基于边缘计算的城市交通事故风险深度预测
2022-02-09严丽平郭成源
严丽平,郭成源
(华东交通大学软件学院,江西南昌330013)
1 引言
随着城市化的快速发展,车辆数量的激增导致非常多的交通事故发生,造成了社会人员伤亡和巨大的经济损失。预测交通事故风险的能力对于预防交通事故的发生,减少交通事故具有重要意义[1]。目前道路交通安全研究已积累大量的研究成果,由于利用的数据不同,还存在一些不足。如利用交通事故数据方面,大多是事故后的统计工作,事故发生前的风险研究相对较少。
随着智能设备的不断进步,边缘计算技术在智能交通领域取得了重大发展。边缘计算体系结构旨在推动收集、处理与生成数据,它是一个服务沿云到网络边缘的连续体,在数据源头的一侧采用网络、计算、存储、应用核心能力为一体的开放平台,就近提供最近端服务,可以产生更快的网络服务响应,有很大的潜力来解决数据传输延迟这一问题[2]。为了实现交通信息数据的可靠性和低延迟传输,Garg等人[3]将边缘服务器作为中间接口,辅助车辆与云端数据中心间通信,减少了终端节点访问时间和网络拥塞。Yang等人[4]提出了一种融合交通灯模型和车速模型的新型短期交通预测模型,并考虑了边缘计算服务器有限的计算资源,可以更有效地捕捉到交通状况的实时变化。
2 交通风险实时评估模型
边缘计算网络架构主要分为终端节点、边缘服务层和中心网络三层。终端节点层主要为接入边缘服务器的移动设备,在本文中为道路上的行驶车辆,车辆的车载导航设备以及智能手机均可作为终端节点将道路上的车辆信息传送给边缘服务器,边缘服务器再将计算后的信息发送给中心网络,如图1所示。城市地区划分成等大的区域,然后将边缘计算服务器均匀部署到每一个区域,每一个服务器对其所管辖区域的道路车辆信息进行收集和分析。
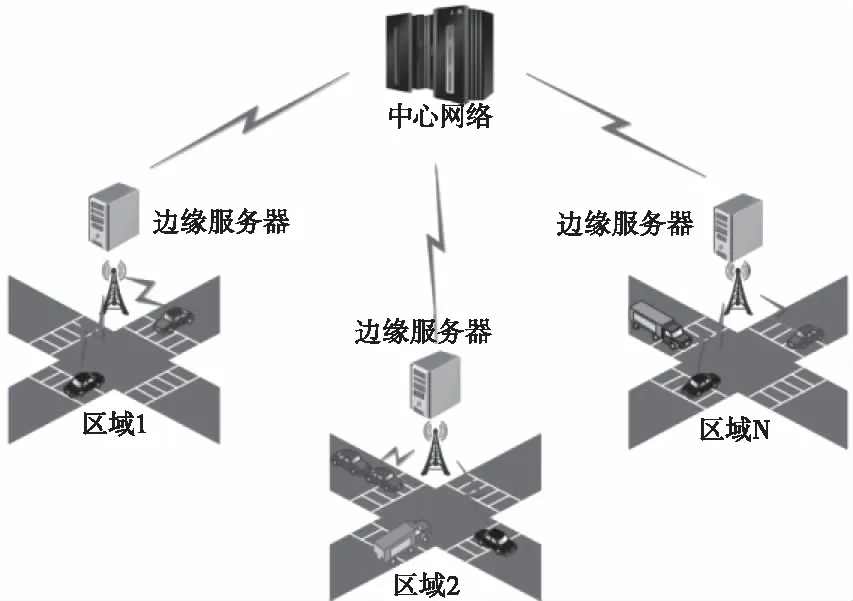
图1 边缘计算架构图
影响道路交通风险的因素有很多,但绝大多数主要来自于行人、车辆和道路。以往对城市道路风险的研究中,众多关于车速离散度的研究通常通过判断车速的分布情况来判断交通流是否处于异常状态,并没有考虑到城市道路车辆行为异常的情况。因此,本文在边缘计算的环境下采用异常车辆和异常车流信息对交通风险进行实时评估。在本文主要从车辆急变道、车辆急加速急减速、车速离散程度三个角度来评估道路的风险。
2.1 急变道行为分析
