基于大数据与人工智能的关联分类改进算法*
2022-02-12黎文娟周忠眉
[黎文娟 周忠眉]
1 引言
目前人工智能算法中比较流行的算法都是在大量数据的基础上进行分类的算法研究。带标签的大量数据是进行分类的基础。大多数的人工智能算法都对计算机的运算能力和运算速度有很高的要求。一个好的分类算法希望能有比较准确的分类的同时能够尽量少占用系统资源和时间。关联分类算法具有这两方面的优点。关联分类算法虽然算法复杂度不高,但能够挖掘出数据集中的大量关联规则从而得到很好的分类准确度。
关联分类算法是大数据与人工智能领域的一种重要的分类算法[1~3]。主要原理是通过对带标签的数据集进行学习,挖掘关联规则构建分类器模型来对待预测实例进行分类。目前已经提出了许多基于关联规则挖掘的分类算法,如CBA[4]、MCAR[5]、CMAR[6]算法。这些分类算法能挖掘出大量的规则并且具有较高的分类准确率[7~10],因而得到了广泛地关注。
关联分类算法虽然具有较好的分类效果,但是也存在以下一些不足:CBA、CMAR 算法都是基于支持度和置信度度量挖掘关联规则,没有考虑项集与类别之间的相关性,并且产生的规则数量庞大,其中有许多质量不高的规则容易导致对预测实例的误判。针对此问题许多学者对关联分类算法进行了改进。Arunasalam.B 等人提出使用补类支持度CCS 度量[11]项集与类别之间的相关性,使用提升度对规则剪枝,能更有效地挖掘关联规则。提出的CCCS 算法在多个数据集上有效地提高了分类准确率。王卫平等人在CCCS 算法的基础上提出了改进算法ACSER[12],ACSER算法不仅考虑了项集在补类的支持度还考虑了项集在本类的支持度,使用增比率来度量项集与类之间的关系,有效地提高了规则质量并比CCCS 算法具有更高的分类准确率。虽然提升度、增比率能有效度量项集与类别之间的相关性,但提升度和增比率受数据集数据总量的影响非常大,其值波动范围很大不稳定,因而在实际运用中难以有效确定提升度和增比率的阈值,导致在一些数据集上分类准确率不理想。
针对提升度和增比率度量存在的问题,本文提出的改进算法IACD(Improved association classification algorithm based on Cosine Degree)在度量项集与类别的相关性时使用了一种新的度量——余弦度量,余弦度量仅受项集和类别支持度影响不受数据总量的影响,能更好地反映项集与类别之间的关系。本文算法有以下几个特点。
(1)提取规则时同时考虑了规则的置信度和余弦度量两种度量以提高规则质量。
(2)提出了一种新的规则强度对规则进行排序、剪枝以减少冗余规则的数量。
(3)预测时选取最优的K条规则计算规则强度,避免出现新实例被单条规则误判的情况。
实验结果表明IACD 算法在多个数据集上平均分类准确率高于几种改进的关联分类算法。
2 相关理论

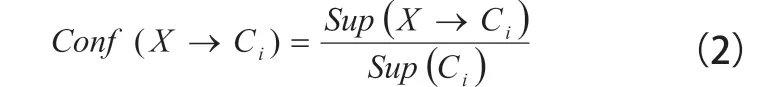

lift用来度量项集X与类Ci之间的关联程度,lift值为1 代表项集X与类Ci之间相互独立,lift值越大代表项集X与类Ci之间关联程度越高,一条规则的值受训练集实例数目影响很大,其取值范围在。

Cosine同样用来度量项集X与类Ci之间的关联程度,值为0.5 代表项集X与类Ci不相关。Cosine与lift值的区别在于Cosine对分母开了根号,其度量值仅受支持度的影响,不受数据集实例数的影响,具有零不变性且其取值范围在。
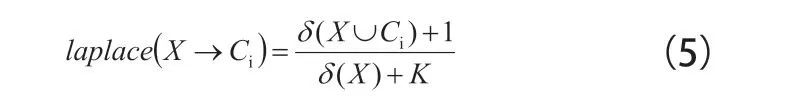

