基于集成多极限学习机的短期负荷预测
2022-02-09姚岱伟崔双喜戚元星
姚岱伟,崔双喜,戚元星
(新疆大学电气工程学院,新疆 乌鲁木齐 830047)
1 引言
电力系统短期负荷预测是根据负荷发展变化规律的历史数据和其有关影响因素对未来几天或一周负荷进行科学预测,准确的负荷预测是安排电力生产调度、提高电力系统自动化运行水平的重要决策依据[1]。
目前,关于负荷预测已有大量研究,现代预测方法以人工神经网络(Artificial Neural Network,ANN)和支持向量机(Support Vector Machine,SVM)为主。常见的ANN多为采用BP训练方法的三层神经网络,该网络对于电力负荷的不确定性、非线性有强大的拟合和适应能力,但其训练的参数容易陷入局部极小值,限制了其预测精度[2]。SVM在非线性,局部极小点及高维模式识别问题有很大的优势,泛化性强[3],但难以处理大规模样本。极限学习机(Extreme Learning Machine,ELM)是一种新型三层ANN,和传统的BP训练方法相比具有训练速度快等优点。但随机权值输出依然不稳定,为克服这些缺点可通过优化算法优化网络权值和阈值,提高网络稳定性和预测精度[4]。传统的单一预测模型难以满足预测精度和泛化性要求,高效结合多模型可实现高精度预测。Stacking集成学习是一种串行结构的多层模型框架,可采用学习法作为集合策略实现多模型融合[5]。但在Stacking集成学习中往往采用交叉验证的方式得到元学习器的样本,初级学习器需要对样本多次学习,导致学习时间过长[6]。选择相似日可以优化训练样本,减少外界因素对负荷的影响[7],基于相似日的短期负荷预测方法能够降低训练数据规模并利用较少的训练数据达到较高的预测精度[8]。
针对上述问题,本文采用模糊C均值聚类筛选相似日样本集合,引入Calinski-Harabasz指标(CHI)确定最佳簇数。在此基础上采用Stacking集成学习架构,用LSSVM作为元学习器,融合多个ELM预测模型,以实现短期负荷精准预测。
2 基于模糊C均值聚类的相似日选取法
2.1 模糊C均值聚类
FCM是模糊理论和C-means聚类的融合,区别C-means聚类对样本直接划分,FCM给出样本对簇的隶属度确定其所属。在计算开始需要人为设定簇的个数,初始的簇中心随机生成。通过优化目标函数最终得到同一簇样本具有较大的相似度且不同簇样本之间相似度较小。
设样本xi(i=1,2,…N)和簇中心vj(j=1,2,…C)是维度相同的列向量。用隶属度矩阵U=[uij]表示xi与vj之间的隶属度,可得FCM目标函数

