边缘算力网络中智能算力感知路由分配策略研究
2022-02-11孙钰坤
孙钰坤,张 兴,雷 波
(1.北京邮电大学 泛网无线通信教育部重点实验室,北京 100876;2.中国电信股份有限公司研究院,北京 102209)
0 引言
随着人工智能与移动互联网技术的不断发展,增强现实、人脸识别、图像渲染、自动驾驶等新型业务应用大量涌现,这些新型业务应用通常需要消耗巨大的计算资源、存储资源以及能耗,目前智能终端设备的计算能力尚且比较有限,电池容量也比较低,无法满足这些新兴业务应用的处理需求。因此,云计算得以提出并持续升温。
云计算利用虚拟化技术建立超大容量的算力资源池,使得各种应用可以获得所需的计算资源、存储资源以及软件和平台服务。云计算的出现满足了计算密集型的业务处理需求,但是,自动驾驶这一类智能应用同时具有时延敏感的特性,终端到云端的传输时延在很多情况下无法满足这一类应用对于超低时延的需求。因此,ETSI于2014年12月成立移动边缘计算(Mobile Edge Computing,MEC)行业规范组(Industry Specification Group,ISG),启动移动边缘计算标准化,以发展移动边缘计算[1]。ETSI将MEC定义为一种可以在无线接入网络中移动用户附近位置提供IT和云计算功能的网络架构,旨在将IT和云计算从核心网络迁移到边缘接入网络,以缩短任务处理端到端的时延,并确保数据的安全性与隐私性。2016年9月移动边缘计算的概念被扩展为多接入边缘计算(Multi-access Edge Computing,MEC),将移动边缘计算从电信蜂窝网络进一步延伸至其他无线网络,以扩大边缘计算在包括WiFi和固定访问技术在内的异构网络中的适用性。
边缘计算设备和智能终端设备的大量部署,虽然解决了网络中海量数据上传至云计算中心导致的带宽紧缺、网络拥塞、时延过长的问题,但也使得算力资源呈现泛在部署的趋势,不可避免地出现了“算力孤岛”效应。一方面,边缘计算节点没有进行有效的协同处理任务,单一节点的算力资源无法满足如图像渲染等超大型的计算密集型任务的算力资源需求,仍然无法解决同时具有计算密集和时延敏感特性的新型业务的超低时延需求问题;另一方面,虽然一些边缘计算节点出现超负载无法有效处理计算任务的情况,但是由于网络负载的不均衡,势必会有一些计算节点仍然处于空闲的状态,导致边缘网络的算力资源无法得到充分的利用。
因此,为了高效、协同地利用全网异构的算力资源,2019年由运营商、设备商等主导提出一种基于分布式系统的计算与网络融合的技术方案——算力感知网络[2-5](Computing-aware Networking,CAN),以实现ICT系统的联合优化调度,提供端到端的体验保证。CAN旨在将云边端多样的算力通过网络的方式连接与协同,实现计算与网络的深度融合及协同感知,以及算力资源的按需调度和高效共享[6-10]。
算力感知路由和算力资源分配是算力感知网络研究中的一个关键问题,在传统的网络架构中,算力与网络通常是单独进行管理。在算力管理方面,计算卸载技术作为边缘计算的一项关键技术,在边缘计算概念被提出之后,便有许多研究者提出基于单用户多节点[11]、多用户单节点[12]以及多用户多节点[13-14]的任务卸载策略,这些策略实质上都是将终端任务与边缘计算节点进行完美匹配。在网络管理方面,研究主要集中在如何优化任务路由策略[15]。
