基于神经网络的图像分类模型的设计与实现
2022-02-03刘鹏
刘 鹏
(苏州盛景信息科技股份有限公司,江苏 苏州 215004)
0 引言
图像分类技术在图像检索、用户搜索行为分析、人脸识别等领域有着广泛的应用前景。目前国内外学者对图像分类和识别方向的研究都是基于开放的图像数据集,例如有COCO[1]、CIFAR10[2]、MNIST[3]、ImageNe[4]和Fasion-MNIST等图像集,其中,COCO图像集是微软发布的大规模对象检测、分割和字幕数据集,MNIST图像集是训练各种数字图像识别,同时也是最先用在卷积神经网络的数据集,ImageNe图像集是一个用于视觉物品识别研究的大型数据集,包含了超20 000个类别和超1 400万个图像以及每个图像上的标注。Fasion-MNIST图像集是用于衣服的识别。本文采用改进后的卷积神经网络模型,选取包含了10个分类由60 000个32×32彩色图像组成的CIFAR10图像集作为训练集,提出将图像增强技术应用在图像集上,通过对图像的预处理从而达到增强图像特征层信息的目的,有效地避免了训练集中图像的冗杂,从而实现对CIFAR10图像集中所有图像的有效分类。
1 残差网络
2015年,何恺明在CNN的神经网络模型中引入了一种称为残差网络的新结构(ResNet)[5],残差网络的技术如图1所示,可以实现连接跳过几层的训练并直接连接到输出。
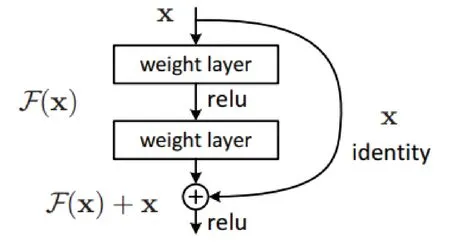
图1 残差块
残差网络是为了在进一步加深网络结构的同时,能够学习到更精细的特征从而提高网络精度,首先实现的一点就是恒等映射H(x)=x,所以何恺明等人将网络设计成H(x)=F(x)+x,即F(x)=H(x)-x[5]。这样随着网络的加深,F(x)便会逼近于0,从而实现恒等映射。残差块的优点是如果有任何层损坏了架构的性能,那么它将被正常化跳过。因此,使用残差块后可以训练得到非常深的神经网络,而不会因梯度消失或者爆炸梯度而导致的问题。ResNet50是一个易于使用和优化、具有更小的卷积核的残差学习网络框架,因此,本文将采用基于残差神经网络框架的ResNet50网络作为图像分类训练的模型。
2 图像数据集和图像数据增强技术
2.1 图像数据集CIFAR10
CIFAR10是一套典型的用来训练机器学习与电脑视觉演算法的图像集[2],其包括60 000幅32×32的10种不同类型的彩色图片,这10个类别分别是飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和货车。每一类均有6 000幅图片,其中5 000张的训练图像和1 000张的测试图像。由于CIFAR10中的图像分辨率为32×32像素,因此该数据集通常被科研人员用于测试各种网络,且各种卷积神经网络也往往最擅长识别CIFAR10中的图像。因此本文所设计的图像分类系统选取CIFAR10作为图像分类模型的数据集。
2.2 图像数据增强技术
为了提高数据集的分类准确率,以鸟的类别为例,本文将对此采取了色彩空间转换和噪声注入的图像数据增强技术。
2.2.1 色彩空间转换
简单的色彩强化就包括了隔离每一个色彩通道,比如,使用RGB通过隔离该矩阵和在其他的色彩通道加入二个零矩阵,就能够使图形迅速地转化为它在一个色彩通道上的表现。本文将通过grey,hsv,yuv3种不同的颜色转换来进行展示[4]。
2.2.2 噪声注入
噪声注入包含了一个随机值矩阵,该矩阵一般是从高斯分布中提取的。本文将噪声矩阵加入图像中可以使得优化后的卷积网络模型获得更多的特征。可以清晰地看出加入噪声和不加噪声在图片上的区别。
3 图像分类模型
3.1 图像分类模型构建
基于CIFAR10图像集的图像分类模型的构建流程如图2所示,分为以下3步骤。
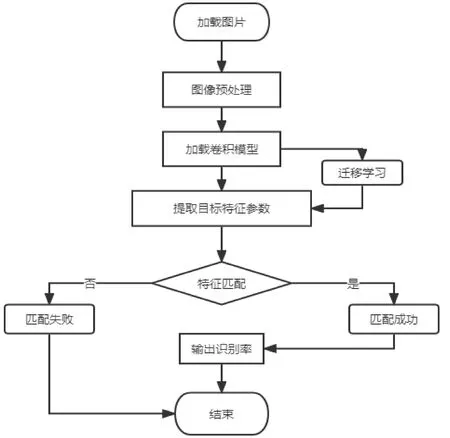
图2 图像分类模型构建流程
