基于稀疏卷积神经网络的车载激光雷达点云语义分割方法*
2022-02-18夏祥腾王大方张京明
夏祥腾,王大方,曹 江,赵 刚,张京明
(哈尔滨工业大学(威海)汽车工程学院,威海 264200)
前言
语义分割是无人驾驶汽车中的关键算法之一,对车载激光雷达扫描获取的3D 点云数据进行语义分割,不仅可以保证行车安全,还可以使无人驾驶汽车对周围环境进行进一步的理解,使其更加智能。
由于卷积神经网络(convolutional neural network,CNN)的应用,对于2D 图像中的许多问题有了突破性的进展,例如图片分类、图片语义分割和目标检测等问题。这些突破性的进展使得计算机对2D世界的理解有了质的飞跃。但是,对于3D点云数据的处理不能简单地将运用在2D 图像中的算法迁移过来,这不仅仅因为维度的提升带来了更巨大的计算量和内存消耗,还带来了点云数据的无序性、密度不一致性、非结构性和信息不完整性等问题。针对这些问题,3D 点云语义分割算法主要可以分为4 类:基于投影的算法、基于体素化的算法、基于点的算法和结合多种方法的算法。
早期学者们借鉴2D 图像处理的方法,想办法把3D 点云数据转化为2D 数据,进而使用2D 图像处理中较为成熟的CNN、全连接神经网络(FCN)算法,于是,基于投影方法应运而生。MVCNN获取三维点云形状在不同视角下的二维图像,对每个视图进行卷积处理再通过池化层和全连接层将每个视角得到的特征进行聚合得到最终的语义分割结果。SqueezeSeg结合激光雷达扫描特点,利用球面投影将3D 点云数据转换为2D 数据,结合CNN 中的轻量化模型SqueezeNet模型进行语义分割。SqueezeSegV2在SqueezeSeg 的基础上,利用上下文聚合模块增强了该模型的鲁棒性,提高了语义分割的准确率。SqueezeSegV3提出了空间自适应卷积模块根据输入投影图像位置不同使用大小不同的卷积核。SalsaNext提出了像素混合层(pixel-shuffle layer)用来上采样,并使用了更适合语义分割的Lovasz-Softmax 损失函数,得到了目前基于投影方法的最好分割效果。无论采用哪种投影方法,投影过程中都会产生信息损失,但因为2D 语义分割技术较为成熟,这类方法也取得了不错的效果。
为了将无序点云转化为结构化的数据,学者们将原始点云数据进行体素化,即将点云数据转化为立体结构,然后使用3D 卷积进行处理。3D U-Net首次利用3D 卷积神经网络构造了运用于点云语义分割的编码器结构。使用“1”代表非空的体素网格,“0”代表空白的体素网格。VVNet使用径向基函数(radial basis functions,RBF)代替这种布尔表示以获得连续的表示,使用基于内核的内插变分自编码器(kernel-based interpolated variational autoencoder,VAE)来编码每个体素内的局部几何信息,将它们映射到一个隐空间中。基于体素化的方法可以有效结合领域信息,但三维点云相比图像多出一维,会造成过多的内存消耗和计算开销。为解决这一问题,子流形稀疏网络提出了稀疏卷积神经网络的数据保存形式和具体运算形式。MinkowskiNet利用稀疏卷积神经网络,构造了加上时空维度的4D 卷积。Cylinder3D根据激光雷达扫描特性,利用柱坐标进行体素化,并使用不对称的卷积核,有效地解决了点云数据密度不一致的问题。
为了降低体素化或投影过程中的计算复杂度,有些研究者开始从三维数据着手,直接设计网络提取原始点云数据中的特征信息。PointNet使用多层感知机(multilayer perceptron,MLP)对每个点进行特征提取,并利用最大池化函数直接提取出全局信息,解决了点云的输入无序性问题。PointNet++对输入点进行最远点采样,再使用KNN 算法寻找周围点信息,对每个中心点和其邻近点进行PointNet 操作。KPConv通过寻找点核构造类似于卷积神经网络的点核卷积Kernel Point Convolution,并且构造了刚性和可变两种核。RandLA-Net针对在大规模点云中使用基于点的算法在采样时过于消耗时间这一问题,使用随机采样代替广泛运用的最远点采样,并构造LocSE 模块解决随机采样中信息随机丢失的问题,使点云语义分割时间大大减少。
上述3 种算法各有利弊,因此有学者结合几种算法对点云进行语义分割。PVCNN结合基于体素化和基于点的算法,使用基于点的算法减少体素化时的信息损失,使得可以取较小的体素化分辨率。KPRNet将球面投影进行语义分割得到的点再利用KPConv进一步分割,得到了比上述两种算法更好的分割效果。
本文中利用稀疏卷积神经网络,不仅保留了体素化便于结合领域点特征的优点,还一定程度上解决了3D卷积神经网络内存时间开销过大的问题。相对于投影的方法和传统神经网络的方法,利用稀疏卷积神经网络更好地保留了点云的空间特征,并且无需复杂的预处理流程,提高了分割效果且方便高效。
1 稀疏卷积神经网络
通过对点云进行体素化处理,使无序的点云数据有了类似于图片规则的结构(图片的数据结构为×矩阵,体素化点云的数据结构为××的张量)。因此,可以使用三维卷积神经网络处理点云数据,但尽管3D 数据只比2D 数据多了一维,内存的消耗和运算速度却是指数级增长。因此受到计算机硬件的限制,将3D 卷积神经网络应用在大规模点云场景中十分困难。针对大规模点云体素化数据的稀疏性,3D 稀疏卷积神经网络应运而生。稀疏卷积神经网络本质上还是卷积神经网络,但其对输入输出数据的保存形式和具体运算过程和普通的卷积神经网络有很大的不同。
1.1 输入输出数据保存形式
普通卷积神经网络数据保存形式为××,为小批量,为特征通道数,对于点云来说,为××。由于稀疏性,这些××所对应的特征相当大一部分都为空点,但依然占用内存。在稀疏卷积神经网络中,点云体素化数据由一个矩阵和一个哈希表组成。的大小为×,为点云体素化数据中不为空的个数。哈希表的键为点云体素化数据中不为空的点的坐标,值为这个坐标对应于中的那一行。在大规模点云体素化数据中,≪××,因此可以节省大量内存。
1.2 稀疏卷积具体运算过程
在稀疏卷积中,当卷积核的中心对应的点为非空时,才进行卷积运算,这样便保证了进行步长为1的稀疏卷积运算时不会使非空白点数增加。2D 稀疏卷积如图1所示,其具体运算过程如下。

