基于改进快速密度峰值聚类算法的电力大数据异常值检测分析
2022-02-17杨峰刘胜强
杨峰,刘胜强
(广东电网有限责任公司佛山供电局,广东佛山 528000)
随着智能配电网信息化、自动化的不断发展,各行业广泛使用先进配用电自动化和管理系统,多源异构数据也在不断增加。有效挖掘数据并且使用能够提高智能配电网运行管理水平,此为电力企业在大数据背景下发展的需求[1]。由于存在不同的数据统计口径与来源,从而使数据出现异常。异常数据存在异常信息,异常数据研究尤为重要,能够提供实际使用帮助,包括用电设备故障监测与设备监测。传统异常检测为技术人员到现场排查,此方法效率低,而且物力、人力等资源较为浪费。通过数据方法自动锁定异常事件,能够提高异常事件查处命中率,降低稽核成本与电网企业经济损失[2]。以此,文中就分析改进了检测快速密度峰值聚类算法电力数据异常值。
1 传统算法分析
基于密度峰值的空间聚类算法(CFSFDP)首先利用其他非类中心点到大密度且临近数据点类别中归类。类中心要满足以下特征:自身密度比较大;对比其他大密度数据点,距离比较大。在该模型中,CFSFDP 算法要对数据点局部密度ρi和高密度点距离δi进行计算。
假设聚类数据集为S=(x1,x2,…,xn),指示坐标集设置为:

数据点xi与xj的距离表示为:

在具备离散值数据点时,局部密度表示为:
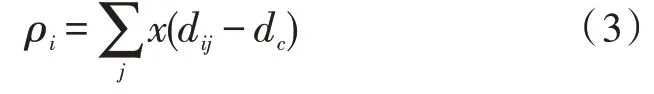
式中的i和j不相等,函数x(x)表示为:

在连续值为数据点时,局部密度表示为:

公式中的横断距离dc>0,ρi指的是S中和数据点xi的距离比dc要小的数据点数量[3]。
和高密度点的距离表示为:

相应指标集Is为:

通过以上公式表示,在xi指的是最大局部密度的时候,Is指的是空集,δi指的是S中和xi最大距离数据点和xi的距离。
对各个数据点局部密度和距离进行计算之后,CFSFDP 算法利用启发式的方式对决策图绘制,选择类中心并实现类标记的初始化。使非聚类中心根据下述规则实现聚类:目前数据点类别标签指的是比数据点密度要高的最近数据点类别,之后对类边界区域进行计算,寻找类边界高密度值的点,从而将噪声点去除。
CFSFDP 算法直接操作数据集,没有对数据空间分布的特性进行考虑,选择并且使用全局密度阈值dc。在数据密度与类间距分布出现不均匀或者某个类中具有多密度峰值的时候,无法对合适dc值选择实现聚类,所以得到的聚类结果也不精准[4]。
2 改进的快速密度峰值聚类算法
2.1 选择自适应参数
在信息论中使用香农熵作为系统不确定性度量,熵越大,就会提高其不确定性。n个样本点局部密度估计值设置为ρ1,ρ2,…,ρn,假如其中样本点密度估计值是一样的,对于底层数据分布具有较大的不确定性,并且香农熵较大。相反,不确定性最小,香农熵也最小。所以,使用以下密度估计熵对样本点局部密度估计合理性进行衡量,也就是:
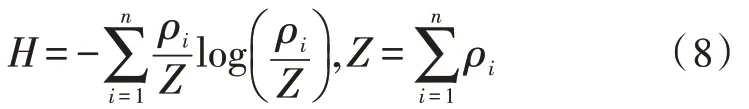
式中,Z表示标准化因子。
在对密度估计熵性质进行分析的过程中0≤H≤log(n)。以此得到,全部样本点局部密度估计值是近似相等的,所以密度估计熵最大[5]。
针对给定核函数的形态,对密度参数dc通过0到+∞的递增过程中密度估计熵H变化的情况:在dc→0的时候,H满足Hmax=log(n)。在dc不断增加的过程中,首先H减小,在某优化dc地方为最小值。之后增大,在dc→+∞的时,为最大值Hmax=log(n)。参数优化值为最小密度估计熵dc值,对dc值进行优化的过程中就是单变量非线性函数最优化的问题,也就是:
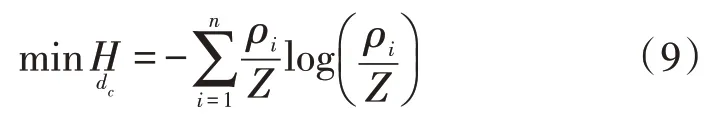
该问题中具有模拟退火法、简单试探法等大量的标准算法,在实际使用过程中会在样本容量不断增加过程中,使dc值时间开销得到降低。n越大,使用抽样率在2.25%以下的随机抽样方法使算法优化性能得到提高[6]。
2.2 选择聚类中心
利用以上对CFSFDP 算法的分析表示,该算法的基本立足点为:
1)聚类中心具有较大的局部密度;
2)聚类中对比其他大局部密度数据点的距离大。
以此表示,聚类中心局部密度和距离具有较大的值。那么本文所提出的改进快速密度峰值聚类算法自动选择策略为:利用标准化局部密度与距离的乘积对聚类点差异度进行评测,之后将高斯分布应用到乘积中实现异常检测,从而能够得出异常点。针对需要聚类数据,此异常点也就是聚类中心。高斯分布能够满足异常检测需求,在两端分布的小概率事件为异常点,通过此点能够得出数据集聚类中心[7]。
首先,使用簇中心权值概念对数据点簇中心权值γi进行定义:

