森林植被碳密度遥感反演和校准研究
2022-01-27吴恒,胥辉
吴 恒,胥 辉
(1.西南林业大学,昆明 650224;2.国家林业和草原局昆明勘察设计院,昆明 650216)
森林植被生物量和碳储量不仅是研究生态系统与大气间碳循环的基本参数,也是反映森林生态系统结构和功能特征的重要指标[1],在应对气候变化中发挥着不可替代的重要作用,及时、准确、连续、动态的生物量和碳储量监测数据是世界各国应对气候变化的行动的重要决策依据,也是估算森林植被生态系统固碳经济价值的关键因子。随着生态产品价值实现机制的建立健全,建立生物量和碳储量动态监测制度,及时跟踪掌握生物量和碳储量数量分布、功能特点、权益归属等信息就显得尤为迫切[2]。
传统的森林资源连续清查生物量估算和基于规划设计调查数据的生物量估算都需要耗费大量的人力、物力和财力,对于大尺度、长时间、落实到山头地块的连续监测实现的可行性极小,采用遥感数据与地面调查数据建立反演模型是大区域尺度生物量和碳储量估算的有效途径[3-4]。森林植被生物量和碳储量遥感信息提取是“3S”技术结合林学、生态学和信息科学等的一个综合应用[5],尤其是MODIS,Landsat,Sentinel,GF,HJ,ZY等系列数据[6-7]在国内外林业、农业[8]和生态[9-10]等遥感方面都有广泛的应用,利用卫星遥感数据提取植被覆盖类型面积的技术相对成熟,且精度不断提高。本研究基于时序遥感卫星数据,以连续的地面观测数据为基础,利用遥感数据融合及数据同化等方法,解决大尺度森林植被生物量和碳储量遥感信息提取过程中建模和校准的问题,并对影响森林植被生物量和碳储量信息提取精度的原因进行分析研究,对生态系统生物量和碳储量的连续、实时、动态监测具有现实意义。
1 研究区概况
四川省(26°03′~34°19′N,97°21′~108°12′E)位于我国西南部长江上游地区,位于中国大陆地势三大阶梯中的第一级和第二级,是青藏高原生态屏障和川滇生态屏障的重要“握手区”,地形复杂,气候多样,东部盆地,西部高原,幅员面积48.6万km2。属于全国第二大林区、第五大牧区,森林资源以天然林为主,主要分布在川西高原和盆周山地,草地资源主要分布在川西北。湿地资源丰富,是我国高原泥炭沼泽最集中分布区,泥炭储量居全国前列。据第九次全国森林资源调查结果[11],四川省森林面积1 839.77万hm2,森林覆盖率38.03%。活立木蓄积197 201.77万m3,森林蓄积186 099.00万m3,每公顷蓄积139.67 m3。森林植被总生物量150 386.79万t,总碳储量71 582.45万t。
2 研究方法
2.1 数据来源
遥感数据根据精度要求和获取的可行性决定,高精度的影像获取受时相、成本和卫星重返周期等限制。本研究为了建立时序数据的基准,降低精度选择重返周期最短的MODIS数据,确保所有的影像数据均为3月,以消除季节变化对遥感指标NDVI和NPP的影响。遥感NDVI数据[12]涵盖了2002—2017年共16幅影像,空间分辨率均为1km;NPP数据[13]涵盖了2002—2017年共16幅影像,空间分辨率均为1km。地面监测数据包括四川省第六次(2002年)、第七次(2007年)、第八次(2012年)和第九次(2017年)森林资源连续清查数据,样地总数10 098个,全为机械布设的固定样地,样地形状为正方形,面积为0.066 7hm2。按照《森林资源连续清查技术规程》[10]对龄组、起源、树种(组)的划分方式,将优势树种进行归并处理,得到森林植被分龄组、起源、树种(组)的面积、蓄积量等数据。
2.2 储量估算与模型构建
2.2.1储量估算
基于森林资源连续清查样地调查的优势树种、龄组和蓄积量,采用林木生物量扩展因子法进行蓄积-生物量转换,分优势树种和龄组计算样地生物量和碳储量,本文所采用的BEF与单位面积优势树种(组)分龄组蓄积倒数方程,其参数来源于《全国林业碳汇计量监测技术指南》(试行)(1)国家林业局.全国林业碳汇计量监测技术指南.2011.中的拟合结果,及相关地区的森林优势树种及树种组的生物量转换因子,竹林和灌木林采用全国林业碳汇计量监测技术方法估算。在ArcGIS 10.2中运用Raster Calculator工具提取48km2区域内的遥感指标。
2.2.2反演模型构建
参数模型根据遥感时序数据与地面连续观测值之间相关性与差异性,考虑各遥感因子间的交互作用和共线性关系,分析生物量密度、碳密度与遥感指标间线性函数、多项式函数等关系的基础上[14],按照以下备选方程(1)和(2)构建遥感反演模型,根据模型拟合决定系数等综合确定模型拟合结果。