针对目前研究存在的问题,本文在多任务、多路由节点、多边缘服务器的边缘算力网络场景下,分别基于用户业务侧、网络侧、边缘计算资源池侧,构建算力需求、网络状态、算力资源的感知信息模型;基于感知信息模型,在计算资源和存储资源的约束限制下,以用户业务的调度传输时延最小化为优化目标,联合优化路由控制、计算节点的选择和存储、算力资源的分配;最后,本文提出了基于Floyd的算力感知路由分配策略,有效地将算力与网络进行协同管理,缓解网络负载不均衡的问题,并通过仿真分析了所提策略在改善用户业务体验以及算网资源利用率方面的性能。
1 任务调度系统建模
1.1 算力感知网络系统概述
如图1所示,算力感知网络系统由终端设备、基站以及边缘网关(路由节点)、边缘服务器(边缘计算节点)和云中心组成。其中用户业务由终端设备发起请求,通过无线链路传输至基站;边缘网关主要负责路由控制和数据转发,在实际网络系统中,边缘网关可以部署在基站侧,路由节点之间可以通过实时动态的链路进行数据传输;边缘服务器是以硬件基础设施为虚拟化资源的边缘应用平台,主要负责提供存储和计算资源,进行用户业务的处理,边缘计算节点与路由节点之间通过固定链路进行数据传输;云中心具有充足的存储资源和计算资源,是部署在距离用户较远位置的大型服务器集群,边缘计算节点与云中心节点之间具有固定的链路进行数据传输,虽然在本文的系统模型中,假设用户业务只在由边缘计算节点组成的边缘算力感知网络中进行处理,但是云中心是算力感知网络架构中不可或缺的一部分,因此在图1中予以表示。

图1 算力感知网络系统Fig.1 System of computing-aware networks
1.2 任务模型
假设算力感知网络系统中共有M个终端设备,终端设备的集合表示为Μ={1,2,...,M},m∈Μ表示一个终端设备,假设每个终端设备每次最多发起一个计算任务处理请求。
假设算力感知网络系统中共存在K个用户业务,用户业务的集合表示为Κ={1,2,...,K},k∈Κ表示一个用户业务。第k个用户业务可以表示为Sk(Ak,Xk,Ck,Dkmax,Dka,Bk),其中Ak表示用户业务k所接入的路由节点,Xk表示用户业务k所需要的存储资源的量化值,Ck表示用户业务k所需要的计算资源的量化值(中央处理器的转数/比特数据/秒,即单位时间处理单位比特数据所需要的中央处理器的转数),Dkmax表示用户业务k允许的最大业务处理时延,Dka表示用户业务k接入路由节点的时延,Bk表示用户业务k的大小。
1.3 通信模型
终端设备发出请求的用户业务通过无线链路传输到算力感知网络中的边缘无线接入点,根据香农定理,用户业务k到所接入的路由节点Ak的数据传输速率可以表示为:
Rk,Ak=Bk,Aklb(1+γk,Ak),
(1)
其中,Bk,Ak表示用户业务k到所接入的路由节点Ak信道的带宽,γk,Ak表示用户业务k到所接入的路由节点Ak传输的信噪比(Signal Noise Ratio,SNR),表示为:
(2)
