型研究智能问答技术。文中介绍了BERT的基本内容和特点、Finetuning BERT中的文本词汇生成过程,以及在深度学习模型中引入主题特征的方法和实现。
随着大数据时代的到来,每天都有数以亿计的信息存留于互联网,庞大的信息量让人们很难从中获取有价值的信息,如何快速筛选这些有价值的信息是智能问答系统的关键。本文中的答案选择模型采用基于预训练模型BERT微调的答案选择模型,通过分别采取全连接网络,DPCNN网络,BiLSTM网络以及调整不同输入层后,我们发现采用BiLSTM网络模型有较好的效果。在进行系统部署后,通过对文本选择的正确率和响应时间进行对比,均可获得理想的效果。
1 Fine-tuning BERT模型
BERT采用Transformer模型作为基本单元,并且也同时采用Transformer模型的编码器,此举让BERT[1]模型实现了真正意义上的上下文相关。在Attention is ALL You Need[2]一文中,论述在将一个或多个Transformers堆叠后,可以认为其成为了一个拥有多输入,多输出的黑盒,而BERT模型中则同样可以按照此方式理解为:采用特定格式后输入由多个Transformers组成的黑盒模型中训练后得到输出。
BERT模型是可以进行两种任务类型的多任务模型,一种是掩码语言模型任务,另一种是预测上下文模型。掩码语言模型任务是通过在预料中遮盖部分词语,然后使用类似上下文预测的方法预测被掩盖的词语;而上下文预测类型则是通过使用大量的语料来训练模型让其学习到:短语于句子之间的上下文和逻辑关系,然后自行预测句子间是否存在上下文关系,本文便是采用此种训练模型作为基础的预训练模型。后续的预训练模型选择方案则是由相关下游任务确定的。
