基于文本表达的指向性目标分割方法研究
2022-02-17魏庆为张丽红
魏庆为, 张丽红
(山西大学 物理电子工程学院, 山西 太原 030006)
0 引 言
图像分割是图像识别和目标分类至关重要的预处理方法. 目前, 基于深度学习的图像分割方法主要有3种: 语义分割、 实例分割和全景分割. 但这些方法仅仅是利用了图像特征, 没有涉及文本信息, 在分割过程中经常会出现类别数量分割错误, 或是相同类别区域颜色不同的问题.
近年来, 基于文本表达的图像分割方法取得了较好的成果. 通过文本信息可以指导网络对图像进行针对性分割, 打破了以往方法中只对图像本身进行处理的局限性. Hu等人利用一个端到端的可训练网络框架, 结合图像特征和文本特征, 得到了较粗糙的像素级分类[1]; Wu等人提出了模块化方法, 将类别、 属性和相关联的视觉特征进行结合, 但是分割精度不高[2]; Ye等人利用跨模态自注意模块来捕捉视觉和文本之间长期的依赖关系, 使分割目标得到较好的特征表示[3]; Huang等人提出一种新的跨模态渐进理解模型, 通过文本引导的特征交换模块经多路通信实现信息交流[4]. 虽然这些方法在一定程度上实现了图像特征和文本特征的融合, 但是仍然存在视觉和文本难以对齐的问题; 而且目前的研究大都是将指向性目标检测和目标分割视为两个独立的任务, 分别进行处理, 没能实现两个任务之间的信息交互, 从而导致了网络的推理速度缓慢[5].
为解决上述问题, 本文使用多模态融合方法来处理视觉特征和文本特征, 同时设计的协同网络结构将指向性目标检测和目标分割联合起来, 不仅解决了视觉和文本的对齐问题, 而且还提高了网络的训练速度, 实现了更好的分割效果.
1 网络框架
多任务协同网络整体框架包括两个部分: 协同网络部分和后处理部分, 网络具体结构如图 1 所示. 其中协同网络使得指向性目标检测和目标分割两个任务之间相互学习, 同时使用协同能量最大化方法解决了指向性目标检测和目标分割之间的预测分歧问题. 此外, 本文使用目标区域裁剪的后处理方法, 得到最终的预测结果.

图 1 多任务协同网络整体框架
2 协同网络结构
协同网络首先使用卷积神经网络darknet53提取多尺度的视觉特征. 其中, darknet53网络包含卷积层、 激活层和池化层, 共有53层卷积, 网络的卷积核大小设置为1×1和3×3, 步长设置有1和2, 填充设置有0和1. 网络输出3个不同尺度的检测图, 用于检测不同大小的物体. 同时, 使用双向门控循环神经网络编码文本特征, 然后, 将视觉特征和文本特征经过多模态特征融合, 生成多尺度多模态特征, 将多模态特征通过自下而上的连接方式分别输入到指向性目标检测和目标分割两个分支中, 增强两个任务的共同学习. 最后使用协同能量最大化方法连接这两个分支, 通过最大化损失优化两个分支的响应一致性.
2.1 双向门控循环神经网络
循环神经网络(Recurrent Neural Network, RNN)是以序列数据为输入, 在序列的演进方向进行递归的神经网络[6]. 但是过拟合和梯度弥散等现象会使得RNN无法建模较长的序列. 双向门控循环神经网络(bi-directional gated recurrent neural network, Bi-GRU)是双向长短时记忆网络(bi-directional Long Short-Term Memory, Bi-LSTM)的延伸, 是将Bi-LSTM中的LSTM模块替换为GRU[7]. GRU是将词嵌入向量和隐藏层, 状态向量经过门控计算, 得到最终的输出向量和隐藏层状态向量. 相比于RNN, Bi-GRU的参数量较少, 同时泛化效果更好, 因此, 在大型语料文本中应用广泛. 本文使用双向门控循环神经网络提取文本特征, 其中, GRU单元内部结构如图 2 所示.

