基于LSTM-LightGBM模型的车站环境温度预测
2022-02-16张亚伟陈瑞凤徐春婕杨国元吕晓军
张亚伟,陈瑞凤,徐春婕,杨国元,吕晓军,方 凯
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
0 引言
智能高铁已成为目前铁路运输领域的发展方向,推进智能车站的建设是构建智能高铁的重要组成部分。铁路客运站作为城市间重要的桥梁,智能化体验、舒适旅行也成为了人们所追求的目标。某些大型客运站人流进出量大,容易出现人流密集、拥挤的情况,而其内部的空气环境直接影响着旅客舒适度的体验,尤其是温度成为了环境指数中重要的物理量。站内风水系统的调节直接受环境温度影响,随着环境温度高低的变化,风水系统可提前调节为合适的大小,从而可达到最佳的旅客感知体验。站内温度受多方面环境因素影响,包括湿度、二氧化碳(CO2)浓度、PM2.5、PM10等参数,本文基于站内环境特征变量参数,结合模型算法重点研究站内环境温度的预测问题。
基于数学建模的预测方法种类繁多,如单耗法、弹性系数法、统计分析法、灰色预测法等[1]。针对不同预测内容的特点会选择相应的预测方法建立预测模型。对于中短期预测,近似于指数增长的预测,可选用灰色预测模型。对于时间序列问题,传统方法有指数平滑法、自回归积分滑动平均ARIMA模型算法,LSTM模型算法等[2],这些方法对具有周期性规律的数据预测有较好的效果。对于多因子影响的预测问题,可用BP、GBDT等机器学习算法[3]。文献[2-3]采用分位数回归法、改变学习速率法对LSTM模型进行了改进,并应用于用电负荷与股价趋势预测。文献[4]采用时间序列分析ARIMA模型对局部地区的季节性气温进行了预测。另外,基于GBDT模型改进的梯度提升算法如XGBoost、LightGBM模型,具有训练速度快、占用内存小的特点,也得到了相关预测的应用。车站环境温度值有两个特点:(1)一种时间序列,即数据会随时间发展而展现出一种规律性,受季节与白天黑夜的影响呈现一种周期性波动;(2)规律之中又有其特殊性,如会受湿度值、PM2.5、CO2等环境因素的影响而发生波动,对于车站人员密集场所,这些因素的影响会更大,单独使用上述算法缺乏对车站环境温度的整体预测感知能力。
针对车站环境温度的特点,本文将LSTM与LightGBM模型进行组合,充分利用车站环境特征变量对站内环境温度进行预测。该组合模型能够结合LSTM与LightGBM模型各自的特点,既可挖掘长时数据之间的内在关系,又可避免非连续性以及波动数据对预测精度的不良影响[4]。
1 LSTM环境预测模型算法
LSTM是一种特殊的RNN网络,RNN会存在梯度消失和梯度爆炸的问题,LSTM通过cell门开关实现时间上的记忆功能,并防止梯度消失,可以学习长期依赖信息,让信息长期保存,解决RNN的缺陷问题[5],其算法结构如图1。LSTM的当前输入xt和上一个状态传递下来的ht-1拼接训练可以得到四个状态,状态公式如下:

图1 LSTM算法结构图
(1)
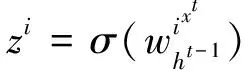
(2)
zf=σ(wfxtht-1)
(3)