正常情况下车辆变道时间是比较短的,一般在3-8秒内便可以完成,而且车辆的转向角度也是比较小的,因此可以通过车载陀螺仪或者手机陀螺仪来记录车辆的转角大小。依据行车经验,设置每3秒记录一次转角大小变化记录,将转角大于25度的车辆分类为急变道车辆。在正常转弯时,比如经过十字路口,发生直角转弯的情况,要舍弃该记录。根据这种方法,统计某一区域一个时间段内道路上的急变道车辆数,并增加急变道车辆特征记为B。
2.2 急加速/急减速行为分析
交通运输行业规定,急加速或者急减速并不属于违规行为,但是在道路交通中,经常性的该行为却是引发交通事故的重要因素。通过设置GPS轨迹节点可以有效的记录车辆加速度的变化过程。GPS轨迹节点记为{p1,p2,p3,…ph}(h是采集的总次数),如图2所示。相邻的两个结点设置一个较短的周期,如每2秒记录一次车辆的信息,该信息包括当前车速v、加速度a、行驶方向、位置信息。
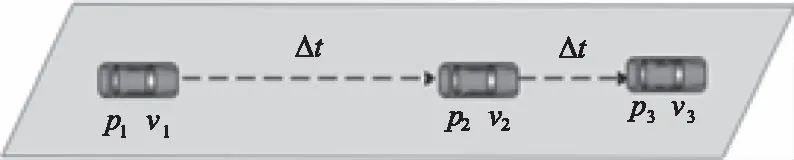
图2 车辆GPS轨迹节点
根据司机驾驶行为“急加/减速”判定标准,加速度按大小值分为三个等级,如表1所示。
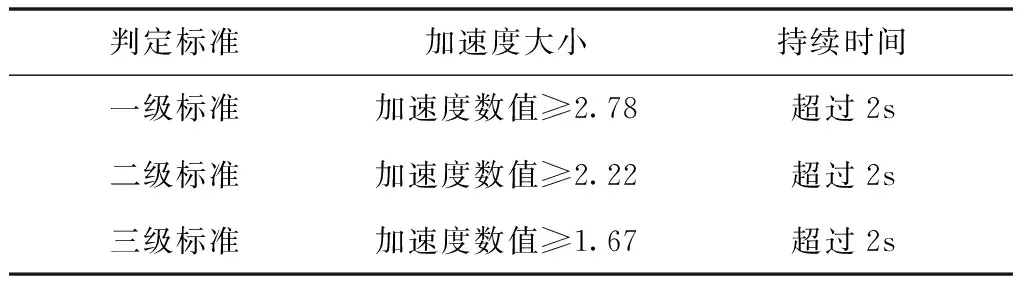
表1 急加/减速等级标准
统计不同标准的急加/减速的车辆数目,增加急加/减速特征S。根据不同的标准可以赋予发生该异常行为的车辆不同的异常值,该部分会在后续风险评估过程详细描述。
2.3 车速离散度分析
根据行业经验,车速离散程度越大说明该路段中超车频率越高,发生事故的可能性就越大。对于众多车辆的车速离散程度,本文用道路车辆速度的标准差σ(v)来衡量,计算公式如下
通过BIM技术的可视及可协调化的特性,进行多专业碰撞检查、净高控制检查和精确预留预埋的位置,可大大减少返工,加快工程建设速度,节约施工成本。
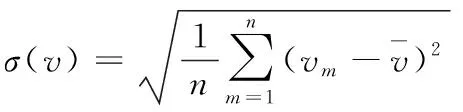
(1)
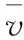
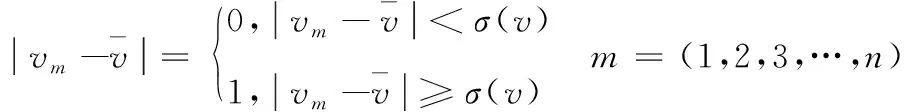
(2)
那么,存在车速异常的车辆总数U为
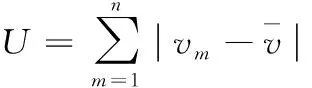
(3)
2.4 风险评估
不同异常行为的车辆对于交通影响的程度是不同的,某些异常行为例如一级的急加速和急减速行为相对于急变道而言更容易造成交通事故的发生。当多种异常行为同时存在于一个车辆的时候,那么该车辆对于道路交通风险造成的影响是非常大的,因此可以对不同异常行为赋予不同的参数值,并根据此值来进行后续的道路风险评估。根据车辆异常对道路风险影响的业内经验,可以对前面描述的三种车辆异常行为赋予不同的异常参数值。具体参数设置如表2所示。
