基于GAN的雷达HRRP数据增强方法
2022-02-14王彦华宋益恒
周 强 王彦华 宋益恒 李 阳
(1.北京理工大学信息与电子学院雷达技术研究所,北京 100081;2.嵌入式实时信息处理技术北京市重点实验室,北京 100081;3.北京理工大学重庆创新中心,重庆 401120)
1 引言
雷达自动目标识别(Radar Automatic Target Recognition,RATR)是一种根据目标的雷达回波来判断其类别的方法。高分辨距离像(High Resolution Range Profile,HRRP)[1]代表了目标散射中心在雷达视线上的分布[2]。由于HRRP 的获取不需要目标与雷达间的相互运动,对存储和处理资源的占用较低,因此基于HRRP 的RATR 方法有重要的研究和应用价值。
在众多基于HRRP 的RATR 模型中,数据驱动模型能够有效地根据已有数据从特征空间中确定决策边界[3]。然而,得到一个准确的决策边界往往需要足够多的训练数据,这限制了数据驱动模型在某些关键场景中的应用。例如,由于HRRP 具有很高的时移敏感性[4]并且HRRP 的采集场景具有不确定性,因此,为非合作目标或者复杂环境下目标构建完整数据集会十分困难。数据增强方法可以利用现有数据的多种变换(如裁剪、填充、反转和噪声注入等经典方法)[5]来提高数据的多样性,已经成为了开发数据驱动模型过程中必不可少的步骤。然而,在特征层面上,经典方法无法对不完备数据集的固有信息进行扩充。
近年来,生成对抗网络(Generative Adversarial Network,GAN)[6]为人工合成数据提供了一种有效的框架[7]。GAN 是一种深度生成模型,能够利用深度神经网络在给定数据集上拟合其分布,并生成与给定数据分布相一致的人工样本,拓展不完备数据集的固有信息。在光学图像分类[8]、SAR 和ISAR 目标识别领域[9],GAN 已经被用于数据增强。在HRRP 领域,Song 等人[10-11]提出了基于DCGAN 的HRRP 生成方法,用于不平衡数据的处理,证明了GAN 能够生成足够真实的HRRP 数据,所提出的不平衡处理框架的性能优于最新的过采样方法。
基础生成对抗网络(Basic Generative Adversarial Network,BGAN)用于数据增强时,需要利用各类别样本分别对网络参数进行训练,得到能够生成对应类别样本的多组模型。而条件生成对抗网络(Conditional Generative Adversarial Network,CGAN)通过向生成器中引入条件标签项,可以在一个GAN 模型下生成不同类别样本数据,从而在一组模型下完成数据增强任务。本文分别设计了一维BGAN 和CGAN 网络结构,通过在现有地面车辆目标HRRP数据上进行训练,以获取生成各类别下具有多样性的HRRP 样本的能力。然后,利用训练好的生成器来生成HRRP 样本,作为现有HRRP 数据的补充,得到HRRP 增强数据集。最后将BGAN 和CGAN 的增强效果与HRRP 传统的时移[12]和镜像增强方法[13]进行比较,结果表明基于BGAN 的HRRP 数据增强方法有效地提升了目标识别的准确率,基于CGAN用于数据增强能够在保证识别率提升的同时降低模型的时间与空间复杂度,提升效果要优于传统的平移和镜像增强方法。
本文内容安排如下:第2 小节介绍了GAN 的基本原理,第3 小节详细介绍了所提一维BGAN 和CGAN 的结构,第4 小节展示了增强数据的可视化和对比试验的结果,第5小节是对全文的总结。
2 GAN基本原理
GAN 是一个生成网络模型,可以通过深度神经网络的拟合能力来学习真实数据集的样本分布。经过良好训练的GAN 可以生成与真实数据集具有相同分布的人工样本。图1 展示了GAN 的结构,GAN 由一个生成器(G)和一个鉴别器(D)组成,并且G 和D 均由多层神经网络结构组成。G 从隐空间z中采样,并通过前向传播输出生成的样本x’。D的输入是从G 生成的样本x’和真实数据集中的真实样本x,并通过正向传播输出判别结果。