(4)
式(2)~(4)的zi,zf,zo是由拼接向量乘以权重矩阵之后,再通过一个sigmoid 激活函数转换成0到1之间的数值,作为一种门控状态。公式(1)中z是将结果通过tanh激活函数转换成-1到1之间的值。⊙是操作矩阵中对应的元素相乘,要求两个相乘矩阵是同型的[6]。⊕代表矩阵加法。ct、ht、yt计算公式如下:
ct=zf⊙ct-1+zi⊙z
(5)
ht=zo⊙tanh(ct)
(6)
yt=σ(Wfht)
(7)
LSTM模型计算过程主要分为三个阶段:忘记阶段、输入阶段、输出阶段。忘记阶段即“忘记”之前没用的信息。遗忘门会根据当前时刻节点的输入xt、上一时刻节点的状态ct-1和上一时刻节点的输出ht-1来决定哪些信息将被遗忘[7]。输入阶段决定当前输入数据哪些信息被留下来。主要对输入xt进行选择记忆。当前输入内容由公式(1)z得出,选择门控信号由zi来进行控制。由公式(1)、(2)、(3)可得到传输给下一个状态的ct,即公式(5)。输出阶段确定输出值。LSTM在得到最新节点状态ct后,结合上一时刻节点输出ht-1和当前时刻节点的输入xt来决定当前时刻节点的输出yt,通过公式(6)的ht变化得到公式(7)。其中公式(6)中zo来进行控制,并对状态ct进行了缩放(通过tanh激活函数进行变化)[8]。
2 LightGBM模型算法
LightGBM是基于决策树算法的分布式梯度提升GBDT框架,在大训练样本和高维度特征的数据环境下,GBDT算法的性能以及准确性会面临极大的挑战。为了解决此问题,LightGBM应运而生。LightGBM具有训练速度快、内存占用少、准确率高、支持并行化学习、可处理大规模数据的特点[9]。
LightGBM在梯度算法中主要采用了一些优化算法:
1) 单边梯度采样算法(GOSS):LightGBM使用GOSS算法进行训练样本采样的优化。GOSS算法的基本思想是首先对训练集数据根据梯度排序,预设一个比例,保留在所有样本中梯度高于比例的数据样本;梯度低于该比例的数据样本不会直接丢弃,而是设置一个采样比例,从梯度较小的样本中按比例抽取样本。为了弥补对样本分布造成的影响,GOSS算法在计算信息增益时,会对较小梯度的数据集乘以一个系数用来放大。在计算信息增益时,算法可以更加关注“未被充分训练”的样本数据。
2) EFB算法(Exclusive Feature Bundling):LightGBM算法不仅通过GOSS算法对训练样本进行采样优化,也进行了特征抽取,以进一步优化模型的训练速度。EFB算法可以将数据集中互斥的特征绑定在一起,形成低维的特征集合,能够有效避免对0值特征的计算。在算法中,可以对每个特征建立一个记录非零值特征的表格。通过对表中数据的扫描,可以有效降低创建直方图的时间复杂度。
3) 直方图算法(Histogram):LightGBM采用了基于直方图的算法,将连续的特征值离散化成了K个整数,构造宽度为K的直方图,遍历训练数据,统计每个离散值在直方图中的累积统计量。在选取特征的分裂点时,只需要遍历排序直方图的离散值。使用直方图算法降低了算法的计算代价,同时降低了算法的内存消耗。
4) 按叶子生长(leaf-wise)算法:大多数决策树学习算法的树生成方式都采用按层生长(level-wise)的策略[10],如图2所示。