图1 2D稀疏卷积示例
(1)建立输出哈希表和规则书,规则书为输出点和输入点的对应关系。对每个输出点,检测其是否为非空点,若其为非空点,在输出哈希表中建立一个键-值对,根据卷积核大小找出其对应的输入点,并在规则书中写入对应关系(输出Hash 表的值,输入Hash表的值)。若卷积核大小为,则一个输出点最多对应个输入点。
(2)建立输出矩阵。找出输出点在规则书中的对应关系,根据对应关系中输入Hash 表的值,在输入矩阵找出该输入点的特征向量,设某输出点共对应个输入点,输入特征数量为,输出特征数量为′,则该输出点的特征向量为

式中:为输出点特征向量,大小为1×′;X为第个输入点的特征向量,大小为1×;为卷积核矩阵(并不是卷积核),大小为×′。
2 网络模型及算法设计
本文中首先将原始点云数据进行体素化,然后利用稀疏卷积神经网络构造了用于车载激光雷达点云的语义分割模型。针对体素化时多点落入同一网格造成的信息损失问题,结合了多层感知机对原始点云直接处理。并利用通道和空间注意力机制,构造了3D-CA 模块和3D-SA 模块,提升语义分割效果。
2.1 体素化
体素化的主要目的是将无序化的点云结构转化为有序的数据结构,方便利用稀疏卷积神经网络对其处理。体素化的具体形式是将原始点云数据{(P,F)}投影到立方网格结构{V}中,其中P代表第个点的原始坐标,P=(x,y,z),F为第个点的特征向量,则有
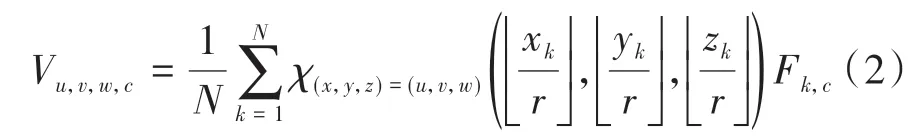