GAN 的训练过程可以看作是G 和D 的极大极小二人博弈。D的目标是最大程度地提高分类准确度,以尽可能地将生成的样本x’与原始数据集中样本x区分开。因此,在训练判别器时,其损失函数可以表示为:
具体地,在训练D 时,我们固定G 的参数,最小化损失函数d_loss:
对于上式我们有pdata(x) ≥0,pg(x) ≥0,因此当D(x)=pdata/(pdata+pg),上式取极小值,其积分值也取得极小值,此时D为最优的判别器。
G 的目标是使D 犯错误的可能性最大化,也就是说,D 错误地认为x’是原始数据集中的真实样本,而不是生成器生成的伪样本。因此,训练生成器时,其损失函数可以表示为:
即在已训练最优D(x)=(x)=pdata/(pdata+pg)的情况下,最小化损失函数g_loss:
对于上式我们有pdata(x) ≥0,pg(x) ≥0 上式当且仅当pdata(x)=pg(x)时取得最小值。因此G 优化至最优解时,pdata(x)=pg(x),D(x)=pdata/(pdata+pg)=0.5。此时,判别器无法判别数据的真伪,对生成数据和真实数据的判别准确率均为50%,最优生成器所产生的数据概率分布与真实概率分布相一致。因此,经过G 和D 的对抗训练,GAN 最终可以达到Nash平衡。在这种情况下,生成的数据空间等于实际样本空间。
可以根据GAN 这一特性,对现有数据集进行隐式建模,学习真实样本分布,并对所构建模型进行重采样即可生成与真实样本同分布的新样本,如下图2所示。因此,利用生成样本进行数据增强,能够生成与给定数据分布相一致的人工样本,拓展不完备数据集的固有信息。
3 基于GAN的HRRP数据增强方法
图3 展示出了所提出的数据增强方法,其包括两个主要部分,即GAN训练过程和增强过程。
在GAN 训练过程中,根据HRRP 的特点,我们提出了可以很好地适合一维HRRP 数据的GAN 结构,G 和D 均由四个全连接层组成,以确保网络具有足够的拟合能力。GAN 的具体结构如下:
指定G 的输出尺寸和D 的输入尺寸,使其与HRRP尺寸一致。
G 和D 中隐藏层的激活函数为线性整流单元(Rectified Linear Unit,ReLU)。
G和D输出层的激活函数均为Sigmoid函数。
在G的每个隐藏层中使用批量归一化。
图4 展示了所提一维BGAN 与CGAN 网络示意图,二者区别在于CGAN 的生成器输入增加了虚线框内的类别标签。对于BGAN,利用各类别的HRRP 数据分别对网络参数进行训练,得到能够生成对应类别样本的多组模型。对于CGAN,利用全类别的HRRP数据和对应的类别标签同时对网络参数进行训练,得到受类别标签控制的能够生成全类别样本的一组模型。
在增强过程中,利用经过良好训练的生成器生成HRRP 样本作为现有HRRP 数据的补充,得到HRRP 增强数据集。最后利用卷积神经网络(Convolutional Neural Networks,CNN)分类器的F1 分数[14]来评估BGAN 和CGAN 增强的改进。F1 分数结合了查全率和精确度,可以更好地反映分类器的性能。
4 实验结果与分析
为验证BGAN 和CGAN 的增强效果,本文利用现有HRRP数据集进行了数据增强实验。首先在现有HRRP 数据集上完成二者的训练,并对训练过程和生成效果进行了可视化。然后利用数据驱动模型(卷积神经网络)进行了二者和传统方法增强效果的对比试验。下文将对实验流程和结果进行详细的介绍与分析。
4.1 实验设置
实验使用四种类型地面车辆目标的HRRP数据。每种目标包含5000 个样本,四类目标共20000 个样本,其中16000 个样本用于训练,其余4000 个样本随机分为测试集和验证集,具体如表1所示。
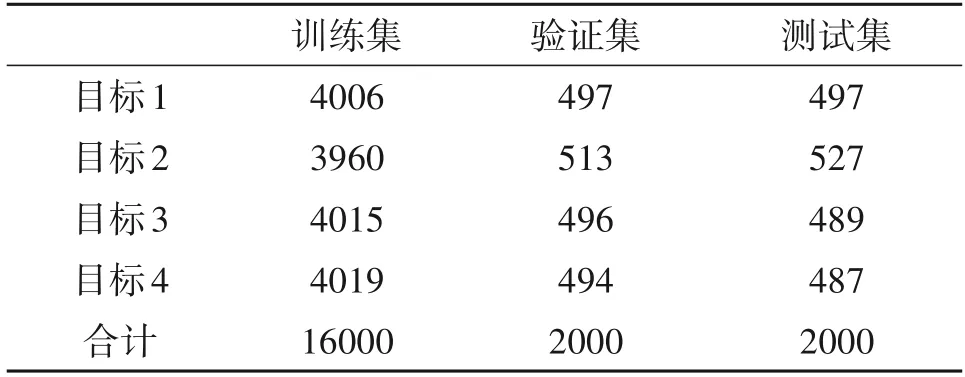
表1 数据集划分情况Tab.1 Detail of data set division
在实验进行之前,首先要对数据进行预处理。预处理包括HRRP 数据的截取和归一化。经过预处理后,四种目标的HRRP 示意图如图5 所示。
4.2 训练过程可视化
