改进卷积神经网络在预制构件工时预测中应用
2022-02-09栾方军崔洪斌韩忠华孙亮亮
栾方军,崔洪斌,韩忠华,孙亮亮
(沈阳建筑大学信息与控制工程学院,辽宁 沈阳 110168)
1 引言
由于工艺流程中的一些如拉毛预养护等工序,受环境温度、湿度、光照的影响较大,布料工序受机械喷口流速和混凝土原料配比等因素影响,如养护工序受养护窑余温温度差异影响,导致生产工时呈现一种不可控的波动特性,使得利用历史数据的统计性结果所获取到的工时与实际工时相比有一定偏差。随着生产进程的推进,不断累积的工时偏差,导致生产线上所执行的生产计划常出现“脱轨”现象,即使通过资源调度和生产计划调整也很难弥补工时偏差带来的影响,从而降低了整个生产计划的可执行性,导致生产计划难以有效的指导企业实际的生产运作。通过分析预制构件生产过程,发现预制构件生产过程受季节,湿度和构件形状等因素影响导致构件生产工时波动较大,因此目前从生产工艺角度设计的工时计算方法存在的误差难以得到修正,使得生产计划难以有效的指导企业实际的生产运作。从挖掘历史生产数据价值的角度进行研究,探索一种通过历史数据对工时预测模型进行训练以得到更契合实际生产过程的工时的有效方法,近些年,深度学习飞速发展,由于深度学习能起到有效对已知数据进行解释的作用,并且具有学习和分析的能力,因此深度学习能够通过对一定规模的历史数据进行分析来实现对未来部分结果的较高精度的预测。国内外学者已将深度学习理论广泛应用于各领域的预测问题。Hamdulla Askar[1]等人提出了一种新颖的深度学习方法来预测图数据库中查询任务的执行时间。设计并实现了一个基于长短期记忆(LSTM)的准确而有效的模型,以预测执行时间。杨建军、何利力[2]为了降低企业生产车间空调能耗,基于长短期记忆(LSTM)网络构建了一种工业空调启动时间预测模型。使用该模型对车间空调提前启动时间进行预测,并将预测结果应用于车间空调系统的启动控制,以达到节能目的;采用平均绝对百分误差(MAPE)对预测模型进行整体误差评估,它结果表明:LSTM较好地解决了生产车间空调系统启动时间预测问题,相较于传统预测方法有着更小的MAPE。胡军、郑文东[3]由于当前的深度学习模型没有特定的学习机制来捕获时间序列预测中的突变信息。为此,提出了一种新的深度学习模型来捕获数据之间的突变信息。为了捕获突变信息对目标序列的影响,在编码器的注意力机制中设计了一个新的函数映射,以处理历史隐藏状态和单元状态信息的融合。