基于深度学习的视频目标检测算法的实现
2022-01-26孙洪迪贾民政杨民峰
孙洪迪 贾民政 杨民峰
(北京工业职业技术学院 信息工程学院,北京 100042)
0 引言
近年来,视频监控已经逐渐从银行、工业生产控制、安防等特定市场向大众市场进行拓展,如智能家居、无人驾驶、智能交通等新兴领域逐渐兴起,视频监控行业的飞速发展对视频目标检测算法与系统的性能与准确性提出了更高的要求。然而在当前互联网的大环境下,视频数量呈爆炸性增长,视频质量、大小参差不齐,并且每帧视频中的物体大小、尺寸以及数量都不确定。在拍摄过程中,如果视角移动还会出现画面模糊、待检测目标发生扭曲等问题,同时还伴随有光线强度、遮挡等外界的环境影响,这就要求视频目标检测算法必须具有良好的鲁棒性。另外系统面向的用户大多是不熟悉代码的普通用户,因此必须设计出简单界面来简化操作,使其适应所有用户,同时检测结果需要使用边界框对关键物体进行位置标注,并明确指出该物体所属的类别。
目标检测就是以确定视频图像中的目标大小和位置为主要任务,是机器视觉领域中的一个核心问题。不过由于受光照的变化、物体遮挡和复杂的背景条件等众多因素的影响,目标检测一直是机器视觉领域最具有挑战性的问题。
目前相对主流的目标检测算法有R-CNN[1],Faster R-CNN[2-3],YOLO[4-6]。R-CNN分为目标proposal和目标分类2大步,Faster R-CNN把R-CNN中的2步作为同一网络的不同分支来分别进行输出,可以将计算时间大大缩短。YOLO系列则直接省略了2个分支,通过1个网络来同时将目标的位置、分类进行输出。
1 孪生网络介绍与改进
近年来,目标检测算法已成为当前机器视觉领域的热点问题,其中孪生网络相关的高效算法不断涌现[7-8],在目标检测与追踪中得到了广泛的应用。
1.1 孪生网络介绍
孪生网络是一种使用2个或多个相同子神经网络进行度量学习的一种方法,其结构图如图1所示。孪生网络的主要思想是使用2个或多个相同的网络来处理输入,即训练样本与测试样本被分别输入到2个相同的CNN中,得到2个特征向量,再经过计算彼此间的距离(L1)来判断相似度高低,最后通过相似度来判定两者是否为一类。

图1 孪生网络结构图
