第五代编程语言设计与实现
2022-02-15韩济澎李陈志航
韩济澎,李陈志航
(北京华规科技有限公司技术部 北京 100081)
0 引言
编程语言的发展经历了机器语言、汇编语言、高级语言、函数语言、逻辑语言[1]。其中,逻辑编程语言亦被称作第五代编程语言。最早的逻辑语言是列表处理语言LISP(LISt Processing),其特点是用符号表达式而不是数字进行计算;不足是数值运算能力较弱和数学语义不清晰[2]。后来PROLOG问世,其特点是基于符号逻辑进行运算,通过模式匹配完成计算,语言清晰、可读、简洁[3-4];不足是对规则和目标的表示有严格限制,难以适用于复杂的应用环境[5-7]。
具体改进如下:第一,COOL支持面向过程与面向对象,便于应用于生产项目;第二,COOL支持将表达式作为函数声明以及函数返回,同时支持将函数参数嵌入函数名字字符串中;第三,COOL引入了权重机制并通过累计权重法加速推理过程;第四,COOL引入正向函数、逆向函数的概念,以处理逻辑上具有先后顺序约束的问题;第五,通过回溯算法和动态规划算法实现计算机利用正向求解过程推导逆向求解过程;第六,引入预执行步骤,将推理过程从程序的执行过程中分离,提升程序的执行速度。
1 语法
1.1 函数
函数构成了COOL的推理框架。此节介绍了返回表达式的函数、返回运算值的函数、附加权重的函数、正向函数、逆向函数、函数权重。在COOL中函数由函数声明和函数体两部分组成,表示相加的函数可以用如代码1的方式进行定义。
代码 1 函数声明示例:
@add(a,b){
return:a+b;
}
通过为函数声明加上属性“exp”来表明此函数的返回是一个表达式。这种函数用来表述变换规则,用户不能直接调用此类函数,如代码2通过函数描述乘法分配律的逆运算。
代码2返回表达式的函数示例:
exp:@{a*c+b*c}{
return:(a+b)*c;
}
正向函数与逆向函数均指返回运算值的函数;返回表达式的函数不具备此属性。正向函数,即所有函数参数均确定,函数返回值待定的函数。正向函数的执行过程即利用输入参数推导函数的返回值。逆向函数,即函数返回值确定,函数输入参数中存在待定参数的函数。逆向函数的执行过程即利用函数的返回值与确定的输入参数计算待定的输入参数。
函数权重用于控制推理系统的推理方向。用户可以为那些更容易导向正确推理结果的变换赋予更大的权重,不容易导向正确推理结果的变换赋予更小的权重。函数的权重在函数声明时确定,例如代码3中定义了一个权重为10的函数:
代码3具有权重的函数示例:
@(10){$a == b;}{
a = b;
}
1.2 变量
COOL的非临时变量在使用前必须被声明。变量的类型由最近一次所赋值的类型决定。默认类型为浮点数。变量从其被声明处至其所在作用域结束处之间均可被访问。一个表达式优先使用当前作用域的变量。用户可以通过使用“out”修饰变量以使表达式使用上层作用域的变量。例如代码4:
代码4“out”使用示例:
new:a = 1;
{
new:a=0;
a=out:a+1;
}
1.3 完整代码示例
求解以下数学问题:对两个数字量x,y依次进行以下操作:将x,y求和,结果记为a;修改x的值,使其满足x+1值等于y;求解变量z,满足z^2+x*z+y等于100;x,y,a求和,得到最终结果;求解问题的完整代码如代码5,最终结果为36.1005。
代码5完整代码示例:
/*定义求解二次方程的函数*/
@(100){a*$x^2+b*x+c}{
x=(-b+(b^2-4*a*(c-ans))^0.5)/(2*a);
}
/*定义加法的逆向函数*/
@(10){$a+b}{
a=ans-b;
}
@由(x)与(y)得结果{
new:a = x+y;
$x+1==y;
new:z=0;
1*$z^2+x*z+y==100;
return:a+x+z;
}=>@由($x)与(y)得结果;
new:x = 0;
new:y = 3;
由($x)与(y)得结果==50;
x-->0;/*“-->”表示输出,意为将x值以默认方式输出*/
企业发展需要员工具有较高的综合职业能力,包括创新意识和创新能力、组织执行力、交往与合作能力、学习与思维能力、独立性与责任感等,这就需要我们在教学过程中突出强化和渗透这种能力。
1.4 类
解决相似问题的规则可以单独封装成类,通过继承用户可以更灵活地复用、修改和拓展规则,实现对复杂问题的分治处理和程序的模块化开发。在COOL中类由声明和类的作用域组成,在定义一个类时可以使其继承其他的类以使用其成员函数和变量,如代码6所示:
代码6类继承示例
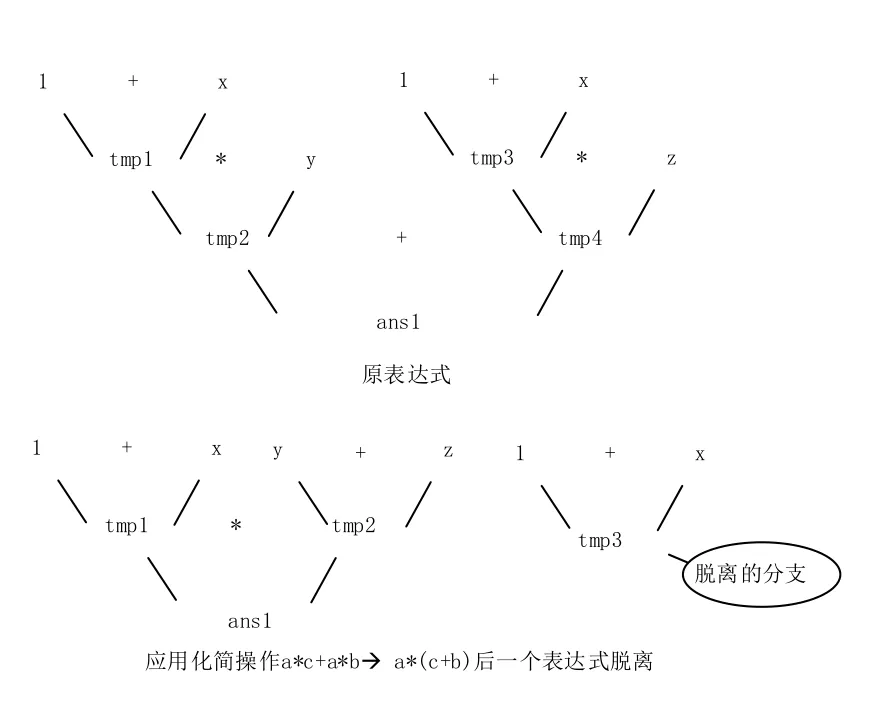
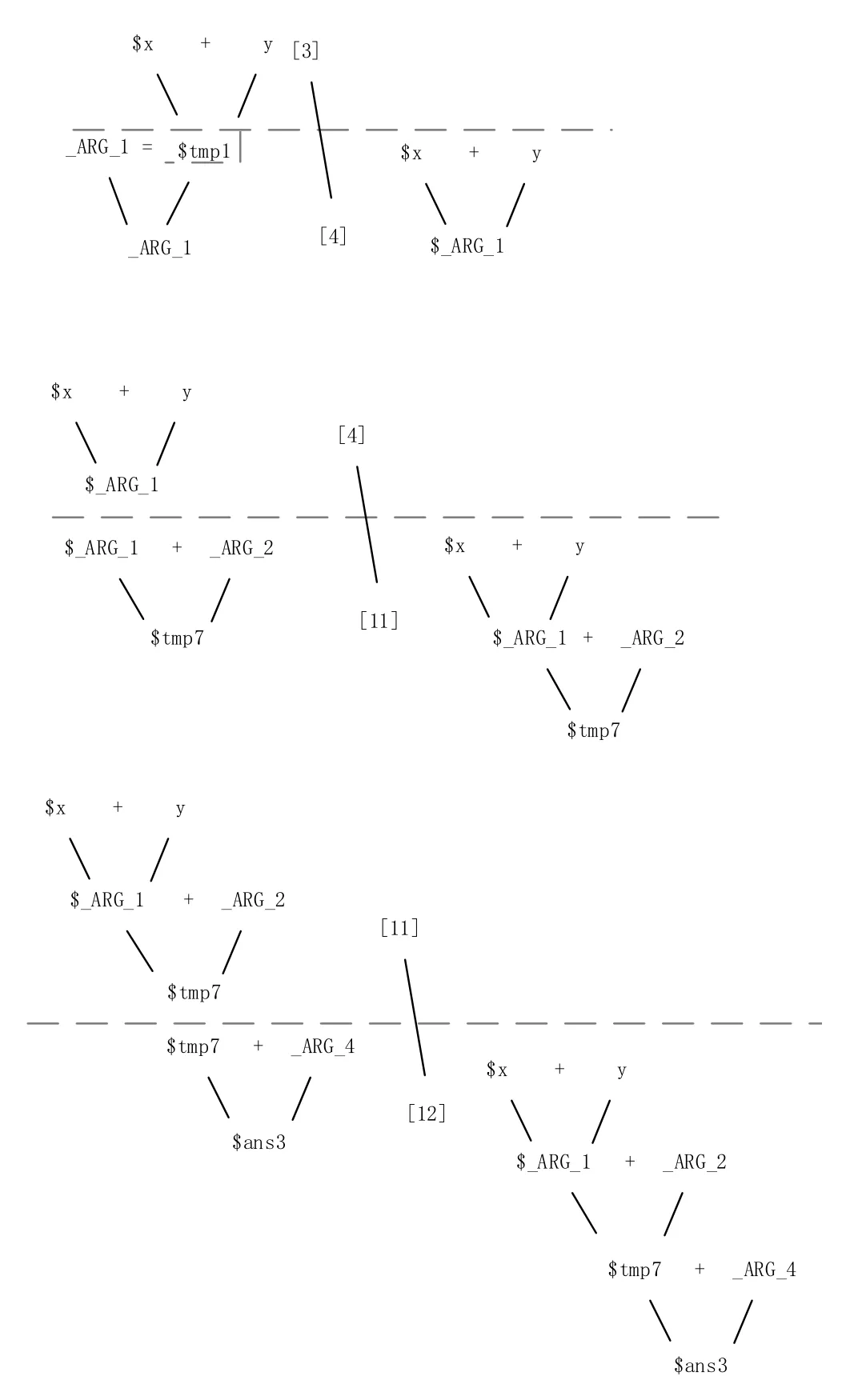
system:MainProcess< …… } 预编译过程中将源代码标识符中出现的非ASCII码替换为ASCII码字符串;同时,将所有函数参数移动至函数名字字符串后,并保持函数参数顺序不变,在函数参数原来位置用特定字符串(例如:“_Arg_”)代替形成新的字符串;例如add(A)and(B)to(C)在预编译后变形成add_Arg_and_Arg_to(A,B,C)。 通过词法分析程序与语法分析程序将预编译后的代码编译为字符码。字符码由三部分组成,包括代码类型标志位、四元式、四元式参数类型标志位数组。 代码类型及其所描述的功能包括变量声明(声明一个变量);函数操作(绑定函数声明作用域与函数体作用域,或绑定权重、返回类型与函数声明作用域);推导函数(根据指定的正向函数推导逆向函数的实现逻辑);域起始(表示作用域的起始);域结束(表示作用域的结束);表达式(表明此行代码的四元式是表达式的一部分,包括运算、函数调用、将属性(“$”“#”“out”)赋予变量);跳转(当一定条件跳转到指定代码继续执行);表达式结束(截断表达式);返回(从函数返回);成员访问(给计算机指明访问成员的路径);类操作(用于声明类、继承类、将类名与作用域绑定)。 