基于机器学习的降雨—滑坡灾害链直接经济损失脆弱性评估*
2022-02-05李子轩
李子轩,杜 鹃,徐 伟
(1.北京师范大学 地理科学学部 环境演变与自然灾害教育部重点实验室,北京 100875;2.北京师范大学 地表过程与资源生态国家重点实验室,北京100875;3.应急管理部-教育部 减灾与应急管理研究院,北京 100875)
现有降雨—滑坡灾害链的研究主要集中在两方面:第一个是诱发滑坡的降雨阈值[1-4],包括降雨诱发滑坡的阈值形式,不同的研究区的阈值曲线特点,以及加入阈值曲线的新的变量等;第二个是降雨滑坡敏感性(易发性)评估,采用不同的方法如逻辑回归模型、随机森林模型等实现降雨滑坡敏感性分布图的绘制[5-9]。而关于滑坡的社会经济影响方面的现有研究仍然很少[10-11]。一般来说,由于数据缺乏,大多数关于滑坡的社会经济影响评估是有限的[12],并且在量化方法上呈现一定的复杂性[10]。如ZHANG等[13]利用动态投入产出模型和重力模型评估公路沿线滑坡导致的间接经济损失;ZUMPANO等[14]以农村土地为研究对象基于山体滑坡事件估计了历史和未来的经济损失。但针对降雨—滑坡灾害链致灾与成害过程联系,即脆弱性研究仍较为缺乏。在滑坡脆弱性研究中,往往难以对致灾因子的具体强度进行表征,因此研究者更多的关注社会脆弱性,即通过影响灾害损失的社会经济多方面因素进行脆弱性评估。如SAHA等[15]采用深度学习算法结合灾害脆弱性影响要素的空间分布,评估了不丹的滑坡脆弱性。本研究以贵州省毕节和六盘水两市的降雨—滑坡灾害链事件为例,利用机器学习方法建立降雨—滑坡灾害链直接经济损失脆弱性的定量评估模型,以期为降雨—滑坡灾害风险评估提供关键参数,也为风险管理实践提供参考。
1 数据与研究方法
1.1 研究区介绍
本文以贵州省毕节、六盘水两市作为研究区进行降雨—滑坡灾害链直接经济损失脆弱性定量评估。两市地处贵州省西部云贵高原一、二级台阶地区斜坡地带,地形地势复杂;同时位于亚热带季风区,全年湿润,降水较多,时有强降水发生。两市滑坡灾害发生频繁,尤其是在降水密集的6—8月份。根据毕节市自然资源和规划委(https://www.bijie.gov.cn/bm/bjszrzyhghj)和六盘水市自然资源局(http://zrzyj.gzlps.gov.cn)统计,至2021年年末,两市共有具有变形迹象的地质灾害隐患点2 171处,占贵州全省的21.66%。其中滑坡隐患点950处,占贵州全省的19.62%(图1)。

图1 研究区与滑坡编目数据位置示意图(基于贵州省自然资源厅标准地图服务网站审图号为黔S(2022)005号的标准地图制作,底图无修改)
1.2 脆弱性评估数据选取
本文所使用的数据如表1所示。基于灾害系统的功能体系,本文从致灾因子危险性、孕灾环境敏感性以及承灾体暴露三个维度,选取可能影响研究区暴雨—滑坡直接经济损失脆弱性的因子,共3个类别9个变量。
(1)致灾因子指标。降雨强度指标直接影响着滑坡发生的可能性以及影响强度。本文选取降雨持续时间(D)、累积有效降雨量(CR)作为致灾因子指标。其中CR考虑了距离灾害发生时间点不同时间长度内的降雨可能对滑坡发生的贡献不同,计算公式为[16]:
(1)
式中:CR为累积有效降雨量,i为前期降雨的n个时段,Ri表示每个时段内的降水量,α为经验降雨系数,取0.8。
(2)孕灾环境指标。不同地形地貌、植被覆盖、水文条件、以及人类活动因素都可能对滑坡的发生产生不同的影响。本文选取高程(DEM)、NDVI、距水系距离(DS)和距道路距离(DR)作为脆弱性模型的孕灾环境指标。
(3)承灾体指标。通常,在人口和财富集中的地区,灾害可能导致的直接经济损失也会相对较高。本文采用GDP和人口密度(PP)作为脆弱性模型的承灾体指标。
在得到各指标原始数据之后,将历史暴雨—滑坡点分布与各指标空间分布图叠加,提取灾害点各指标的属性值,共同构成降雨—滑坡灾害链直经济损失脆弱性评估的数据清单。其中直接经济损失折算为2015年基准价。
1.3 脆弱性评估方法
考虑到影响直接经济损失脆弱性的要素是多方面的,且不存在明显的线性关系。为更好地建立致灾因子强度—损失的关系,本文在脆弱性模型的选取中选择基于决策树算法的随机森林、XGBoost机器学习算法进行定量评估,并进行评估效果的对比分析。
(1)决策树算法(Decision Tree,DT)。决策树算法本质上是一个树形结构的算法,树的节点代表对输入因子要素的判断,树的分叉则代表对每一个判断结果进行的输出,通过多次的输出过程得到了最后的叶节点则代表了模型最后输出的结果。
决策树算法常用于分类问题与回归问题。当目标问题为回归问题时,主要指CART回归树算法,其核心步骤为:
(2)
式中:yi为输入样本点的值,c1和c2分别为两组样本的输出均值。式(2)表示在建立回归树时,对于任意用于划分的样本特征A,对应的任意的划分点s两边划分成的数据集D1和D2,求出一个使得D1和D2各自所对应的均方差最小,同时两者均方差之和最小所对应的特征和特征值划分点。通过输入灾害损失脆弱性的影响因素作为回归样本,建立非线性回归模型,通过影响因素的属性值实现对灾害损失的预测。
(2)随机森林模型(Random Forest,RM)。随机森林算法是机器学习领域常用于分类问题和回归问题的算法之一。通过随机森林的回归模块可以实现对灾害损失的预测,从而将其使用于灾害脆弱性和风险评估中。
随机森林算法也是基于决策树的一种算法,不同的是,它是对多个决策树的综合运用,来避免单一决策树容易出现的过拟合问题。用于回归问题时,随机森林由多个互不相关的回归树组成,且模型的最后输出结果由每一个回归树来确定。
(3)极致梯度回归模型(XGBoost)。XGBoost 是一种用于构建监督回归模型的机器学习方法,属于Boosting算法族GBDT(梯度提升决策树)算法框架下中的一种。在目标问题为回归问题时,目标函数包括梯度提升算法损失和正则化项:
(3)

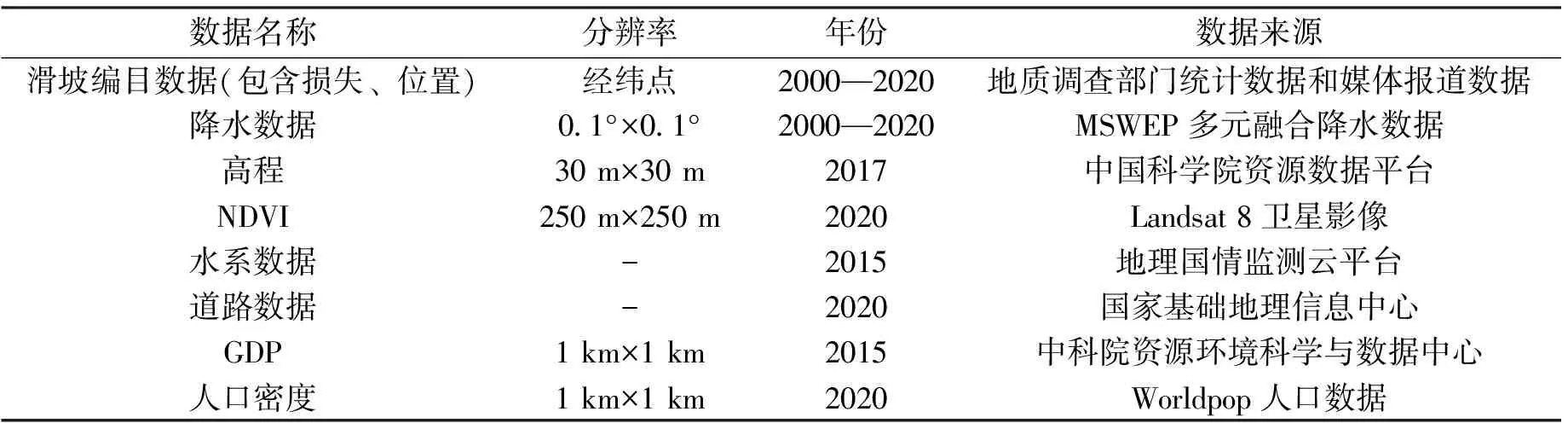
表1 研究数据

表2 脆弱性变量相关性检验矩阵
在回归问题中常使用reg:linear作为损失函数,之后使用二阶泰勒展开近似,在基于残差的拟合条件下将目标函数改写,使其最小化;而正则化项的处理需要将写成树结构的形式,并代入目标函数,得到最终优化之后的目标函数,即一个二次函数,根据二次函数的性质公式可以得到最优的参数和目标函数最小值。