图 2 GRU单元内部结构Fig.2 Unit internal structure of GRU
更新门为
zt=σ(Wz·[ht-1,xt]).
(1)
重置门为
rt=σ(Wt·[ht-1,xt]).
(2)
t时刻隐藏点的待选值为

(3)
GRU单元t时刻隐藏点激活值为

(4)
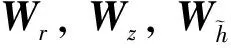
2.2 自适应特征选择和多模态特征融合
在视觉特征和文本特征融合过程中, 由于文本表达式的多样化, 本文采用了自适应特征选择的方法, 通过文本表达式的内容, 自适应地融合不同尺度的视觉特征[8]. 其中多尺度视觉特征为Fv1∈Rw1×h1×d1,Fv2∈Rw2×h2×d2和Fv3∈Rw3×h3×d3, 自适应特征选择如图 3 所示.
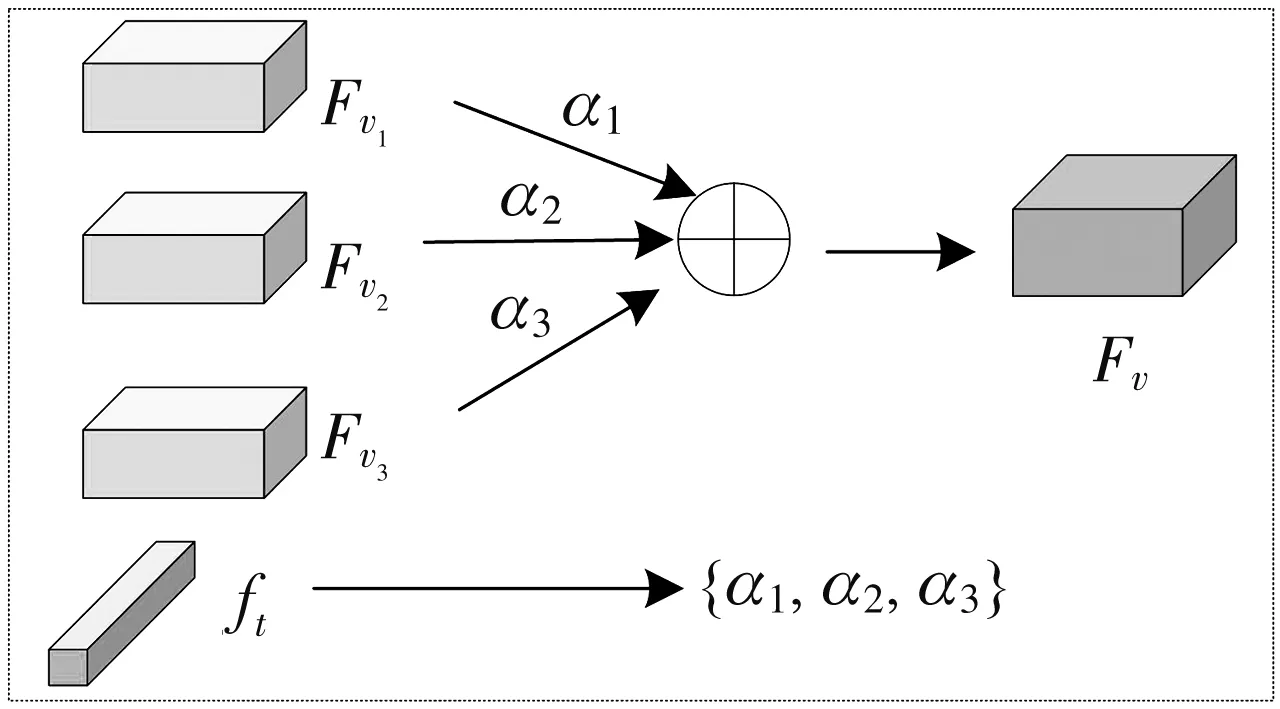
图 3 自适应特征选择Fig.3 Adaptive feature selection
自适应特征选择是将卷积神经网络提取的k个多尺度图像特征通过卷积等操作, 将多尺度特征转换成同等尺寸, 之后通过文本特征ft预训练的权重参数对图像特征进行加权求和, 得到输出的视觉特征, 最后将得到的视觉特征输入到指向性目标检测分支中. 该模块自适应地融合不同尺度的视觉特征, 同时也强化了模型对文本表达式的理解能力. 最终得到的特征为

(5)
式中:αi是文本特征ft的预训练权重.