(1)

(2)

采用2002年、2007年、2012年和2017年4期数据集为训练样本,以遥感样地代表区域内NPP,NDVI均值和标准差作为输入变量,以生物量密度和碳密度地面观测值为目标变量,运用Matlab R2014b构建不同结构BP人工神经网络模型[15-16],人工神经网络模型神经元结构分别采用4-2-1,4-3-1,4-4-1,4-5-1,4-5-3-1,4-5-4-1,4-5-5-1,4-5-6-1的形式,输入层到隐层的传递函数均为tansig,隐层到输出层的传递函数为tansig或者purelin,训练方法为trainlm,学习率为0.01,训练的最大次数为1 000。筛选结果得出4个时期生物量密度和碳密度的BP人工神经网络模型。
2.2.3校准与动态分析
基于建立的参数模型和BP人工神经网络模型,采用2002—2017年的NPP,NDVI栅格数据,在ArcGIS 10.2中运用Raster Calculator工具,连接参数模型和BP人工神经网络计算模块,利用GPS精准定位,加权计算得到各年度生物量密度和碳储量密度分布图。其中,2002年模型用于2002—2004年的影像估算;2007年模型用于2005—2009年的影像估算;2012年模型用于2010—2014年的影像估算;2017年模型用于2015—2017年的影像估算,并基于基准进行计算矫正。
2.3 影响遥感反演精度的因素分析
为了分析月度、季度、年度影像的时相和估算尺度对碳密度反演精度的影响,本研究采用相对误差(RE)作散点图进行各密度区间的影响因素分析,采用平均误差(ME)、平均绝对误差(MAE)和均方根误差(RMSE)进行定量各因子的影响程度,各误差的计算公式如下:
(3)
(4)
(5)
(6)

3 结果与分析
3.1 时序数据相关性与差异性
根据生物量密度和碳密度平均值与遥感时序数据的Pearson相关性分析(表1)表明,2002—2017年生物量密度与NPP和NDVI的Pearson相关系数平均值分别为-0.385 3和0.112 0,2017年生物量密度与NPP的Pearson相关系数最小,2012年生物量密度与NDVI的Pearson相关系数最小。2002—2017年碳密度与NPP和NDVI的Pearson相关系数平均值分别为-0.388 0和0.109 5,2017年碳密度与NPP的Pearson相关系数最小,2012年碳密度与NDVI的Pearson相关系数最小。生物量密度和碳密度与遥感时序指标NPP和NDVI的线性相关性较弱,且生物量密度、碳密度与遥感时序指标的相关性呈现一致性规律。

表1 2002—2017年生物量密度 碳密度平均值与NPP,NDVI的Pearson相关性Tab.1 Pearson correlation between biomass,carbon densities and NPP,NDVI from 2002 to 2017
方差齐性检验表明,不同时期生物量密度、碳密度、NPP和NDVI的Levene统计量分别为5.388 0,5.382 0,400.390 0和122.108 0,显著性值均小于0.01,不同时期各指标总体的方差存在显著差异。根据生物量密度、碳密度平均值、NDVI平均值和NPP平均值单因素方差分析(表2)表明,2002—2017年生物量密度、碳密度、NDVI和NPP均值间存在极显著性差异(P<0.01),生物量密度和碳密度的均值差异呈现一致性规律。