式中,pk,Ak表示用户业务k到所接入的路由节点Ak的发射功率,N0表示加性高斯白噪声的谱密度,hk,Ak表示用户业务k到所接入的路由节点Ak的路径损耗,hk,Ak的大小与用户业务k到所接入的路由节点Ak之间的距离有关,距离越远,路径损耗越大。本文主要研究终端设备发出的业务请求在算力感知网络中如何基于感知的信息路由调度到最佳的算力节点上进行业务处理,因此没有考虑用户业务的位置分布,而是将用户业务到所接入的路由节点的数据传输速率进行统一的量化表示。
综上所述,用户业务k到所接入的路由节点Ak的接入时延为:
(3)
终端设备发出请求的用户业务在算力感知网络中,通过动态的通信链路在相邻的路由节点之间进行数据传输,假设在算力感知网络中路由节点之间动态链路的数据传输速率可以感知,则表示为:
式中,wi,j表示路由节点i与路由节点j之间的数据传输速率,满足
(4)
因此,用户业务k在路由节点i和路由节点j之间的传输时延为:
(5)
算力感知网络中的计算节点与路由节点之间通过固定链路进行数据传输,路由节点i到计算节点n之间的数据传输速率可以表示为:
(6)
因此,如果用户业务k选择计算节点n,则通过路由节点传输到计算节点n的到达时延为:
(7)
1.4 计算、存储资源模型
在算力感知网络系统中,网络控制面需要实时感知计算节点的存储资源以及算力资源状态。假设网络中存在N个计算节点,计算节点的集合表示为Ν={1,2,...,N},n∈Ν表示一个计算节点,则第n个计算节点可表示为Zn(An,Xn,Cn,Rn),其中An表示该计算节点连接的路由节点标签,Xn表示该计算节点的存储资源大小,Cn表示该计算节点的计算资源大小(中央处理器的转数/比特数据/秒,即单位时间处理单位比特数据所需要的中央处理器转数),Rn表示该计算节点到路由节点的数据传输速率。
综上所述,当计算节点的存储资源、计算资源满足用户业务需求时,用户业务的计算时延为:
(8)
2 任务调度优化模型
在上述算力感知网络系统架构模型、任务模型、通信模型、计算和存储资源模型的基础上,一个任务处理的总时延包括任务接入时延、任务传输时延、任务到达计算节点时延、任务处理时延和任务等待时延,由于任务处理时延和任务等待时延在确定的算力需求条件下具有统一性,因此可以在优化模型中不予考虑,所以用户业务k到调度的计算节点的传输时延为:
tk,t=Dka+Dt+Dk,n,a。
(9)
考虑联合优化计算任务路由策略和算力资源的分配,本文将最终的计算任务调度优化问题建模为:
(10)
目标函数的约束条件如下:
(11)
(12)
式中,Κn表示调度到计算节点n的所有用户业务的集合,约束条件(11)表示调度到计算节点的所有用户业务可利用的存储资源不超过该计算节点可以提供的存储资源,约束条件(12)表示调度到计算节点的所有用户业务可利用的计算资源不超过该计算节点可以提供的计算资源。
由于当算力感知网络处于部分计算节点过载,或者全网计算节点过载的情况时,根据最小化用户业务传输时延的目标得到的调度策略,部分用户业务势必会因为算力资源短缺而无法按需完成任务处理,考虑实际工程问题的可行性以及算法的复杂度,需要重点关注的不是如何精确地求出最优解,而是在如何保证用户公平性的前提下,高效快速地获得一个联合优化路径选择与计算节点选择的次优解,本文提出一种基于Floyd的算力感知路由分配(CARA)算法来解决该问题,为计算任务均衡选择优化的路径以及计算节点。
3 基于Floyd的算力感知路由分配算法