四元式及四元式参数类型标志位数组:在代码类型为“表达式”时用于储存四元式的左运算对象、右运算对象、运算符、运算结果以及对应的数据类型;当代码为其他类型时仅用于储存参数。 四元式形参标志位数组:当代码位于函数声明作用域时有效,标识四元式中参数是否为形式参数;当代码位于函数声明作用域外时有效,标识查询四元式中对应参数是从当前代码所在作用域内开始查询(标志位为真)还是从当前代码所在作用域的上层作用域开始查询(标志位为假)。四元式参数待定标志位数组:用于标识在此行代码被执行时,四元式中对应参数的值是否待定,若参数待定(标志位为真),则此参数的值将被视作未知(或无效);若参数确定(标志位为假),则此参数的值将被视作已知条件;对于返回表达式的函数,由于很多情形下其代表的变换规则与变量是否待定无关,故允许其函数声明中的参数具有“待定”“确定”“无关”三种状态,相应地表示为真、假、无关三种值。绑定函数地址:用以标识代码所绑定的函数的地址;由于COOL中所有函数声明均储存为语法树形式,因此调用某个函数需要将此函数的地址与函数声明表达式进行绑定,在执行此行段代码时就会调用所绑定的函数。此地址在函数根结点标志位为真,说明此行代码对应所绑定函数的声明表达式的根结点,为假则对应子结点。 定义数据的表示格式a(b│c),表示数据a和 周期(匹配轮数)内被创建或赋值,在周期c内被使用;定义一种键值对的表示方式 (1)初始化 复制当前执行代码所在最长的表达式对应代码段e,获得以初始累计权重值0为键、复制代码段为值的键值对<0,e>;将复制代码段键值对添加至当前代码仓S;其中,S为一个以累计权重值为键、代码段为值的二维表; 代码仓的容量由用户设定,当尝试向一个已满的代码仓添加新键值对时,如果其键大于代码仓中最小的键,则代码仓删除键最小的键值对后再添加新的键值对;如果其键不超过代码仓中最小的键,则添加失败;此外,代码仓中不允许存在值完全一样的键值对。 (2)第k轮匹配 对于k∈N*,在当前代码仓S(k-1│k)不为空时,对于所有 代码段匹配函数,指将代码段对应的表达式exp1与函数声明表达式exp2进行比较,若exp1与exp2的语法树结构相同,且任取exp1的一个结点node1以及exp2中与node1对位的结点nod12,node1与node2均满足以下五种情况之一,则匹配成功:node1是具体值且node2是相同的值;node1是具体值且node2是类型相同的形式参数;node1是变量且node2是类型相同的形式参数;node1与node2是同一个变量。当fun代表的是一个化简操作,在进行代码替换后,可能产生脱离表达式语法树的代码片段,如1中所示。 