本文采用的为预训练模型是chinese_L_12_H-768_A-12模型,由于此模型是几乎适用于所有任务的模型,所以BERT预训练模型需要使用下游任务的数据进行微调训练。微调时使用的数据通常的建模方式是对文本对进行独立编码,之后采用双向交叉注意力机制进行文本建模。而BERT由于其本身所使用的自注意机制可以对文本对的编码,在此过程中实际上已经实现了两个句子之间的双向交叉注意力的作用。答案选择任务的数据源为文本对数据,在微调过程中只需将此任务特定的输入输出形式送入BERT模型并采用端到端的方式微调模型中的所有参数。预处理模块通过对原始文本进行数据清洗后,将问题和答案转换为BERT模型的输入形式。模型的输入形式如下:BERT_Input(Sentence1,Se ntences2)=[CLS] Sentence1[SEP]
其中,[CLS]与[SEP]为BERT模型的特殊输入标志。[CLS]向量代表整个句子的句向量表示,用于分类任务,[SEP]向量代表句子中的词向量表示。
我们通过将训练数据送入语言模型中训练,从而让每个位置的矢量输出捕获句子中的语义信息。BERT模型可以根据词语在句子中的位置向量来捕获词语的深层信息。在答案选择任务上,模型微调方法如图1所示,模型输入如下所示:
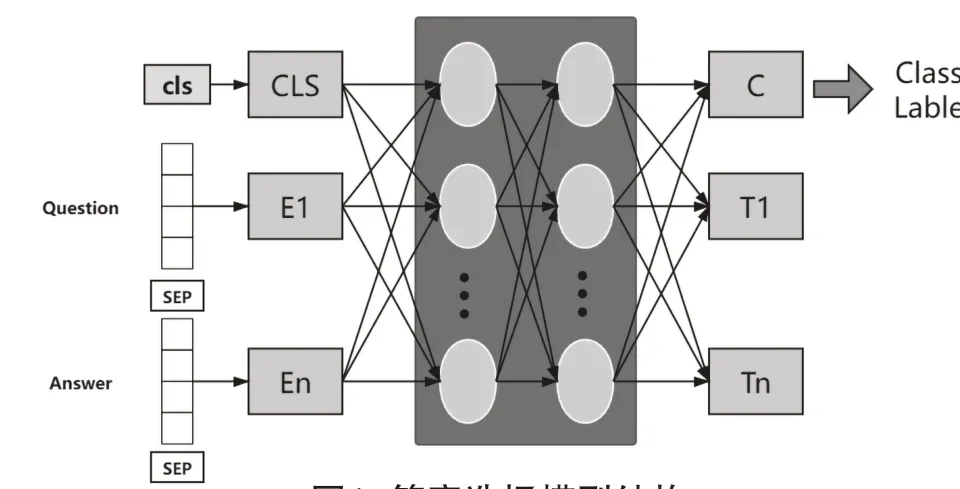
图1 答案选择模型结构Fig.1 Answer selection model structure
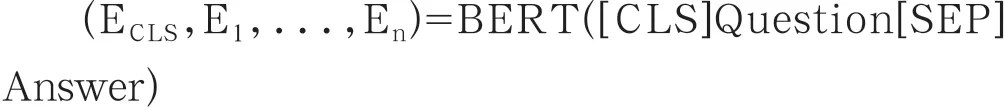
在基于Google公布的BERT代码中本文使用了其中进行分类型任务的下模型训练,其中针对部分参数进行微调修改如表1所示[3]:

表1 模型参数Tab.1 Model parameters
2 结合Fine-tuning BERT模型的智能问答系统
基于用户角度对功能进行需求分析:
(1)法律智能问答:系统提供的三种法律问答方面为:法律问题,法律案例,法律规章,其中需要程序能做到返回关联度最高的文本,以便用户查阅。
(2)法律测试:收录了相关法律普及问题,便于用户学习后测试,并返回用户选择的正确与否。
(3)法律资料库:用于与用户键入文本的匹配。
解决以上问题需要使用到的相关技术为:
(1)网络爬虫:用于收集数据集,并对数据进行初步的清理和整理。
(2)Fine-tuning BERT的预训练:将进行了数据清洗和整理之后的数据送入BERT中文预训练模型中进行训练。
(3)信息检索:使用ES搜索引擎,对大量数据录入搜索引擎中建立索引,等到用户键入相关问题之后进行初次答案筛选。
(4)BERT预测答案:将问题和初次筛选的答案送入BERT模型中进行上下文预测,并通过对候选答案评分进行从高到低的排序。
(5)BERT模型加载:由于在实际部署情况中用户需要反复使用BERT模型,所以此处本文此处选择放弃使用无法预加载的ckpt模型而采取可预加载的pb模型,来满足用户需求。
(6)问题预处理:将用户输入的问题句中的语气词,杂项词和停用词进行清理,使检索获得更好的结果。
基于以上核心问题和解决方案,本文设计了如图2所示的问答程序流程:
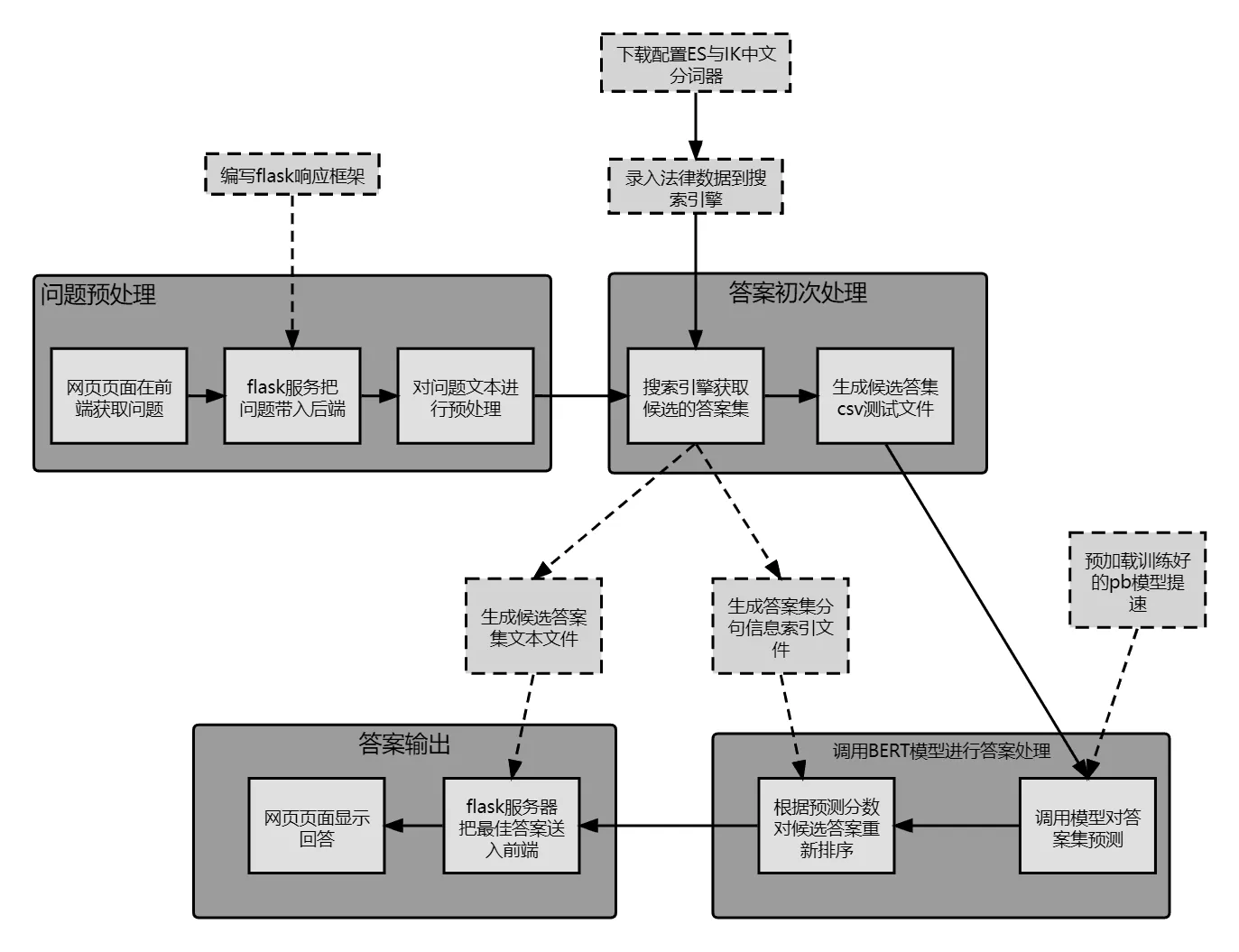
图2 问答功能程序流程Fig.2 Question-anwser program procedure
由于深度学习领域的训练十分依赖数据,所以对于数据量的解决方案我们使用网络爬虫的方案解决,而数据中的冗余或错误数据则需要我们后续的数据清洗步骤:
(1)查看获取的数据是否损坏。
(2)将特殊字符替换为常规字符,对于难以处理的特殊字符可以考虑删除。
(3)考虑到后期输入训练的格式,需要对文本进行文本格式的排版检查。
