基于强化学习的变电站巡检路径规划算法
2022-02-09马松玲陈起源康佳欢
马松玲,陈起源,康佳欢
(西安建筑科技大学机电工程学院,陕西 西安 710000)
1 引言
变电站是电力传输与分配的枢纽,电网的《变电站智能机器人巡检系统运维规范》中对油浸式变压器、断路器、隔离开关等 28 类设备的巡视点位以及巡检项目进行了详细规定[1]。由于变电站运维工作量大,工作风险高,出于安全和节省人力成本的考虑,巡检机器人的应用日益广泛[2]。面向在不同变电站下多种电器的巡检任务,巡检机器人的正常工作依赖于有效合理的路径规划[3]。现有的巡检机器人路径规划方法大多依赖于环境建模[4],其优点是机器人能够理解环境,利用地图对所有检测点进行遍历,能够实现全局最优的路径规划[5];其缺点是变电站一旦由于后期维护导致检测点发生变化,需要对变电站环境和检测点进行重新建模与标定,具有较高的维护成本[6]。巡检机器人运行过程中,由于累积误差导致机器人对自身定位存在较大偏差,导致机器人实际巡检路径与规划的最优巡检路径存在偏离,不仅需要变电站工作人员进行定期校准,而且存在较大的安全风险[7]。同时,当巡检机器人需要在不同变电站进行迁移和快速部署时,基于环境建模的方法也导致巡检机器人的迁移代价较高,不利于其推广使用。针对于此,强化学习被用来实现无环境模型下的机器人路径规划。然而,传统强化学习通过维护状态-行为-期望回报映射的Q表来实现最佳决策的迭代寻优,存在维数灾难问题,难以应用于大规模变电站环境。近年来,研究表明在未创建地图情况下利用深度强化学习实现移动机器人的导航是完全可行的,且利用在栅格化地图中初步实现了路径规划[8]。深度强化学习是一种结合了强化学习中的Q学习(Qlearning)[9]和深度学习中的卷积神经网络的算法。深度强化学习采用卷积神经网络作为学习模型,网络参数需通过强化学习反复调整,达到神经网络对Q 表建模的目的。深度强化学习能够将强化学习的决策能力和深度学习的感知能力相融合[10]。然而,基于深度强化学习的方法普遍以图像作为输入,使用较为复杂的卷积神经网络进行学习,这对机器人平台的计算能力提出了较高的要求。针对上述问题,本文提出了一种基于多层感知机的强化学习框架以及巡检路径规划方法。该方法不需要对环境进行事先建模,能够使得巡检机器人完成遍历检测点的巡检任务。
2 基于改进强化学习的训练路径规划方法
2.1 强化学习算法基本原理
