基于CatBoost的温室日参考作物蒸发蒸腾量估算模型研究
2022-02-13牛曼丽李红岺李新旭
牛曼丽,李红岺,李新旭
(北京市农业技术推广站,北京100029)
0 引 言
参考作物蒸发蒸腾量(Reference Evapotranspiration,ET0)是计算作物需水量的一个基础要素,是灌溉制度制定、灌溉系统设计等方面的重要参数[1,2],作物蒸发蒸腾量的准确估算对提高农业用水效率、发展节水农业具有重要意义。ET0计算的标准方法是采用世界粮农组织推荐的FAO 56 Penman-Monteith 模型,该模型已经在世界各地、各种气候类型下通过蒸散仪进行了验证,但是这种方法需要较为完备的气象数据,计算过程复杂[3]。
近年来,随着机器学习的快速发展及其在解决非线性复杂问题上的独特优势,多种机器学习方法如人工神经网络[4]、随机森林[5]、支持向量机[6]开始应用于蒸发蒸腾量的估算和模拟。CatBoost(Category Boosting)以其减少过拟合、泛化能力较强等特点受到广泛关注,基于树结构的集成学习模型尤其是CatBoost 算法在蒸发量估算模拟方面有了一些应用,董力铭等[7]应用蝙蝠优化分类梯度提升算法构建了干旱半干旱地区的水面蒸发量预测模型,模型具有较好准确性。Huang[8]将CatBoost 模型与SVM 模型、RF 模型在估算中国亚热带湿润地区12 个站点的ET0进行了对比,发现CatBoost 模型在精度和稳定性方面具有显著优势。目前已有的CatBoost应用主要是大田环境下的ET0估算,在设施农业领域的ET0估算未见报道。在设施农业中,ET0的估算更加复杂,为了提高ET0估算精度,本研究提出采用具有极佳性能的Catboost 方法构建ET0估算模型。本文主要研究内容分为3 个部分:①构建基于CatBoost 的ET0估算模型,研究了各变量与ET0之间的相互关系;②评价不同数量的输入参数对模型估算精确度的影响;③对比其他6种机器学习模型:XGBoost、AdaBoost、随机森林(RF)、决策树、最邻近节点算法(KNN)、支持向量机(SVM)。
1 数据获取
1.1 试验区域
试验地点位于北京,地处海河中下游,经纬度:115.7°~117.4°E,北纬39.4°~41.6°N,属温带大陆性季风气候区,降水年际、年内分配极不均衡,经常伴随着高温天气。
试验数据样本采集于北京市农业技术推广站小汤山农业科技展示基地,该基地位于北京市昌平区小汤山镇立汤路,占地面积约23 万hm2,具有现代化连栋温室4.5 hm2,日光温室65 栋,是北京都市现代农业的展示基地。选取西区连栋温室作为试验区域,主要种植作物为番茄,采用基质栽培模式。该区域面积1 万m2,东西长70 m,南北长145 m,肩高6 m,脊高7.5 m。温室屋面为5 mm浮法玻璃,外墙为中空玻璃。温室内有三维立体加温管道、内保温幕加温设备,高压喷雾、内遮阳降温设备。
1.2 数据采集方法
温室内部采用“Priva Connext”环境自动监测记录系统,包括温室内传感器和室外气象站,具体布置位置如图1 所示。温室内传感器监测记录项目为温度、相对湿度,每15 min 记录一次数据。温室外部的气象站监测系统采集指标为太阳辐射。采集周期为2016年12月至2020年6月30日。

图1 信息采集设备位置示意图
1.3 研究方法
1.3.1 温室修正型Penman-Monteith 模型
FAO-56 Penman-Monteith 模型是联合国粮农组织推荐的用来计算参考作物蒸发蒸腾量的方法,但由于温室内风速为0,该方法不适用于温室作物蒸发蒸腾量计算,需要进行修正,采用修正型Penman-Monteith 模型[9,10]进行计算,其公式如下:

式中:ET0为参考作物蒸发蒸腾量,mm/d;Rn为作物表面净辐射,MJ/(m2·d);G为土壤热通量,MJ/(m2·d);T为2 m 处的日平均气温,℃;e0为气温T下的饱和水汽压,kPa;es为日平均饱和水汽压,kPa;ea为日平均实际水汽压,kPa;Tmax、Tmin分别为地面2 m 高度的日最高、最低温度;Tm为日平均温度,℃;△为水汽压曲线斜率,kPa/℃;γ为湿度计常数,kPa/℃;P为大气压,kPa;λ为汽化潜热,MJ/kg;Rn=Rns-Rnl,Rns=0.77RS,Rs采用实测结果,MJ/(m2·d)。
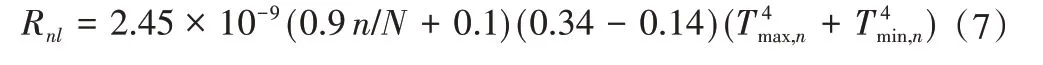
净辐射Rn是通过净短波辐射与净长波辐射之差来计算。在计算过程中,由于日土壤热通量的影响相对来说很小,所以可以忽略不计。
本研究将采用修正型Penman-Monteith 公式计算温室参考作物蒸发蒸腾量,并作为其他模型估算的标准值。
1.3.2 分类梯度提升模型(CatBoost)
CatBoost 是一种新的梯度增强决策树(GBDT)算法,是以对称树为弱学习器,使用GBDT进行分类。梯度提升本质上是通过在特征空间中执行梯度下降来构建弱学习器,通过局部最优方式迭代加权组合弱学习器来构建强学习器[11-13]。
在决策树中,标签平均值将作为节点分裂的标准,这种方法称为Greedy Target-based Statistics,简称Greedy TS,用公式(8)表示。该方法的缺点是用标签的平均值表示特征,当训练数据集和测试数据集结构和分布不一样的情况下会出现条件偏移问题。
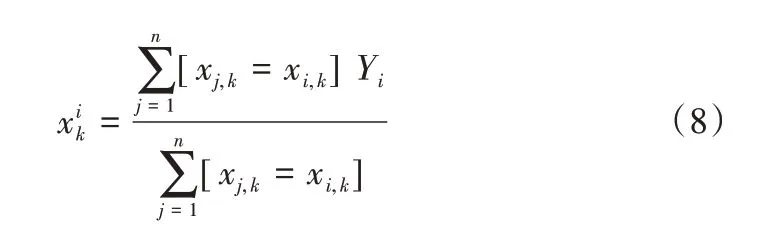
针对上述问题,CatBoost 中一个标准的改进Greedy TS 的方式是通过添加先验分布项来减少噪声和低频率类别型数据对于数据分布的影响[12]。令σ=[σ1,σ2,…,σn]Tn为置换,然后用公式(9)替代。

式中:P为添加的先验项;a为大于0 的先验的权重,针对类别数较少的特征,可以减少噪声数据。
它能够高效合理地处理类别型特征,并利用训练过程中对类别型特征处理,使用了组合类别特征,极大丰富了特征维度。该算法的另一个优点是它在选择树结构时采用对称树计算叶值,解决了梯度偏差以及预测偏移的问题,能够防止过度拟合并允许使用整个训练数据集,即对输入样本集进行随机排列并进行计算。该方法对于回归任务,先验项取数据集对应标签的均值。CatBoost算法结构图见图2。
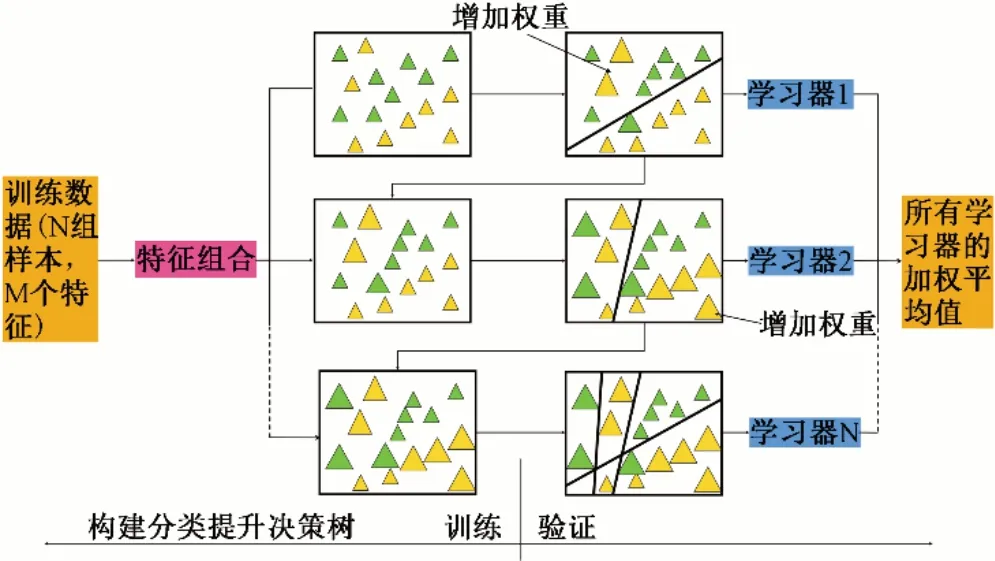
图2 CatBoost 算法结构图
1.4 统计指标
通过平均绝对误差(MAE)、均方根误差(RMSE)、决定系数(R2)3个统计指标对模型估算性能进行评估。
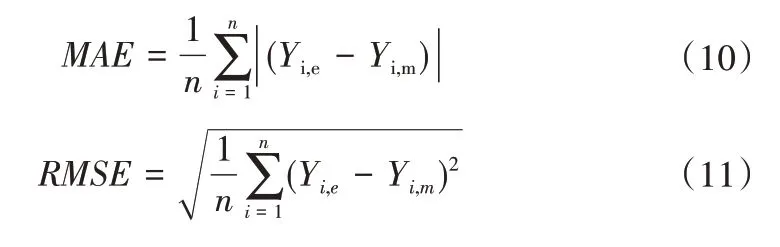

