基于生成对抗网络与深度学习的少数据云资源预测
2022-02-13陈基漓张长晖谢晓兰
陈基漓, 张长晖, 谢晓兰*
(1. 桂林理工大学信息科学与工程学院, 桂林 514004; 2.广西嵌入式技术与智能系统重点实验室, 桂林 514004)
在云资源计算领域中,云资源预测是一个重要的研究领域,通过对云计算资源的长/短期预测,可以降低资源抖动的概率,从而实现计算平台的安全运行[1]。长期以来,云资源预测的研究就受到中外学者的广泛重视,然而现实情况较为复杂,导致预测结果的准确性较低。因此,实现云资源较高精度的预测是所有学者面临的一大挑战。
云资源数据是时间序列样本的一种,对于时间序列样本的传统预测研究中,主要有两种方法:一是物理模型方法,二是统计学方法[2]。由于实际云资源数据具有波动性和随机性,常规的物理模型在预测上存在很多干扰因素,预测难度大。统计学方法预测过程中受到不少复杂因素的影响[3],其预测精度同样有限。
近年来,随着人工智能的发展,深度学习和机器学习算法已经成为了时间序列数据预测的研究热点。人工智能算法具有良好的参数学习能力以及非线性数据拟合能力[4],随着机器学习和深度学习的技术在图像处理以及语音识别等领域的逐渐成熟,其思路和方法技术逐步被应用到多个领域时间序列的预测研究中,主要包括:反向传播神经网络(back propagation neural network, BPNN)[5]、支持向量机(support vector machine, SVM)[6]、随机森林(random forest,RF)[7]、极限学习机(extreme learning machine,ELM)[8]和长短期时间记忆网络(long short-term memory network, LSTM)[9]。
文献[10]建立了改进BP神经网络模型进行云资源预测,但是BP神经网络模型结构过于简易,存在的缺点有:①参数权重繁多和学习速度慢,迭代时间过长,容易出现梯度爆炸或者梯度消失的现象;②容易出现过拟合现象,泛化能力低下,即训练集的预测效果良好,但在测试集中的预测效果很差;③陷入局部最值,在训练过程中梯度下降到局部极小值点就停止迭代,无法跳出局部最优。文献[11]提出了一种自适应神经网络的云资源预测模型相对于BPNN模型,自适应网络算法的学习速度较高且泛化能力强,但是其预测结果并不稳定,非线性拟合能力不高。单一的算法模型存在自身的局限性,很难有较高的预测准确率,因此许多学者对传统算法模型进行改进,从而达到提高预测精度的目的。文献[6]使用卷积神经网络和支持向量机建立了云资源预测模型,经卷积神经网络处提取空间关系后的数据,加强了SVM的数据拟合能力以及泛化能力,提高了模型训练的预测精度,但是SVM仍然对原始数据中存在的噪声比较敏感,一旦噪声明显则模型训练的效果较差。此外,巨大数据量的样本会使得SVM的计算过程变得困难。
以往关于云计算资源的预测研究中,不少算法模型在一定程度上有着较高的预测精度[12],但是在数据匮乏的情况下,原本的算法模型精度明显下降。对于资源数据相对较少的情况下,数据的匮乏将会很大程度提高算法模型的训练难度,降低模型预测的准确率[13]。在电气领域,文献[14]使用生成对抗网络对变压器数据这类时序样本进行学习扩充,在得到高质量的虚拟数据后,因少样本数据造成的预测精度低下的问题得到明显改善。现借鉴已有生成对抗网络(generative adversarial network, GAN)技术,提出在云计算资源的预测研究中使用生成对抗网络对云资源数据进行学习扩充,同时,针对传统循环神经网络无法全面利用数据时间相关信息这一局限性,使用双向门控循环单元网络作为预测模型,从前向和反向两个方向提取数据的时间相关性,以期提高模型预测性能。
1 WGAN模型
1.1 GAN模型
GAN算法作为一种典型的无监督深度学习方法[15],已被广泛应用于解决图像处理、特征提取和模型识别等问题。在GAN框架中,生成模型和判别模型相互博弈,产生最优的数据结果[16]。生成模型用于提取真实数据样本中潜在的复杂分布并生成虚拟样本,并使用判别模型来识别输入是来自真实样本还是虚拟样本。生成模型和鉴别模型通过“最小-极大”博弈不断优化,分别提高生成器生成数据的能力和判别器判断数据真假的能力[17]。GAN的基本架构如图1所示。
生成模型生成的真实样本x和虚拟样本G(z)都可以作为判别模型的输入。如果输入为G(z),则将判别模型的输出标记为“0”。如果输入是真实样本x,则将判别模型的输出标记为“1”。生成模型的主要目的是模拟真实样本数据的复杂分布,以达到“欺骗”判别模型的目的[18]。因此,生成器和判别器之间的博弈实际上是一个动态的游戏。在最理想的状态下,生成器可以生成虚拟样本,而判别器很难判别生成器所生成的样本是否为虚拟的[19]。
判别模型的目标函数易于定义,当输入为x和G(z)时,判别模型的输出分别对应于1和0。判别模型的训练过程基于交叉熵最小化以下目标函数,判别器损失LD定义为
(1)