(4)基于CSV训练集文件中采取逗号或者制表符作为分割,需要对文本进行检查以免冲突造成错误。
(5)采取UTF-8的编码。
本文中模型的数据集来源于网络爬虫,在经过数据清理后按照训练集,验证集,测试集比例为6∶1∶1的情况分割,由于原始数据集中只有问题与答案是上下文的数据,每一条数据都智能制作正例,负例无法直接制作,所以我们需要通过余弦相似度计算不同问题之间的相似程度,对每个问题做一次计算然后把其他问题按照相似度由高到低的顺序排序,其中25%~75%区间内随机抽取一个问题,并将抽取到的问题对应的答案作为原问题的答案,以此制作负例。此外我们还需要将数据集中的长文本切割,由于数据集中存在个别样例中的答案文本能长达1000字符,所以需要将长文本切割为短文本。在保证切分后能保持原句语义的情况下,我们采取以下方案:
(1)将答案文本按照逗号或句号切分为短句集,将当前答案语句的内容置空。
(2)遍历短句集,遍历完成后进入五。
(3)将当前短句加入答案语句,如果发现加入后答案语句长度大于128,则短句不加入,跳转至四,否则跳转至二。
(4)将问题语句与当前答案语句和标签制作为CSV训练文件,将当前答案语句的内容置空,跳转至二。
(5)如果答案语句的长度小于16,则不处理并结束算法,若大于16,将问题语句与当前答案语句和标签制作为CSV训练文件并结束算法。
本文中的自动问答中的答案选择模型是基于Transformer预训练模型的答案选择模型,并且在尝试与BiLSTM网络结合,以及调整输入层尝试构造新的模型。针对于与训练模型对数据量的要求,本文采取了以下策略:
(1)预训练模型的微调策略:采用基于迁移学习的二次微调策略,首先采用大规模答案选择数据集进行一次微调,之后采用目标域数据二次微调,将预训练模型微调到目标域。