式中:Yi,e和Yi,m分别为Penman-Monteith 公式计算值和模型预测值,mm/d;和分别为参考作物蒸散量彭曼公式计算值的平均值和模型预测值的平均值,mm/d。RMSE和MAE越小,R2越大,则说明模型拟合的效果越好,精度越高。
1.5 运行环境
本研究试验的训练环境为一台图形工作站,CPU 主要配置为:Intel(R)Xeon(R)E5-1620 v4主频3.50 GHz,GPU 的配置为:NVIDIA Quadro K2200。模型训练采用Anaconda 平台作为深度学习训练基础平台,底层Python版本为3.7。
1.6 模型构建
在数据集划分中,利用该试验点的940个数据集进行模型训练、测试和评价,80%的数据用于模型训练,20%用于模型测试。在用于模型训练的数据中,随机选取20%作为验证数据集,以判断模型拟合情况。训练集主要用于参数调整,按照模型评价指标确认最佳的模型参数,测试集主要作用是测试模型泛化性能,确保训练集得到的训练参数与测试集无关,模型鲁棒性更高。CatBoost 使用默认参数可以提供很好的结果,能够减少参数调整所需的时间。因此,在本模型构建中相关参数采用默认参数。
2 数据统计及预处理
将系统监测的数据通过计算获得每日最大值、最小值及平均值,主要是以下7 个指标:累积太阳辐射(Rs,MJ/m2)、室内最高温度(Tmax,℃)、室内最低温度(Tmin,℃)、室内平均温度(Tm,℃)、室内最大相对湿度(RHmax,%)、室内最低相对湿度(RHmin,%)、室内平均相对湿度(RHm,%),通过温室修正型P-M 公式计算出参考作物蒸发蒸腾量(ET0,mm/d)。数据集共计1 124 个,剔除番茄拉秧停产日期的数据,共计940个数据集。
本次用于模型构建的数据集包括平均室内温度Tm、平均相对湿度RHm、累积太阳辐射Rs、ET0共4个指标。表1显示了不同时期各指标平均值、标准差、最大值、最小值和中值等。

表1 数据集数据特征统计
目标值ET0处于[0.54,7.9]之间,中位数为3.32 mm/d,标准差为1.59 mm/d,波动较为剧烈,如图3所示。

图3 番茄一个生长周期ET0变化图
另外,数据归一化可以提高模型的预测精度和拟合速度。据此,采用最大最小归一化方法对每个特征变量进行处理,如下式所示。

3 结果与讨论
3.1 相关性分析
本文采用Pearson’s 相关系数[14]Pc计算出各个指标之间的一一对应相关程度。Pc主要用来衡量两组分析对象线性关系的强弱,其取值范围为[-1,1],数学表达式为:
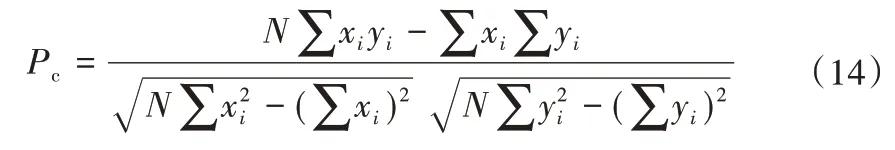
式中:x和y分别对应两组分析对象的数据序列;N为样本个数;Pc绝对值越大,相关性越强。
通过Origin 软件对数据进行相关性分析,3 个特征向量与参考作物蒸发蒸腾量ET0的相关系数及相关性分析如表2 和图4所示。