图 4 多模态特征融合Fig.4 Multimodal features fusion
2.3 指向性目标检测和目标分割
目前, 大多数基于文本的分割方法是将指向性目标检测和目标分割作为两个独立的模块, 分成两个阶段完成. 本文将指向性目标检测和目标分割结合成一个阶段, 提高了模型的推理速度. 指向性目标检测是根据给定的文本表达式, 通过边界框来固定目标对象. 通常情况下, 指向性目标检测是从图片中检测出目标区域, 再使用多模态交互的方法找出图片中最符合的区域. 大多数方法使用目标检测器先提取视觉特征, 再利用语言特征进行交互. 虽然这种方法性能较高, 但是计算效率低下. 指向性目标分割常用的方法是对文本进行编码, 再将编码后的文本特征输入到分割网络, 但是难以得到精确的分割掩码.
事实上, 指向性目标检测有助于指向性目标分割正确定位分割对象, 同时, 指向性目标分割利用像素级标签, 使得指向性目标检测更好地实现视觉和文本的对齐. 因此, 本文使用指向性目标检测和目标分割两个分支共同学习的方法, 使得二者相互增强, 互为补充, 从而达到较好的效果. 在指向性目标检测分支中, 使用回归层来预测置信度得分和检测边界框的位置, 目标检测的损失函数

(6)
在指向性目标分割分支中, 本文通过使用精细化的多模态张量和改进的空洞空间金字塔池化模块来预测分割掩码. 目标分割的损失函数
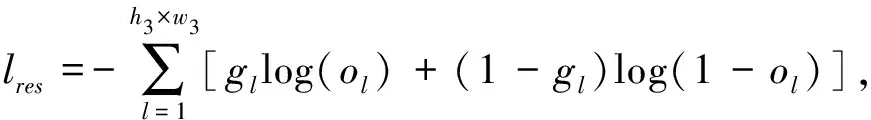
(7)
式中:h3和w3分别表示特征Fv3的高度和宽度;gl和ol分别表示对应真实值的元素和预测掩码.
2.4 协同能量最大化
基于文本表达式理解的图像分割中常见的问题是预测分歧, 即: 指向性目标检测分支未能正确理解文本描述, 导致错误地固定图像中的检测目标, 如图 5(a) 所示; 或者是指向性目标分割未能对边界框中目标对象进行正确分割, 如图 5(b) 所示.

图 5 预测分歧Fig.5 Prediction conflict
为了解决上述预测分歧问题, 本文使用了协同能量最大化的方法, 如图 6 所示.
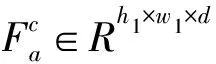

(8)

图 6 协同能量最大化Fig.6 Consistency energy maximization


(9)

