物联网环境下的数据库隐私保护技术研究进展
2022-02-15万利永
万利永
(江西软件职业技术大学 江西 南昌 330041)
0 引言
基于物联网环境下,人们为了增强信息数据的利用效率,通常是采用亚马逊、阿里云等云服务商进行数据信息处理,这样使得数据所有权和使用权处于分离状态,在数据利用过程中输出、输入、储存等各环节都成为隐私数据泄露的风险源,并且隐私数据的生成者并没有主动参与的隐私保护中,仅依靠被动式的隐私保护和数据收集者的隐私保护,加之信息数据集之间会存在一定的关联性,会对隐私保护造成较大的难度,文章重点从数据库隐私来探究了隐私保护技术,希望借助完善的隐私保护技术来推动物联网技术的高质量发展。
1 物联网环境下的隐私保护概念
1.1 定义及分类
1.1.1 定义
隐私通常是指用户不愿意公开或者让其他人知道的个人秘密,在互联网时代,隐私信息的泄露问题随着互联网技术的发展及物联网技术的广泛应用而变得越来越严重;人们在进行网站信息查询、网上购物、发送电子邮件等网络操作的时候均有可能在不经意间泄露个人隐私[1]。针对越来越严峻的隐私泄露问题,一方面要保护涉及个人隐私的数据的安全,另一方面也要保证网络的正常、健康、稳定发展,隐私保护技术能够借助隐私度量进行相关风险披露,让用户能够合理地选择信息数据应用程度,从而达到网络技术深度运用和用户隐私安全的平衡点[2]。
1.1.2 分类
根据数据本质特性因素,可以分为个人隐私和公共隐私。个人隐私主要包括个人基本资料、网络资料、邮箱信息、工作信息、健康信息、财产状况等。公共隐私主要是指有代表性的群体的共同特征信息,如政府的一些统计信息、趋势分析等。根据研究对象的不同,可分为数据隐私、位置隐私及身份隐私[3]。数据隐私主要是指数据所包含的隐私信息。位置隐私是指通过统计分析、聚集相关数据而获取的关于个体的位置状况信息。身份隐私是指通过综合分析个体的财产状况、购物习惯、出行时间、线路而推断得到的身份信息。
1.2 隐私度量
物联网技术实现了智能设备、计算机终端、移动设备等多通信设备的互联,让人们更容易享受到通信技术带来的便利和功能优势,但在信息数据传递中也会造成隐私数据的泄露威胁,隐私度量是为了合理地评估个人的隐私水平,这样有助于隐私保护技术更易达到预期的防护密度,不同的隐私保护需求就会存在对应的度量指标,主要分为数据库隐私、位置隐私、身份隐私三类[4],文章主要研究了数据库隐私保护。数据库是一个信息数据集合的存在,在数据库隐私保护技术应用中,需要从数据库的应用需求和隐私保护程度两个方面入手,首先在数据应用上,可以根据数据质量评判,以数据丢失程度、原始数据相似度等指标度量。其次,在隐私保护程度上,需要明确隐私保护范畴,将不同的信息数据保护程度进行有效隔离,可以借助风险披露进行数据分离,用户在数据库使用中,可以根据风险等级来进行相关信息数据的输入和读取,风险等级越高,则泄露风险越大[5]。
2 物联网环境下的数据库隐私保护技术
2.1 数据库的隐私威胁模式
现阶段,隐私保护技术主要是在数据采集和数据发布两个层面来实现数据库隐私保护,让数据库能够在安全的环境下进行数据信息采集和信息输出,如图1所示,展示了数据采集和数据发布的应用场景。在数据采集阶段,数据发布者在用户A.B.C处获取到隐私数据,并将数据传输到数据接收者,以网络平台购物为例,电商平台作为数据发布者,将用户A的账户、密码隐私数据进行收集,并传递给支付平台(数据接受者);在这个流程中,基于不可信计算模式,数据发布者是不可信的,它可能会通过多种途径从用户那里获取敏感数据,其中包含隐私数据,在可信计算模式中,数据发布者是可信的,用户也愿意将隐私数据提供给数据接收者,但数据接收者不可信。如支付平台在采集大量的账户、密码过程中,出现账户泄露问题,而账目数据是用户不愿意泄露的隐私数据[6]。
