基于无监督的热点话题发现研究
2022-02-17闻彬,熊飞,陈薇
闻彬,熊飞,陈薇






摘要:高校“百度贴吧”经常会有用户发表一些讨论帖,这些信息对于学校来说是非常有用的。但是未经处理的信息无法实时给当局者提供帮助。因此,文章提出一种利用自然语言处理方法获取“贴吧”信息,并实时发现热点话题的方法。本文首先获取网络文本信息,对文本进行预处理,包括分词、去除停用词,再计算文本的TF-IDF值,最后利用无监督学习方法(K-means)对文本进行聚类,从而获取热点话题。从实验结果中可以看出,本方法可以有效地发现“贴吧”中的热点话题。
关键词:自然语言处理;热点话题;机器学习;K-means
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)35-0016-03
1 概述
众所周知,互联网已经成为当前人们日常获取信息的主要途径。基于此,人们也乐衷于在互联网上发表自己的看法和观点。但是绝大部分信息可能是没有太大意义的,需要过滤掉不太重要的信息,并从中挖掘出有意义的信息。热点话题发现就是在此背景下应运而生,并引起了广泛的关注。
热点话题发现的目的是在海量的数据信息中,找到引起大家共鸣、为大家津津乐道的信息,为当局或者管理者提供实时的情报,也为舆情监控和观点抽取等提供支持。
2 研究现状
话题发现(Topic Detection)[1]是指分析大量语料,在无需人工监督的情况发现文本中的热点话题。话题发现常用的方法主要有三类:基于聚类的、基于主题模型和基于词共现的方法。Xie[2]等人针对微博信息,首先提出用句子嵌入法来表示微博文本,然后再提取微博子主题,最后利用K-means[3]聚类算法对实验结果进行验证,实验结果显示,该算法取得较好的效果。Mathioudakis[4]等人建立了TwitterMonitor系统,该系统可以通过实时监测微博文本信息,并实时发现热点话题,最后创建图表来对热点话题进行显示。
目前的话题发现学习方式主要有监督学习和无监督学习。
2.1 有监督学习
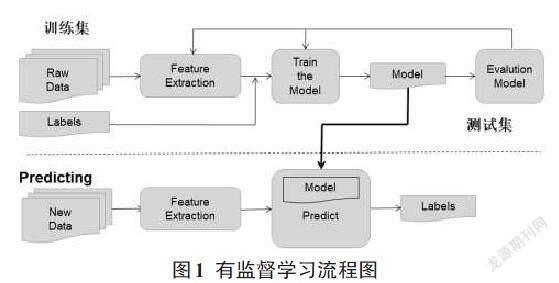
在监督学习中,通过给出训练数据集,并在数据集中标注类别,训练机器并让其能够识别出是哪个类别,图1为有监督学习流程图。
有监督学习原理如图2所示。
图2中,分别对狗类和猫类进行了正确分类以及标注,然后利用机器学习算法进行训练,获取到模型的相应参数,再根据训练好的模型,对新的样本进行判定,如图3所示,以此获取新样本的属性。
监督学习算法根据任务的不同,又分为了回归分析(Regression)和统计分类(Classification)两大类。回归和分类的算法区别在于输出变量的类型,定量输出称为回归,或者说是连续变量预测;定性输出称为分类,也称为离散变量预测。回归不是本文的重点,因此在这里不再讲述,本文重点讲述分类算法。以上介绍的是利用算法对模型训练后,能够将“狗”和“猫”进行分类。常用的分类算法有以下几种:K-近邻算法(K-Nearest Neighbors,KNN)、决策树(Decision Trees)、神经网络分类(Neural Network)、支持向量机(Support Vector Machine, SVM)等。
2.2无监督学习
无监督学习是指在缺乏足够的先验知识时,让计算机帮助解决这些问题,或者至少提供一部分帮助,因此无监督学习使用的训练集是没有任何标注的,目的是发现数据集本身的聚集性。如图4所示,训练集本身没有任何标注,通过机器学习训练之后,聚类为2大类,同时也无法判定类别。
常见的无监督学习算法分为聚类和降维两大类,热点发现使用的为聚类算法,本文仅讨论聚类算法。常见的聚类算法有:K-均值(K-means)聚类、层次聚类(Hierarchical Clustering)、基于密度聚類(Mean Shift)等。聚类算法的目的是将相似的样本聚在一起,聚类只需要考虑样本之间的相似度,而不需要考虑类别数目。以K-means为例,该算法用来对n维空间内的样本根据欧式距离远近程度进行聚类。
3 方法
本文以学校的百度贴吧为讨论对象,从对应的学校的“贴吧”中获取该学校的讨论文本。然后对文本进行处理,从而获得该学校的热点话题。
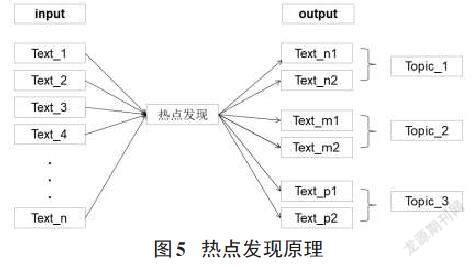
从贴吧中获取到相应文章,分别为Text1,Text2,Text3,..., Textn,热点发现原理如图2所示。
3.1 分词
对文本进行分词,使用Jieba[5]进行分词。
Jieba的常用三种模式:
1)精确模式,尽可能将句子精确切分;
2)全模式,快速地将句子中的可能成词的词语都切分出来,不足之处在于无法解决汉语词语的歧义问题;
3)搜索引擎模式,在第一种模式的基础上,对句子中出现的长词语再次精确切分,目的是提高召回率,一般适用于搜索引擎中的分词工作。
本文采用第一种方式精确模式对文本进行处理。