最终得到协同能量最大化

(10)
为了确保指向性目标检测和目标分割两个任务的响应一致性, 本文通过定义协同能量最大化损失函数来优化它们的注意力张量, 损失函数

(11)
式中:h1和w1分别表示特征Fv1的高度和宽度;h3和w3分别表示特征Fv3的高度和宽度;C(i,j)表示最大化的协同能量.
网络的总损失函数包括协同能量最大化损失、 指向性目标检测损失和目标分割损失3个部分. 总损失函数
lall=lres+lrec+lcem.
(12)
2.5 改进的ASPP模块
空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)主要用于图像或视频的分割[8]. ASPP是对网络的输出特征进行多尺度信息提取, 以多个比例捕捉图像的上下文信息, 然后将输出的特征映射采用不同膨胀率的空洞卷积进行并行采样. 通常是采用1×1的卷积来改善输出通道, 再采用3个具有不同膨胀率的3×3卷积. ASPP模块中的空洞卷积消除了下采样操作导致的信息损失, 同时还增大了网络的感受野. 但是ASPP模块中多个3×3卷积会增加参数的计算量, 造成信息冗余, 在训练中通常会消耗较长时间. 为此, 本文对ASPP模块做出了必要的改进. 具体是将ASPP模块中3×3的空洞卷积分解成两个3×1和1×3的卷积, 将分解后的特征f1,f2,f3,f4和f5组合得到最终的特征f. 该方法在不改变膨胀率的情况下减少了参数量, 提高了网络的训练速度, 改进的ASPP模块如图 7 所示.
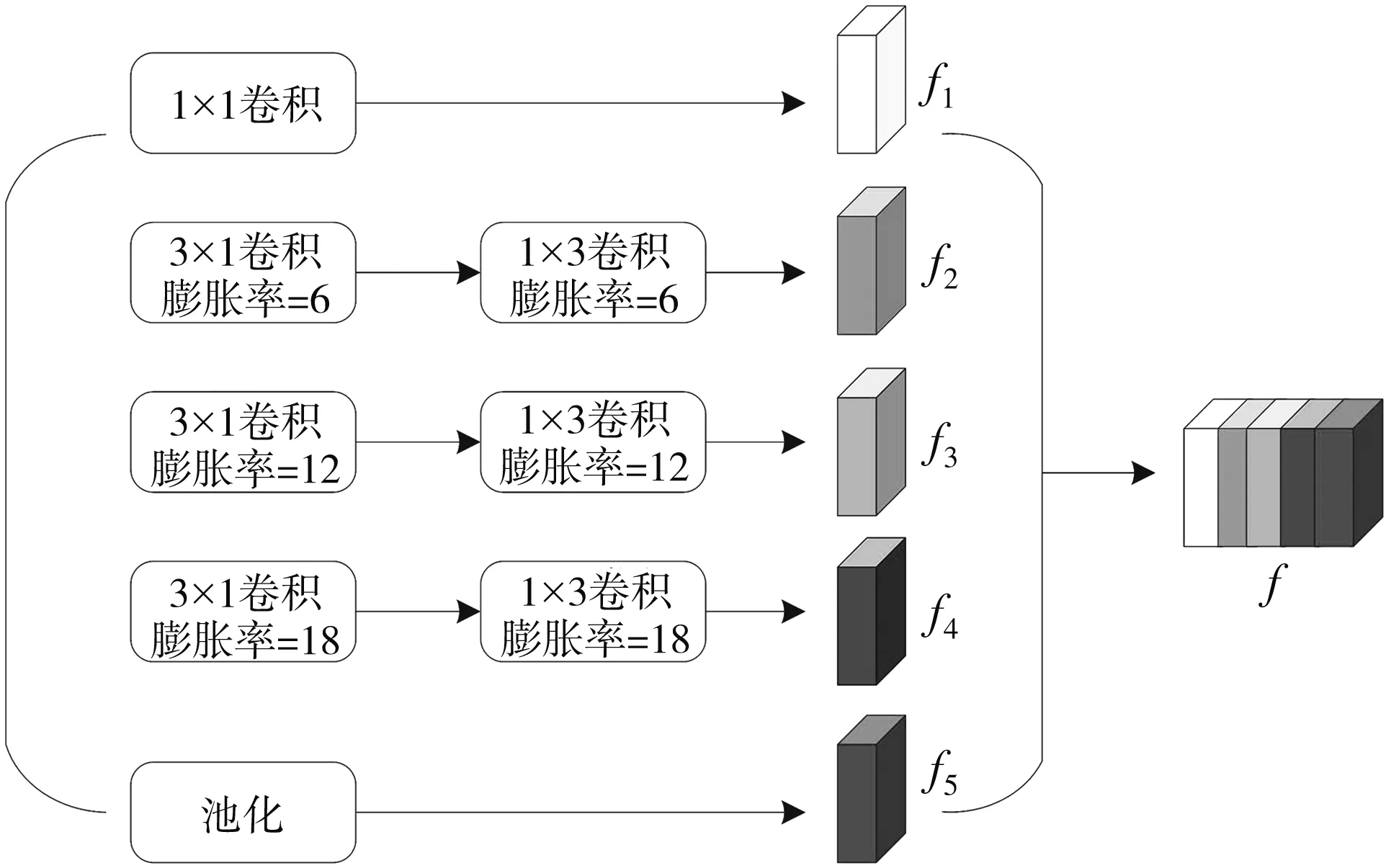
图 7 改进的ASPP模块Fig.7 Improved ASPP module
3 后处理