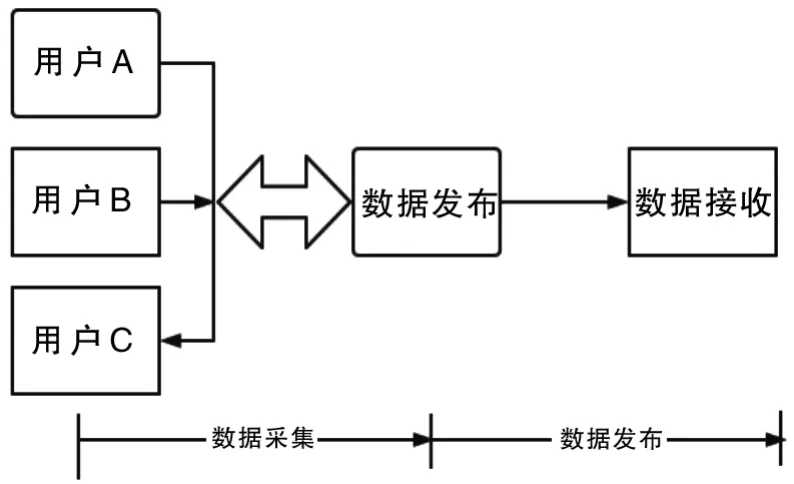
图1 数据采集和数据发布
2.2 数据库隐私保护技术
隐私保护技术是为了有效地解决数据发布者及数据接收者可能出现的数据泄露问题,在具体的实施中需要考虑到:一是隐私数据是数据库输入和输出过程中不被篡改、泄露;二是在增强数据库隐私数据保护的同时,也需要提高隐私数据利用效率,不能出现顾此失彼现象。在技术分类上,分为数据失真技术、数据加密技术、限制发布技术[7]。
2.2.1 基于数据失真的隐私保护技术
数据失真技术指的是将私密数据进行失真处理,如添加噪声、信息交互等造成原始数据的扰动,从而达到隐私数据的保护目的,在进行数据失真处理时,首先需要确保攻击者不能识别真实隐私数据,即攻击者难以通过数据集、关联知识推理出真实数据。其次要确保原始数据的属性,让数据性质不发生变化。在实际应用中,通常采用随机化扰动技术来实现数据失真:x1随机扰动:通过采用随机化技术(随机添加噪声、信息交互)来修改真实数据,将真实数据进行有效隐藏,让攻击者难以找到原始数据,从而完成隐私数据的保护。如图2所示,攻击者只能查获扰动数据。

图2 数据扰动过程
2.2.2 数据加密的隐私保护技术
(1)分布式匿名化
匿名化指的是对隐私数据的信息和来源进行隐藏,通过匿名化处理后,数据库在进行隐私数据的采集或者发布过程中,隐私数据处于匿名化状态,这样极大地降低了隐私数据的被攻击的风险,进而提高隐私数据的安全性。分布式匿名化在信息通信过程中,为了保证隐私数据的利用效率,是基于垂直划分的数据环境下实现两方分布式匿名化,并以k-匿名为例来说明,在信息隐藏中以“是否满足k-匿名条件”来判断原始数据匿名[8]。
(2)分布式聚类
分布式聚类的关键是安全地计算数据间的距离,聚类模型有Naive聚类模型(K-means)和多次聚类模型,两种模型都利用了加密技术来实现信息的安全传输[9]。①Naive聚类模型:数据节点将隐私保护方式传输给可信任的第三方,然后第三方对原始数据进行数据加密,聚类后反馈相关处理结果。②多次聚类模型:数据节点对原始数据进行聚类处理,并发布结果,各节点在根据隐私保护需求对聚类处理结果发布,进行二次聚类处理,从而形成分布式聚类。
2.2.3 限制发布的隐私保护技术
限制发布指的是将隐私数据进行分类,根据风险披露等来针对性地发布或者不发布数据,从而起到隐私数据保护的作用。现阶段,匿名化处理技术是限制发布的隐私保护技术的关键技术,通过结合风险披露等级和隐私数据保护程度,进行部分隐私因素的匿名化处理,达到一个折中的效果,既能满足隐私数据的使用,也确保隐私数据泄露风险处于预期范围内。以学校考试成绩公布为例,在原始数据上会存在姓名、年龄、专业、成绩分数等主要隐私数据,通过传统隐私数据保护,会将姓名进行※保护,但经过攻击者关联数据推理,会容易得到原始完整数据,经过分布式匿名化算法匿名化处理,会将原始记录映射到特定的度量空间,再对空间中的点进行聚类匿名。类似k匿名,算法保证每个聚类中至少有k个数据点在r-gather算法中,以所有聚类中的最大半径为度量对所有数据点进行聚类,保证每个聚类至少包含k个数据点。如在姓名上会出现数字标识、年龄呈现出区间数值,这样使得攻击者难以根据关联数据识别获取隐私数据[10]。