图2 level-wise策略图
LightGBM采用一种更为高效的按叶子生长(leaf-wise)策略算法,如图3所示。该策略每次从当前决策树所有的叶子节点中,找到分裂增益最大的一个叶子节点进行分裂,如此循环往复。该机制减少了对增益较低的叶子节点的分裂计算。与level-wise策略相比,在分裂次数相同的情况下,leaf-wise可以降低误差,得到更好的精度。Leaf-wise算法的缺点是可能会生成较深的决策树。因此,LightGBM在leaf-wise上增加了限制最大深度的参数,在保证算法高效的同时,防止过拟合[11]。
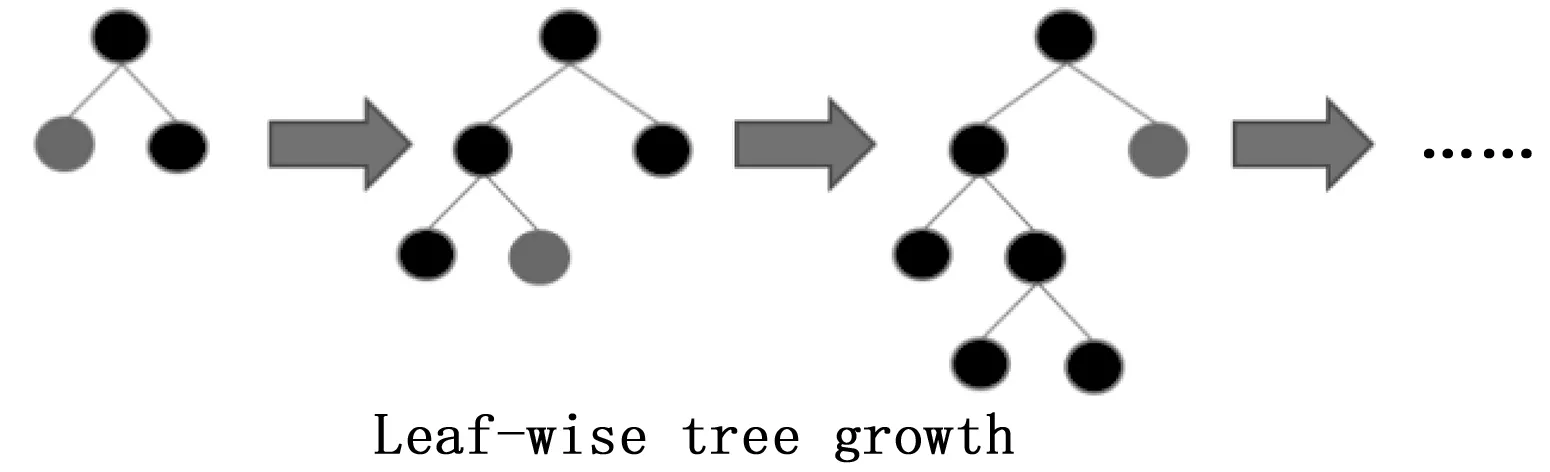
图3 leaf-wise策略图
3 基于LSTM-LightGBM组合模型预测算法
基于LSTM-LightGBM组合模型对温度进行预测的流程图如下,其中环境特征变量为湿度、二氧化碳、PM2.5、PM10,环境传感器数据除上述4种环境特征变量外还包含温度值。
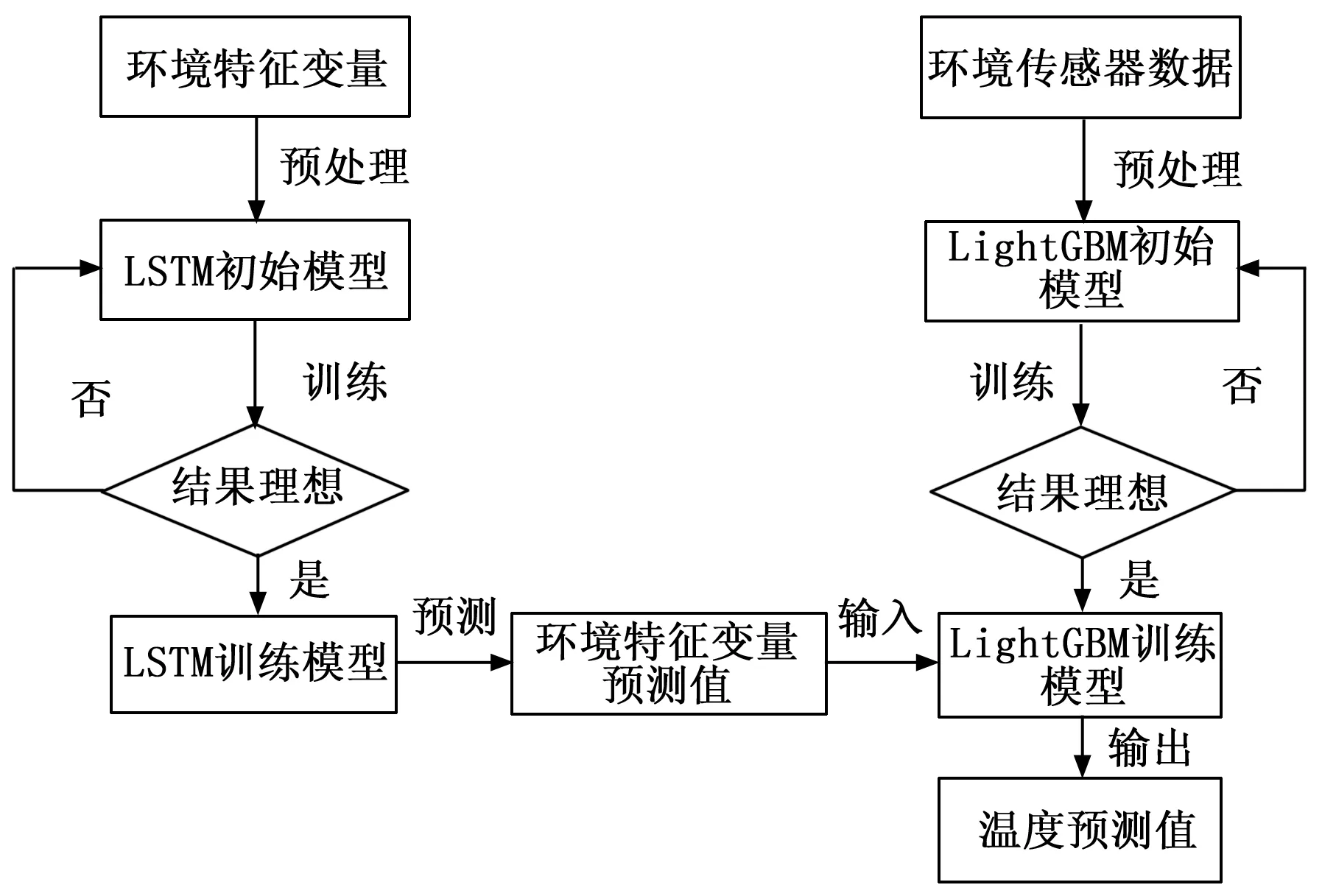
图4 LSTM-LightGBM算法流程图
3.1 数据预处理
数据来源为京张线清河站环境传感器获取的两日内145条数据,包含温度(Temprature)、湿度(humidity)、二氧化碳(CO2)、PM2.5、PM10数据。表1所示为采集数据的前5行:

表1 环境传感器采集数据
由于输入、输出变量值差异较大,先做归一化处理,以减小所得结果误差[12]。采用min-max标准化方法,将数据映射到[0,1]之间,如公式(10)所示:
(10)
其中:xmax为样本数据的最大值,xmin为样本数据的最小值。归一化后的数据前五行如表2所示。
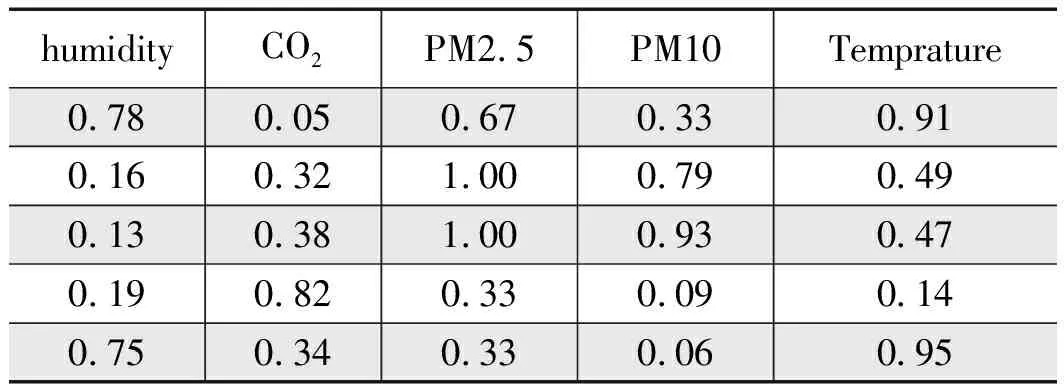
表2 归一化样本
3.2 构造模型及训练
3.2.1 构造LSTM训练模型
首先将输入数据整理成LSTM所需的三维结构,表示为(TrainX, SeqLen, Dim_in)第一个维度TrainX表示对应样本,第二个维度SeqLen表示该样本所采集的序列数据(指定序列长度),第三个维度Dim_in表示对应的特征维度,本文数据集环境特征变量为4个,因此Dim_in取4。按照此三维结构形式将数据集划分为训练集和测试集[13]。
第二,构建LSTM模型。模型结构表示为(Units, Input_Shape, Activation, Recurrent_dropout)。Units为隐含层神经元个数,Input_Shape为输入数据集的结构形式,Activation为激活函数,Recurrent_dropout为学习率。分析数据集样本大小和特点,得到最佳模型取值。本文Units取45,Activation取“relu”,Recurrent_dropout为0.01。
第三,训练LSTM模型。训练模型结构为(X_Train, Y_Train, Epochs, Batch_Size, Validation_Split)。 X_Train, Y_Train为模型训练数据;Epochs为迭代次数;Batch_Size为批处理样本数;Validation_Split为训练验证集分割比例。训练模型参数的取值是基于先验知识与大量实验得出,本文Epochs取值为100,Batch_Size为16,Validation_Split为0.8[14]。
3.2.2 构造LightGBM训练模型
将数据集划分为训练集和验证集,设置训练集和验证集比例系数为0.8。模型的参数设置是基于先验知识以及大量的实验,针对所用实验数据,LightGBM训练模型的核心参数设置如下[15]:
objective:任务类型。可选任务类型为regression(回归)、binary(二分类)、multiclass(多分类)等。本文任务是进行预测,设置为regression。
num_leaves: 叶节点的数目。该参数决定树模型的复杂度,越大会越准确,但可能过拟合,该参数设置为120。
max_depth: 控制了树的最大深度。该参数可以显式的限制树的深度。一般设置为不大于log2(num_leaves)的值,本文设置为7。
min_data_in_leaf: 每个叶节点的最少样本数量。它是处理leaf-wise树的过拟合的重要参数。将它设为较大的值,可以避免生成一个过深的树,但是也可能导致欠拟合。本文设置为16。
learning_rate:训练模型的学习率。较大的学习率会加快收敛速度,但是会降低准确率,默认为0.1。针对数据集的大小可调整学习率,本文设置为0.05。
num_boost_round:迭代次数。设置为1 000[16]。
3.2.3 LSTM-LightGBM组合模型预测
将环境特征变量湿度、二氧化碳、PM2.5、PM10数据输入LSTM训练模型,可计算出每个环境特征变量的预测值。该多维预测值作为输入变量,输入LightGBM模型,由此可得出温度预测值。
3.2.4 实验评价标准