XGBoost由于其正则化,并行计算、引进特征子采样等优点,在避免过拟合的同时,又能减少计算,在处理灾害损失预测等多元非线性回归问题时有着较大的优势。
在进行模型模拟之后,本文采用RMSE(均方根误差)、MAE(平均绝对误差)和R2(确定性系数)统计量对模型的拟合效果进行检验。其中R2越接近1表示拟合效果越好,反之则越差;RMSE和MAE统计量越接近0表示模型的拟合效果越好。
2 研究区降雨—滑坡灾害链直接经济损失脆弱性评估结果与分析
2.1 变量筛选
在选取变量后,需要对变量的自相关性进行检验,以剔除具有较强相关性的变量。本文采用斯皮尔曼相关系数进行检验,该相关系数对数据的分布没有要求,适用范围广。变量的相关性矩阵如表2所示。
基于多重共线性的考虑,不存在明显与其它多个变量均相关的变量,因此,本文将8个指标均纳入模型中进行计算。
2.2 基于机器学习模型的脆弱性评估结果对比分析
在得到降雨—滑坡灾害链事件损失数据清单之后,将数据写入模型进行训练。其中,模型的相同类型参数应尽可能保持一致。本文中选取70%的样本作为训练集,30%的样本作为预测集,构建脆弱性预测模型:
Loss~f(D,CR,NDVI,DEM,DR,DS,GDP,PP)。
(4)
模型的训练结果如表3所示。模型训练结果显示,随机森林算法相比于决策树算法拥有更高的精度,XGBoost算法在研究区的直接经济损失脆弱性评估中缺乏可靠性。
为了更直观的展现模型的预测效果,使用模型测试集数据建立实际损失—预测损失曲线图,其中y=x曲线(虚线)表示实际损失与预测损失重合线,即越靠近曲线,模型的预测效果越好。图2展示了模拟预预测效果较好的随机森林算法模型4(图2a)以及决策树算法模型1(图2b)的实际损失与预测损失关系。
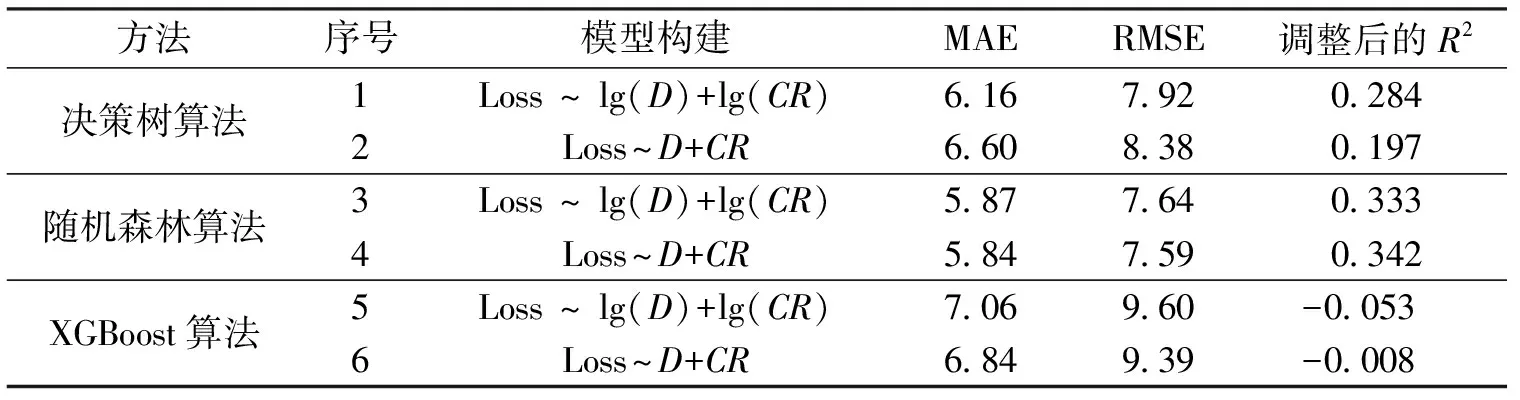
表3 不同机器学习算法得到的模型训练结果比较
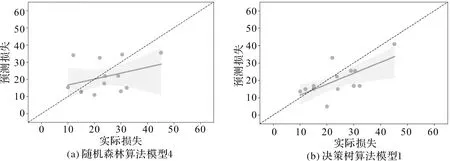
图2 不同模型的实际损失—预测损失曲线

表4 不同模型事件测试集中损失极值区域预测的效果实例比较
图2的散点图表明,基于测试集的损失预测结果均落在了y=x曲线的两侧,但对于损失的极大值和极小值的预测效果较差,损失的中位数附近预测结果较好。一方面,损失的极值本身就是相对小概率的事件;另一方面,已有的数据量条数较少限制了模型对于损失极值的预测效果。从散点图的比较来看,决策树算法的预测趋势更接近于参照线y=x,总体预测效果要好,随机森林方法虽然统计检验量表现较好,但在实际预测中偏离值仍然相对较大(表4)。
虽然基于机器学习算法的模型无法提供显性关系的表达式,但可以通过对回归分析中变量重要性的计算来比较不同影响因素之间的重要性关系。图3是决策树算法和随机森林算法的变量重要性结果。

图3 不同模型的变量重要性结果