对Q表的学习是强化学习算法中的重要部分。Q表存储某一个时刻的状态下,采取动作能够获得收益的期望,即环境会根据机器人的动作反馈相应的奖赏。强化学习算法的主要思想是将状态和动作构建成一张表来存储Q值,然后根据Q值来选取能够获得最大收益的动作。针对无环境模型的任务场景,Q学习一般使用融合了蒙特卡洛和动态规划的时间差分法进行学习,利用贝尔曼方程对马尔科夫过程求解最优策略:
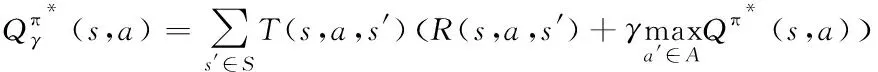
(1)
式中,Qπ(s,a)为状态-动作值函数,用来表示在策略π上,在状态s下执行动作a后得到的累积奖励值,π*表示最优策略,γ是折扣累积奖赏值,T(s,a,s′)表示执行动作a后状态s变为状态s′的概率;R(s,a,s′)表示在状态s下采取了动作a后得到的奖励,依照此策略行动能获得最佳预期奖励值。
在强化学习算法在解空间进行探索的过程中,根据(1)式,Q表的迭代过程为
Q(s,a)←Q(s,a)+α(r+γmaxa′Q(s′,a′)-Q(s,a))
(2)
Q表即状态—动作值函数Q(s,a),α是学习率,γ是折扣因子,r和s′分别是在状态s下选择动作a后得到的即时奖励和下一个状态,a′是在当前策略下机器人处于状态s′时选择的动作,max(s′,a′)是状态s′对应的最大累积奖励值。算法训练目标是为了获取到最优化的Q值。通过对Q表的不断更新能够建立每个状态下对应的可选行为的回报值。根据更新后的Q表可以实现环境状态和最优行为的映射。
2.2 机器人状态-最优行为映射模型
当解空间规模较大时,传统基于Q表维护的方法难以实现有效的状态-行为映射建模。本文采用多层感知机(Multi-Layer Perception,MLP)实现对机器人状态-最优行为映射的学习,以替代传统的Q表模型。MLP神经网络以低维向量为输入,具有计算效率高的特点,能够满足巡检机器人在环境探索过程中进行更加高效训练的需求。与深度强化学习将地图作为环境和机器人的状态输入到卷积神经网络中进行训练不同,本文重新定义了低维度机器人实时状态作为的输入,以机器人的最优运动控制量作为预测输出,如图1所示。
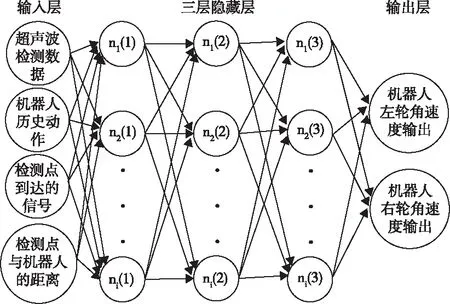
图1 机器人状态-最优行为映射的神经网络学习模型
本文选用三层神经网络,每层32个神经元,MLP每个神经元的值的前向传递公式为
ni,j=f(∑jni-1,j*wj+bj)
(3)
其中:w为神经网络中每层的连接权重值,b是该神经元的偏置值,f是激活函数,nij是代表第i层第j个神经元的值。
激活函数采用双曲正切函数

(4)
针对机器人巡检任务,本文设计的状态输入和行为输出量如下:
1)状态输入量一:机器人到巡检目标检测点之间的距离。将检测点设置为一个信号发射器,巡检机器人在信号辐射范围内都可以接收到该信号,障碍物对于信号的阻挡衰减和反射阻碍在仿真中忽略不计,如图2所示。
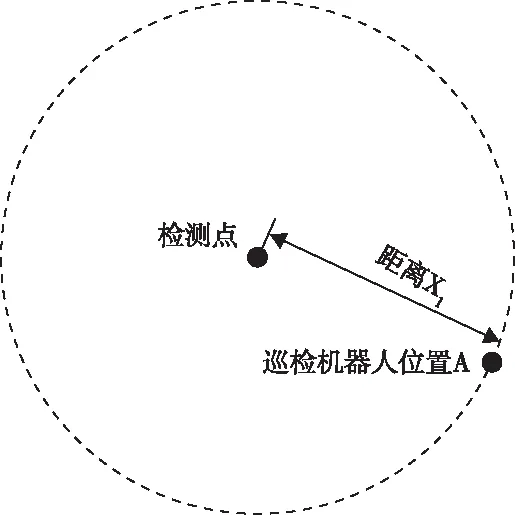
图2 巡检目标检测点设计
根据辐射信号衰减关系,辐射强弱和距离的平方分之一成正比,可以得到巡检机器人与检测点传感器的距离为

(5)
式中,d为巡检机器人与检测点之间的距离,γ为信号的衰减程度。
2) 状态输入量二:检测点的遍历标志位。本文设置nc个检测点,标记为nc1、nc2…nc3,机器人已知检测点的数量,每个检测点对应的到达标记值初始化为0。在仿真环境中模拟当机器人与检测点距离小于0.1时,认为机器人经过了该检测点,则该目标点对应的到达标记变为1。如果全部nc个点遍历,则表明遍历任务成功结束,本文将检测点的经历信号做为神经网络的第二组输入。
3) 状态输入量三:机器人对环境障碍物的感知距离信息。仿真环境地图设置为10×10个单位,超声波传感器检测到的空间距离范围设定为(0,20),机器人搭载12个环形设置的超声波传感器。它们检测到的距离信息为神经网络的第三组输入。
图3 超声波传感器搭载设计
4) 状态输入量四:机器人历史运动行为。机器人会存储过去nstorage步的传感器信息,不足以达到帮助机器人识别检测点方向的目的,所以机器人还需要记录过去nstorage步的历史动作。如图4所示,历史动作的表达和计算方式如下:

图4 检测点大致方向分析
如图所示,巡检机器人由A点移动到B点,与检测点的距离从b变化到a,b、a由检测点传感器得出,为已知量,机器人内部存储器能够记录前nstorage步动作,所以距离c对于机器人来说也是已知量,根据公式

(6)
α角与机器人掌握的距离信息有着明确的逻辑关系,所以本文将机器人前两次动作输出做为神经网络的第四组输入。
5) 状态输出量:机器人左右轮的角速度控制量。本文主要针对两轮的巡检机器人,因此通过左右轮的角速度变化实现对机器人状态的转移。
2.3 奖励函数设计
巡检机器人必须到达每个检测点并对重要设备进行拍照和检测任务,在强化学习框架下,本文建立新的奖励函数来实现无碰撞的遍历巡检效果。
利用奖励函数可以针对机器人的每步行为动作进行打分,是诱导机器人实现避障和遍历检测点的关键[8],本文设计了一种奖励函数

(7)