公式中的和指的是分别使用z-score的标准化结果。之后通过以下公式对γi均值和方差:
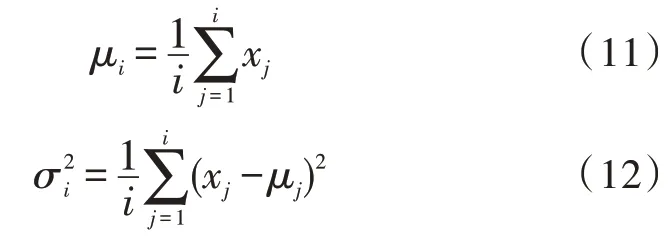
之后针对阈值ε关系对数据点是否为异常点进行判断,本文的阈值设置为0.005。针对交叉验证集使用多个阈值,并且将此阈值作为基础,对交叉验证集中的F1 值进行计算,得到最高值进行返回[8]。F1定义为:

在阈值为0.001~0.01的时候并不会影响到实验结果,但是不能够过大或者过小。如果p(γi)<ε的时候,此数据点就是聚类中心。图1 为三螺旋数据集,图2 为高斯分布得出聚类中心。一般,阈值设置的值比较小,所以图2 接近横轴点利用五角星标记,也就是数据集聚类中心[9]。
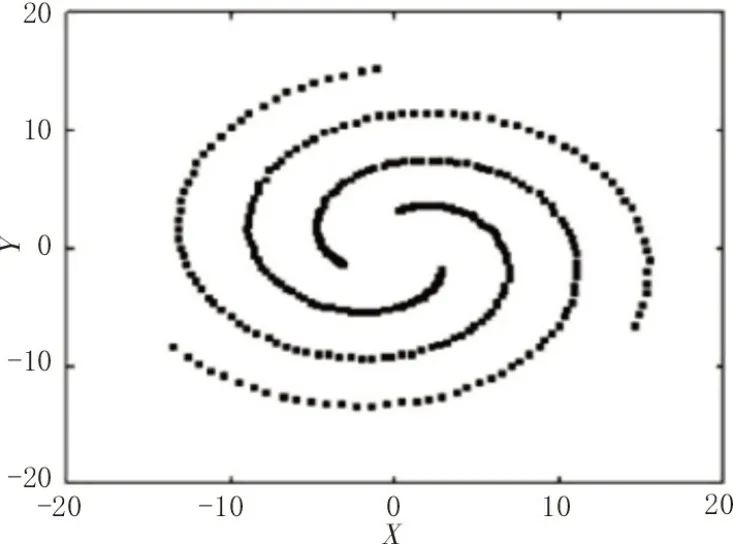
图1 三螺旋数据集