(1)
式中m为加权指数,指定为大于1的常量,一般取2,用于控制模糊簇间的共享水平。FCM算法的一般步骤如下:
1)按(1)式约束初始化U;
2)计算簇中心:
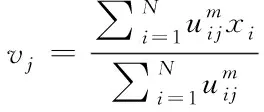
(2)
3)更新隶属度矩阵:
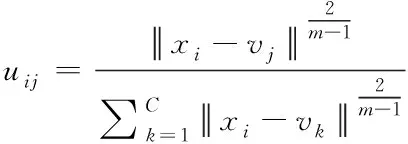
(3)
4)计算目标函数值Jm;
5)重复步骤2)到4)直到Jm收敛到极小值;
6)最终根据U中各个隶属度元素将每个样本纳入其对应的簇。
2.2 Calinski-Harabasz聚类评价指标
簇数目影响聚类效果好坏,CHI是一种广泛使用的聚类评价指标,通过求取分离度和紧密度之比[9]。簇间和簇内散度
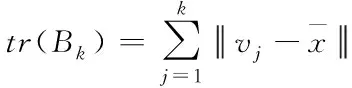
(4)
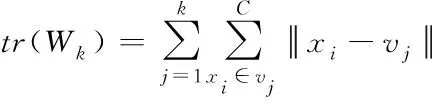
(5)
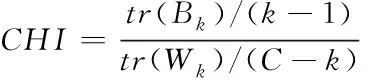
(6)
式中k为当前簇,(6)式分子和分母分别表示簇间和簇内的协方差,分子越大表示簇间越分散,分母越小表示簇内越紧密,即CHI越大聚类结果越优。
3 基于Stacking-ELM-LSSVM的短期负荷预测模型
3.1 Stacking集成学习方法
集成学习是一种模型融合的框架,可以将不同学习模型融合得到更好的预测模型[10]。在负荷预测问题中常采用平均法作为结合策略对多个初级学习器的预测结果进行组合。当训练样本数量规模较大时采用Stacking集成学习方法以第二层元学习器作为结合策略可以取得更好的预测结果。模型结构见图1。
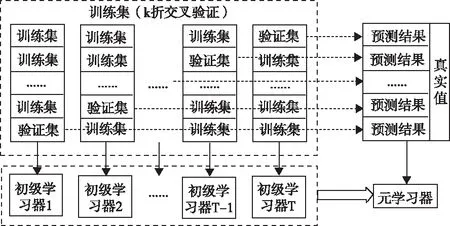
图1 Stacking集成学习方法
3.2 极限学习机
极限学习机是一种单隐层前馈神经网络。训练过程中ELM的网络参数由随机产生和求解线性方程组计算得出,在同等规模数据下训练速度极快[11]。对于输入向量x,ELM的输出向量为
y=βg(ωx+b)
(7)
式中ω和b为隐含层的输入权值矩阵和偏置,随机产生;β为隐含层输出权值矩阵,需要根据训练样本求解线性方程组计算得出。训练时,包含N个训练样本的ELM的隐含层输出矩阵
H=[g(ωx1+b) …g(ωxN+b)]
(8)
则输出权值矩阵可计算为
β=YH+
(9)
H+称为H的广义逆,Y=[y1,y2,…,yN]为样本输出矩阵。由此,ELM的内部参数全部确定。