Hamdulla Askar[4]提出了一种新颖的深度学习方法来预测图数据库中查询任务的执行时间。设计并实现了一个基于长短期记忆(LSTM)的准确而有效的模型,以预测执行时间。石晶,彭其渊[5]等人分析列车晚点时间传播规律,构建列车晚点时间被动关系网,表示列车到达、出发时刻的制约关系。基于广义回归模型公式,利用Logistic回归模型和Poisson回归模型分别预测相邻、相间列车晚点时间。边冰,郑军[6]等人提出一种基于RBF神经网络的公交车到站时间预测,以公交车到站时间为输入,以两站相差的时间为输出建立模型。李楠、焦庆宇[7]等人提出一种基于时间-空间-环境数据的深度学习模型(Spatio-temporal-environment deep learning model,STEDL)来提高滑行时间预测的准确性。使用STEDL模型对香港机场离场航空器滑行时间进行预测验证。张盛涛、方纪村[8]等人采用深度学习中的长短期记忆神经网络(Long Short-Term Memory,LSTM)方法预测道路旅行时间,通过调节LSTM隐藏层单元数和训练次数得到最优的时间相关的LSTM模型。通过对国内外研究文献综合分析,深度学习理论在时间预测问题方面已经得到了一定的应用并且可以得到比较良好的预测效果,但是在预制构件生产问题方面尚没有深度学习理论应用的先例,同时由于综合考虑神经网络效率及结构复杂度和用于训练神经网络的构件生产工时历史数据不止包含其长度、宽度等空间特征相关属性,还包含了具有一定规律性的季节、气候等时序相关属性,所以提出一种基于改进卷积神经网络的预制构件生产工时预测方法。
该方法在对卷积神经网络进行改进,在卷积结构后添加了门控循环单元,使其能够利用历史数据对神经网络模型进行训练,并通过不断的学习来对生产工时进行更精准的预测,该方法填补了预制构件在生产工时预测方面的技术空白,能够为企业生产计划的编制提供数据支持。
2 预制构件生产工时预测
装配式建筑预制构件生产企业中构件生产的各工序上所需加工时间的预测问题可以看作是一类非线性回归问题。使用收集到的包含时间信息的历史生产数据作为预测模型的输入,将需生产构件在生产线各工序上加工时间的预测数值作为模型输出,构建了一种基于深度学习的工时预测模型。该模型的模型结构不仅能够通过学习提取出构件自身属性与构件加工所需时间之间的特征关系,也能够探索出构件在季节更迭,气候变化等因素影响下产生的相关时间序列与加工时间之间的隐性特征关系。
2.1 模型训练使用数据集