图2 高斯分布的聚类中心
聚类中心的选择步骤为:
1)实现数据点局部密度和距离的标准化;
2)对每个点簇中心权值γi计算;
3)对每个点均值μi与方差进行计算;
4)对点概率密度p(γi)计算;
5)对p(γi)和阈值大小关系进行判断,如果p(γi)<ε,那么此数据点就是簇中心,要不然就是聚类中心[10]。
3 仿真实验
3.1 算例分析
为了对分析算法有效性进行验证,该文进行了仿真实验。案例使用某省交流10 kV 配电变压器负荷数据,设置1 h 为采集频率,所以日负荷曲线中的数据点共有24 个。
图3 为交流10 kV 配电变压器日负荷数据的标准化曲线,该变压器在常规运行过程中的曲线偏离正常的运行模式[11]。

图3 日负荷数据标准化曲线
根据以上分析对数据集中样本K各近邻进行计算,并且计算样本局部密度与KNN 距离。图4 为异常值检测的决策图,表示大部分的样本距离都在小于0.2 区域中集中,局部密度在大于0.95 区域中集中。只有部分样本点具备大距离与小局部密度,也就是异常值[12]。
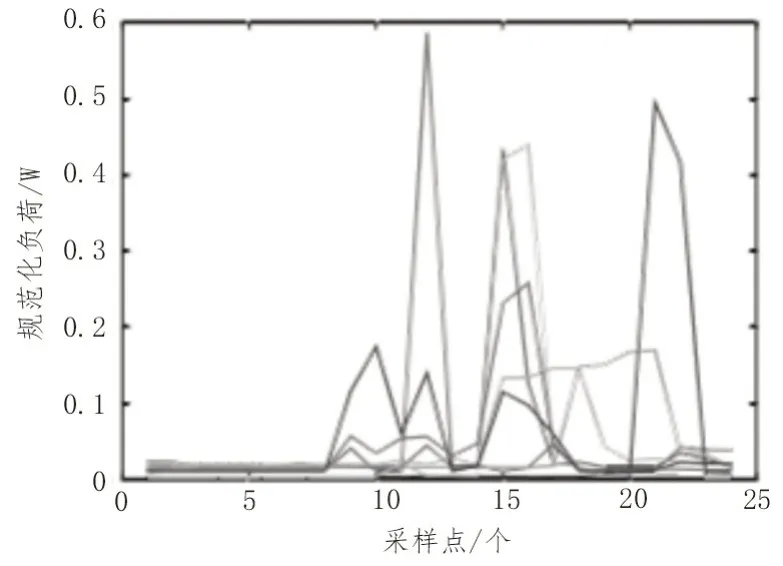
图4 异常值检测的决策图
对比分析表示,该文算法能够有效监测和正常运行模式不同的曲线,在120 条曲线中所筛选的异常曲线共有7 条。表1 为曲线时间分布,在异常曲线中的时间是中国的信念,也就是表示该文所提算法能够对异常用电模式进行检测[13]。