3.3 最小二乘支持向量机
LSSVM是一种新型SVM方法,SVM训练过程就是求解凸优化的过程,一般采用SMO算法求解,而LSSVM将原优化问题转换为线性方程求解,具有更快的学习速度[12]。LSSVM回归原理:对包含n个样本的训练集{(xi,yi)|i=1,2,…,n}进行非线性回归,xi为输入向量,yi为输出值,LSSVM回归模型可表示为
f(x)=αTφ(x)+b
(10)
式中α、b为权向量和偏置量,φ(·)为高维映射函数。LSSVM回归可转化为二次规划问题
(11)
s.t.yi=αTφ(x)+b+ei,i=1,2,…n
(12)
式中,C(C>0)为正则化参数;ei为样本的误差量。
引入拉格朗日函数求解
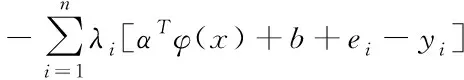
(13)
引入拉格朗日乘子λi,根据KKT条件
(14)
消去α和ei,得到线性方程组
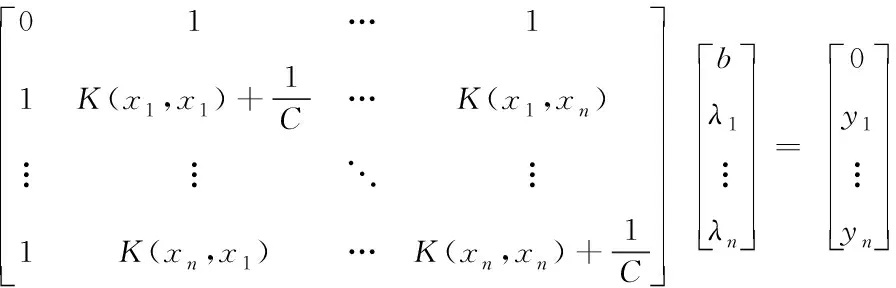
(15)
式中K(xi,xj)=φT(xi)·φ(xj)为符合默塞尔定理的核函数,用于描述高维映射φ(x)。求解出的b和λi,即可得到LSSVM预测模型
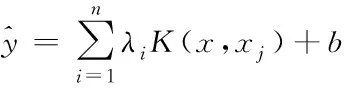
(16)
3.4 负荷预测模型的建立
在Stacking集成学习的框架下以ELM作为初级学习器,对预测日的负荷值进行预测;以LSSVM作为元学习器,对预测结果修正。由于ELM具有极快的学习速度,在该集成学习框架下即使采用交叉验证方法也不会造成训练时间过长的问题。ELM个数设置为10,短期负荷预测流程见图2。
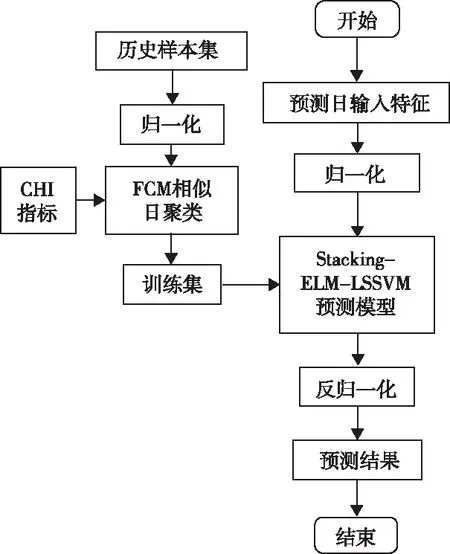
图2 Stacking-ELM-LSSVM负荷预测方法
1)按照变量类型构建原始样本集,对数据特征进行归一化处理;
2)将样本输入特征向量作为聚类对象进行FCM聚类,以CH指标确定最佳簇数。以预测日输入特征向量对应所在簇对应的样本集作为预测模型的训练集;
3)采用0中交叉验证方法训练10个ELM初级学习器,并以验证集的预测结果和真实负荷值分别作为输入和输出得到新的样本集训练元学习器LSSVM模型;
4)对预测日输入数据特征进行归一化处理并分别用10个ELM模型进行预测,得到多组预测结果。随后将多组预测值重构为LSSVM模型的输入特征向量,经LSSVM运算并反归一化,得到预测日的负荷值。
4 算例分析
4.1 样本数据选取