该模型训练所使用数据集为调研所在装配式建筑预制构件生产企业生产工厂内记录的构件在生产线各工序段的实际生产加工历史时间数据。该数据集内共有两万条数据,每条数据包含三十六个属性,分别是:构件长度属性,构件宽度属性,构件体积高度属性,构建类型属性,构件生产所处环境温度属性,构件生产所处环境湿度属性,构件生产时间,构件生产所处季节,构件生产时刻天气等。数据集内数据类型主要分为浮点型(float)和字符串类型(string)。
2.2 模型训练数据集的预处理
对于深度学习神经网络需用到大量的历史数据,由于庞大的数据集具有数据多样性和数据类型复杂性,无法保证训练中的数据处于同一量级,所以需要进行数据预处理,以保证对于模型训练的有效性。需要对数据集的预处理依次分为三步,分别是:字符数据处理、数值数据处理和数据升维处理。
● 字符类型数据预处理
首先对于数据集内离散的字符类型数据,需用到one-hot编码进行文本特征提取,one-hot编码将字符型数据转化为以0和1表示的二进制表达方式,例如转化数据集中判断类数据,是则为1,否则为0,这样可以将字符型特征转化成为数值类型特征,能够被深度学习模型识别。
● 数值类型数据预处理
对于数值型数据,在并不清楚各个维度中的数据重要程度时,需要对数据集中各个维度数据进行标准化,使各维度数据的重要性得到平均,更好的对网络进行训练。文章中使用了z-score标准化,该方法易于计算,能够很好地将数据集中不同量级的数值类型数据转化为同一量级,保证数据间可比性。

(1)
其中x是原始数据,μ是整体数据的均值,分母为数据的标准方差。
● 数据的升维处理
在传统的卷积神经网络接口中,一般接收的输入对象为三维图像数据,因此在进行卷积操作之前对数据进行升维处理,原始数据为两万条,每条数据拥有36个属性,所以首先将数据重构成为(6,6)的形状,然后继续数据重塑为(6,6,None)使原本的数据转化成为形状为(6,6,1)的单通道灰度图,这样就可以将数据输入卷积神经网络进行卷积操作并进行训练。
2.3 装配式建筑的生产工时预测模型设计
针对于装配式建筑预制构件生产工时预测问题,提出一种基于深度学习的局部调度方法,利用历史构件生产工时数据和神经网络模型学习能力,实现对装配式建筑预制构件生产工时的预测。
2.3.1 激活函数的选择
激活函数一般来说是非线性函数,激活函数主要用途是使模型对于非线性分布的数据具有映射和学习的能力,如果不设置激活函数,无论模型的结构及深度如何都只能实现对线性输入的学习,无法对非线性的输入实现非线性映射。选用激活函数为ReLU函数,原因如下:
● ReLU函数
如式(2)所示,ReLU函数使大于0的x值保持不变,当x为负时使x值为0
ReLU(x)=max(x,0)
(2)
在深度学习模型中,相比较其它两个激活函数,ReLU的表达能力更加强。ReLU函数不会像Sigmoid函数,当输入趋近于负数时,预测值与正确值之间的差距会逐渐减小,出现梯度消失的现象,导致模型学习能力下降。
2.3.2 损失函数的选择
损失函数大致分为两类,一类是分类损失函数,一类是回归损失函数,由于需解决的问题属于回归问题,所以模型所需损失函数需要从回归损失函数中选取。
MAE(平均误差)损失函数与MSE不同,如式(3)所示,MAE主要是算出真实值与预测值之间误差的绝对值之和的均值。

(3)
模型中所选损失函数为MAE损失函数,因为MAE损失函数对于数据中的异常值和误差值具有更好的鲁棒性,在实际生产过程中,生产数据也许会因为某些原因导致与常规数据产生偏离,但却符合实际情况,此时的数据就属于异常点,由于训练数据集本身规模较大,必然会产生一些异常点,所以选用具有更好鲁棒性的MAE损失函数。
2.3.3 神经网络的构建
1)卷积神经网络模型
卷积神经网络与全连接神经网络的模型结构整体相似,但在每相邻的两层之间却不像全连接神经网络每个节点都与上一层的所有节点相互连接,卷积神经网络相邻两层之间有部分节点相互连接,且每一层的节点会组成一个三维矩阵。卷积神经网络能够卷积层的叠加和迭代学习到数据间的潜藏特征,并且通过反向传播不断更新改进参数促使得出的结果无限的接近真实解。但针对所提出的工时预测问题,卷积神经网络虽然有效但是缺少对于数据集中时间序列相关属性的特征提取能力
2)改进卷积神经网络模型
在改进卷积神经网路的生产工时预测方法中,将待解决的问题看作是一个非线性回归问题。因为数据集中包含多个时间序列相关属性,所以在改进卷积神经网络结构中加入了GRU层,提取数据中的时间特征,提升网络结构的学习能力,降低模型的损失度,提升预测的精准度。在改进卷积神经网络结构内的卷积层之间添加池化层,目的是在保证模型深度的情况下,提取数据主要特征,减少模型参数,防止过拟合,提高模型泛化能力。添加Dropout层防止训练中产生过拟合现象。改进卷积神经网络结构中选用ReLU函数作为激活函数,可以更加有效的进行梯度下降及反向传播,避免梯度爆炸及梯度消失等现象,减少整体的计算成本。

图1 网络结构图