D[G(z)]为判别器对生成样本的判别输出;D(z)为判别器对噪 声的判别输出图1 原始GAN网络结构Fig.1 The structure of original GAN
式(1)中:x和z分别为真实样本和随机噪声;E为期望。
生成模型的目标是通过最小化式中的目标函数来模拟真实数据中的复杂分布,以达到使D[G(z)]接近1的目的。
生成器损失LG定义为
(2)
从式(1)、式(2)可以看出,LD和LG可以构成一个动态的最小-最大优化游戏,可表示为
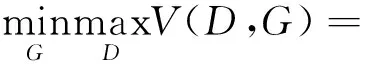
Elg{1-D[G(z)]}
(3)
式(3)中:D、G分别为判别器和生成器。
对GAN中的生成模型和判别模型进行交替优化,以达到纳什均衡的稳定状态[20]。
1.2 WGAN-GP模型
自GAN网络提出以来,判别器和生成器就存在训练困难的问题,主要表现为两个方面:一是生成器生成的虚拟样本缺乏多样性,二是当判别器模型越好,生成器模型的梯度消失现象越严重[21]。
为有效解决GAN网络训练不稳定的问题,使用WasserStein距离替换原始GAN网络中的JS离散度用以衡量真实分布和生成分布之间的距离[22]。使得网络中的生成器与判别器更加稳定,并且生成器所生成的虚拟样本更具多样性,并且更加接近原始样本的边缘分布。
WasserStein 距离又称为EM(Earth-Mover)距离,定义为
(4)

为了使网络不出现模式崩溃等问题,将梯度惩罚项加入判别器损失函数中,对生成样本施加 Lipschitz 限制,以此提高网络收敛速度。因此判别器损失函数定义为
LD=Ex~Pg[fw(x)]-Ex~Pdata[fw(x)]+
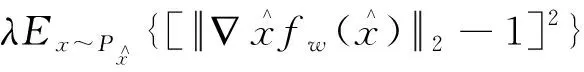
(5)

原始GAN网络训练过程中,出现真实分布和生成分布没有重叠时,JS离散度和相对熵并不能够反应两者的远近程度,而WasserStein 距离有效解决了这个问题。相对熵和JS散度是突变的且极端,而WasserStein 距离却是平滑的,并且WasserStein 距离是可以用梯度下降法优化部分参数,具有更好的鲁棒性[23]。由此,加入WasserStein距离在相当大程度上改进了GAN网络的训练过程,增加了模型的稳定性,减少梯度爆炸或梯度消失的现象[24]。
针对云资源数据匮乏造成算法模型训练过程困难的问题,提出一种基于WGAN-GP的云资源数据增强方法,提高预测模型精度。WGAN-GP网络算法步骤如下。其中,ω为权重,RMSProp为优化器类型,clip为梯度。