在指向性目标检测和目标分割任务完成之后, 需要进行后处理操作. 为了使得指向性目标分割能够准确分割目标对象, 本文采用Faster R-CNN网络中目标区域裁剪(ROI Crop)方法[9]. 首先, 指向性目标检测利用文本表达式检测出目标对象, 同时指向性目标分割用于输出分割概率图; 然后, 利用检测的边界框定位分割概率图中的目标对象, 进而对分割图进行裁剪; 最后, 将裁剪的目标对象经二值化处理得到目标的分割掩码.
4 实验结果及分析
4.1 数据集
实验采用RefCOCO数据集和RefCOCO+数据集, 二者均是基于MSCOCO数据集收集的. RefCOCO数据集包含来自MSCOCO数据集中的19 994张图片, 有142 210个引用表达式用于50 000个边界框. 该图片数据集被分为训练集、 验证集、 测试集A和测试集B, 分别具有120 624, 10 834, 5 657和5 095个样本. 这些表达式通过交互式游戏界面收集, 短句的平均长度为3.5个单词.
RefCOCO+数据集包含来自MSCOCO数据集中的19 992张图片, 有141 564个引用表达式用于49 856个边界框. 与RefCOCO数据集类似, 该图片数据集被分为训练集、 验证集、 测试集A和测试集B, 分别具有120 191, 10 758, 5 726和4 889个样本.
4.2 评估指标
实验中使用精度(precision)作为指向性目标检测的评价指标. 精度的具体意义是查出所有正样本的准确率. 在目标检测任务中, 正例通常是希望在图像中被检测出的对象, 负例通常是除正例之外的背景. 精度
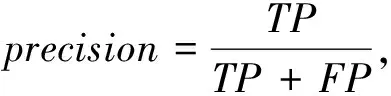
(13)
式中:TP表示将正例预测为正类的样本数;FP表示将负类预测为正类的样本数(误检).
对于指向性目标分割的评估, 使用交并比(IoU)作为评价指标. 交并比是图像分割常用的评价指标, 其计算真实值和预测值表示的两个集合的交集和并集之比, 如图 8 所示.
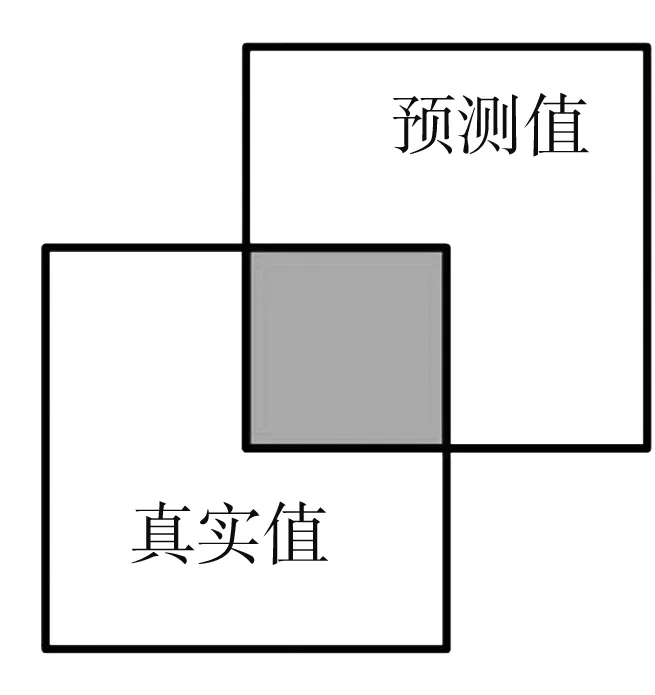
图 8 交并比Fig.8 Intersection-over-Union
交并比