两类模型前四个重要解释变量总解释率均超过80%,但不同模型对变量重要性的识别不同。决策树模型前四重要的解释变量为NDVI、GDP、高程以及距河流距离,而随机森林模型中累积有效降雨量(CR)是最为重要的变量,单一变量解释率达到0.51,距道路距离(DR)变量次之,重要性只有0.15。人口密度因素(PP)在两个模型中得到的变量重要性均低于0.05。根据变量重要性结果的分析,不同模型对于变量的识别也存在不同的结果。决策树算法采用的是单一的树状结构对应特征要素进行回归结果的输出,而随机森林模型是随机选取同时训练多棵决策树的集成学习算法,相比决策树算法来说对非平衡和内部偏差比较大的数据有更好的效果,在特征采样过程中也更为复杂。因此决策树与随机森林输出的变量重要性也不同,相比较而言,随机森林方法能够更好地反应不同变量对于最终损失值的贡献程度。
对于数据相对较为不平衡的灾害损失数据来说,随机森林方法往往具有更好的效果。因此在应用脆弱性评估模型对区域脆弱性评估时,考虑区域的自然环境和社会条件特征也较为重要,进行多模型的比较,更有助于选取最适合目标评估区域的模型。
3 结论与讨论
3.1 结论
本文通过对贵州省毕节、六盘水两市的降雨—滑坡灾害链事件的分析,基于决策树、随机森林和XGBoost机器学习算法,建立了定量的直接经济损失脆弱性评估模型。结果表明:
(1)随机森林和决策树方法具有相对较高的精度,最优模型的R2分别为0.284和0.342,RMSE分别为7.92和7.59;
(2)模型均显示出对损失极大值和极小值预测的不精确;
(3)不同的模型对脆弱性贡献变量的重要性识别结果也不同。决策树模型中脆弱性贡献变量最为重要的是NDVI、GDP和高程,而随机森林模型中则为累计有效降雨量和距道路距离。
3.2 讨论
机器学习方法已经在灾害脆弱性评估领域得到使用,包括滑坡和其它灾种的研究[15,17-18],但已有的基于机器学习的脆弱性评估重点在区域特征的空间分布,采用基于网格单元的评估,更多表征的是区域脆弱性的相对大小;或是基于行政单元进行多要素的社会脆弱性评估。本文的创新点在于,通过灾害事件点的社会经济属性数据与损失数据,建立了基于灾害事件的机器学习的降雨—滑坡脆弱性评估模型,从而实现了损失绝对值的评估,同时提供了可能的灾害直接经济损失预测,从而提供更为精确的脆弱性评估。同时本文对比了多种机器学习算法,更好反映了不同算法在模型构建中的差异。与传统的致灾因子—灾情范式的脆弱性评估相比,机器学习方法扩展了评估的范围,纳入了更多影响区域灾害损失的因素,能够更全面的反映区域特点;而与传统的滑坡脆弱性评估相比,本文通过降水要素与滑坡导致的损失在模型中的结合,提出了能够运用于降雨—滑坡灾害链的脆弱性评估模型。
基于本文的研究,结合现有的灾害风险管理工作现状,本文认为以下内容仍然需要在之后的研究中得到重视:
(1)目前滑坡损失数据的获取较为困难。自然灾害的社会经济影响或风险评估需要翔实的损失数据作为基础。在未来的研究工作中,需要重点关注如何建立可靠的损失数据收集和筛选机制,有关灾害管理部门也应推进拓宽数据获取渠道,建立统一可获取的滑坡灾害损失编目数据库。
(2)对降雨—滑坡灾害链的研究现有的重点仍然在致灾过程中,关注滑坡可能导致的社会经济影响相关工作较少。本文的研究为可能的降雨—滑坡灾害链综合灾害风险评估框架的构建提供了可行的方法思路,以适应在自然灾害影响不断变化的大背景下灾害风险管理工作的需要。