表2 3个特征向量与ET0的相关系数
从图4 可以看出,除平均相对湿度外,其余环境因子与ET0之间的相关系数均为正值,即环境因子增加会导致ET0的升高,其中累积太阳辐射Rs与ET0相关性最显著,相关系数0.923,决定系数R2为0.852;其次Tm>RHm。而平均相对湿度与ET0呈负相关,相关系数为-0.552,R2为0.304。太阳辐射和温度是影响ET0变化的主要影响因子。
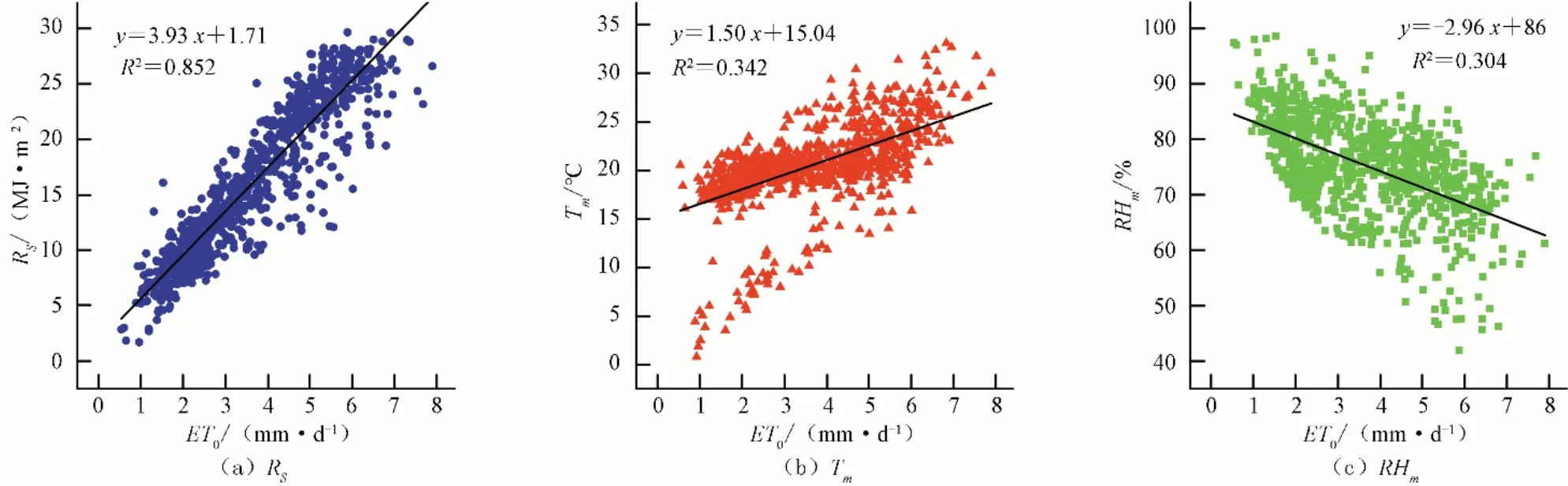
图4 ET0与输入特征向量之间相关性分析
3.2 CatBoost模型不同输入组合估算精度对比
表3 显示了CatBoost 模型在不同的7 个输入参数组合下日参考作物蒸发蒸腾量模型估算精度。结果显示,当输入参数仅为1 种环境数据时,累积太阳辐射Rs表现最好,RMSE为0.677 mm/d。由于温室内部风速为0 m/s,作物蒸腾的能量来源是太阳辐射,因此太阳辐射与作物蒸腾量的相关性最大,是主要影响因子。在Rs的基础上,分别引入Tm、RHm,其精度均有所提高,其中引入RHm的CB5组合提高最显著,测试集决定 系 数R2由0.818 提 高 到0.892,RMSE由0.677 mm/d 降 到0.522 mm/d。在输入3 个特征向量时,精度最高,R2达到0.962。