3 基于数据扰动的分类数据采集隐私保护技术
基于数据扰动的分类数据采集隐私保护技术在具体应用中,首先是给原始数据集的各属性域构建一个随机扰动矩阵,并给定一个转移概率,其次再根据转移概率值将原始数据集中的值进行转换操作,最后构建原数据分布,并进行分类采集。在数据预处理中,是通过属性域编码表进行,便于生成离散数据。在转移概率值设定中,可以引入矩阵条件数、r-amplifying方法减小重建原数据分布的错误率,采用决策树分类,整个过程分为数据预处理、数据扰动、分类数据采集三个阶段,基本框架如图3所示:
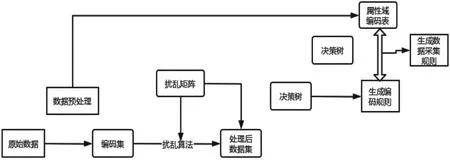
图3 分类数据采集隐私保护基本框架
3.1 数据扰动算法
3.1.1 数据预处理
首先要对数据进行预处理,才能实现原始数据的转换操作,本次采用的是平均区域划分方法进行数据离散处理,如式(1):

length=离散区间长度 A=连续属性n=离散数
在具体计算中,以A1为第一个离散值开始,进行(1)离散区间长度计算,结果采用四舍五入计,最后以0结束。
属性域编码是对离散数据集中各属性域值进行查询,并对这些不同的属性域值进行重新编码,进而生成属性域编码表。
数据集转换成编码集时将离散数据集的属性值用对应的编码来代替,替换后形成编码集。
3.1.2 单属性随机扰动矩阵
单属性随机扰动矩阵的值体现着属性域值的转化概率,单属性随机扰动矩阵的应用关乎着隐私数据保护的程度和精准度,可以说是整个隐私保护技术的关键内容。本方法选择r正定对称矩阵为单属性扰动矩阵。首先要求用户给定每个属性的阈值前验率a1和后验率a2,要求0<α1<α2< 1,并在a2(1-a1)/a1(1-a2)>r≥ 1 随机取个r值,生成任意属性A的扰动矩阵。
3.1.3 数据扰动
数据扰动是各属性值根据对应的转移概率值转换后形成的其他值,在本次扰动中首先给定编码数据集,再通过扰动算法进行扰乱。
3.2 测试与结果分析
3.2.1 实验环境
(1)开发环境:WindowsXP操作系统17 Hz主频,2 B内存320 GB硬盘
(2)开发工具:Eclipse-SDK-3.4.1,SQL Server 2000。
(3)开发语言:Java。
3.2.2 实验数据
实验数据采用学生考试成绩,通过分类数据采集隐私保护技术在数据集隐私保护的前提下,找出判断是否及格的规律,以下从隐私保护度和挖掘精度两个方面对该方法进行考察[11]。
3.3 测试结果
隐私保护度用1/(a2-a1)来表示,其中,a1为用户前验率,a2为后验率。如图4所示,随着数据集的增加,采集精准度越高,越来越接近真实的数据水平。
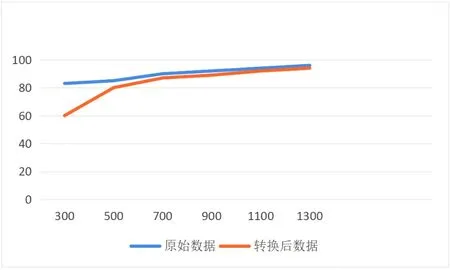
图4 精度和数据量的关系
4 结语
综上所述,物联网环境下网络隐私保护主要包括位置隐私、身份隐私、数据库隐私三类,随着物联网技术发展,数据库增量信息会呈现出阶梯式上升,数据库的隐私数据使用效率和保护技术都会成为影响物联网技术发展的重要因素。文章以数据库隐私保护为例,提出基于数据扰动的分类数据采集隐私保护技术研究,希望以此来满足数据库隐私保护需求。
