基于流式计算引擎的时空查询中间件设计与实现
2022-02-03秦俊峰
秦俊峰,熊 文
(云南师范大学 信息学院,云南 昆明 650000)
0 引言
传统关系型数据库已经无法满足大规模空间数据的存储和分析需求。利用大数据组建进行适当扩展,以支持大规模空间数据的存储、分析计算的方法逐步进入人们的视野,代表性的成果有HadoopGIS[1],GeoSpark等[2],但是这些工具只支持批处理场景下的应用分析,并不支持流式计算场景,因此本文参考GeoSpark的设计机制,扩展了Spark-Streaming功能,实现了一个中间件,这个中间件支持空间数据对象,空间分区和空间索引,并且实现了空间最近邻域搜索,区域查询这两个空间查询。
1 背景与动机
1.1 空间查询介绍
常见的空间查询有空间最近邻域搜索、区域查询等。KNN是用来查询距限定范围内距离指定空间对象最近的k个空间对象。本文对KNN定义如下:给定一个空间对象集合S和一个查询空间对象q,以及查询距离r(r∈(0,+∞)),KNN就是从S中找出q半径范围r内距离最近的k个空间对象,记作KNN(P,q,r,k),其形式化的定义如公式(1)所示(pk为距离q第k远的点)。
KNN(P,q,r,k)={p|p∈P,dist(p,q)≤dist(pk,q)∩dist(p,q)≤r,p≠q}
(1)
RQ是用来查询给定空间范围内的某一类、某几类或者所有的空间对象。本文对RQ的定义如下:给定一个空间对象集合S和一个查询范围q,RQ就是从S中找出在范围q内的所有空间对象,记作Range(P,q)。其形式化的定义如公式(2)所示。
Range(P,q)={p|p∈P,pinsideq}
(2)
1.2 空间分区和空间索引
空间分区按照一定的规则将空间对象划分为多个不同的集合,是并行查询或计算的基础。空间索引对集合内部的空间对象按规则进行组织,减少搜索过程中的无效计算。常见的空间分区方式有网格分区和多级网格分区[3],常见的空间索引方式有四叉树索引、KDB树、R树等[4]。
2 空间查询在流式场下的实现
本文主要在Spark-Streaming流式计算引擎上实现了KNN,RQ这两种时空查询算法。因为Spark-Streaming是一个微批原理的计算引擎,所以两个查询算法都是在被查询数据集组成的RDD以及一个微批次查询请求数据集组成的RDD上基于Join的原理实现的。
在Spark当中Join是一个非常重量级的操作,因此本文着重对此进行了优化,先将被查询的POI数据生成一个Spatial RDD,对此RDD进行等网格分区,分区完成后对每个分区建立局部索引,并缓存至内存当中,以供后续查询使用。接下来便是查询请求数据,可以根据查询请求对应的参数,确定请求所涉及的网格分区,执行查询时只针对查询所涉及的分区进行计算,这样多个查询同时执行,可以大大提高查询的并行度。因此需要将查询请求广播到RDD对应分区的每个节点。从而保证每个请求所涉及的分区都会有该请求的存在。
如图1所示,KNN和RQ在Spark-Streaming中的DAG。因为一个查询可能涉及多个分区,每个分区执行Join的查询后形成中间结果,最后将中间结果进行一次聚合操作,使同一查询请求在不同分区的中间查询结果聚集到一起。在进行聚合操作后,RQ便得到了最终的结果,KNN还需要进行过滤和筛选才能得到最终结果。