Floyd算法是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法。在算力感知网络架构中,路由控制器可以感知用户业务的数据大小和网络的链路状态(包括链路的数据传输速率、抖动以及丢包率等)。因此,可以根据网络感知的信息计算出用户业务经过网络中任意一条链路的传输时延,所有的终端设备、路由节点、计算节点和动态的链路时延构成一个实时变化的多源点加权图。
算力感知网络中计算任务调度策略的优化目标之一便是最短传输时延的路径选择,基于Floyd算法可以计算出将用户业务路由至各个节点的最短时延以及其对应的具体调度路径,进而选择时延最短的计算节点作为最佳计算节点及根据Floyd算法确定的路径作为最优路由策略,如算法1所示。

算法1 基于Floyd算法的算力感知路由分配策略输入:算力感知网络中计算节点状态Z,计算节点数目N,算力感知网络中链路状态W,用户业务的算力需求S,用户业务数目K输出:任务调度路径P,任务处理节点X1:基于Floyd算法计算将用户业务路由至各个计算节点的最短时延Dmin,获取最优调度路径P'2:根据Dmin选择时延最短的计算节点以及对应路径作为调度策略,计算最短时延D*min,获取最优调度路径P*和最佳计算节点N*3:for k=1:Kdo4: for n=1:Ndo5: ifN*(k)==n6: ifSk,2≤Nn,2且Sk,3≤Nn,37: 最佳计算节点N*不变8: 最优调度路径P*不变9:更新节点存储资源状态 Nn,2:=Nn,2-Sk,210:更新节点计算资源状态 Nn,3:=Nn,3-Sk,311: else12: 重复步骤6的判断,依次循环遍历N个节点直到资源满足或者回到初始节点停止13: 更新最佳计算节点N*(回到初始不更新)14:更新最优调度路径P*(回到初始不更新)15:更新节点存储资源状态 N*,2:=N*,2-S*,216:更新节点计算资源状态 N*,3:=N*,3-S*,317: end if18: end if19: end for20: end for 21: return 最佳计算节点N*,最优调度路径P*
然而,算力感知网络作为一种面向B5G/6G通信的新型网络架构,与传统的无线网络面临同样的问题,即网络负载不均衡,网络中部分计算节点的计算任务超过所能容纳的最大任务数目,导致计算任务的处理时延过长,无法满足时延敏感型的新型网络业务需求。与此同时,网络中另一部分节点可能没有计算任务达到,处于资源空闲状态,没有充分利用全网的算力资源,导致算力资源利用率低下。因此,仅仅基于Floyd算法选择最短时延的路由策略,进而确定计算节点的方案在网络负载不均衡的情况下,无法联合优化计算任务路由策略和算力资源的分配。
如算法1中第3~20步所示,根据Floyd算法已经确定的路由分配策略,如果一个计算任务被分配的计算节点已经过载,则将计算任务循环调度到下一个有剩余算力资源的计算节点。为保证用户的公平性,计算任务按照标签顺序优先获取网络的算力资源;为降低算法的计算复杂度,计算任务在重新选择计算节点时,默认循环至下一个有剩余算力资源的计算节点即可,无需再次基于Floyd算法优化调度策略。