3 IACD 分类算法
本节首先介绍了IACD 算法的各个主要步骤,其次详细说明IACD 算法使用余弦度量的优势,最后给出算法的伪代码。
3.1 IACD 算法主要步骤
3.1.1 规则挖掘
IACD 算法采用类apriori 算法根据支持度挖掘频繁项集,其次对其中每一个频繁项集计算到各类的置信度,生成满足置信度阈值的候选规则。接着计算每一条候选规则的余弦度量,满足余弦度量阈值的候选规则加入规则集。
剪枝时,IACD 算法计算规则集中每一条规则的Cos strength强度,然后按照Cos strength强度对所有规则排序,如果该规则覆盖的所有实例均已被优先级较高的实例正确分类,则剪枝掉该规则。
3.1.2 未知实例预测
IACD 算法在分类新实例时,扫描规则集,将规则集中与新实例匹配的规则最优K条规则取出,然后把这些规则按照类标签划分,并计算每一条规则的Cos strength规则强度,最后对每个类标签所属的规则计算平均强度,将平均强度最大的类标签赋予新实例。
3.2 余弦度量的优势及算法伪代码
表1 显示了一组数据集和两种度量提升度以及余弦度量的评价结果。

表1 训练数据集
在D1和D2两个数据集中,XCi明显大于因此项集X 和类标签Ci是正相关的,但是根据公式计算提升度可以发现,在D2中项集X 和类标签Ci变成不相关的,这显然与事实不符,而在D3中,XCi明显小于和所以项集X 和类标签Ci应该是负相关的,可是提升度计算得出的结果是正相关的。同理在D4中,XCi、这三者是一样的,因此项集X 和类标签Ci是不相关的,但是提升度计算得出却是强正相关的。
从上面几个例子可以看出,提升度受数据总量的影响非常大,使用提升度判断项集与类别的相关性会存在失真的情况,而使用本文中的余弦度量可以真实地判断出项集与类别之间的相关性。
IACD 算法的伪代码如图1 所示。

图1 IACD 算法步骤
其中,第4步是挖掘频繁项集,第5步是生成关联规则,第6 步则是对规则集剪枝,第7 步是对规则集进行排序。
4 实验及结果分析
4.1 实验设计
本实验使用的实验环境搭载Microsoft Windows10(64 bit)操作系统,运行Java 8.0 编程环境下进行,实验利用了16组具有不同特点的UCI 数据集:austral、Breast、cleve、Diabetes、heart、pima、labor、Iris、horse、glass、sonar、tic-tac、wine、Led7、vehicle、zoo,这些数据集都是大数据与人工智能方面的经典抽象数据集。数据集如表2 所示。表2 分别给出了每组数据集的属性数目、类别数目及实例总数。实验中,对每组数据集实验均采用10 折交叉验证方法,以减小随机性。本实验采用分类准确率来评价所有算法的分类性能。

表2 实验所用的数据集
4.2 实验结果及分析
实验参数设置如下:在IACD 算法中,设置置信度阈值为0.80,支持度阈值为0.05,余弦度量阈值阈值为0.7。其 他 对 比 算 法:CBA、CMAR、CPAR、CCCS、ACSER的分类准确率均来自参考文献。
实验结果如表3 所示,从实验结果可以看出,在所使用的16 个数据集上,IACD 算法在10 个数据集上分类准确率高于其他所有对比算法,同时IACD 算法较其他算法取得最高的平均分类准确率。因此可以得出结论余弦度量有效地度量项集与类别之间的关系,提高了规则质量。并且在多种数据集的准确率都比较高,具有一定的通用性。
5 总结
针对基于支持度和置信度度量的关联分类算法无法度量类别和项集之间的相关性的问题,本文提出了基于余弦度量关联分类的改进算法IACD。IACD 算法在挖掘关联规则时使用余弦度量来衡量项集与类别间的相关性以提高生成规则的质量并减少冗余规则的数量。实验结果从测试的几个不同特点的典型数据集来看,IACD 算法在多个数据集上比几种经典的关联分类改进算法具有更高的分类准确率。

表3 IACD 算法与多种算法的准确率对比