式中:rste为机器人行走步数的负奖励,nste为机器人移动的步数;rmov为机器人移动距离的负奖励;Lstr为机器人从A点移动到B点的直线距离;rnearcol为机器人接近碰撞时的负奖励;dr-o(t)为t时刻机器人与最近障碍物间的距离;dnearcol为机器人接近碰撞时的距离;rapp为机器人靠近检测点时的距离;dwin为机器人被认为到达检测点的距离;dr-t(t)为t时刻机器人与目标检测点间的距离;nnew为机器人新到达检测点的个数;rnew为机器人到达新检测点的奖励;rall为到达所有检测点的奖励;rcol为出现碰撞情况的负奖励;rout为出现超时情况的负奖励,具体参数如下
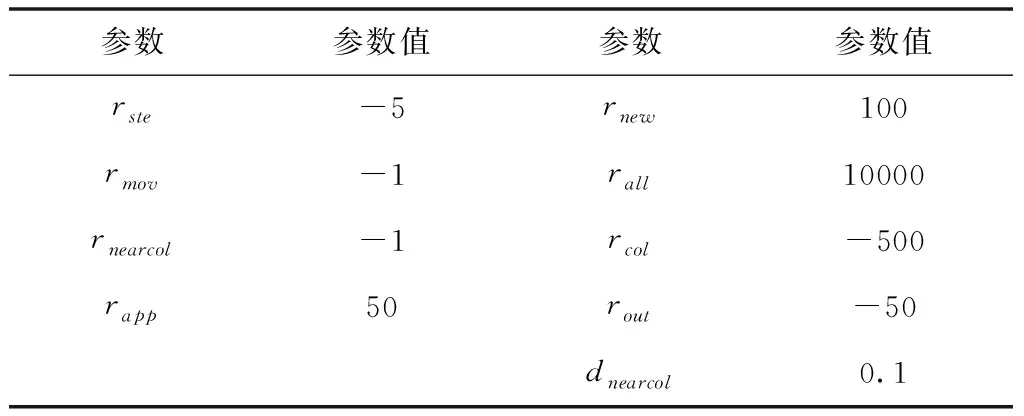
表1 奖励函数具体参数值
对机器人的移动进行负奖励是为了避免机器人无意义的移动[9],巡检需要有效率的遍历检测点的路线。对机器人的移动进行负奖励是为了避免机器人无意义的移动[11],巡检需要有效率的遍历检测点的路线。对于经过新的检测点和临界靠近新的检测点设置较大额度奖励是为了鼓励机器人追求到达检测点,到达一个新的检测点的正奖励和机器人移动带来的负奖励组合起来就可以鼓励机器人不仅趋向于到达新的检测点,还要走最短路径,以更快的获得奖励。对于碰撞的负奖励和临近碰撞的负奖励可以诱导出机器人的避障效果。对于超时的情况设置负奖励是为了使机器人工作更有效率,使机器人学习到能够规划出更有效率的的遍历检测点的运动路线。遍历的最高额奖励设置明确了机器人的最终目标,如果单一设置这个奖励就会陷入稀疏奖励的误区当中,但本文的奖励函数设计方法对机器人靠近新的检测点,到达新的检测点都设置了奖励,使奖励设置的更为密集,帮助机器人能够从易到难完成最终的目标。基于前述定义的网络模型和奖励函数,利用较为成熟的近端策略优化[12]对整个强化学习模型进行训练。强化学习过程如下图5 所示。其中,策略预测神经网络对应于本文2.2节提出的网络模型。值函数预测网络为多层神经网络模型。
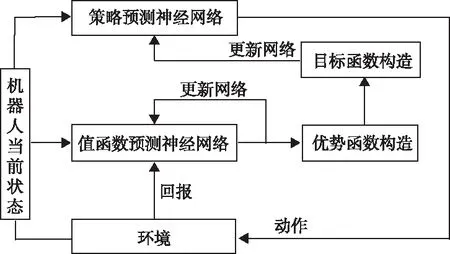
图5 本文强化学习模型
PPO1参数如下表所示:

表2 PPO1参数表
3 实验结果与分析
3.1 仿真环境
为验证本文所提出方法的性能,本文在仿真环境中进行巡检路径规划实验。本文在OpenAI Gym[13]中建立了仿真环境,搭建了10×10的仿真场景。OpenAI Gym是一种较为通用的强化学习平台。根据巡检机器人两轮运动学模型定义了机器人,以空心小圈表示。其搭载了超声波传感器,具有检测距离的功能。在环境中定义了随机障碍物,赋予其不能被机器人穿过,不能被超声波穿透,机器人过度靠近会发生碰撞的规则,以实心矩形表示。进一步定义了检测点传感器,用黑点表示,机器人靠近时会显示其辐射范围圈。仿真环境如图6所示。