3.2 去除停用词
停用词是指那些对句子没有多大意义的词语。在不牺牲句子含义的情况下,可以忽略。因此,需要将这些停用词进行删除,经过整理,共获得1598个停用词,在分词后的文本中删除停用词。
3.3计算文本的TF-IDF值
首先考虑计算文本之间的相似度。本文使用TF-IDF对文本进行向量化。下面介绍一下TF-IDF的原理。
[TF-IDF=TF×IDF] (1)
其中:
[TF=某个词语在文章中的出现次数文章的总词数] (2)
[IDF=log(语料库的文档总数包含该词的文档数+1)] (3)
TF-IDF用來评估某个词语对于某篇文档或者整个语料库中其中一份文档的重要性。例如,当一个词语在一篇文档中出现频率很高,同时在其他文档中出现频率很低,甚至没有出现,那就认为该词语对于该词语所在的文档具有很强的代表性,适用于对文本进行处理。其中词频(Term Frequency,TF)就是指一个给定的词语在该文本中出现的频率。这个数字是对词数的归一化处理,以防止它偏向长的文本,从而忽略短文本的重要性。逆向文件频率(Inverse Document Frequency,IDF)是一个词语普遍重要性的度量。
3.4 向量空间模型
向量空间模型首先是假设文本内的词语之间是不相关的,再利用向量将文本表示成向量模式,充分利用权重信息计算文档之间存在的相关性[6]。
计算出TF-IDF值之后,为防止出现维度过高问题,采用Compressed Sparse Row Format(CSR)压缩稀疏行矩阵进行存储。
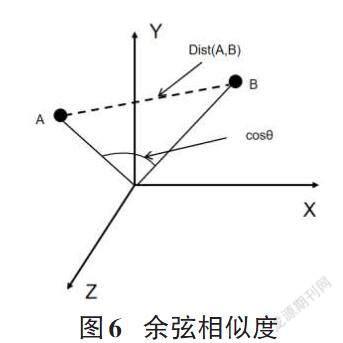
利用余弦相似度计算文本之间的距离,用向量空间中两个向量的余弦值作为衡量两个个体差异大小,如图6所示。
其中,A、B分别为2个文本向量,Dist(A,B)为AB间的距离,cosθ为相似度,cosθ值越接近1,就表示夹角越接近0度,也就是两个向量越相似,从而判定文本之间的相似程度similarity。
[similarity=cosθ=A·BAB=i=1nAi×Bii=1nAi2×i=1nBi2] (4)
3.5 利用K-means聚类算法进行聚类
(1) 随机生成K个聚类中心;
(2) 计算每个样本与每个聚类中心的距离(余弦相似度),离哪个聚类中心近,就划分到哪个聚类中心所属的集合当中;
(3) 重新计算每个集合的聚类中心;
(4) 重复2、3步,直到收敛(聚类中心偏移很小,或者计算聚类中心次数超过阈值);
(5) 返回所有聚类标签。
从“百度贴吧”下载湖北轻工职业技术学院、武汉理工大学、华中师范大学下载各1000篇文本,利用本文的方法对文本进行处理,处理完后,发现热点话题如表1所示。
4 结束语
热点话题发现有助于快速获取网络中的当前热点,能够及时为当局提供快速响应的依据。从实验中可以看出,本文提供的方法可以有效且及时发现网络中的热点话题。不仅在贴吧平台可以使用,在有数据来源的情况下,同样可以作为社会舆论的监测工具。但是本实验中数据量有限,实验结果可能与实际情况存在稍许偏差,后期笔者将重点放在增加实验数据和改进实验方法的工作上。
参考文献:
[1] Allan J.Topic Detection and Tracking:Event-based Information Organization[M].Boston,MA:Springer US,2002.
[2] Yu X,Bin Z,Yang O.A method based on sentence embeddings for the sub-topics detection[J].Journal of Physics:Conference Series,2019,1168:052004.
[3] Naik M P,Prajapati H B,Dabhi V K.A survey on semantic document clustering[C]//2015 IEEE International Conference on Electrical,Computer and Communication Technologies.Coimbatore,India.IEEE,2015:1-10.
[4] Mathioudakis M,Koudas N.TwitterMonitor:trend detection over the twitter stream[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data.Indianapolis,Indiana,USA.New York:ACM,2010:1155-1158.
[5] https://github.com/fxsjy/jieba.
[6] 徐云青,徐义峰,李舟军.基于VSM的中文信息检索[J].计算机系统应用,2007,16(4):21-23.
【通联编辑:唐一东】