表3 测试集不同输入参数组合CatBoost模型的性能评估
3.3 CatBoost与其他机器学习方法估算精度对比
在监测气象数据比较充足条件下,采用3个参数作为输入特征向量进行训练学习,通过模型对测试集的预报误差进行精度检验,将CatBoost 模型的估算结果与其他6 个模型[XGBoost[15-17]、AdaBoost[18]、随机森林[19](RF)、决策树[20](Tree)、KNN[21]、SVM[22]]的精度进行对比,结果如表4 所示,验证集预测精度从高到低为CatBoost>XGBoost>RF>KNN>Tree>AdaBoost>SVM;测试集CatBoost 的模型测试集的R2最大,为0.962,MAE为0.220 mm/d、RMSE为0.310 mm/d,预测精度优于其他6 个模型,其他模型的预测精度从高到低依次为XGBoost>KNN>RF>Tree>AdaBoost>SVM。在稳定性方面,将7个模型运行3次,拟合精度不再改变,都具有较高稳定性。
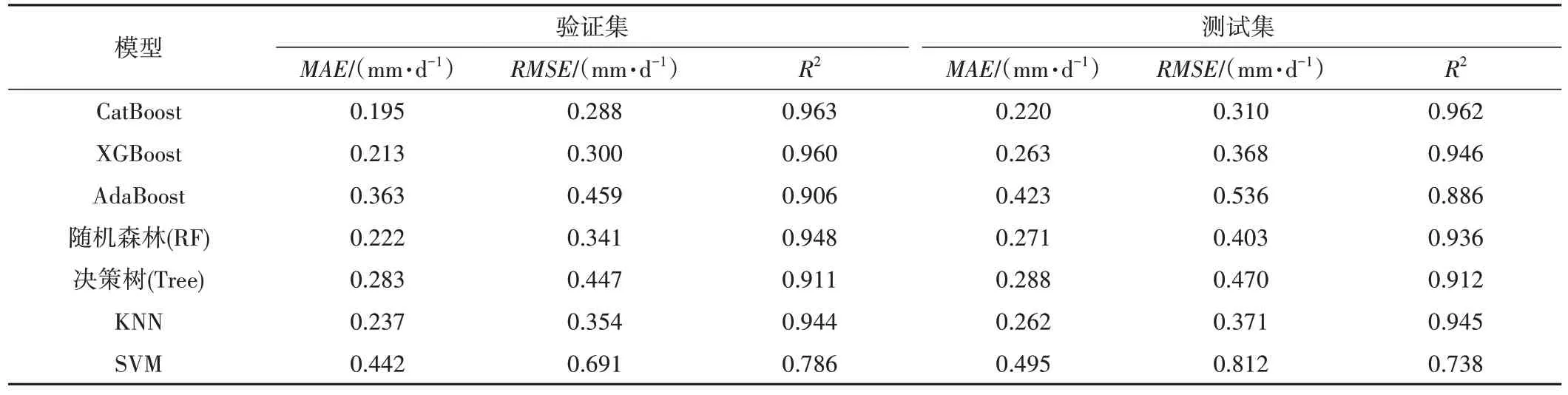
表4 7种模型性能对比
图5 为7 种机器学习模型测试集估算值和计算值之间的散点图,从图5 可以明显看出,CatBoost 模型的散点图最接近1:1的关系,表明其拟合程度最高。

图5 7个机器学习模型ET0估算精度对比
3.4 讨 论
在输入项选择方面,本研究得出可在实际生产配置传感器不足时,首选累积太阳辐射和湿度传感器,进行ET0的估算模拟。当配置温度、湿度、光辐射传感器时,通过获取的平均室内温度、平均湿度、累积太阳辐射进行模拟,估算精度最高。在模型选择方面,本研究表明CatBoost模型具有最佳的估算精度,与本研究结果类似,陈志月等在预测江西地区水面蒸发量的研究中也得出了CatBoost 相比XGBoost、GPR 模型预测效果最佳的结论[11],HANG 在亚热带地区ET0估算方面也得出了CatBoost在完整的参数组合下表现优于随机森林和支持向量机的结论[8]。在未来的研究中,还将从以下几个方面入手,进一步改进温室蒸发蒸腾量估算模型:①参考作物蒸发蒸腾量受气象因素的影响较大,北京市不同地区间气象差异较大,本次试验只选用了昌平区一个地点作为试验,下一步将在北京多选择几个具有代表性的生产温室,开展相关试验,构建完善的数据集,增强模型的泛化能力。②本次研究主要是对日均数据进行模拟,未来将对每小时作物蒸发蒸腾量模型进行模拟和预测。③本次研究模型是基于连栋温室数据,未来计划在日光温室进行验证性研究。
4 结 论
以上结果表明,本文构建的基于CatBoost的ET0估算模型,当输入参数为平均室内温度、平均湿度、累积太阳辐射3参数时,效果最佳;在传感器获取的气象数据充足的条件下,输入3个参数时,CatBoost模型相比XGBoost、AdaBoost、随机森林(RF)、决策树、最邻近节点算法(KNN)、SVM 表现最佳。以上结果证明本文提出的CatBoost温室作物日蒸腾蒸发量估算模型具有较好的拟合性能。因此,本文提出的CatBoost模型能够较好地拟合参考作物蒸发蒸腾量的计算结果,可以作为彭曼公式的一种替代计算方法。