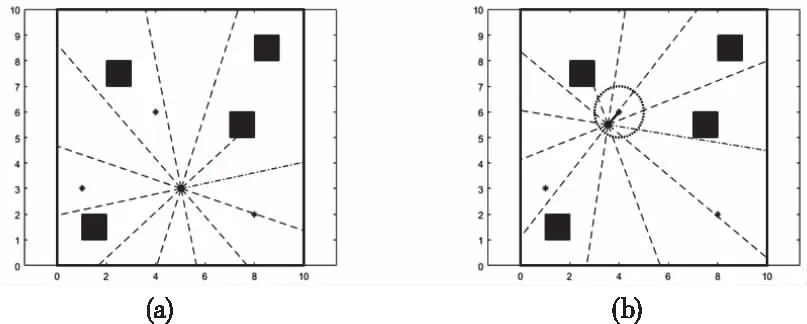
图6 仿真环境
3.2 仿真结果分析
在巡检机器人起点、障碍物位置与大小、检测点位置与个数不变的情况下,通过调整巡检机器人的训练次数,设置对比实验验证本文方法的效果。训练结果如图7所示。
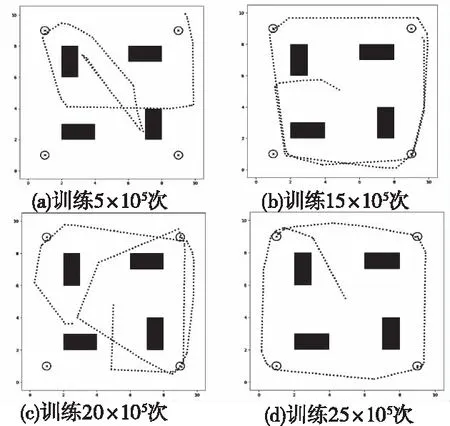
图7 仿真结果对比
从图7可以看出,在奖励函数的诱导下,随着训练次数的增加,机器人经历的检测点数量逐渐增加,路径效率不断提高。且因为奖励函数对于碰撞和临界碰撞的有效负奖励设置,即使在训练次数较少的情况下,机器人依然具有避障的功能。进一步对训练过程中机器人所获得的奖励进行可视化展示,如图8所示。

图8 奖励随步数变化曲线图
由上图可以看出,训练前期因为机器人尚处于探索环境阶段,无法判断什么样的动作会取得高分,所以每次动作获得的奖励较低,甚至可能因为碰撞产生负奖励。随着训练的深入,神经网络的输入有更多的先验知识进入,到达检测点的概率会提升,机器人每次动作获得的奖励不断增加。在训练后期,机器人达到了一直保持收益高奖励的状态,证明了巡检机器人通过MLP神经网络实现强化学习可以达到遍历检测点和避障的目标。
3.3 算法泛化性实验结果分析
针对于变电站后期升级会产生的变化,现设置更改障碍物、改变检测点位置、改变起点位置的对比实验,验证本文方法是否能够保证机器人的自适应性:
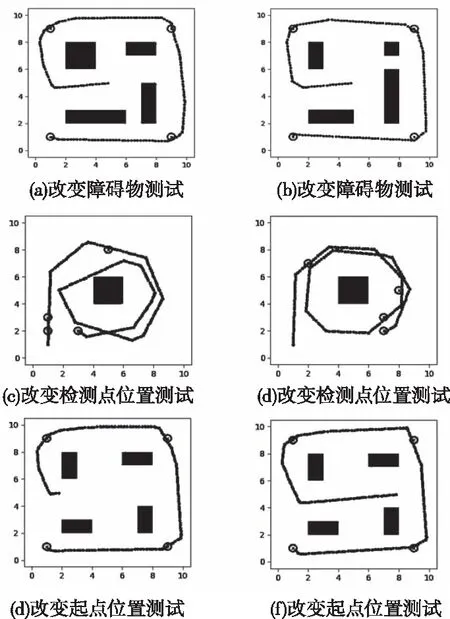
图9 算法泛化性仿真结果对比
其对应的奖励随步数变化曲线图如下

图10 奖励随步数变化曲线图
实验结果表明:在机器人起点、检测点的位置以及障碍物大小、数量和方位发生一定范围的改变时,巡检机器人依然可以通过自学习,在不直接理解环境的情况下,完成遍历检测点且全程无碰撞的目标,证明了本文采用的方法能够保证巡检机器人的自适应能力。
4 总结
本文提出了一种基于强化学习的机器人巡检路径规划算法。在强化学习框架下,提出了有效的策略学习模型和奖励函数。将超声波传感器所获取的与障碍物的距离信息、机器人与检测点的距离和机器人的动作历史等作为多层感知器神经网络的输入,提出了相适应的连续奖励函数,使用近端策略优化对学习模型进行训练,实现对巡检机器人左右两轮的在线角速度最优控制量进行决策。最后,在OpenAI Gym环境中建立算法仿真环境,对巡检机器人进行仿真学习训练,仿真结果验证了本文算法能够使得巡检机器人实现遍历检测点和全程无碰撞的目标,并且具有较高的可泛化性。