图1 分支脱离表达式语法树示例 当fun代表的是一个化繁操作,则在使用返回表达式的函数进行代码替换后,表达式的语法树可能产生环状结构(例如变换(a+b)*(x+1)→a*(x+1)+ b*(x+1)在语法树只有一个x+1分支的时候会导致a*(x+1)和b*(x+1)引用同一个x+1分支的根结点,产生了环状结构);如2中所示: 图2 表达式语法树形成环状结构示例 因此每当代码替换后都需要查找并删除代码段中脱离表达式语法树的代码片段并展开生成的环状结构。 (3)匹配结束条件 当ej满足所有代码均与函数绑定时,匹配过程以成功结束,用ej替换掉当前执行代码所在最长的表达式对应的代码段;否则将 当匹配轮数k超出用户规定上限时以失败结束;当本轮和下一轮均无可用元素参与匹配时以失败结束: 图3展示了在预执行结束后表达式与函数的绑定情况。 图3 代码段21预执行后表达式与函数的绑定效 当代码类型标志为“推导函数”时,利用指定的正向函数推导逆向函数的函数实现,依次执行以下步骤: (1)将正向函数的函数体代码段拆解为代码块 代码块,由序号、代码段、代码块信息组成,越早创建的代码块序号越小;代码块信息包括:代码块类型,反映代码段中代码的类型;代码块依赖待定输入参数标志位,反映代码段中是否存在依赖待定输入参数的变量。变量依赖于待定输入参数,指的是在正向执行函数体代码的过程中,确定待定输入参数的值是确定此变量的值的必要条件,反之则独立于待定输入参数。 拆解过程需从前向后逐行分析正向函数的函数体的每一行代码,若当前分析代码的可执行标志位为假,跳过;若为真或“一定条件下执行”,根据代码类型执行以下步骤,a域起始:创建代码块,类型为“域起始”,依赖待定输入参数标志位为假,代码段为当前分析代码;将其加入代码块队列B中;b域结束:创建代码块,类型为“域结束”,依赖待定输入参数标志位为假,代码段为当前分析代码;将其加入代码块队列B中;c表达式结束:跳过;d表达式:若函数根结点标志位为假,跳过;否则,复制当前代码所在函数调用表达式对应的代码段,并对此复制代码段依次执行操作创建代码块;f返回:创建代码块,类型为“返回”,依赖待定输入参数标志位为假。由于逆推时返回值已知,故在代码段中将正向函数返回值ans赋予被返回的变量,同时将代码类型“返回”修改为“表达式”;最后将代码块加入代码块队列B中;g其他情况:创建代码块,类型为“默认”,依赖待定输入参数标志位为假,代码段为当前分析代码;将其加入代码块队列B中。 (2)利用代码块推导逆向函数的执行过程 a将B中的代码块根据是否依赖待定输入参数,重组为依赖待定输入参数代码块队列Bdependent,和独立于待定输入参数代码块队列Bindependent,重组的两个队列中代码块根据序号从小到大排列;b当Bdependent不为空时,通过动态规划算法进行逆推。 所采用的优先顺序,具体为待定输入参数的必要变量数目越少越优先,依赖关系树的结点数越少越优先。