如图1所示,改进卷积神经网络结构中分为特征提取块、初始点时间预测块、GRU网络块。Conv1至Conv7皆为卷积层,卷积核形状设置为2*2,步长为1,且设置padding=same使得输入和输出的形状保持一致。池化层采用最大池化,将最大池化窗口设置为2*2,步长设置为1。利用Flatten层的操作,将多维数据拉平,方便接入后面的全连接层。将特征提取块、初始点时间预测块输出数据结合作为GRU网络块的输入,并最终输出一个一维数据作为总体输出结果。
相比于使用普通的卷积神经网络来处理装配式建筑预制构件生产工时预测问题,创建的改进模型结构不仅能够使用卷积层提取出数据集内含的空间特征,更添加了门控循环单元,使得模型能够提取出到数据集的时间特征,学习到数据集中隐含的时间序列关系。相比于单一使用卷积神经网络,构建的神经网络能够进一步提升模型整体的学习速度,提高模型损失值下降速度,提升模型的精准度,提升模型学习效果。
3 仿真研究
为了验证改进卷积神经网路的生产工时预测效果,搭建仿真环境,应用Pycharm 2018a作为编程工具,使用Python3.6和基于tensorflow-GPU2.0.0得深度学习框架进行仿真,操作系统为Windows10,使用英特尔i5-8500 6核处理器,内存大小为8G。
3.1 仿真分析
它数据选取调研过程中所获得的装配式预制构件车间收集排产工时数据,在前期工作中,调研企业生产车间已经配备完善的构件追踪系统和产品数据记录机制,对于构件排产工时有大量数据记录,将这些数据进行整理,按照固定7:2:1比例将数据分为训练集、测试集和验证集,并在仿真过程中将数据进行预处理以应用至神经网络模型的训练。
3.2 模型参数
在对收集到的装配式建筑生产车间历史数据进行预处理后,可以得到[6,6,1]形式的三维数组。且最终的输出形状设置为1。
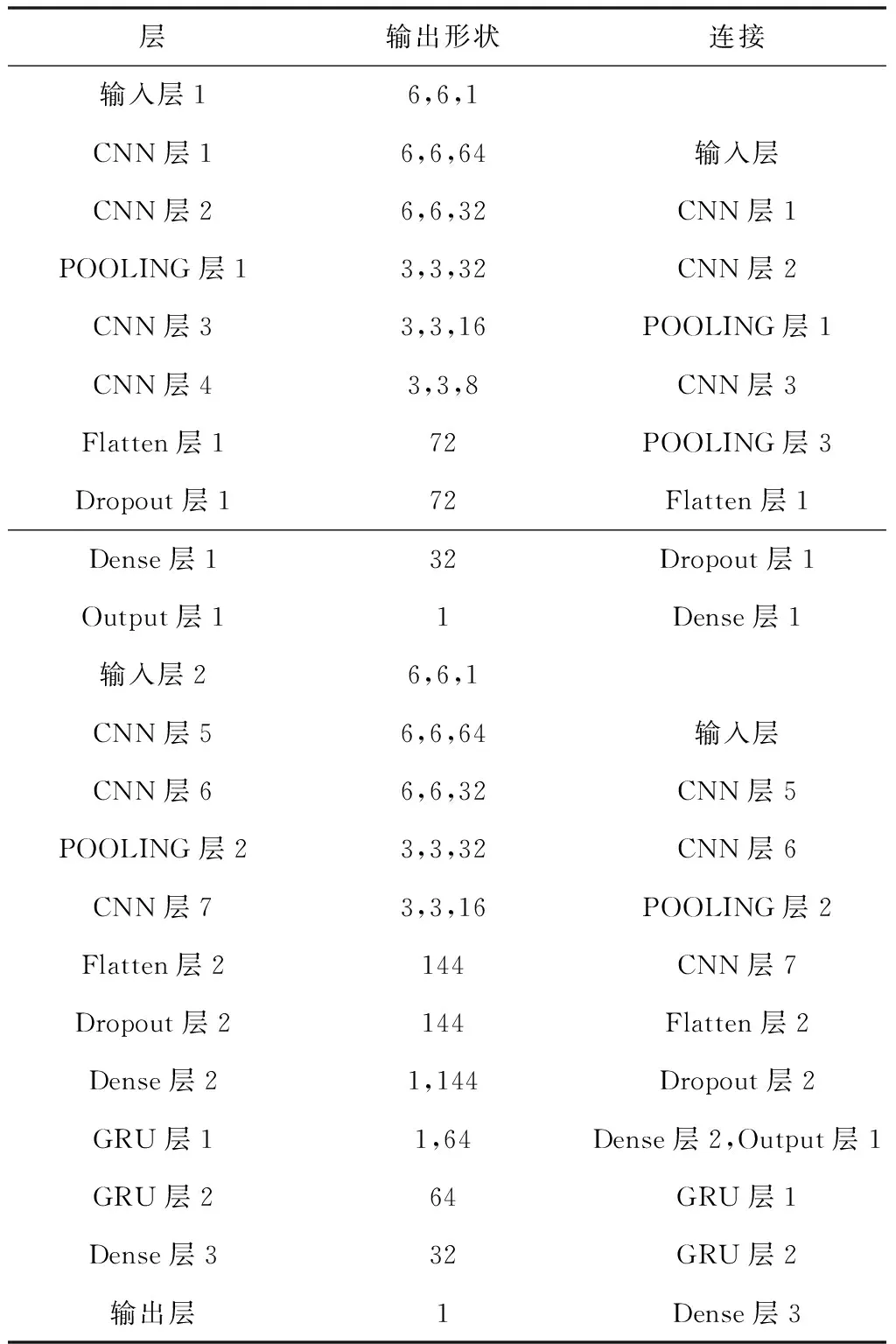
表1 模型参数
3.3 模型效果与分析
通过使用从某装配式建筑生产车间收集的数据对神经网络模型进行训练,在训练过程中对模型参数进行调整使其达到最优效果,通过训练模型给出的损失函数和对比测试集得出的精准度,可以判断模型效果是否通过调参得到上升。
设置模型的学习率为0.01,优化器参数选择Adam,设置batch size为32,epoch为15。
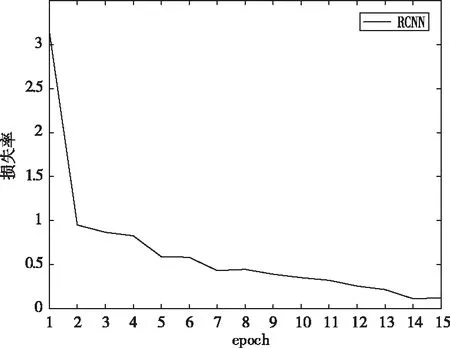
图2 损失函数下降曲线
如图2,为模型的损失函数下降曲线,其中X轴为迭代代数,Y轴模型的损失率。