(2)基于信息检索的数据扩充策略:对于目标域训练数据问题,我们提出了利用外源知识库,为预训练模型提供更为丰富的语义信息。
通过以上步骤,我们可以得到我们需要的Finetuning BERT模型,此模型的应用过程如图3所示:
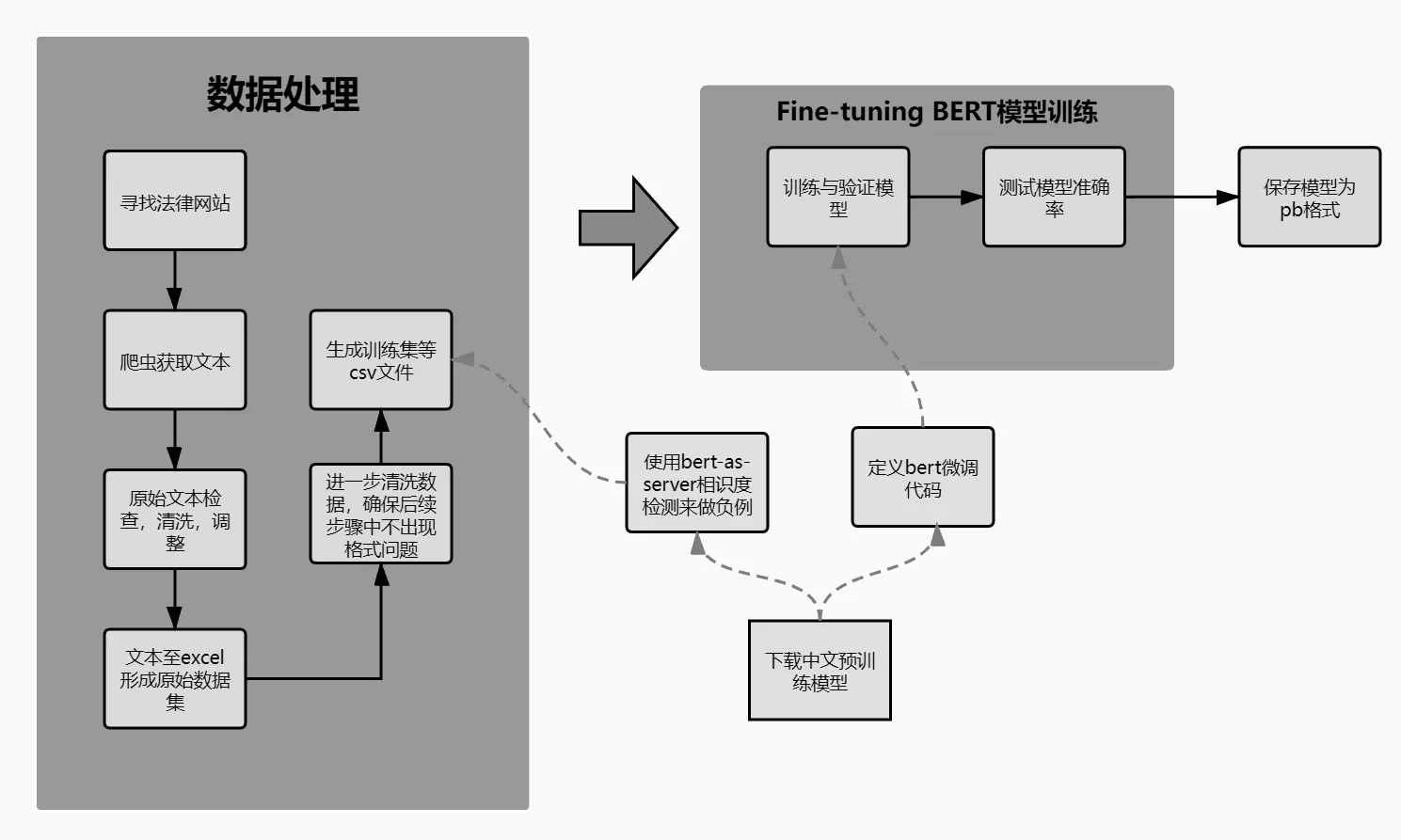
图3 深度学习训练过程Fig.3 Deep learning training procedure
数据量即训练时间如表2所示:
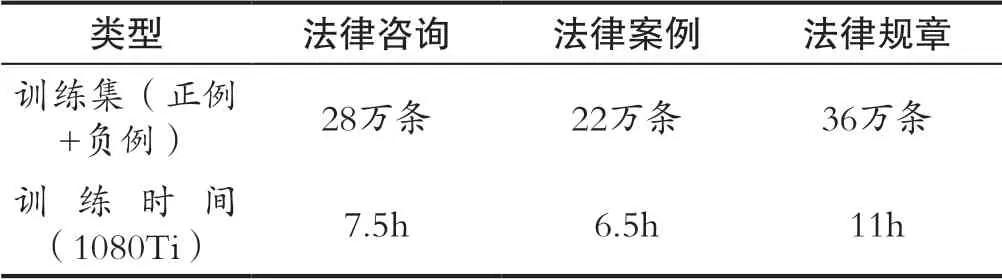
表2 训练集大小和训练时间Tab.2 Traing dataset size and training time spent
3 结语
目前此项目实现了一个较高准确率和速度的法律智能问答系统,相信在未来有可能会出现在BERT模型+信息检索技术的基础上再添加一些技术的方法来继续提高准确率或速度。由于自然语言处理技术正在快速发展,不可否认越来越多的BERT改进版模型也在不断提出,今后还会出现良好的自然语言处理方法,法律智能问答系统使用新技术后会在准确率和速度上继续提升,达到令用户基本满意的程度。并且基于此模型问答系统能在响应时间和准确率(通过比较模型对答案的范围值中相关度是否大于0.5)可以认为此系统符合使用习惯,准确率数据如表3所示,运行等待时间如表4所示:
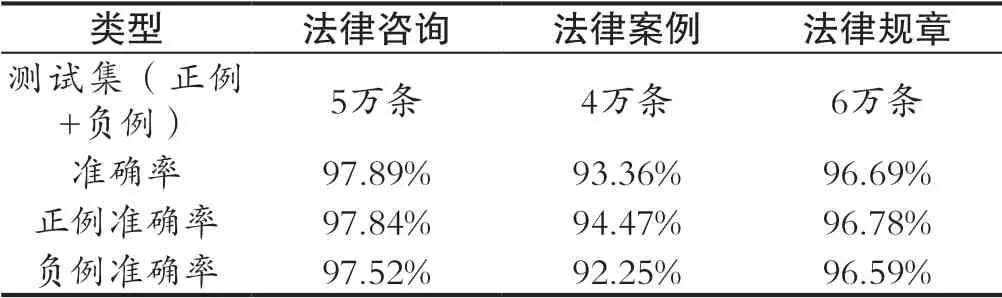
表3 模型准确率Tab.3 Model accuracy

表4 等待时间Tab.4 Time spent during process
计算公式如下:
准确率=(预测正确的正例数+预测正确的负例数)/(测试集中的总条数)
正例准确率=预测正确的正例数/测试集中的正例条数
负例准确率=预测正确的负例数/测试集中的负例条数