步骤1:需要从本地加载图片,并将图片进行预处理操作。
步骤2:建立ResNet50神经网络模型,并利用迁移学习技术来提取图片的特征参数。
步骤3:将输出的特征参数进行特征匹配,设置CIFAR10图像集中的10个分类对应10个不同范围,如果输出的参数在某一范围便返回某一类别。
3.2 模型训练
为了更好地优化模型,以便能提升图像分类识别的准确率,本次模型训练将分为以下两个阶段进行。
阶段1:对已有的模型参数进行调整。由于模型中最后的特征输出层为2 048维,所以在进行外积操作时可能会因维度过大导致显存爆炸,因此,利用1×1卷积将特征输出的维度降成1 024维,并添加正则化技术和激活函数来避免过拟合和梯度爆炸。由于ResNet50的训练模型使用迁移学习进行预习的,因此可以将预先训练的权重装入已建立的ResNet50模型中,在提高训练时间的前提下,达到较好的分类效果[6]。
阶段2:通过对阶段1中出现的损耗和精度进行观察,并对各权重进行重新调整。利用ResNet50的预训练模型,对残差神经网络进行初值重建,固定预训练卷积层的参数,只训练未参加预训练的卷积层,以便获得较好的残差网络参数;采用模型优化技术,在其之后加入 Dropout层和RELU线性整流函数,逐步对网络进行优化;最后采用反向传播算法对已优化好的残差神经网络进行加权更新,直到网络收敛。
3.3 模型训练结果
由于Pytorch-lightning可以很好地将训练过程进行复现,考虑到训练时间和算力的消耗,本次图像分类模型第二阶段仅迭代50次,通过Tensorboard工具将预测结果和模型损失以可视化的方式进行展现。
这里,Train_loss为训练集的损失量,经历了一次迭代之后,损失率便出现了大幅度下降,这是因为迁移学习已经预先加载好权重。Train_acc为训练集的准确率,经历了50次迭代后,训练集的准确率已经逼近于百分之九十,由于实验时迭代次数较少,从而导致了准确率产生波动,未能达到更高的准确率。Val_loss为测试集的损失,在经过几轮迭代后,损失率降至1.5左右,和训练集的损失率基本持平。Val_acc为测试集的准确率,由于测试集图片数量相对较少,但其准确率也高达到95%,其幅度在经历了几次迭代后逐渐转为平稳。
4 图像分类测试结果
通过加载上文训练得到的图像权重值和构建的ResNet50模型,图像分类实现步骤:
步骤1:为了增加结果的准确率,在进行分类识别前利用图像增强技术对图像进行预处理。
步骤2:分别加载训练阶段的残差神经网络和训练好的权重。
步骤3:将权重和图像进行匹配,获得图像的所属类别及识别准确率。
步骤4:利用matplotlib库将图像和分类结果以可视化进行展示。
最后,通过CIFAR10图像集来验证本文模型的图像分类结果是否达到需求,下列所示为本文模型在CIFAR1中的识别结果,从表1的结果可以看出10类图像结果均达到了90%以上的准确率。
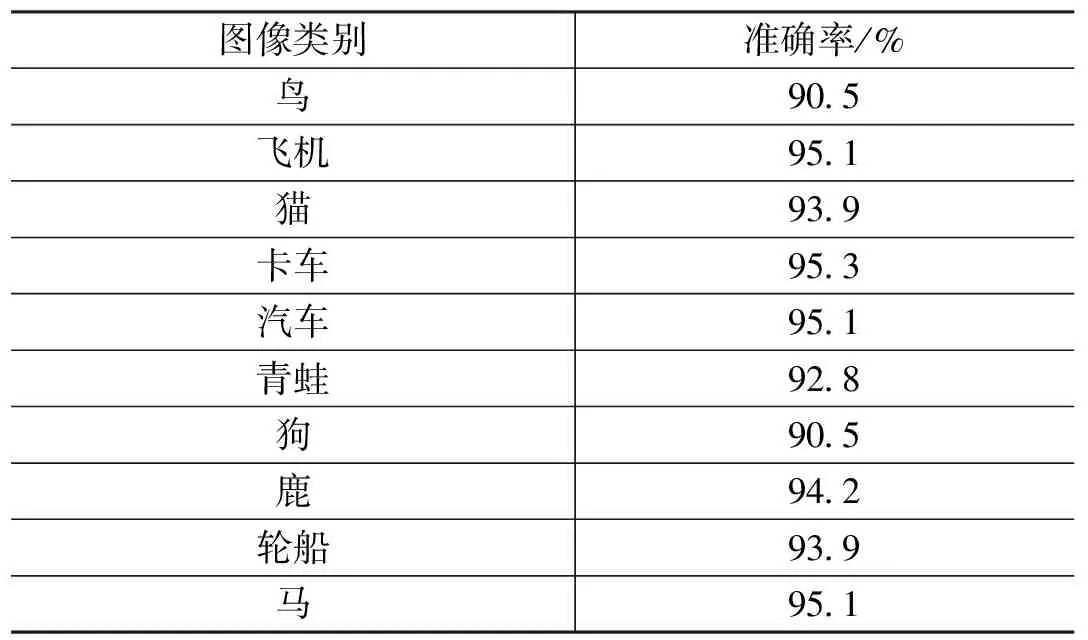
表1 图像分类测试结果
5 结语
本文设计的图像分类模型引入RELU激活函数和正则化技术来对整个模型进行优化。通过ReLU激活函数可以使网络随机梯度下降和反向传播算法更加有效,避免梯度爆炸和梯度消失的问题,同时在池化层的后面添加Dropout层来防止网络过拟合。为了加快深度神经网络的学习,可以在两个卷积层之间施加附加的限制,从而使各层网络的输入平均值与方差值在某一区间。
从图像分类预测结果可以看出,本文设计的图像分类神经网络模型应用到CIFAR10图像集上的图像分类识别准确率高,具有较好的鲁棒性,识别准确率基本能够达到90%以上。但由于硬件限制,本文实验所采用的GPU环境都部署在云端,并不能很好地调动GPU性能,如果有计算性能更好的硬件环境和设备,在满足最大显存的要求下,通过提高batch_size和增加迭代次数又或者更换神经网络模型,来提高训练的准确率。