Luca Bertinetto等[9]提出的SiamFC把深度卷积网络当成一个普遍适应的相似性的学习问题,利用全卷积网络对网络结构进行改造,虽然实时性已经得到了满足,但是并不具备边界框回归,因而只能对多尺度进行测试,致使它的美观程度、精确度以及鲁棒性并不如意。LI B等[10]提出的SiamRPN在其基础上引入RPN模块,使用tracker可以对目标物体的形状、位置进行回归操作,从而无需进行多尺度的测试,提高了性能和速度,但是分类与回归分支参数量不平衡是它最主要的缺陷。ZHU Z等[11]提出的DaSiamRPN针对SiamRPN中正负样本块分配不均衡问题以及样本块的丰富性问题做出了改进,在训练孪生网络时,对网络通过构造语意样本的策略来加强其判别能力,使其更加关注输入的数据,在搜索区域中寻找与模板差别最小的物体。
1.2 孪生网络的局限与改进
通过对孪生网络及其算法分析,发现原先的孪生跟踪网络主要通过滑动的方法来对目标与搜索区域的相似程度进行计算,这种设计有2个缺陷:(1)在目标的检测过程中,当检测帧的目标进行移动时,相应地响应位置也会做等量移动;(2)将搜索区域图像输入到网络后,得到的结果与模板区域得到的结果是一致的。这2个缺陷会导致网络出现2种限制,即网络具有平移不变性和目标相似度的限制。
当前的深度网络都具备大量的padding,而这些padding会对孪生网络的平移不变性造成破坏,使得深度网络都不具备平移不变性。因此当利用深度网络对特征进行提取时,如果继续采用将正样本放在中心的策略,就会使网络产生位置偏见。而采取正样本均匀分布的策略,在特征提取时,可使因为破坏了平移不变性而造成学习到位置偏见的问题得到有效的缓解,同时为在目标检测中更好地利用深度网络做了准备。
对于目标相似度的限制,由于使用回归代替相似度的计算时,采用的是非对称结构,从而产生了另一个阻碍利用深度网络的因素,即对目标进行分类与回归时所需要特征是不对称的。为了解决这个问题,采用深度交叉相关的信息关联策略。
在孪生网络中,相似度衡量是一个非常重要的步骤。如SiamFC采取获取待测物体位置信息的单通道的响应图的方式。而SiamRPN则在做相关性计算之前添加了2个卷积层来对通道进行扩展,但是因为引入了anchor,所以严重影响了参数分布的平衡,使得特征提取层中参数的数量要远远少于RPN层中的参数数量,这直接导致了算法在后期难以实现高效的训练与优化。因此,利用互相关层来对信息实现关联,以解决参数多且不平衡的问题。因为在进入RPN层的时候,需要通过1个卷积层来对通道数进行提升,这就产生了大量的参数。为此,使用DW卷积来对以上方案做出改进,每一个通道只对这一个通道的卷积操作负责。改进后,该层所拥有的参数大大减少,并且在计算量大大减少的同时,2个分支所拥有的参数也达到了平衡状态。DW卷积结构如图2所示。