(9)
4 结果分析
选取环境特征变量24条数据(即2小时)输入LSTM模型,所得预测结果如图5,四幅图为每个环境特征变量的预测结果。从图中可看出LSTM模型对于有突变的尖峰预测灵敏度较差,但是可以将数据的整体上升下降趋势预测出来[18]。表3为环境特征变量预测值与真实值的RMSE。

图5 LSTM环境特征变量预测结果

humidityCO2PM2.5PM10RMSE9.8111.230.8826.39

图6 LSTM-LightGBM温度预测结果
将LSTM模型已预测的湿度、二氧化碳、PM2.5、PM10数据输入LightGBM训练模型,所得温度预测值如图6。两模型预测结果RMSE分别为0.82和1.35。从图中可看出,LSTM-LightGBM组合模型比LSTM模型结果更接近原始波形,LSTM-LightGBM组合模型对波形突变有更好的响应,能反应出环境特征变量所引起的温度变化。
本文利用LightGBM自带的输入变量重要性判别函数对环境特征变量的重要性做了对比,结果如表4与图7。表5对环境特征变量的重要性用数值进行量化,重要性代表特征值在训练过程中使用的平均次数[19],图7以折线图形式呈现。可以看出,二氧化碳和PM10对预测结果有较大影响。

表4 环境特征变量重要性比对

图7 环境特征变量重要性比对折线图
5 结束语
本文基于客运火车站重点区域的环境传感器实际数据,采用预测算法对车站温度值进行预测分析。首先利用LSTM模型分别对湿度、二氧化碳、PM2.5、PM10四项环境特征变量进行预测。再利用LSTM模型预测的四项环境特征变量输入LightGBM模型对温度值进行预测。通过对比单独使用LSTM模型与使用LSTM-LightGBM组合模型对温度的预测结果,得出LSTM-LightGBM组合模型的预测值有更低的RMSE,其预测波形趋势更接近原始波形。
本文研究内容可应用于车站重点区域环境温度的预测,可为工作人员提供辅助决策手段,如通过预测值提前设定站内风水系统的空调温度值与通风量大小,从而提升区域舒适度,减少能耗[20]。最后,本文的算法仍有研究空间,如训练数据量大小对模型的影响,不同环境特征变量的预测对车站节能、舒适度的影响等。