假设边缘算力网络系统中路由节点的个数为R,则本文基于Floyd算法的CARA策略的算法时间复杂度为O(R3KN2),若使用暴力搜索算法来遍历求解用户业务的计算节点选择、路由控制以及存储、算力资源分配,其时间复杂度为O(NKRR),相比于具有指数级时间复杂度的暴力搜索算法,随着路由节点和用户业务数目的增加,本文方法时间复杂度显著下降。
4 仿真实验
本节对基于Floyd 算法的算力感知路由分配(CARA)策略进行仿真实验。首先对仿真场景和参数进行说明,然后展示仿真结果并对其进行分析。
4.1 仿真场景与仿真参数设置
在仿真实验中,考虑多终端设备、多路由节点、多边缘计算节点的场景,如图2所示。在模拟的算力感知网络系统中,包含3个边缘计算节点、6个边缘路由节点,以及若干发出业务请求的终端设备,其数量可以进行具体的设定,所接入的路由节点随机生成。路由节点之间的链路动态连接,相连两个路由节点之间的数据传输速率动态变化,如图2的权值所示,计算节点与路由节点之间的链路连接固定,各个节点之间的链路连接情况以及数据数传速率如图2所示。
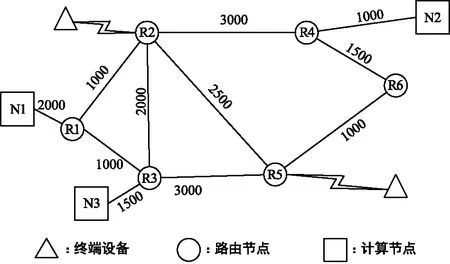
图2 仿真场景Fig.2 Simulation topology
如表1所示,设置默认情况下的算力感知网络系统参数。

表1 仿真参数设置
假设K个用户业务均为同时发起,算力感知网络的初始状态为无任何任务执行。
以图2所示的网络场景作为测试系统,与本文提出的CARA策略进行对比的就近调度算法描述如下:用户业务始终选择部署位置最近的计算节点,即接入R1、R2的用户业务选择N1计算节点,接入R3、R5的用户业务选择N3计算节点,接入R4、R6的用户业务选择N2计算节点。
4.2 评价指标
4.2.1 满意用户数
若任务获得所需要的算力资源,而且任务处理完成总时延不超过允许的最大时延,则认为业务处理成功,即:
(13)
(14)
I(k)=I(k1)I(k2)。
(15)
因此,满意用户数为:
(16)
4.2.2 业务平均处理时延
为了统计所有K个用户业务的平均任务完成时延,本文将网络超负载之后没有得到所需算力资源的用户业务处理时间附加等待时延:
(17)
式中,Κout为过载之后没有获取所需的算力资源的用户业务集合。
综上所述,系统中用户业务的平均处理时延为:
(18)
4.2.3 算力资源利用率
算力感知网络中计算节点的存储资源利用率为网络中使用的存储资源与网络中节点存储资源总和的比值[16],表示为:
(19)
算力感知网络中计算节点的计算资源利用率为网络中使用的计算资源与网络中节点的计算资源总和的比值[16],表示为:
(20)
4.3 仿真结果与分析
4.3.1 满意用户数
系统负载均衡时满意的用户数与系统用户总数的关系如图3所示,系统负载不均衡时满意的用户数与系统用户总数的关系如图4所示。
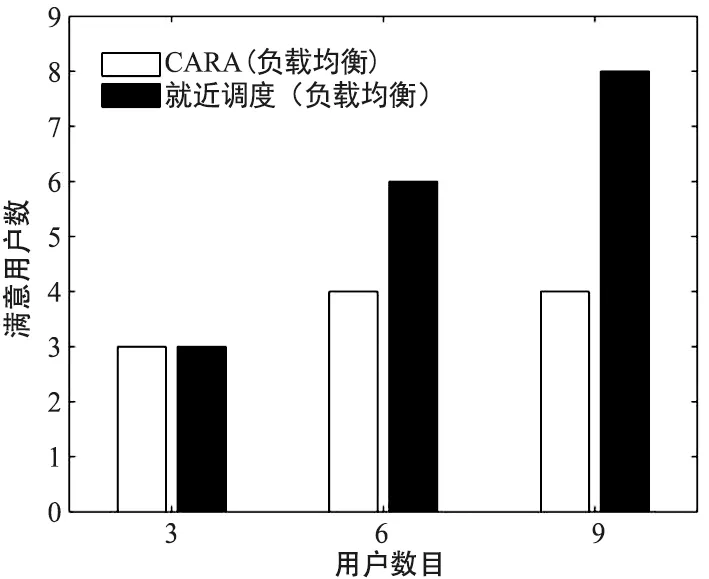
图3 满意用户数与用户数目关系(负载均衡)Fig.3 Number of satisfied users vs users( load balance)

图4 满意用户数与用户数目关系(负载不均衡)Fig.4 Number of satisfied users vs users (load un balance)