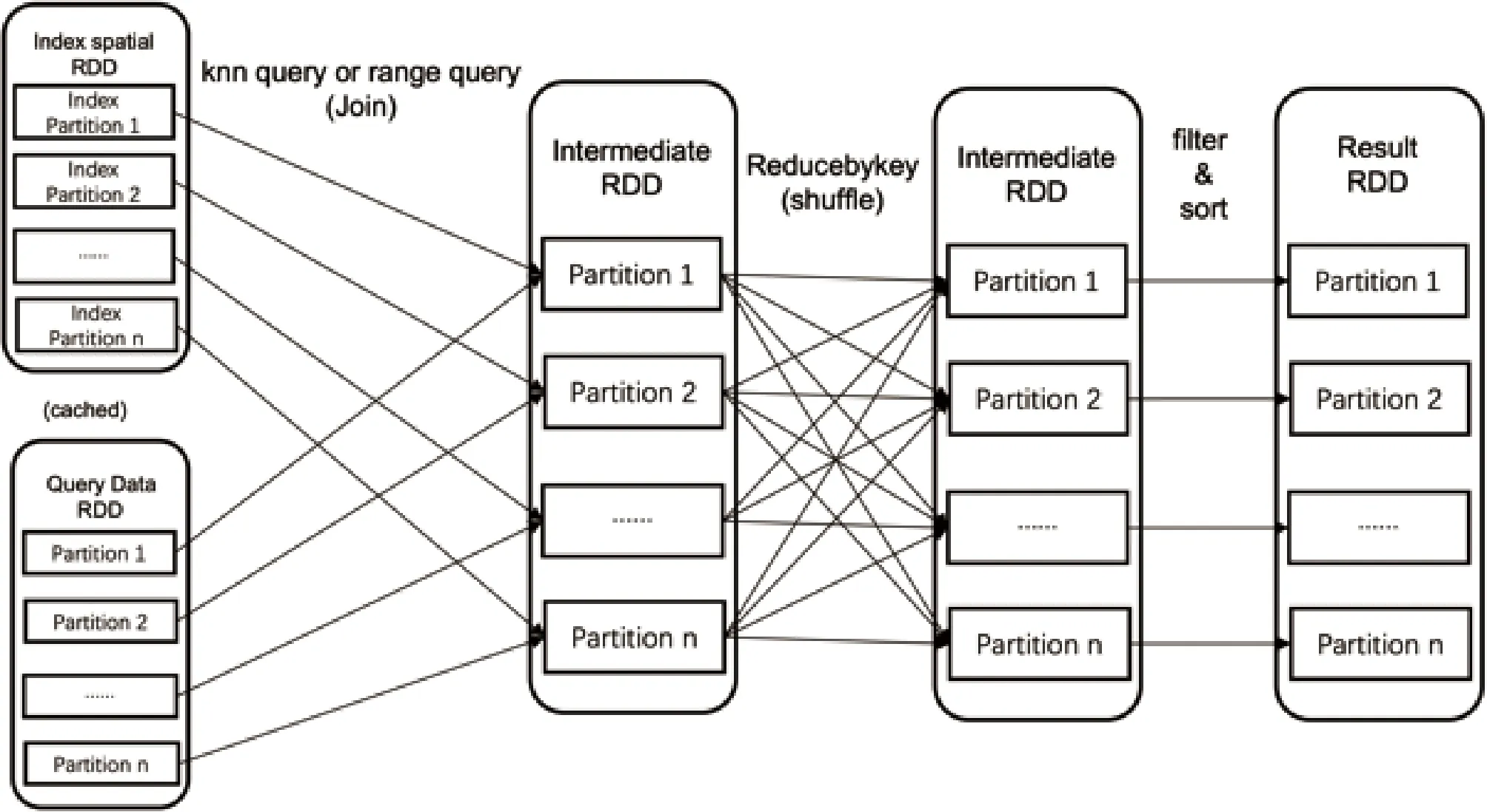
图1 空间查询 DAG
3 实验
3.1 数据集
本文实验数据采用深圳市POI数据约260万条、4.97万个站点(公交站和地铁站),这些数据均为经纬度数据。其中深圳市POI数据是被查询数据,深圳公交站地铁站经纬度数据用来生成查询请求。
本文以某乘客在某站点查询指定半径范围内的k个POI,来模拟KNN查询。每个查询请求的参数为:KNN(point,r,k)。其中point是查询中心点,采用深圳公交地铁站点经纬度点作为查询中心点;r和k分别为最大查询半径长度和需要查询POI点的个数,这两个值都采用固定值,分别是1 km和10个。
以某乘客查询公交或者地铁站点附近指定矩形范围内所有的POI点这一应用场景,来模拟RQ查询。每个RQ查询请求的具体参数为:Rangequery(point1,point2),其中point1,point2分别为查询矩形范围的左下角和右上角。将深圳公交地铁经纬度点作为查询矩形范围的中心点,矩形的长和宽分别为1.1 km和1 km,从而计算出point1和point2。
3.2 实验结果与分析
如图2所示,KNN查询在Spark-Streaming微批时间间隔分别为0.2 s,0.4 s和0.6 s时的实验结果。其中横坐标为请求的提交速度,左边的纵坐标为系统的吞吐,右边的纵坐标为查询对应的时延。
这些实验图结果都呈现出一个相同的规律,即在数据流流速尚未达到一个临界值的时候,吞吐随着数据流流速的增加而上升,且满足一个线性增长的规律,时延呈现出缓慢增长的趋势,且在当前微批时间间隔内;当数据流流速超出临界值的时候,吞吐虽然还会继续增长,但是增速会放缓,此时的时延会快速增加,且超出当前的微批间隔。在工程应用当中,当时延大量超过微批时间间隔时,便会导致程序变得不再“实时”,因此定义数据流流速达到临界值时的吞吐为最佳吞吐。
从图2可以看出,KNN的最佳吞吐都会随着批处理间隔的增加而上升,分别是0.2 s时900 op/s、0.4 s时2 000 op/s、0.6 s时2 600 op/s。RQ也是呈现出相同趋势,其最佳吞吐分别是0.2 s时400 op/s、0.4 s时500 op/s、0.6 s时700 op/s。在达到最佳吞吐时,这两个空间查询算法的平均时延和微批时间间隔也近似相等。尽管单个请求的查询时延从批处理对应的0.1 s增加到流式计算对应的0.2 s。但是吞吐这个指标与批处理环境下相比提升几十倍甚至上百倍。具体来讲,批处理场景下KNN和RQ的吞吐分别是9 op/s和10 op/s,流式场景下两种查询对应的吞吐分别为900 op/s和400 op/s。可以得出初步的结论,在流式计算场景下以0.1 s的时间为代价换取了KNN查询接近100倍的性能提升,RQ查询近40倍的性能提升。

图2 空间最近邻域搜索实验结果
4 结语
本文通过Spark-Streaming流式计算引擎实现了KNN和RQ这两个空间查询算法,其性能相比较于批处理环境下的空间查询均有很大的提升。具体来讲,批处理场景下吞吐为9 op/s,时延为0.1 s,流式计算场景下吞吐为900 op/s, 时延为0.2 s。以0.1 s的代价换取吞吐提升100倍,能够解决大规模实时查询的需求。在下一步的工作中,可以尝试在Flink流式计算引擎上来实现空间查询算法,进一步提升查询性能。