如图3,为模型的精准度曲线图,其中X轴为模型的迭代代数,Y轴为模型的精准度。通过分析损失函数曲线图和精准度曲线图可知,随着模型迭代次数的增加,其精准度无限趋近于0.98并保持平衡,可以为装配式建筑预制构件生产工时预测提供有力的理论支持。

图3 精准度曲线

图4 模型效果对比
3.4 方法它及效果评价
预制构件生产线具有多工序、多工位的特点,每天投产的大量构件上线前要在多个模台上进行分配,因此,其排产过程具有典型NP-hard问题的特征。预制构件生产技术来源于现代浇筑式混凝土浇筑工艺,其生产工时受车间内环境因素的影响会产生波动,这使得实际生产工时与传统工时计算方法获取到的工时存在误差,随着生产进程的推进,这种误差不断累积,导致利用历史数据的统计性结果编制的排产计划难以有效指导预制构件的复杂生产过程。对于预测工时误差导致的排产计划脱离实际的问题,提出了一种基于改进卷积神经网络的工时预测方法来进行解决,用更加精准的工时来辅助制定排产计划,使排产计划更加贴合实际生产。
为了验证改进工时预测方法的效果,对其进行仿真它。依据某预制构件生产车间的生产流程可将生产线划分为六道工序,分别是:支模工序、绑筋工序、布料工序、拉毛预养护工序、蒸养工序、拆模工序。以部分实际生产数据作为它数据,将包含改进卷积神经网络工时预测方法在内的多种预测方法获取的工时与实际工时进行对比论证。
3.4.1 评价指标介绍
采集某工厂内的部分预制构件生产订单与场内环境信息如表2,并对表内的两万条数据进行随机抽取组成仿真它数据。对改进卷积神经网络工时预测、卷积神经网络工时预测和传统工时预测方法分别从精准度、复杂度、稳定性、合理性、工时分量偏差度(即所有构件在所有工序内工时的偏差度之和)、工时总量偏差度(即整批构件经过某种排产操作后得到的总加工工时和实际的总加工工时之间的偏差度)六个方面进行综合评价。精准度、复杂度、稳定性、合理性四个评价因素以优,良,合格,差进行评判。利用构件加工的工时偏差值进行计算可得出各预测方法的工时偏差度。
i∈{1,2,…,n},j∈{1,2,…,m}
(4)
Fsum=max(0,Tdsum-TCsum)
(5)
Bsum=max(0,TCsum-Tdsum)
(6)
fsum=αFsum+βBsum
有很多员工每天的生活一成不变,他们处理相同的事务,体验相同的挫折,最后获得相同的结果。正因为每天都体验同样的事情,因此一线员工最知道存在什么问题,同时对于解决这些问题都有着很好的想法。精益寻求将员工中未利用的想法和改善措施与企业的总目标结合起来,来追求企业的长期绩效[3]。一个好的精益组织一定是充分利用了员工的智慧。当员工参与度发生变化时,企业精益生产的效果也必然会出现变化。