图2 DW卷积结构
通过上述的改良,克服了孪生网络的限制,使得孪生网络具备了学习并训练深度网络(如ResNet-50)的条件。
2 算法主干网络模型设计
孪生网络对深度网络的处理不尽人意,本算法通过改进使得siamese网络可以学习并处理深度网络,同时采用多个层次特征进行融合的方式更好地获取网络的语义特征。为了使算法达到速度的要求,采用逐个通道进行计算的策略,实现分类和回归的目的,大大减少计算量。
2.1 系统主干网络
系统最终构建的主干网络如图3所示。
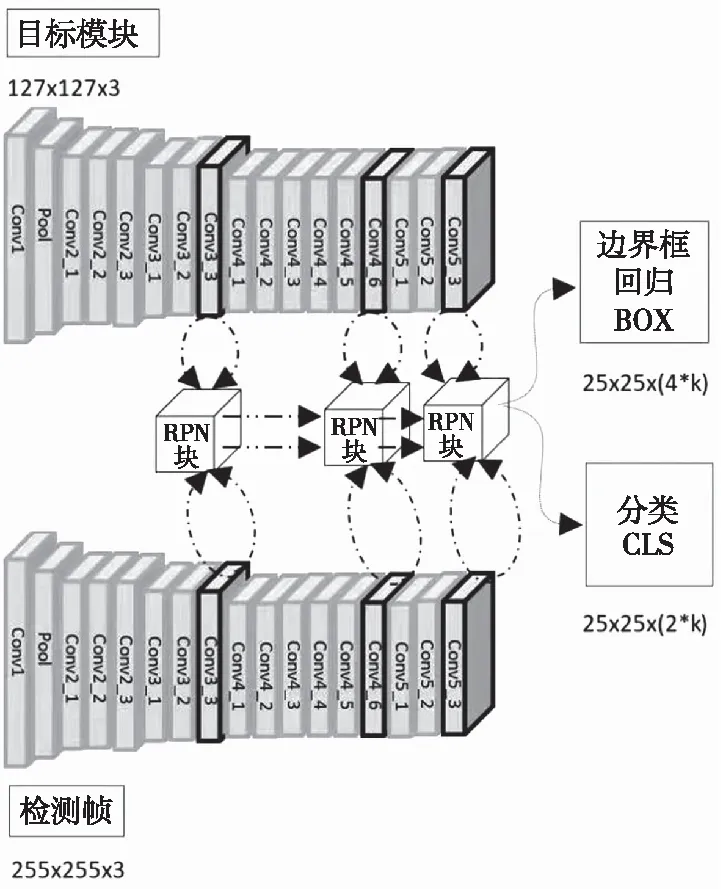
图3 系统主干网络
从图3可以看出,本系统主干网络在RestNet-50网络的基础上对conv4,conv5块进行修改,使其具备步幅的同时,将最后2个块的stride改为8 pix,这样做有益于孪生网络的训练与预测;同时通过人为加大卷积核内部元素之间的距离,扩大卷积来达到增加其感受野的目的,即在每个block的输出之后,增加1个用来减少通道数的1×1卷积层。当输入目标模板与检测帧2个特征图进行网络的学习和训练时,网络会将stage3,stage4和stage5中获得的结果通过RPN网络进行多层特征融合,即抽取stage3,stage4和stage5中的最后3个模块的特征分别进行分类和回归操作,最后将结果进行级联操作。
个人理财的专业人才主要从事理财中介机构(理财公司、理财媒体等)和金融机构(包括银行、证券、保险、信托、基金等),同时也能从事企事业单位财务工作。因此,具备专业性、实操性、复合型的人才,才能胜任日益变化的金融工作。[5]
系统的RPN网络由2个分支组成,一个是用于对目标和所在背景进行区分的分类分支,而另一个则是通过对候选区域调整,实现边界回归的回归分支。首先该模块将从stage3,stage4和stage5中提取到的模板特征和待检测的视频帧的特征,分别各自通过1个卷积层进行卷积,注意这2个卷积层的参数与权重并不是完全一致的,即这2个卷积层的参数并不进行共享操作;然后利用DW卷积分别对其再次卷积操作;最后得到的分支再分别进行不同的卷积操作,以达到理想的分类与回归效果。
YOLOv3主要是针对比较多的分类(如1 000类)而设计的,对于类别较少的分类操作其效果并不理想。相比较而言,本算法采用的网络更加简洁、训练收敛的速度更快,更加适用于分类较少的场景。