WGAN-GP算法,所有WGAN-GP实验所用参数α=0.000 5,c=0.01,m=64,ηcritic=5输入:学习率α,梯度参数c,训练批次数m,生成器生成一次数据时判别器的迭代次数ηcritic,输出:初始化判别器参数ω0,初始化生成器参数θ01:while θ 不收敛do2: for t = 0, 1, …, ηcriticdo3: 真实数据样本 {x(i)}mi=1~Pr4: 随机噪声数据 {z(i)}mi=1~P(z)5: gw←Δw1m∑mi=1fw[x(i)]-1m∑mi=1fw{gθ[z(i)]} 6: ω←ω+αRMSProp(ω,gw)7: ω←clip(ω,-c,c)8: end for9: 随机噪声数据 {z(i)}mi=1~P(z)10: gθ←-Δθ1m∑mi=1fw{gθ[z(i)]} 11: θ←θ-αRMSProp(θ,gθ)12:end while
2 BiGRU网络
2.1 GRU模型
门控单元网络 (gate recurrent unit, GRU)是一种改良的RNN类型,可以学习时序样本中隐含的长期信息。RNN神经网络模型被广泛用于语言识别和文本分类等多个研究领域[14]。相比于人工神经网络模型(artificial neural network, ANN),RNN神经网络模型可以循环利用神经元的权重参数,能够有效提取原始数据的时间相关性,提高时序数据的预测精度。然而,RNN的不足之处是其误差反向传播过程权重的重复利用,容易产生梯度爆炸或梯度消失问题,这对历史数据的长期依赖性问题无法有效解决。GRU的出现有效地解决了以上问题,GRU模型如图2所示。
GRU模型相较于LSTM是在其基础上将遗忘门和输入门优化为单一的更新门,同时混合神经元状态与隐藏状态。
(1)更新门。保留上一时刻的记忆信息,计算输入门it和在t时刻输入细胞的候选状态值at,计算公式分别为
it=σ[Wi(ht-1,xt)+bi]
(6)
at=tanh(Wc(ht-1,xt)+bf)
(7)
式中:Wi和Wc为不同门控机制对输入向量xt的权重;bi为输入门的偏置向量;tanh为激活函数;bf为遗忘门偏置向量。
(2)重置门。根据输入门和遗忘门的计算结果, 对细胞状态进行更新,从而得出t时刻的细胞状态更新值Ct,可表示为
Ct=itat+ftCt-1
(8)
式(8)中:ft为遗忘门。
(3)输出门。控制决定哪些信息需要输出.根据计算得到的细胞状态更新值, 可得到输出门的计算公式为
ht=σ[Wf(ht-1,xt)+bo]tanhCt
(9)
式(9)中:Wo和bo分别为输出门的权重和偏置向量;ht为当前单元的输出值;xt为t时刻的输入;yt为t时刻的输出;σ为sigmoid函数。
在GRU模型误差反向传播校正权重时,有些误差可以直接通过输入门传递给下一层神经元,有些误差则可以通过遗忘门去进行数据遗忘,这样就解决了梯度爆炸与消失的难题,即有效地处理历史数据中相关信息的冗余等问题。

zt为更新门在t时刻保留的信息;为保留了上一状态的记忆图2 GRU隐含层图Fig.2 The hidden layer of GRU
2.2 Bidirectional GRU模型
云资源数据具有明显的时间相关性,如某一时刻CPU使用率不仅与前一时刻的使用率有关,与后一时刻的使用率同样相关,传统的GRU单向训练模式无法做到完全利用数据全局的时间信息,在训练长短期时间记忆网络的过程中,隐含层的状态更新通过的单向时序样本数据输入实现。传统的单向循环网络及其变种网络都存在数据的时间跨度越大,网络就越有可能遗忘掉早期学习到的内容的问题。
双向递归神经网络(BiRNN)可以同时利用数据的正向时间信息和反向时间信息,更加高效和全面的利用数据的时间相关性。采用BiRNN网络结构,用长短期时间记忆网络细胞取代传统的RNN细胞。双向门控单元网络(bidirectional gate recurrent unit,BiGRU)将两个传输方向相反的隐藏层连接到同一输出层,使输出层获得过去和未来状态的信息。这意味着BiGRU神经网络能够从两个不同的数据方向学习信息,从而进行更准确的预测。BiGRU的实质是将常规的GRU神经元拆分为正向状态(正时间方向)和反向状态(负时间方向),每一时步的输出均由正反两向 GRU共同组成,可对历史数据进行正反两方向训练,从历史数据中学到更多有效信息,BiGRU基本结构如图3所示。