表2 2002—2017年生物量密度 碳密度平均值 NPP,NDVI的单因素方差分析Tab.2 Results of ANOVA for biomass,carbon densities and NPP NDVI from 2002 to 2017
3.2 遥感反演结果及动态分析
3.2.1参数模型拟合结果
采用模型1以NPP均值及标准差作为自变量,拟合不同时期生物量密度的决定系数均值为0.228 7,碳密度的决定系数均值为0.229 8;采用模型2以NPP均值及标准差作为自变量,拟合不同时期生物量密度的决定系数均值为0.221 0,碳密度的决定系数均值为0.222 8。采用模型1以NDVI均值及标准差作为自变量,拟合不同时期生物量密度的决定系数均值为0.102 2,碳密度决定系数均值为0.101 9;采用模型2以NDVI均值及标准差作为自变量,拟合不同时期生物量密度的决定系数均值为0.087 6,碳密度的决定系数均值为0.087 2。模型1相较于模型2具有更好的拟合效果,增加指标的标准差作为自变量不能有效提高模型拟合效果,NPP和NDVI具有对模型具有不同的解释效能,采用精度较低的遥感数据反演森林生物量密度和碳储量密度具有局限性。因此,采用模型1以NPP和NDVI均值为自变量拟合生物量密度和碳储量密度(表3)。

表3 生物量密度和碳密度遥感反演参数模型拟合结果Tab.3 Fitting results of parameter model for biomass,carbon densities with remote sensing indicators
3.2.2BP人工神经网络模型反演结果
根据BP人工神经网络训练结果(表4)可知,相较于参数模型生物量密度拟合决定系数平均提高了0.070 5,碳密度拟合决定系数平均提高了0.076 2,差异最大的为2017年的拟合结果由不到0.05提高到0.20,采用人工神经网络能有效提高模型拟合决定系数。相较于1个隐层,2个隐层模型拟合决定系数提高了0.009 9,增加隐层数和神经元数量会提高BP网络的拟合决定系数,但是也可能导致过度拟合。同时,转换函数的选择也影响着生物量密度和碳密度的遥感反演模型结果。参数模型和BP人工神经网络拟合结果综合分析表明,拟合决定系数均小于0.50,精度较低的遥感数据反演生物量和碳储量密度的信息有限,实际生产运用中应尽可能采用高精度影像辅助地面调查,从而提高遥感估测的精度。
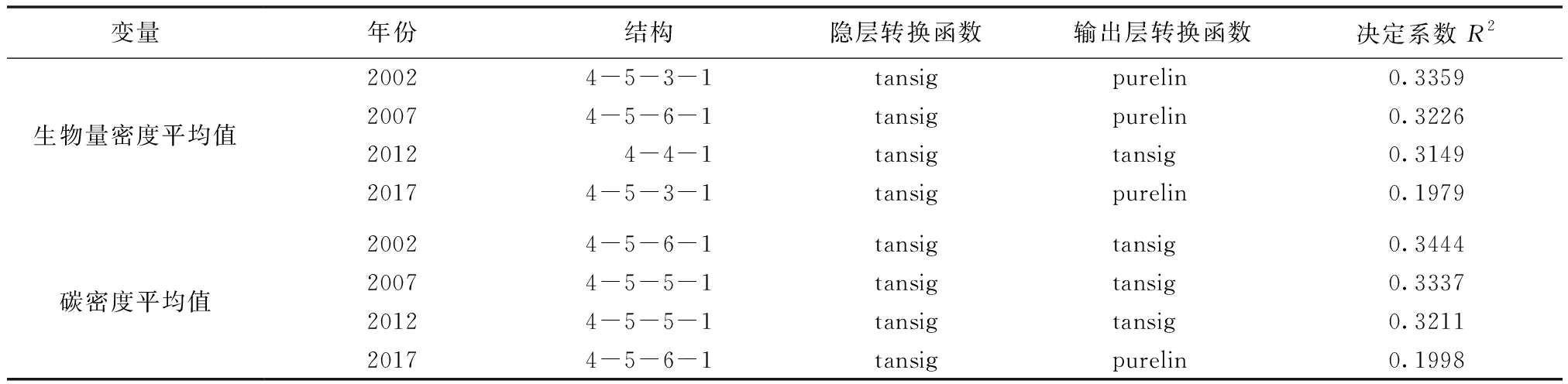
表4 生物量密度和碳密度遥感反演BP人工神经网络训练结果Tab.4 Results of BP artificial neural network training for biomass,carbon densities with remote sensing indicators
3.2.3生物量密度和碳密度动态演变趋势
2002—2017年,四川省森林植被生物量密度和碳密度呈现不断增大的趋势(图1)。各年间生物量密度与碳密度的Pearson相关性系数为0.958 3。高碳密度主要集中于甘孜州、阿坝州、凉山州等盆周区域,应与天然林保护等活动有关,原始林区的天然林分得到进一步的恢复。盆地内碳密度呈现出面积不断扩大的趋势,应与国土绿化等活动有关。