2.2 多层特征融合
目标检测追踪必须具备表现形式丰富的特点,这些表现形式包括可扩展性大小、分辨率高低。即使网络的深度足够深,其每一层具有的特征也是有限的,在引进了ResNet-50这种深度网络之后,对不同的层次进行融合和级联可以有效提高目标识别的效率。
以前的孪生网络学习的都是比较浅层的网络,其提取的特征缺少语义特征。而深层网络中不同层次获得的特征会有所差异,而且具有丰富的语义特征。同时在视觉跟踪中需要丰富多样的表现形式,因此,将多层次的特征进行融合可以有效提高识别和定位的准确率。
YOLOv3中通过采用类似FPN的融合策略来增强算法的精确度,即从不同尺度的特征图中提取特征并进行特征融合,最后融合了3个特征层并在其特征图上进行检测。
与YOLOv3不同,本算法采用多层特征融合的方法,系统网络将后3个块的输出结果输入到RPN模块中,进行分类与边界的计算,同时3个RPN模块的分辨率一致,因此进行融合也非常简单,直接对其进行线性加权求和即可。
3 实验结果与分析
笔者最终实现的系统使用Python语言编写,通过GPU对算法中的大部分深度网络进行运算,从而使深度网络的训练与预测速度进一步地提高。网络构造部分采用Jupyter Notebook完成,并通过与CUDA相结合进行模型训练。另外,通过Pycharm与Qt Designer相结合的方式编写图形用户界面(GUI),用户可以在UI界面中通过选择训练完成的模型以及待检测视频,完成对视频中目标的准确快速识别。
为了验证系统识别现实生活目标的有效性和普遍适应性,将系统跟踪器运行在OTB数据集上完成验证。同时为了更好地验证系统跟踪器性能,配置1个YOLOv3跟踪器,分别对其与系统跟踪器进行试验,并对结果进行比较分析。
系统跟踪器与YOLOv3跟踪器在OTB数据集上运行得到的平均效果如表1所示。

表1 平均效果对比
系统跟踪器与YOLOv3跟踪器在OTB数据集上运行得到的单独类效果对比如表2所示。
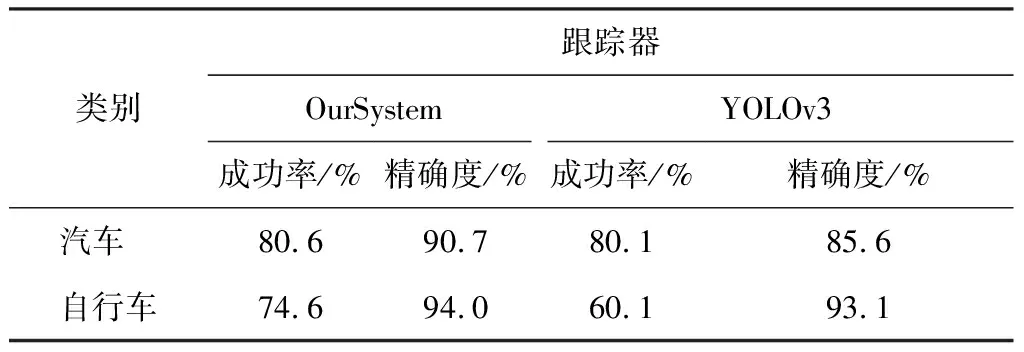
表2 单独类效果对比
从表1可以看到,系统跟踪器在成功率与精度上都超过了YOLOv3,在成功率上比YOLOv3高出了5.7%,精度也超过了4.5%左右。而从表2可以看到,对单独类的识别效果系统跟踪器也有明显的提升。