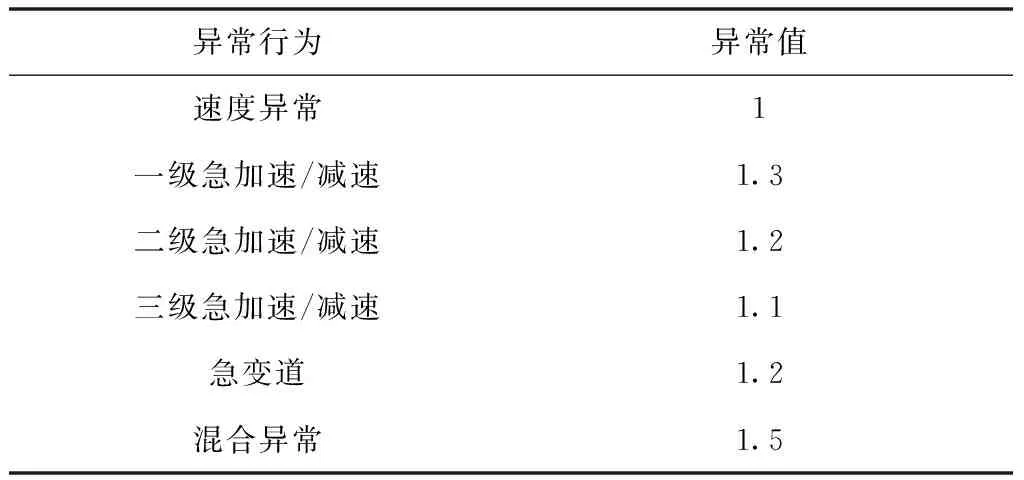
表2 异常行为参数设置
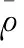
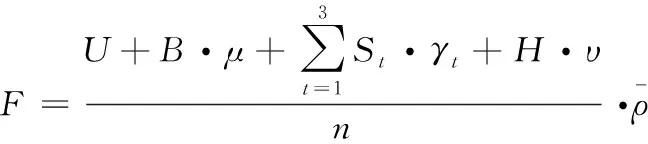
(m=1,2,3,…,nt=1,2,3)
(4)
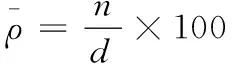
(5)
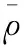
3 交通事故深度神经网络预测模型
通过对一些交通事故数据的分析后,发现很难准确预测一个区域在某一时间段内是否会发生交通事故,因为复杂的因素会影响交通事故,例如天气、司机分心或者行人突然出现等。因此,本文采用预测交通事故发生频率的方式,即最近几天同一时间段每小时发生的交通事故的平均数量。首先,将交通事故数据在空间和时间上离散化,使其可以通过机器学习算法进行处理。然后采用LSTM深度神经网络模型构建交通事故风险的深度预测模型,并将处理后的数据输入到该模型中。经过数据训练后,将近期的交通事故数据输入训练后的模型中,然后从输出中得到预测的事故风险值。
3.1 数据处理
历史交通事故数据很多时候不能直接用到训练模型当中,需要对数据进行一个合理的处理,本文使用纽约市2018-2019年的交通事故数据集对提出的方法进行仿真验证。对主要地区分割成24*24=576个区域,每个区域的大小为1km*1km。将交通事故数据集逐一地归到所处的事故发生区域,并按照发生事故的时间先后进行排序。图3为其中两周内一个时间段内发生交通事故的频率热图,颜色越深的方块表示该区域单位时间内发生交通事故的数量越多。

图3 交通事故频率热图
3.2 LSTM深度神经网络预测模型
本文所使用的模型是LSTM深度神经网络预测模型,因为LSTM模型在训练有时序性数据的时候有很好的效果。如图4所示,输入层由两部分组成。第一个输入是最近的交通事故频率序列,第二个输入包含期望预测的区域的位置信息,它直接输入到全连接的层中。深度模型的隐含层由4个LSTM层和2个全连接层组成。模型的最后一层是输出层,输出给定预测区域的交通事故风险R(频率)。
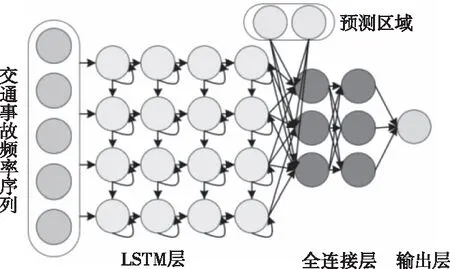
图4 LSTM深度神经网络预测模型
最后根据第2节所得到的实时交通风险值F与深度预测模型所预测的交通事故风险值R按照下式计算,得到最终的交通事故风险值R′。