图3 双向门控单元网络结构图Fig.3 The structure of BiGRU
3 WGAN-GP-BiGRU模型及参数设置
3.1 数据处理与评估指标
3.1.1 数据处理
由于云资源数据中不同特征间数值范围相差较大,为对数据增强以及模型预测产生消极影响,需要对原始数据进行归一化处理,数据归一化的表达式为
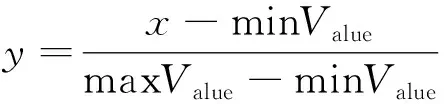
(10)
式(10)中:minValue和maxValue分别为最小值和最大值。
原始数据中按8∶2划分训练集与测试集,训练集用于生成新样本,并用于训练WasserStein生成对抗网络(WasserStein generative adversarial network with gradient penalty,WGAN-GP)以及BiGRU网络,测试集用于验证模型的有效性。
3.1.2 生成样本评价指标
选取功率谱密度(power spectral density, PSD)和相关系数矩阵配色图(spatial correlation coefficients matrix colormap, SCCMC)来验证WGAN-GP网络生成样本的质量。
功率谱密度定义为单位频率间隔的噪声功率,可表示为
(11)
式(11)中:SX(f)为频率密度;τ为输入;GX为傅里叶变换;T为时间周期。
3.1.3 预测评估指标
选择均方根误差(root mean square error, RMSE,记为YRMSE)、平均绝对误差(mean absolute error, MAE,记为YMAE)和决定系数R2来评估文中所有模型的预测效果。

(12)

(13)
(14)

在以上指标中,RMSE和MAE的数值越小,表明模型性能越好,而R2指标则是数值越接近1,表明模型的预测精度越高。
3.2 WGAN-GP-BiGRU模型
以CPU使用率作为预测对象,采样点为10个/d。充分考虑到CPU使用率与其他特征因素之间的关联性,以及考虑CPU使用率的时间序列规律,每个采样点有4个特征,包括CPU使用率、内存使用率、入口网络流量、出口网络流量和磁盘使用率。
使用全连接层搭建WGAN-GP网络,学习原始时序样本中每个单一特征的数据分布。模型采用符合高斯分布的100的噪声作为生成器的输入,根据指定生成新数据的数量,扩充比例分别为30%、60%、100%,即让生成器生成不同数量的虚拟数据进行实验对比。
WGAN-GP网络中的生成器和判别器的结构如表1、表2所示,模型采用RMSProp优化器,训练过程中判别器与生成器相互博弈,达到纳什均衡后完成训练,再根据不同的噪声量生成与原始数据具有相同分布的数据,达到数据增强的目的,从而降低算法模型的训练难度,提高预测精度。BiGRU网络的具体参数如表3所示。
所提出WGAN-GP-BiGRU模型的整体框架如图4所示。

表1 WGAN-GP网络中判别器与生成器的结构Table 1 Structure of discriminator and generator in WGAN-GP

表2 BiGRU模型拟合参数Table 2 Fitting parameters of BIGRU model

图4 WGAN-GP-BiGRU预测框架Fig.4 Forecasting framework of WGAN-GP-BiGRU
4 算例分析
4.1 实验配置
本实验计算是在Inter Core i5-9600的计算机处理器,CPU频率为2.4 GHz,运行内存为16 GB,操作系统为Window10的仿真环境下实现的。算法模型采用Python3.7作为编程语言,架构基于Keras框架,绘图工具采用matplotlab模块。