以我国某地区2012年1月1日0:00到2014年3月2日23:30共792天的历史数据用于训练,采用多步预测方法对该地区2014年3月3日48个采样点负荷进行预测,并和真实负荷值对比验证。考虑负荷的时序性、周期性,以及外界影响因素,模型的输入特征主要包括以下三类:
1)负荷数据:短期负荷具有明显的周期性,其中相邻两日的负荷数据相关性最强,因此选取预测日前一日的负荷数据作为输入特征的一部分。
2)气象因素:预测日最高温度、最低温度、平均温度、相对湿度、降雨量。
3)日期类型:按照预测日是否为工作日(周一到周五)和节假日分别标记两个特征为1或0。
输入特征共计55个,输出为预测日的48个采样时间点的负荷值。
预测模型中,ELM隐含层神经元个数设置为96;激活函数为Sigmoid函数;为满足模型训练要求,需要将样本特征进行归一化处理,由于激活函数值域为(0,1)且ELM输出层无偏置,所以输入变量和输出变量分别归一化至[-1,1]和[0,1]。元学习器LSSVM核函数为高斯核函数,惩罚因子和核参数通过交叉验证寻优。
4.2 模型评价指标
本文选取平均绝对百分比误差(EMAPE/%)和均方根误差(ERMSE/MW)作为评价负荷预测模型效果的指标,具体的计算公式
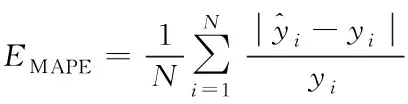
(17)
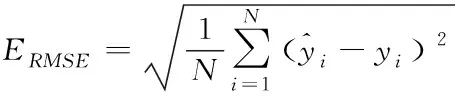
(18)
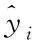
4.3 相似日选取
以输入特征向量作为聚类对象,由于外部影响因素是相似日判别的主要特征,因此将其中48个采样点负荷数据替换为为负荷最大值,最小值和平均值作为聚类特征。聚类算法为FCM,簇数设置为2到10。如图3所示,从CHI的变化中可以观察出最佳簇数为6。在此簇数下,用于训练的样本数为154。
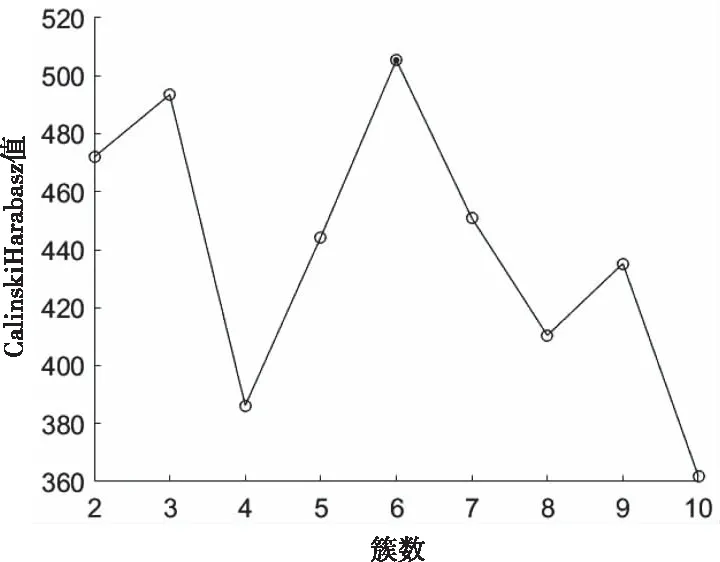
图3 CH指标与簇数的关系
4.4 预测结果对比
为了充分验证Stacking-ELM-LSSVM的预测性能和合理性,将其与单一预测模型ELM神经网络以及传统结合策略下的集成学习预测模型作对比。在选取相似日的前提下,搭建以下四种预测模型用于对比:
模型1:本文提出的基于Stacking-ELM-LSSVM负荷预测模型。
模型2:以误差倒数法作为结合策略替换模型1中的LSSVM元学习器。
模型3:以平均法作为结合策略替换模型1中的LSSVM元学习器。
模型4:在验证集中预测效果最佳的ELM预测模型。