图1 2002—2017年期间四川省植被生物量密度和碳密度时空演变趋势Fig.1 Trend of biomass and carbon storage density change in Sichuan Province from 2002 to 2017
3.3 遥感数据和估算尺度对反演精度的影响
3.3.1遥感数据
采用遥感数据反演生物量密度和碳密度均存在明显的高估和低估区间,其中低估区间为生物量密度和碳密度达到光饱和点以后,遥感指标不随生物量密度和碳密度的增加而增加,导致遥感反演结果低于实际值。高估区间则是由于遥感指标不能区分不同植被覆盖类型而导致对草地、灌木林地和竹林地等非乔木林分的遥感反演结果高于实际值。不同月份数据间遥感反演的相对误差存在显著性差异,2月(图2(b))和3月(图2(c))遥感数据反演的相对误差分布呈现合理的正态分布型,但仍然存在明显的光饱和区间。低密度期间相对误差由低到高的顺序为12月(图2(l))、1月(图2(a))、4月(图2(d))、5月(图2(e))、11月(图2(k))、10月(图2(j))、9月(图2(i))、6月(图2(f))、7月(图2(g))、8月(图2(h))。结果表明,在未能准确区分植被覆盖类型的情况下,采用2月或3月的遥感NDVI指标估计生物量密度和碳密度更为合理。

图2 不同月份数据遥感反演相对误差分布图Fig.2 Relative error distribution of remote sensing modeling by different monthly data
采用月度数据(1—12月)估测森林碳密度与清查样地实测值的平均误差(ME)分别为-19.8,-19.6,-12.1,-8.5,-2.2,8.1,11.1,10.2,3.8,0.5,-9.7和-16.2t/hm2;平均绝对误差(MAE)分别为26.9,29.0,32.1,32.0,33.1,37.0,38.2,37.1,34.7,32.2,29.6和27.0t/hm2;均方根误差(RMSE)分别为46.5,49.2,50.1,48.8,47.6,47.7,48.1,47.2,46.6,45.6和47.4,46.7t/hm2。
不同季度数据间遥感反演的相对误差存在差异,1季度(图3(a))遥感数据反演的相对误差分布较为合理,其次为4季度(图3(d))、3季度(图3(c))和2季度(图3(b))。采用1月的遥感NDVI指标估计生物量密度和碳密度更为合理,但没有月度数据的估计效果好。采用季度数据(1—4季度)估测森林碳密度与清查样地实测值的平均误差(ME)分别为-0.3,13.0,6.2和-12.4t/hm2;平均绝对误差(MAE)分别为103.3,141.8,116.4和55.9t/hm2;均方根误差(RMSE)分别为47.9,48.3,45.9和46.3t/hm2。