(7)

(8)
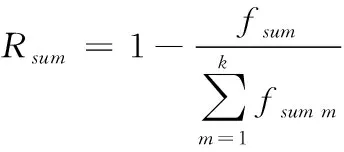
(9)
n为构件数,m代表工序数;α和β分别代表构件的超前和滞后权重,设置为0.8和0.2;TCsum为构件加工完成时间;Tdsum为构件加工目标完成时间。式(4)为各构件在各工序上工作时间偏差值之和;式(5)为所有构件通过排产得出的总加工工时相比较实际工时的超前时间;式(6)为所有构件通过排产得出的总加工工时相比较实际工时的滞后时间;式(7)为构件总加工工时的偏差值。
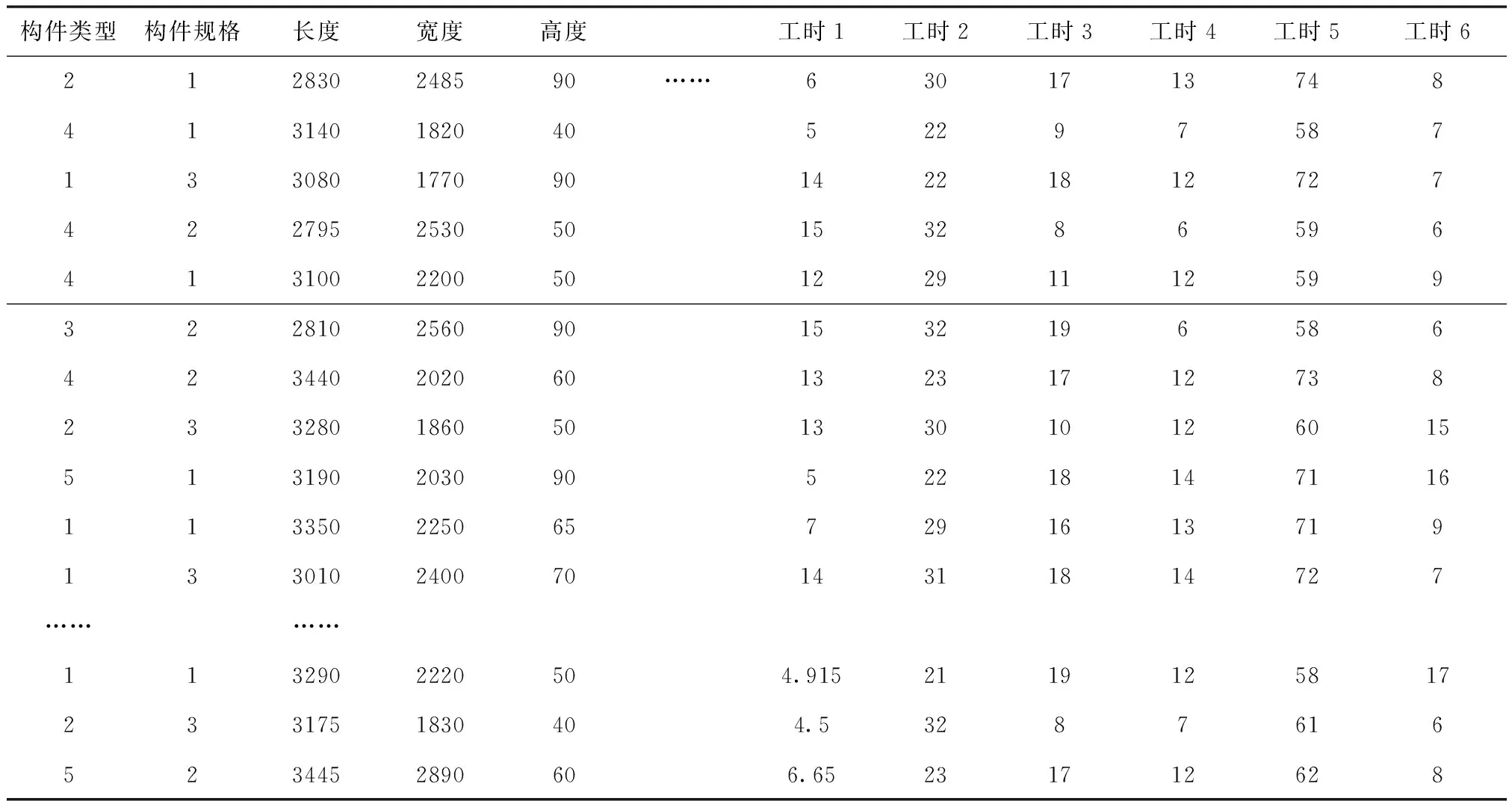
表2 预制构件生产订单与场内环境信息数据表
3.4.2 评价结果
图5是构件工时预测时间与实际生产工时对比折线图。图中直观的表现出各种工时预测方法所得的工时与实际工时的偏差大小。表3为评价指标参数表。精准度、复杂度、稳定性、合理性四个属性的评价结果可通过它数据得出。工时分量偏差度、工时总量偏差度可分别通过式(8)和(9)得出。为评价对象个数。

图5 构件工时预测时间与实际生产工时对比折线图
综合评价中,由于每一个评价因素的重要程度不同,所以需要对六种评价因素的权值进行设置,分别设置为0.2、0.1、0.2、0.1、0.2、0.2,并将权值数值设置为矩阵。

(10)
V={0.2,0.1,0.2,0.1,0.2,0.2}
(11)
R=V*U
(12)

表3 评价指标参数
依据式(12)可以得出最终的评价结果如表4所示。通过综合评判结果可知,改进卷积神经网络结构效果更优,改进工时预测方法获取所得工时从总体分析效果更佳,获取到的工时数据更加贴近实际。改进工时预测方法的应用能够进一步提升管理人员对预制构件生产进程的管控能力。

表4 评价结果
4 结论
针对预制构件生产工时预测问题进行研究,对生产线上历史生产工时数据进行了分析,提出一种基于改进卷积神经网络的生产工时预测方法,该方法运用改进卷积神经网络对历史数据进行训练,能够有效地为预制构件提供较为准确的生产工时。通过它验证表明该方法的结果精准度高,相比较其它方法具有更高的仿真效果。
在装配式建筑产业内,装配式建筑生产工厂内的生产结构复杂,生产工艺多样,生产进度影响因素多变,生产线上可调度空间小,生产产品移动代价高等原因,所以下一步还需将提出的预测方法部署至实际工厂生产管理系统中,以测试方法的实用效果。