相对于体素化,还需要解体素化过程。解体素化即为将网格化的(,,,)数据转化为原始点云数据{(P,F)}。解体素化最简单实现方式为最近邻映射,即直接将某网格对应的特征分配给所有落在该网格中的点。但这种方法会使落入同一网格中的点的特征相同,为此,本文中使用三线性插值法实现解体素化。
2.2 网络模型
整体网络模型如图2 所示。图中蓝色虚线通道为稀疏卷积部分,也是网络模型的主干,以编码器-解码器结构为框架,-为编码过程,该网络结构通过稀疏卷积提取点云特征,通过步长为2 的卷积层代替池化层进行下采样。-为解码过程,采用步长为2的反卷积层进行上采样。
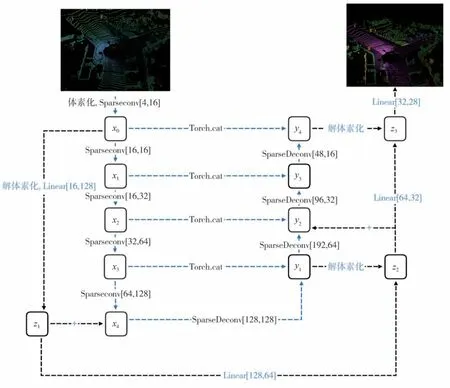
图2 整体网络模型
Sparseconv[,]代表3 个网络基本层串联,每个网络基本层代表3 层稀疏卷积神经网络,前两个网络基本层中步长全为1,最后一个基本层中最后一层步长为2 进行下采样。SparseDeconv[,]也代表3个网络基本层串联,每个网络基本层代表3层稀疏卷积神经网络,前两个网络基本层中步长全为1,不同的是最后一个基本层中最后一层采用步长为2反卷积进行下采样。
网络基本层如图3所示,每个网络基本层含有3个卷积层、1 个3D-CA 模块和1 个3D-SA 模块。每个卷积层后采用ReLU 函数进行激活,并使用BN 层进行批量归一化。代表第一层输入特征数量,代表最后一层输出特征数量。网络基本层中还使用了MoblieNetV2中提出反转跳连接结构,即将输入与该基本层的输出相连,可以有效地抑制深度学习中梯度消失现象。3D-CA 模块和3D-SA 模块将在下文介绍。

图3 网络基本层
黑色虚线通道为逐点对点云处理过程,为网络模型的辅助支路,其中Linear[,]为多层感知机,其输入特征层数为,输出特征层数为,每个Linear[,]中含有3 个全连接层,每个全连接层后使用ReLU 函数进行激活。通过直接对原始点云数据直接提取特征,可以弥补因3D稀疏卷积因体素化时网格边长过大造成的信息损失。这一通路在因计算机资源有限不得不增加体素化立方网格边长时可以起到更大的作用。
2.3 3D-CA、3D-SA
CBAM使用两种注意力机制在2D 计算机视觉中的图像分类任务中取得了不错的准确率增益。本文中将这两种注意力机制推广到3D 计算机视觉中,构造了3D-CA(3D-channel attention,三维通道注意力)模块和3D-SA(3D-spatial attention,三维空间注意力)模块,可以使网络将注意力放在发挥更大作用的特征通道和空间中,从而提升点云语义分割效果。3D-CA 模块如图4所示,其具体做法为:首先将个特征通道的输入张量逐通道取全局平均,得到大小为1×的向量;然后将这个向量经过多层感知机(MLP)和Softmax 函数自动提取权重,得到权重向量;最后将输入张量和权重向量按照广播机制逐元素相乘得到输出。3D-SA 模块如图5 所示,其具体做法为:将大小为×的稀疏矩阵通过全局平均池化和最大池化得到两个大小为× 1的向量,将这两个向量并联得到大小为× 2的矩阵;将这个矩阵分别经过MLP和Softmax函数自动提取权重,得到权重向量;最后将输入张量和权重向量按照广播机制逐元素相乘得到输出。