分别采用以上四种模型对预测日48个时刻的进行负荷预测,负荷预测曲线与实际曲线的对比结果及各个时刻误差分布见图4和图5。图中模型1的预测曲线与实际负荷拟合成度最高,误差变化范围最小,较其他三种模型具有更好的预测精度。
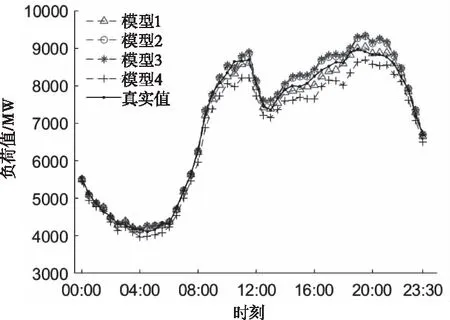
图4 预测负荷曲线与实际负荷曲线
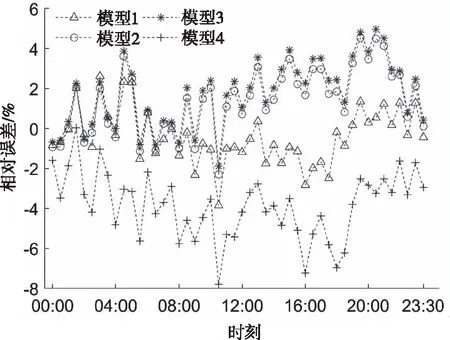
图5 负荷预测误差曲线
为进一步验证本文提出方法的有效性,分别对该地区之后连续3日的电力负荷值进行预测,3月3日至6日四种预测模型的误差见表1。从图表可以看出,ELM可以在一定程度上预测负荷的变化趋势,模型4中单一的ELM由于自身泛化能力不足,在验证集中表现最好的ELM在预测日表现不佳。而集成多ELM预测可以有效降低预测误差,模型3中以平均法作为结合策略可以有效减少单一模型的预测误差,取得不坏的结果,以3月3日为例,和分别降低了1.84%和125.58MW,但该方法也容易受到某些弱预测器的影响;模型2中以误差倒数法作为结合策略,可以赋予在验证集上误差小的初级学习器更大的权重,可以进一步提升预测精度,但验证集样本有时难以反映的各个初级学习器在预测日的误差,且权重根据误差倒数计算,在ELM数量较多时会导致各个模型分配的权重接近,图5中该方法的误差曲线和模型3接近;在表1中,3月4日至6日的预测任务中两种模型最终的预测误差相差不大。模型1以LSSVM作为结合策略,对各个初级学习器ELM在验证集上的预测结果和实际负荷之间的关系进一步学习,预测结果与真实值拟合程度最高,两项误差指标均小于其他三种方法,在其他方法预测效果不佳时该方法最终预测结果仍然具有较高的精度。综上,基于集成学习的预测模型具有更好的泛化性,在此基础上,本文提出的Stacking-ELM-LSSVM预测精度优于其他方法。
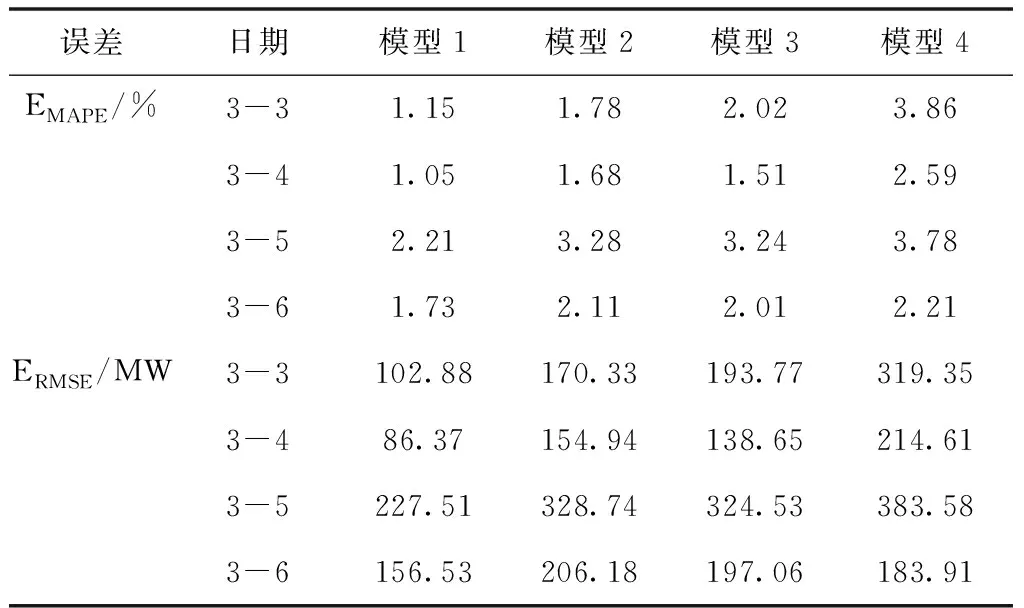
表1 3月3日至6日负荷预测误差
5 结论
本文采用FCM选取相似日用于预测模型的训练;相对于单一预测模型ELM而言,在Stacking框架下集成多个ELM对负荷进行预测,并以LSSVM作为结合策略将多个弱预测器结合成强预测器,可以有效地提高负荷预测精度。算例分析表明,该方法较单一预测模型和传统的结合策略具有较好的泛化性和预测精度。
提出的Stacking集成模型采用单一算法构建初级学习器,虽然具有差异性,但能否全面地体现对数据结构和空间观测的差异性,有待深入研究与改进。