图6 展示出了所提BGAN 和CGAN 在训练集上训练之后鉴别器和发生器的损失函数的值。对于二者,判别器损失越小表示判别器在区分样本时的性能越好,生成器损失越小表示生成的样本的质量越好。同时考虑图6 中的判别器损失和生成器损失,可以看出经过1500 次迭代训练之后,生成器和判别器的损失处于较低水平并且趋于稳定,这表明二者网络此时已经收敛,生成器可以产生高质量的样本。
图7 展示了GAN 生成的HRRP 数据与原始HRRP 数据之间的比较。可以直观地看出,GAN 生成的HRRP具有足够的真实性。
4.3 t-SNE降维结果对比
t分布随机近邻嵌入(t-SNE)[15]降维方法通过二维或三维点对每个高维对象进行建模,其主要机理是令相似的高维对象降维后相互接近,而相异的高维对象在降维后相原理。
图8 展示了t-SNE 降维方法对HRRP 数据集、BGAN 增强数据集和CGAN 增强数据集的可视化结果。可见,相较于训练集,增强数据集降维后的边界更清晰,对于识别更加有利。
4.4 对比实验结果
在对比实验中,本文采用CNN 评估各增强方法对数据驱动分类器性能的改善。首先,在HRRP 原始数据集、时移增强数据集、镜像增强数据集、BGAN 增强数据集和CGAN 增强数据集上分别训练相同结构的卷积神经网络CNN。之后利用训练好的CNN 在测试集数据上进行测试,各数据集上的分类混淆矩阵如图9 所示。其中其第i行第j列元素mi,j定义为测试样本真实标签yreal=i,预测标签ypredict=j的样本数目,即:
对分类混淆矩阵计算其F1 分数,结果如表2 所示。在HRRP原始数据集上,由于目标特征不完整,CNN 的F1分数最低。经过时移、镜像或CGAN 增强后,F1 分数有了一些改进。而在BGAN 增强后,各种样本的F1分数达到了实验中的最佳水平。
观察表2可以发现,目标2与目标3的识别率较低,若使用BGAN 和CGAN 单独对这两类目标进行增强,则得到结果如下表3。可见,BGAN 和CGAN均能有效提升目标识别的准确率,提升效果优于传统的平移和镜像增强方法,基于BGAN 的HRRP 数据增强方法提升效果最优。

表2 各个测试集上的F1分数对比Tab.2 Comparison of F1-scores on each test set
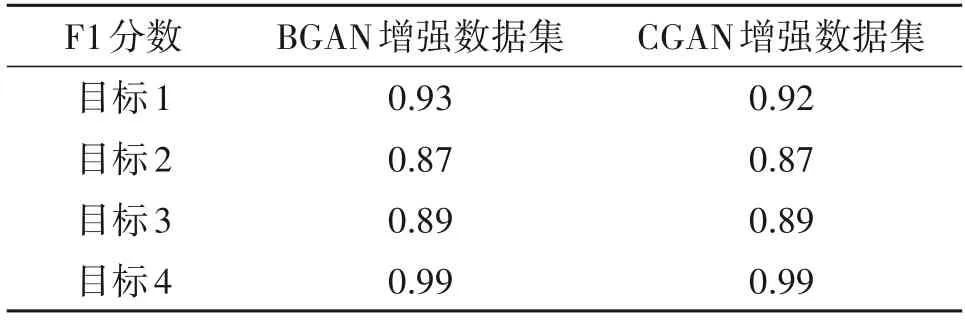
表3 BGAN和CGAN测试集上的F1分数Tab.3 F1-score on the BGAN and CGAN test sets
分别用BGAN 和CGAN 模型大小和生成数据耗时进行空间与时间复杂度评估,结果如表4 所示。可见,BGAN 用于数据增强,其模型的空间复杂度与样本类别数成正比;而且在对各个类别进行增强时,需要分别载入模型参数,因此BGAN的时间复杂度比CGAN 更高。因此,在应用时不考虑资源占用的情况下,基于BGAN 的数据增强的效果比现有方法有明显提升;如果考虑到模型的资源占用,CGAN能够在保证识别率提升的同时降低模型的时间与空间复杂度,具有较高的应用前景。
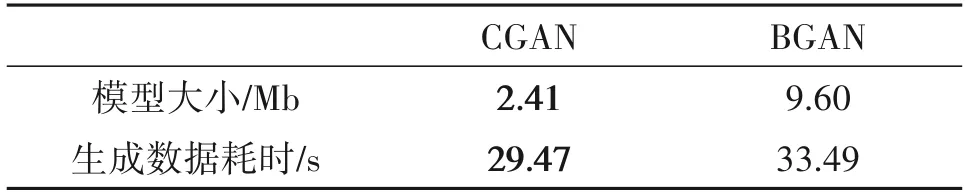
表4 CGAN与BGAN模型复杂度对比Tab.4 Comparison of CGAN and BGAN model complexity
5 结论
数据增强是提高数据驱动模型性能的重要方法,本文提出了用于HRRP 数据增强的一维BGAN模型和CGAN 模型。首先,根据HRRP 的特点,本文提出了可以很好地适合一维HRRP 数据的BGAN 和CGAN 结构,并在现有HRRP 数据上进行训练达到了收敛。然后,利用训练好的生成器来生成高质量的人工样本补充现有HRRP数据,完成了数据增强。最后,使用可视化和CNN 分类方法来主观和客观地评估对基于BGAN 和CGAN 的HRRP 数据增强。结果表明,BGAN 和CGAN 均能有效提升目标识别的准确率,基于BGAN 的HRRP 数据增强方法提升效果最优,并且其增强效果要优于传统的平移增强和镜像增强方法;基于CGAN 的数据增强能够在保证识别率提升的同时降低模型的时间与空间复杂度,具有较高的应用前景。