图3 不同季度数据遥感反演相对误差分布图Fig.3 Relative error distribution of remote sensing modeling by different quarterly data
不同年度数据间遥感反演的相对误差无差异,但没有月度数据和季度数据的估计效果好。采用年度数据2002年(图4(a))、2007年(图4(b))、2012年(图4(c))和2017年(图4(d))估测森林碳密度与清查样地实测值的平均误差(ME)分别为13.4,39.3,78.1和32.1t/hm2;平均绝对误差(MAE)分别为38.9,34.4,36.6和32.8t/hm2;均方根误差(RMSE)分别为48.1,46.2,47.8和43.8 t/hm2。
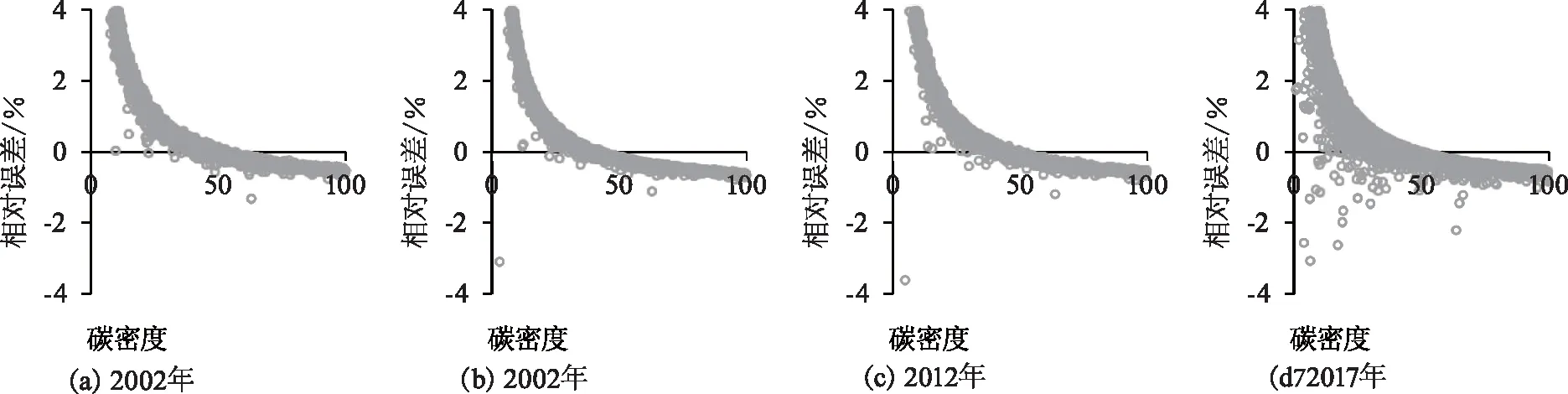
图4 不同年度数据遥感反演相对误差分布图Fig.4 Relative error distribution of remote sensing modeling by different annual data
3.3.2估算尺度
不同估算尺度对遥感反演的相对误差具有显著性的影响,采用清查样地估算1km2(图5(a))碳密度相对误差分布呈现合理的正态分布型,其次为6km2(图5(b))、24km2(图5(c))和48km2(图5(d)),可能与遥感影像的精度为1km有关。不同估算尺度(1,6,24,48km2)森林碳密度与清查样地实测值的平均误差(ME)分别为-4.4,13.7,10.0和2.7t/hm2;平均绝对误差(MAE)分别为34.6,25.4,24.8和24.8t/hm2;均方根误差(RMSE)分别为46.6,38.8,38.3和38.5t/hm2。

图5 不同估算尺度遥感反演相对误差分布图Fig.5 Relative error distribution of remote sensing modeling by different scale of estimation
4 讨论与结论
4.1 讨论
森林、草原、湿地等自然生态系统在增加碳汇中发挥着不可替代的重要作用[17],是争取实现碳达峰碳中和的有效途径。采用精度较低的遥感数据反演森林生物量密度和碳储量密度具有局限性,遥感数据反映的信息有限,故本研究中的模型拟合决定系数较低。由于不同月份NDVI和NPP等差异较大,对基准矫正和年度的时序分析具有较大的影响,这要求建立时序数据校准的遥感数据的时相相对统一,确保时序数据校准实验的合理性和可行性。随着遥感数据的丰富,对比不同精度的遥感影像对生物量和碳储量估测影响是本研究后期需要改进的地方。在生产中也应根据实际需求尽可能采用高精度影像辅助地面调查,利用GPS技术建立地面连续监测的基准对不同时期的遥感影像反演值进行校准,运用智能算法建立反演模型[18],从而提高遥感估测的精度。同时,基于遥感数据的生物量和碳储量估算具有不确定性问题,其中光饱和点的不确定性更为突出[19],在实际调查监测中需要注意和饱和矫正。同时,由于遥感指标不能区分不同植被覆盖类型而导致对草地、灌木林地和竹林地等非乔木林分的遥感反演结果高于实际值,在实际生产和运用中应增加森林植被区划因子,从而提高遥感反演的精度。
4.2 结论
生物量密度、碳密度与遥感时序指标NPP和NDVI的线性相关性较弱,不同年份间生物量密度、碳密度、NDVI和NPP均值存在极显著性差异(P<0.01),NPP和NDVI对模型具有不同的解释效能。相较于参数模型,采用BP人工神经网络生物量密度拟合决定系数平均提高了0.070 5,碳密度拟合决定系数平均提高了0.076 2。辅助GPS精准定位进行时序数据校准,2002—2017年期间四川省森林植被生物量密度、碳密度呈不断增大的趋势。采用遥感数据反演生物量密度和碳密度均存在明显的高估和低估区间,在生产过程中应进行矫正。在未能准确区分植被覆盖类型的情况下,采用2月或3月的遥感NDVI指标估计生物量密度和碳密度更为合理,季度数据和年度数据均没有月度数据的估计效果好,不同估算尺度对遥感反演的相对误差具有显著性的影响。采用“3S”技术和模型技术,结合高精度时序遥感卫星数据能为大区域尺度生物量和碳储量估算提供快速途径[20-21]。