图4 3D-CA模块

图5 3D-SA模块
3 实验及结果分析
针对大规模道路点云场景,选取点云数据集SemanticKITTI和SemanticPOSS作为本文的实验对象。SemanticKITTI 包含了德国卡尔斯鲁厄附近的市内交通、居民区、高速公路场景和乡村道路场景,是现在最大的汽车激光雷达点云数据集。该数据集由22 个点云序列组成,其中00-10 序列作为训练集,一共包含23 201 帧3D 点云场景;11-21 序列作为测试集,一共包含20 351帧3D 点云场景。其中训练集中每点都有自己的标签,人为进行了语义标注。SemanticPOSS 是北京大学最新发布的数据集,包含了北京大学的主要道路场景,含有大量移动的学生和车辆。该数据集由6 个点云序列组成,一共包含2 988 帧点云场景,数据集中行人、车辆的比重比SemanticKITTI数据集高了10倍,更加适合用于无人驾驶技术的语义分割技术研究。
实验采用深度学习框架为Pytorch1.7,CUDA 版本为11.1,处理器为AMD Ryzen 9 3950X,显卡为Nvidia GTX 3090。实验中使用AdamW优化器,AdamW 在Adam 的基础上带有权重衰减而不是L2正则化。
3.1 实验评价指标
点云语义分割算法需要有一定的衡量标准,最简单的衡量标准便是分割的逐点平均准确率,但该标准在全部语义标注类别中不同的类别点数差距很大,不能够合理地评价两种算法的优劣。而在大规模点云场景中,各语义标注类别点数差距很大。本文中使用MIOU(mean intersection over union)来评价分割精度:

式中P代表属于类但被预测为类的像素数量。由式(4)可以看出,MIOU 可以通俗地理解为一个点云场景中对类物种分割正确的平均准确率而不是逐像素的平均准确率。因为MIOU 容易理解且具有准确的表示形式是现在最常用的度量标准之一。
3.2 稀疏卷积优势验证
为验证稀疏卷积的优势,对SemanticKITTI 中大小为100 m×100 m×10 m 的点云场景,体素化时使用不同大小的立方网格边长,记录体素化后点云场景中的非空点数。数据如表1所示。

表1 不同网格边长时的参数对比
从表1 可以看出,对大规模点云进行体素化,非空白点数远小于网格数,当网格边长为0.05 m 时,网格数是非空点数的8 922倍,验证了稀疏卷积节省内存的优势。但随着网格边长的减少,MIOU先增加再减少。分析可知,网格边长越大,体素化后得到的体素化点云越“模糊”,点云场景中物体的特征越不明显,并且会导致代表不同种物体的点落入一个网格中,造成信息损失,影响分割结果。因此在一定范围内,MIOU 随着网格的边长减小而增加。但是,当网格边长继续减小时,尽管非空点数增加,但其所占总网格比例大幅度减少,MIOU便随之减少。
3.3 逐点处理分支效果验证
文中算法网络模型主干是由稀疏卷积构造的自编码器。但是由表1可以看出,选取网格边长为0.05 m,继续减小网格边长,非空点数也会继续增加。说明网格边长为0.05 m时,依然有大量的点落在了同一个网格中。这必然会导致一部分信息损失,因此通过添加逐点处理分支来弥补这部分的信息损失。为了验证这一分支的具体效果,在SemanticKITTI数据集上取立方网格边长为0.05和0.08 m时,分别去除这一分支和仅利用这一分支进行实验,实验数据如表2所示。