R′=R*F
(6)
这样做的好处在于深度预测模型的事故频率预测值可以受到实时评估的风险的约束。当预测值R较大时,如果实际道路车辆很少,且交通顺畅,那么F就会较小,最后所得到的风险值就会减小,反之增大。
4 仿真验证
为了验证本文所提出的方法的可行性,实时数据采集使用Matlab进行仿真并获取车辆以及车流数据。通过对过去交通事故频率的计算,对交通事故多发区域设置了相对较多的异常车辆数据,对事故较少的区域设置较少的异常车辆信息进行仿真。
深度神经网络预测模型选取2018-01-01 ~ 2019-04-01的数据作为总数据,选取2019-04-01 ~ 2019-07-31的数据进行测试。最后20%的训练数据作为验证数据。为了验证本模型的有效性,本文设置了另外三种常用的预测模型进行对比,分别为LR、DNN以及DTR三种模型。通过计算预测结果的平均绝对误差(MAE)、均方误差(MSE)和均方根误差(RMSE)来评估不同模型的准确性,结果如表3所示。
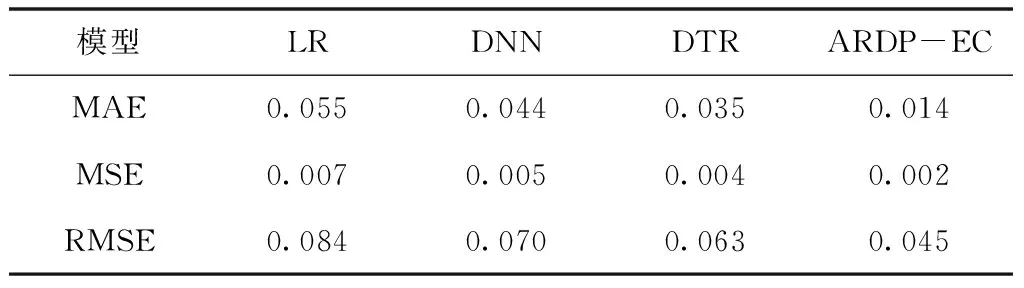
表3 不同模型预测结果各项评估指标值
可以看出本文所提出的ARDP-EC模型在三种误差上的值较其它三种模型都比较小,说明该模型预测的结果更为准确。另外计算出高风险区域(事故频率大于5)交通事故预测的准确率,如图5所示。可以看出ARDP-EC模型的平均准确率在65%左右,明显地高于其它三种模型。
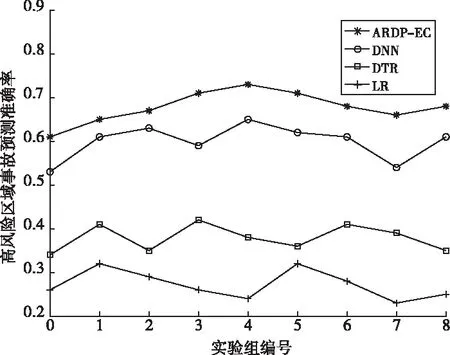
图5 高风险区域事故频率预测准确率
为了更直观的看出预测结果,本文以2019年8月10日~13日实际的交通事故频率为例,比较了不同模型的预测结果。图6和图7分别为实际的交通事故频率图和四种不同模型的预测结果图。颜色较深的方块区域为交通事故频率较高的区域,从ARDP-EC模型的预测结果来看,有多个区域的预测结果符合实际事故频率,而其它三个模型预测的结果整体来看很不理想。ARDP-EC模型的预测结果远优于其它三种模型的预测结果。

图6 实际事故频率图

图7 四种模型预测图
5 结束语
本文采用边缘计算技术对道路车辆信息进行收集和分析,一方面,大大减少了车辆与服务器之间通信的延迟,获取的数据更加精确;另一方面,结合道路实时风险水平和历史交通事故数据信息对城市区域交通事故风险进行预测,使得最终预测结果比LR、DNN以及DTR三种常用的预测模型更加准确可靠。结合这一预测结果可以对在高风险区域驾驶的司机进行有效提醒,从而避免交通事故的发生。