表3 不同增强比例下各预测模型性能对比Table 3 Performance comparison of each prediction model under different enhancement ratios
实验采用Google公司2016年1月份上半月份的云资源数据,数据分辨率为10 min/个,1 d共有288个数据。将前10 d数据作为训练集,后五天数据作为测试集,使用WGAN-GP模型进行学习增强,生成新的样本后与真实数据拼接,作为预测模型的输入。
4.2 WGAN-GP有效性验证
使用WGAN-GP模型的目的是稳定模型训练过程,更好地捕获历史数据的内在特征,去生成与原有数据具有相似分布的不同特征的新数据。在实验中,向训练后的生成器输入从预定义的高斯分布中提取的100个噪声向量。为了测试本文数据驱动模型对生成数据的鲁棒性,以增强比例为100%为例,利用原始云资源数据去生成的新的云资源数据,通过功率谱密度和相关性系数矩阵颜色图两种方法来验证WGAN-GP网络所生成数据的有效分布。为突出实验效果,实验中使用原始GAN网络、WGAN网络进行对比,以增强比例为100%的CPU使用率为例,3种GAN模型生成数据的功率谱密度对比以及相关性系数矩阵分别如图5、图6所示。
由图5可以看出,不同GAN网络生成数据的功率谱密度曲线中,WGAN-GP功率谱曲线更贴合真实数据的功率谱密度曲线,即相比于原始GAN模型和WGAN网络,WGAN-GP网络模型所生成数据的密度分布更接近于原始数据的真实密度分布,这意味着这两种模型下WGAN-GP网络最能良好地学习到真实的数据分布,生成具有分布相似度最高的数据样本。

图5 不同GAN网络生成数据的功率谱密度Fig.5 Power spectral density of data generated by different GAN networks
为验证不同GAN网络生成数据与原始真实数据之间的空间相关性,在增强比例为100%的不同模型下,向模型生成器中注入相同的噪声,在生成数据中以及原始数据中随机选取生成样本连续的相同时刻的24×24个数据点进行相关性对比,形成系数矩阵并由配色图将结果可视化如图6所示。
由图6(b)、图6(c)与图6(a)配色的对比结果可以直观看出,并没有图6(a)与图6(d)之间高度相似的配色,这说明WGAN-GP生成的数据与原始样本之间具有高度相似的时间相关性以及空间相关性。
4.3 WGAN-GP不同增强比例下各预测模型的误差指标
为了验证BiGRU的预测有效性,选用几种经典的预测算法进行对比,包括随机森林(random forest, RF)、长短期时间记忆网络(long short-term memory, LSTM)、门控循环单元(gate recurrent unit, GRU)和支持向量回归(support vector regression, SVR)。
从表3和图7可以得出以下结论。
(1)在任何增强比例下,基于WGAN-GP网络进行数据增强的各机器学习模型的预测性能要高于未使用使用数据增强的模型。例如,以增强30%为例,WGAN-GP-SVR模型的RMSE和MSE要比单一SVR模型分别降低2.04%和2.75%,R2指标要提高2.64%,其他模型也是如此。
(2)在同等增强比例情况下,BiGRU模型的预测性能要明显高于其他算法模型。以增强比例为100%为例,BiGRU的RMSE和MAE指标比LSTM和GRU分别降低7.898%,9.021%和6.537%、8.353%,R2指标分别提高了10.203%和7.752%,这说明了BiGRU能够能够双向提取数据的时间相关性,提高了模型的预测性能。

图6 不同GAN网络数据生成的相关性系数矩阵配色图Fig.6 Color mapping of correlation coefficient matrix generated from different GAN network data

图7 不同增强比例下的模型预测图Fig.7 Model prediction of different enhancement ratios
(3)用WGAN-GP网络进行数据增强,增强比例越高各模型的预测性能越高,以BiGRU为例,增强比例为100%下相对于增强比例为66.6%和33.3%的RMSE和MAE指标分别降低8.516%、7.841%和13.478%、7.848%,R2指标分别提高了2.451%和2.654%。由图7可以看出,随着增强比例的增加,测试集中各模型的预测曲线更加贴合真实值。
5 结论
针对云资源数据匮乏导致的模型预测精度低的问题,提出一种基于WasserStein生成对抗网络和双向门控单元网络的云资源短期预测模型。通过实验仿真,得出如下结论。
(1)通过WGAN-GP可以有效地学习原始样本的数据分布规律,并生成与原始样本高度相似的较高质量的新数据,从而弥补数据匮乏导致预测精度低的缺陷。
(2)采用双向门控单元网络作为预测模型,可以对数据时间相关性进行前向和反的提取,突破传统循环网络单向提取时间信息的局限,达到全面利用数据的时间信息,提高模型预测性能的目的。
尽管所提出模型在本实验中表现优异,但仍然有其局限性需要讨论:模型只在一个数据集上进行实验,对于其应用在其他数据上的有效性仍有待验证。因此在未来工作中将考虑使用其他数据对所提出模型做进一步研究。