表2 逐点处理分支效果验证
由表2 可以看出,如果仅使用逐点处理分支,得到的分割效果非常不理想,但在PointNet中仅使用这种方法在小规模的点云数据集上进行分类任务可以达到不错的精度,这也说明车载激光雷达点云处理任务中需要充分考虑周围点的信息。通过表2 还可以看出,加入逐点处理分支可以明显提高分割效果,说明了其可以稍微弥补因体素化而造成的信息损失。
3.4 3D-CA、3D-SA模块效果验证
在图2 的整体网络构架中使用图3 的网络基本层仅去掉3D-CA 模块、仅去掉3D-SA 模块和同时去掉两模块进行实验,得到的结果如表3所示。从表3中可以看出,相对于网络基本层,3D-CA 模块能够将MIOU 提升0.4%,3D-SA 模块能够将MIOU 提升0.7%,同时使用3D-CA 模块和3D-SA 模块能够将MIOU提升1.2%。

表3 3D-CA、3D-SA模块效果验证
3.5 最终结果分析
3.5.1 SemanticPOSS数据集
目前在SemanticPOSS数据集上进行实验的算法较少,文中在总12 类语义标注物体中选取公路上最常见的行人、汽车和骑手3 类,将这3 类的IOU 和MIOU与其他算法对比,得到的结果如表4所示。

表4 不同算法在SemanticPOSS上的分割结果
通过表4 可以看出,文中算法对于行人和汽车都有不错的分割精度,但对于骑手这一类别,分割效果较差。为了进一步分析,将分割后的结果进行可视化,得到的结果如图6 和图7 所示。对比图6 中第3帧和第4帧结果,同一个体在不同时间序列上会被预测成不同的语义类别,在骑手与行人这种难以分辨的语义类别中更为明显。而在第4 帧中,文中方法预测结果不仅相当准确,还预测出了数据集作者并未标注的行人,这也表明了算法的相对准确性。由图7 可以看出,在路口处的复杂路况下文中算法可以很好地分割行人、车辆、骑手和停靠在路边的自行车。但对距离较远处较小的行人容易识别错误,以及远处的骑手易和行人造成混淆。图6 和图7 表明了文中算法的可靠性,但也显现出了该算法不能利用前后的时间序列进行分割,以及对远处个体预测准确性较差的问题。

图6 SemanticPOSS数据集00序列第3帧和第4帧

图7 SemanticPOSS数据集02序列第1帧
3.5.2 SemanticKITTI数据集
通过文中的方法,在SemanticKITTI 数据集上将其中19 类语义标注物体的平均交并比达到62.7%,超过了目前最好的基于点的方法(KPConv,58.8%)和基于投影的方法(SalsaNext,59.5%),文中算法和其他算法MIOU 以及各语义标注物体IOU 对比结果如表5所示。通过表5可以看出,算法对于驾驶过程中最常见的汽车、建筑分割精准,但对于相似的摩托车与自行车和摩托车骑手与自行车骑手很难分辨。

表5 不同算法在SemanticKITTI数据集上的语义分割结果
4 结论
本文中使用稀疏卷积神经网络构造自编码器对车载激光雷达扫描得到的点云进行语义分割,在自编码器的网络基本层中设计3D-CA 模块和3D-SA模块提高语义分割效果;并结合逐点处理分支弥补因体素化时多点落入同一网格造成的信息损失。本文算法在两个大型点云数据集SemanticKITTI 和SemanticPOSS 上进行了实验,结果表明,在SemanticPOSS 上得到的分割效果超过了其他几种目前最优的针对点云的语义分割技术,证明了稀疏卷积在点云处理中的高效性。
稀疏卷积神经网络可以充分利用空间信息,在特定的时刻可以得到准确的分割效果。但其无法利用时间序列进行分割,即无法结合前后两帧的信息,即在汽车行驶过程中很难利用先验的已知信息对周围环境进行感知。如何利用历史扫描信息提高语义分割效果是未来的研究方向之一。在大规模现实场景中,将静止的交通工具和移动的交通工具进行区分可以进一步保证行驶安全,而目前的算法对静止和移动的语义类别很难识别,这也是未来点云处理中的研究热点之一。