其中,依赖待定输入参数的必要变量,即依赖待定输入参数、且同时被依赖关系树的结点和Bdependent中代码块使用的变量,否则依赖待定输入参数的非必要变量;例如对于依赖关系树T1={[12],[11]},变量$_ARG_1为依赖待定输入参数的必要变量,因为其在代码块[4]中被使用,变量$tmp7和$ans3则属于非必要变量,因为其仅在T1中被使用。将依赖关系树的各个结点重新合并成代码段,具体为从依赖关系树的末端叶结点开始,不断将叶结点代码块的代码段合并到其父结点的代码段,并从树中移除合并成功的叶结点,直至依赖关系树只有一个根结点,此时依赖关系树合并成功。 图4展示了将依赖关系树T={[12],[11],[4],[3]}合并至根结点[12]的过程: 图4 依赖关系树T合并至根节点的过程 若依赖关系树合并成功,记原依赖关系树为Torg,合并得到的依赖关系树为Tfinal,Tfinal只有一个结点[root]final,对[root]final的代码段进行函数匹配与绑定。 若匹配与绑定成功,则将[root]final从后端压入逆向执行代码块队列Bback;由于[root]final的代码段在被执行后,Torg中所有的待定的变量均被确定,因此在进行下一轮逆推之前,需要将Torg中所有结点从Bdependent中移除,并更新Bdependent中其他代码块的待定变量,若其代码段语法树中使用了Torg中的待定变量,则将此待定变量改为确定变量。若失败,则重新执行b-2,由代码块队列B所逆推得到的函数体,如图5中所示。 图5 由 B逆推得到的函数体 预执行过程仅根据语句创建变量以保证参数环境正确而不进行实际的函数调用与运算,此过程中所有代码最多只被执行一次,相较同时进行执行和推理,避免了一个问题可能被多次推理的可。 此过程执行预执行生成的拓展代码表。宏观上程序仍由前向后执行,但由于逆向函数与正向函数的引入,局部代码段的执行顺序并不一定与宏观上的执行顺序一致。对于一个最长表达式对应的代码段,执行时先正向依次执行其中的正向函数,再反向执行其中的逆向函数,如表1所示。 表1 包含正向、逆向函数调用的代码段的执行顺序示例 本文所提出的编程语言COOL开创性地允许将复杂的表达式作为函数声明,相较已有的逻辑编程语言拥有更强的数学表达能力,并可以描述更复杂的问题。COOL提供了利用函数正向执行过程进行逆向推理的功能,相较已有的逻辑编程语言,减轻了用户逆推问题的负担。COOL支持面向过程与面向对象,相较大多数的逻辑编程语言,规则的使用和管理更简便。2 编译
2.1 预编译
2.2 代码类型
3 预执行
3.1 加载字符码
3.2 推理过程



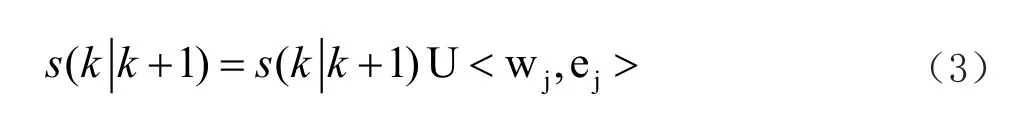
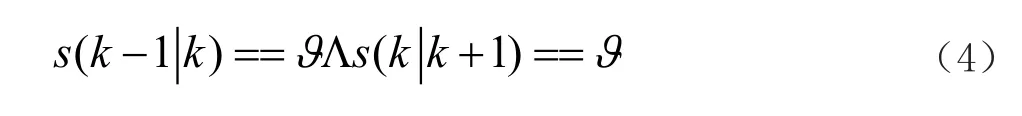

3.3 推导函数

4 执行

5 结语