由图3和图4可以看出,采取CARA策略满意的用户数一直大于或等于就近调度策略,而且随着用户数目的增加或者负载不均衡时,效果更为明显。当负载不均衡时,采取就近调度策略满意用户数目不随着用户总数的增加而增加,很快陷入系统部分饱和状态,而采取CARA策略直到系统资源全部耗尽才陷入超负载状态。
4.3.2 业务平均处理时延
算力感知网络中用户业务平均处理时延与系统中用户总数的关系如图5所示。随着系统用户数目的增加,CARA调度策略和就近调度策略产生的平均时延几乎都在增加。在网络负载均衡和负载不均衡两种情况下,采取CARA调度策略产生的用户业务平均处理时延均小于就近调度策略,而且随着系统用户数目的增加,采取CARA策略缩短的时延效果更为显著。在系统负载不均衡时,采取CARA调度策略缩短的时延也更为明显,而且随着系统用户数目增加到一定数量之后,在负载不均衡的情况下采取CARA调度策略的时延,也小于在负载均衡情况下采取就近调度策略的时延。

图5 时延与用户数目关系Fig.5 Average delay vs the number of users
4.3.3 存储资源利用率
存储资源利用率与系统中用户总数的关系如图6所示。
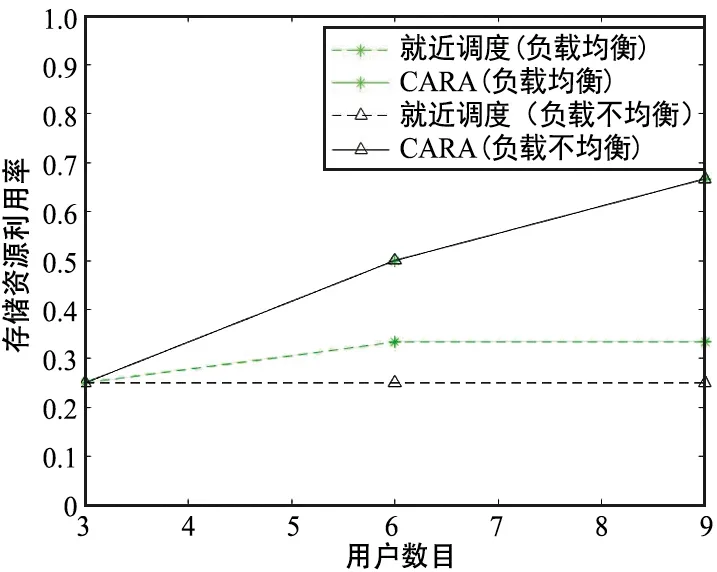
图6 存储资源利用率Fig.6 Storage resource utilization ratio
由图6可以看出,在系统负载均衡与系统负载不均衡两种情况下,采取CARA调度策略时系统的存储资源利用率随着用户数目增加一直在提高,即使在超负载的情况下,存储资源也没有被完全利用,分析原因为此时系统的计算资源已经完全耗尽,存储资源与计算资源是协同处理计算任务的,当存储资源与计算资源没有完全适配计算任务时,会有一种资源无法得到充分利用。采取CARA调度策略得到的存储资源利用率随着用户数目的增加越来越高于采取就近调度策略得到的存储资源利用率,而且在系统负载不均衡时,优势更为明显。
4.3.4 计算资源利用率
计算资源利用率与系统中用户总数的关系如图7所示。

图7 计算资源利用率Fig.7 Computing resource utilization ratio
由图7可以看出,在系统负载均衡和系统负载不均衡两种情况下,采取CARA调度策略时系统的计算资源利用率随着用户数目的增加一直在增加,直到负载达到饱和状态时,计算资源完全利用。与存储资源同样的效果,随着用户数目的增加,采取CARA调度策略得到的计算资源利用率越来越高于采取就近调度策略,而且在系统负载不均衡时,优势更为明显。
5 结束语
算力感知网络通过感知算网资源信息以及业务需求信息,将业务对于算力的需求与泛在分布式的算力资源进行映射,并通过无所不至的网络进行连接,动态、弹性地调度算力资源为用户提供服务,提高算网资源的利用率,达到计算密集型以及时延敏感型的业务对于未来边缘网络的需求。本文提出一种算力感知网络中算力感知路由分配系统,定义一个由通信时延组成的目标函数,并建模一个计算任务调度问题。为解决这一问题,提出了一种基于Floyd的算力感知路由分配(CARA)策略,联合优化了路由策略与算力资源分配。数值仿真结果表明,CARA策略能够在满意的用户数目和系统用户业务处理时延方面提供比就近调度策略更优的性能,并且能够提高网络的存储资源和计算资源利用率。