(14)
4.3 实验结果分析
实验在RefCOCO数据集和RefCOCO+数据集上进行. 表 1 是使用本文方法与其他方法在验证指向性目标检测任务上的精度对比. 其中, MattNet方法利用Faster R-CNN网络来检测目标对象[10]. 从表 1 可以看出, 与常用方法相比, 本文方法的检测效果更好, 在RefCOCO数据集的测试集A上检测精度可达到82.30%.
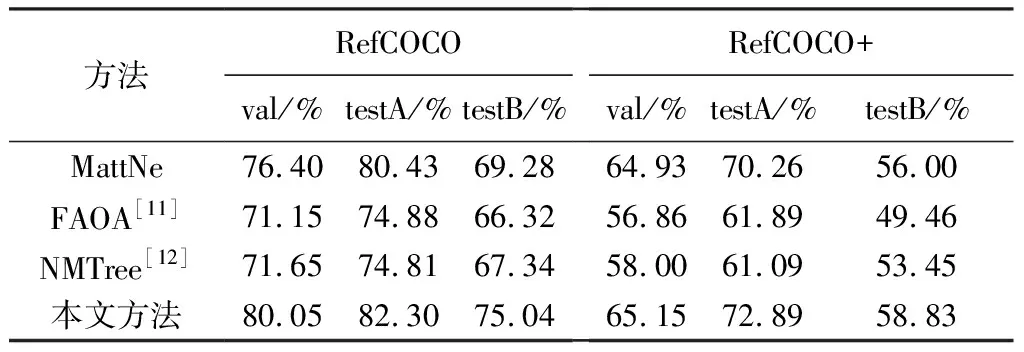
表 1 本文模型与其他模型在两个数据集上的检测结果对比
表 2 是使用本文方法与目前方法在验证指向性目标分割任务上的准确率对比. 其中, MattNet方法利用Mask R-CNN网络对图像进行分割, 得到像素级的分类. CMSA方法使用门控多级融合模块, 结合不同层次的视觉特征来生成图像的分割掩码. 从表 2 可以看出, 与目前方法相比, 本文方法的分割效果较好, 在RefCOCO数据集的测试集A上分割准确率可达到63.20%.

