基于深度学习的图像分类
2022-02-19北方工业大学信息学院余奕盈
北方工业大学信息学院 余奕盈
传统的图像分类过程复杂,准确率低,而卷积神经网络在图像分类领域表现出色。本文基于迁移学习,先对小样本数据集进行归一化数据增强等预处理,在ImageNet大数据集预训练后,微调网络权值,比较VGG16、Inception、Xception三种网络模型图像分类效果,得到了较好的准确率。
近年来,计算机视觉发展迅速,图像分类是计算机视觉领域核心问题之一,新型的基于深度学习和卷积神经网络的方法可以通过自动执行提取和自我学习特征[1],在图像分类方面取得了较大的突破。例如:吴[2]等人提出改进的Inception-V3网络,对花卉图像数据集分类准确率达92.85%;王[3]等人改进DenseNet、Xception和MobileNetV2三种模型,提高了灾难图像场景分类的精度;刘[4]等人预训练CNN、Resnet、DBN和SGAN网络,分析了不同网络对医学影像分类识别的准确率。
本文提出一种基于迁移学习的图像分类方法,在大数据集ImageNet预训练后,迁移参数优化调整VGG16、Inception-V3、Xception新模型,得到较好的分类效果。
1 相关工作
1.1 迁移学习
深度学习依赖大规模的数据集,若数据量太少,可能会出现过拟合现象导致图像分类准确率下降。针对训练集不足的情况,利用迁移学习的方法,可将预训练的模型权值应用到新模型,大大减少训练时间,降低消耗成本,实现了在小数据集上取得较好分类效果的目标。
迁移学习常采用从网络上抓取的1000个对象类别的近150万张照片的ImageNet数据集进行训练,迁移到其他神经网络中。Inception-V3、ResNet50、ResNet152V2、Xception等神经网络模型都使用了迁移学习技术,并获得了较好的分类准确性。迁移学习应用领域广泛,如李[5]等人基于迁移学习方法优化ResNet101网络,提升野生植物图像的识别精度;曹[6]等人迁移了GoogleNet中Inception-V3的预训练模型,解决了壁画数据集收集困难导致的训练数据有限等问题;陈[7]等人基于深度残差网络和迁移学习,结合数据增强和标签平滑策略对古印章文本进行识别,验证了迁移学习的有效性,许多学者在不同领域使用迁移学习方法达到了不错的效果。
1.2 数据增强
数据增强一方面指为解决数据集有限过拟合问题,在不改变数据集主要特征的前提下,常采取随机旋转、放大缩小、平移、裁剪等操作增加数据集的数量;另一方面指增加噪声提高模型的鲁棒性,提高神经网络模型识别率。
2 神经网络
2.1 VGG16
VGGNet16网络模型总共16层,如图1所示,包含13个卷积层和3个全连接层,前13个卷积层负责特征提取,而后3个全连接层负责分类。所有卷积层均使用3×3的卷积核,所有池化层使用2×2的池化核,步长大小为1,该模型通过增加网络深度来提升性能。
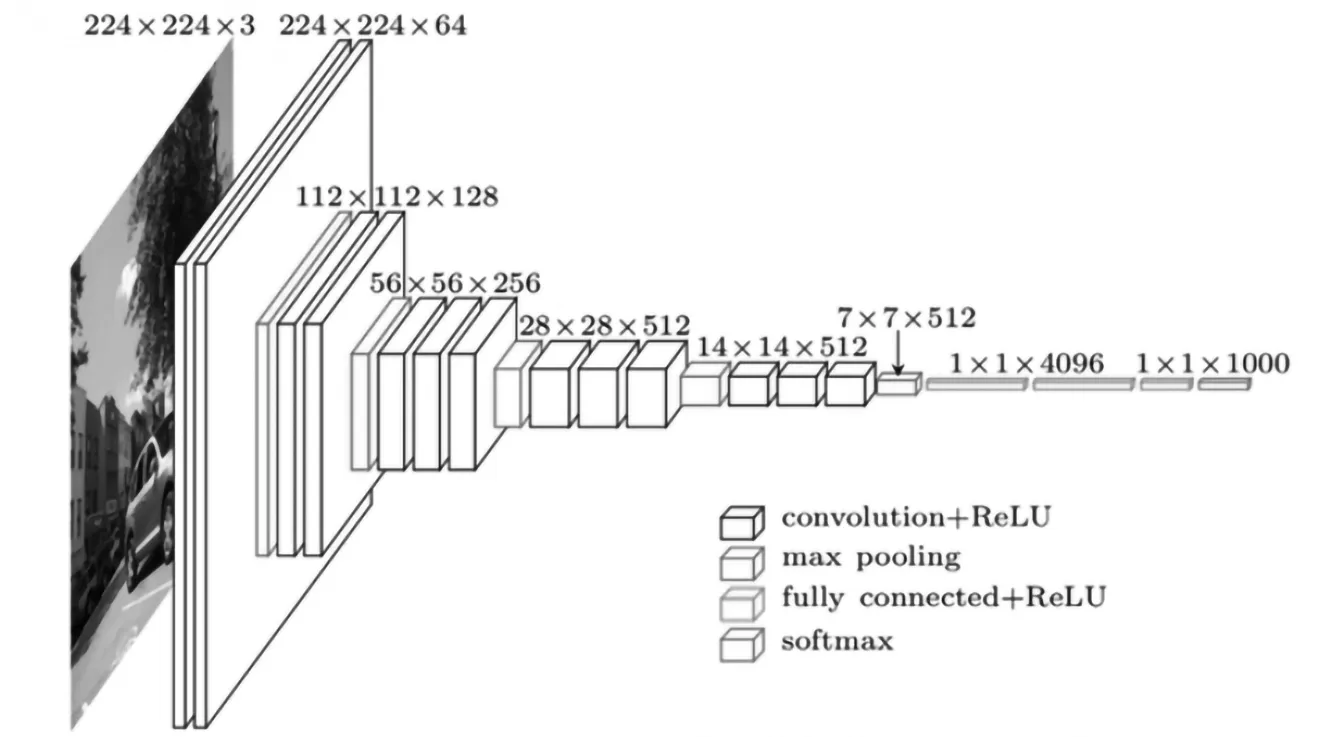
图1 VGG16Fig.1 VGG16
2.2 Inception-v3
Inception-V3主要是Keras开发的一个网络结构,如图2所示,网络模型共22层,该模型将大卷积核分解为小卷积核,对图像进行1×3和3×1非对称并行卷积处理,整合多个不同尺寸的卷积核,池化层,形成一个Inceptionmodule模块,不仅减少了网络参数的数量,同时还增加了非线性表达能力,减轻过拟合现象。