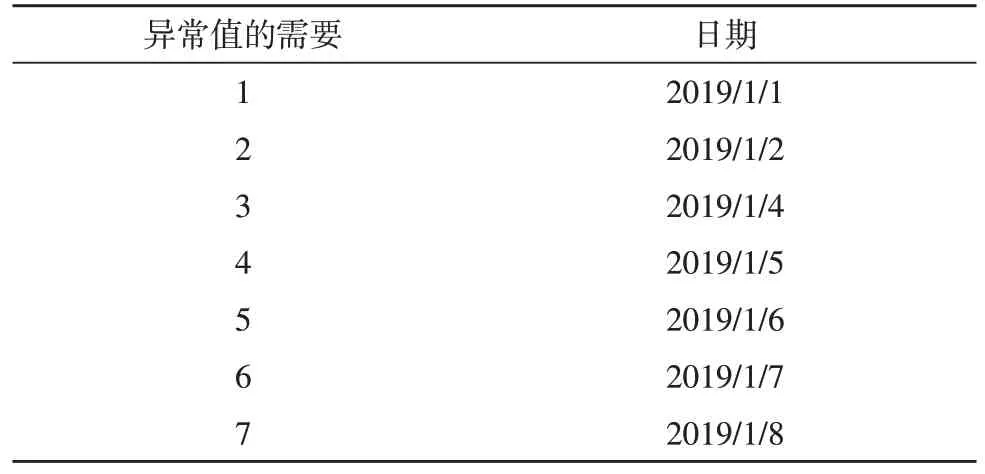
表1 曲线时间分布
3.2 聚类算法的性能对比
以不同的规模实现研究对象子集:对比传统算法与改进算法的聚类分析,分析两种算法的内存小号与执行时间,两种算法性能对比详见表2。通过改进前后传统算法与其他算法的聚类分析,对比算法内存消耗与执行时间。为了保证算法执行时间客观性,在不同规模数据中的算法集中运行20 次,得出此数据规模中运行平均时间的执行时间[14]。
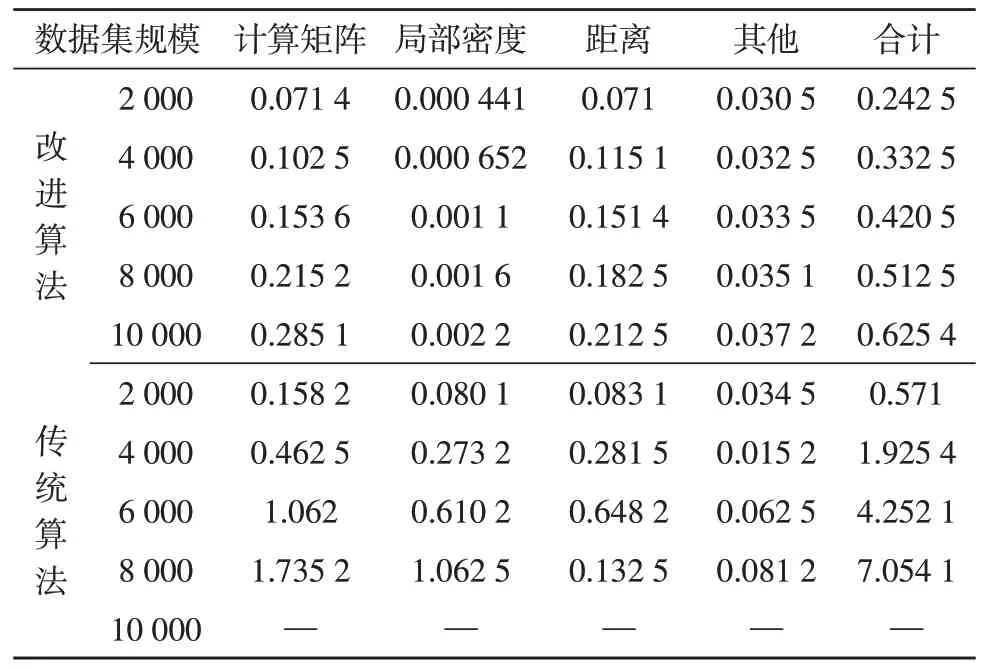
表2 两种算法的性能对比
通过表2 可知,传统算法只能够对8 000 条负荷曲线进行处理,在超过8 000 条的时会由于算法内存消耗过大导致计算机内存空间不足的情况,从而无法继续的进行执行。该文所分析的算法在数据集规模达到140 000 条以上时才会导致内存溢出,也就验证了该文设计的算法能够降低原本算法内存消耗[15-16]。
4 结束语
该文提出了基于改进的快速密度峰值聚类算法,通过全新思想对局部密度和距离进行定义,使传统算法中的问题进行了改善,并且对异常值判断的规则进行定义,基于异常值检测角度实现优化。该方法在某变压器日负荷曲线仿真实验中使用具有良好的性能,在对异常值进行检测之后能够结合实际业务实现异常用电的分析和设备的状态监测,还能够以业务规则修正异常值,使数据质量得到提高。