表 2 本文模型与其他模型在两个数据集上的分割结果对比
网络在训练时输入图片的批量大小设置为4, 学习率设置为0.05. 在RefCOCO数据集上训练的总损失函数曲线如图 9 所示, 从图 9 中可以看出, 随着迭代次数增加, 函数变化趋于平稳.
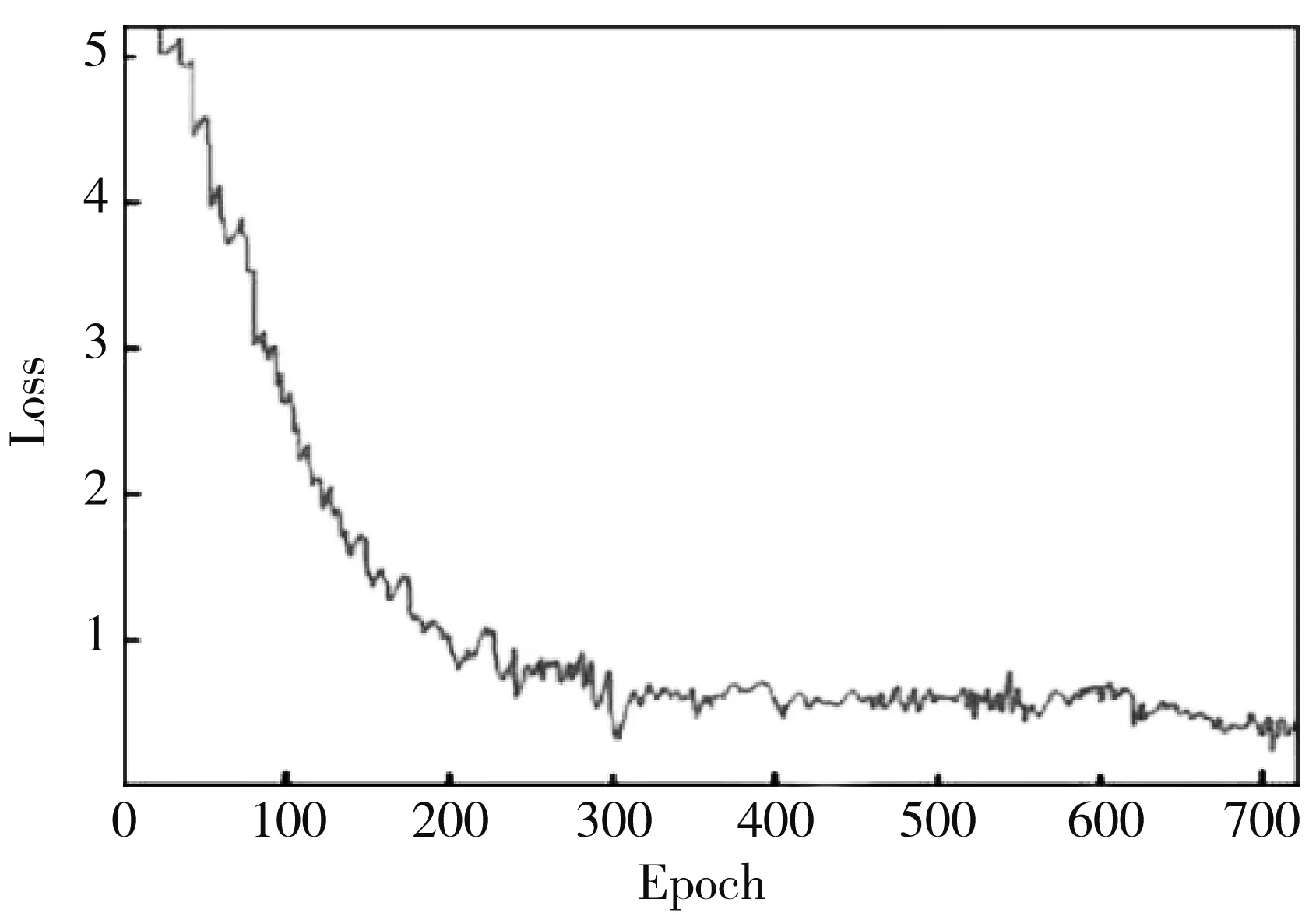
图 9 损失函数曲线Fig.9 Loss function curve
本文方法在RefCOCO数据集和RefCOCO+数据集上的预测结果如图 10 所示. 图 10 中的第1列表示输入的原始图像, 第2列表示使用本文方法得到的预测结果, 第3列表示标注的真实图像.

图 10 本文方法在RefCOCO和RefCOCO+数据集上的预测结果Fig.10 Predictions of this method on the RefCOCO andRefCOCO+ datasets
5 结束语
本文研究了基于文本表达的指向性目标分割分析方法, 模型中的协同网络将多模态特征输入到指向性目标检测和指向性目标分割分支中, 促进二者共同学习, 采用自适应特征选择方法自适应地融合不同尺度的视觉特征, 增强模型对文本表达式的理解能力, 引入协同能量最大化方法解决了多任务结构中的预测分歧问题. 同时, 改进的ASPP模块极大地减少了网络参数量, 提高了训练速度.