图2 Inception-V3Fig.2 Inception-V3
2.3 Xception
Xception模型是Inception-V3的一种改进模型,主要引入了深度可分离卷积和残差块。与普通深度可分离卷积操作相反,Xception先进行1×1的卷积操作,再进行3×3的卷积,该模型可以将卷积神经网络的征图中跨通道相关性和空间相关性的映射完全解耦。
3 实验设计与分析
3.1 实验准备
3.1.1 实验环境
本实验操作系统为Ubuntu16.04,选择Keras深度学习框架,Python版本为Python3.7,内存为8GB,处理器为主频1.60GHz的Intel Xeon E5-2603 v3。
3.1.2 数据集
本实验采用两个公共图像数据集,ETH80数据集和UIUC数据集。
ETH80数据集包含8个类别:苹果、小汽车、牛、杯子、狗、马、梨和西红柿,如图3所示,每个类别10个对象,每个对象不同视角下的41张图像构成一个集合,总计80个集合,3280张图像。UIUC数据集包含8种运动类别:羽毛球、室外滚球、槌球、马球、攀岩、划船、航海和滑雪,如图4所示,共1579张图像。在实验中,两数据集均随机取一半图像作为训练集,一半作为测试集。

图3 ETH80数据集Fig.3 ETH80 dataset

图4 UIUC数据集Fig.4 UIUC dataset
3.1.3 参数设置
在实验中,参数的设置尤为重要。
Epoch:一个Epoch指代所有的数据送入网络中完成一次前向计算及反向传播的过程。
batch_size:每次训练样本的数量,数量太大增加内存,数量太小影响训练时间,经过多次测试,本实验设置为32,在时间消耗和内存消耗中找最佳平衡点。
LearningRate:深度学习网络的重要参数,其决定着训练样本的识别精度,对模型的性能也有一定程度的影响,本实验将学习率设定为0.001。
3.2 实验过程
3.2.1 归一化处理
在UIUC数据集中,图像尺寸从845×1077到1808×496不等,ETH80数据集图像尺寸为256×256,而深度学习算法需要标准化的图片输入,本实验中VGG16网络模型需224×224输入,Xception网络模型、Inception-V3网络模型需299×299输入,在处理时将图像缩放、裁剪为同尺寸的图片,进行归一化处理。
3.2.2 数据增强
因训练数据集较小,可能会产生严重的过拟合现象,造成模型的分类性能下降,实验中需要通过对小样本图像按一定比例旋转、平移、缩放、调整图像亮度等方式进行数据增强,有效避免过拟合的风险,增强模型泛化能力。
3.2.3 迁移学习
本实验分别在VGG16、Inception-V3和Xception网络模型上进行迁移学习,节省大量时间。VGG16、Inception-V3和Xception网络模型在大型数据集ImageNet上充分训练后,获得预训练模型,得到预训练模型的初始权重,后将参数迁移到新的模型微调即可进行测试数据集的分类。
(1)预训练:实验时,首先载入在ImageNet数据集上训练而成的VGG16、Inception-V3和Xception预训练模型,保留模型权重。
(2)调整参数,训练模型:为了使模型更好地适应目标域,需要对这三个模型进行适当微调。针对VGG16、Inception-V3和Xception对三个网络模型,冻结低层参数,改变最后全连接层神经元个数,调整权值重新训练新网络。
(3)测试模型:使用相同测试集对训练好的三个网络模型进行测试,输出识别内容,比较分类效果。
3.3 实验结果
分类结果如表1,表2所示。

表1 图像数据集1分类结果Tab.1 Classification results of image dataset 1
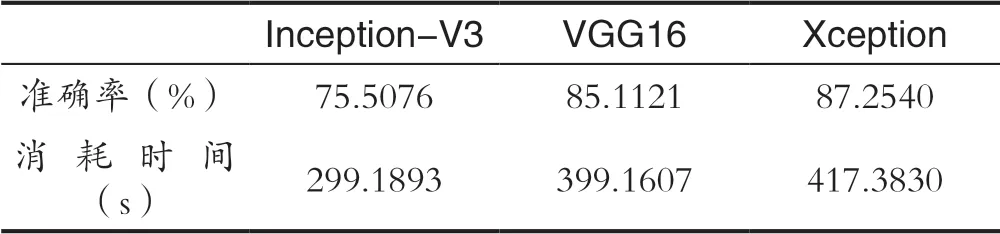
表2 图像数据集2分类结果Tab.2 Classification results of image dataset 2
4 结语
本实验基于迁移学习,对比了图像分类应用在InceptionV3、VGG16、Xception网络下的性能。结果显示,在相同的数据集下,Xception、VGG16的分类结果略好于InceptionV3,在大数据集上训练的模型迁移到小数据集,大大减少了时间消耗,且有较好的识别效果。