为研究目标检测领域重点关注的问题,依次从目标形变、尺度变化、目标遮挡等方面对两者进行结果比较。为了更直观地呈现结果,采用以下2种图示方式:
(1)成功图(Success Plot)。视频中重合率(OS)大于阈值的视频帧数与所有帧数的百分比,重合率的范围为0~1。计算方法为:OS=|m∩n|/|m∪n|,其中,| |表示某个区域内所拥有的像素的数量,m为算法得到的目标位置,n为人工标注的目标所在位置。
(2)精度图(precision plot)。算法检测的目标位置中心点与人工进行标注的目标中心点之间的距离小于阈值的视频帧数与总帧数的百分比,当阈值不一样的时候,百分比也就不相同。
当目标发生变形时,2种跟踪器的性能比较如图4所示。图4(a)表示在目标发生变形后,目标检测成功率随阈值增大而形成的曲线,图4(b)表示精度的变化。从图4可以看出,尽管目标发生变形,2种跟踪器还是会对目标进行比较准确的预测。其中,不论是成功率还是精度,系统跟踪器都要优于YOLOv3。在成功率上,系统的跟踪器要平均高出大约9.5%,而在精度上高出了10.2%。
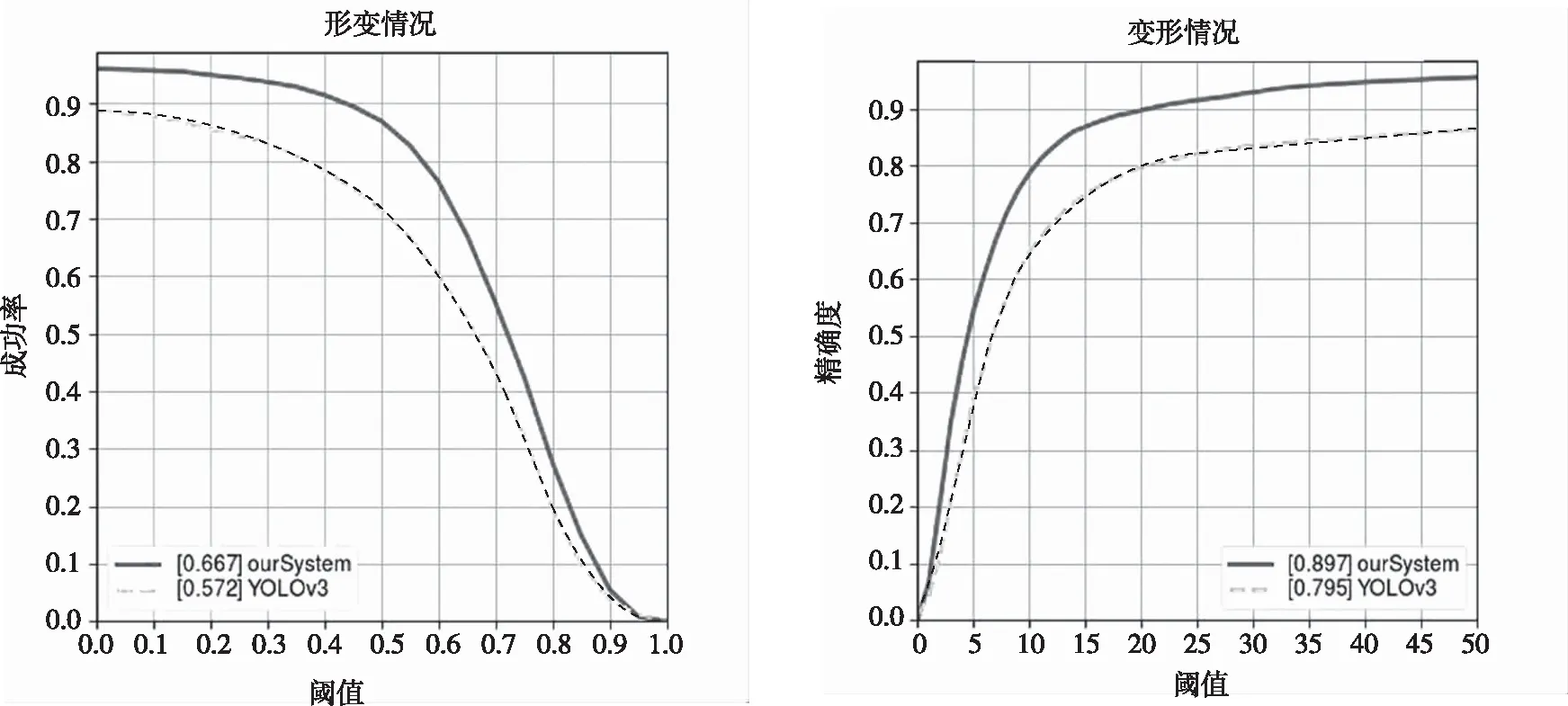
(a)目标形变成功率对比 (b)目标形变精度对比图4 2种跟踪器在目标形变时的性能比较
当目标在平面内旋转时,2种跟踪器的性能比较如图5所示。当目标因为平面内旋转造成尺度变化时,系统跟踪器的成功率与精度均比YOLOv3提高了7%左右。而当目标由平面内旋转变为平面外旋转之后,YOLOv3的跟踪器的成功率变为62.8%,准确率为87.2%。而系统跟踪器的平均成功率变为68.3%,精确度变为91%。由此可以得出,系统跟踪器对平面内旋转情况的处理要优于平面外旋转的情况处理。

(a)平面内旋转成功率对比 (b)平面内旋转精度对比图5 2种跟踪器在目标平面内旋转时的性能比较
在目标遮挡的情况下,能否对目标进行有效的检测是目标检测算法是否具备实用性的一项重要指标,实验所得到的结果如图6所示。2种跟踪器在有遮挡的条件下对目标的检测的性能不分上下,系统跟踪器在成功率上比YOLOv3跟踪器提高了4%左右。

(a)目标遮挡成功率对比 (b)目标遮挡精度对比图6 2种跟踪器在目标遮挡时的性能比较
综上所述,系统跟踪器在不同环境中的成功率与准确度上的表现都要优于YOLOv3,在目标检测中对各类情况的处理良好,可普遍胜任各种情况下的目标识别检测工作。
4 结论
本文对近年来孪生网络的一系列算法进行分析,并在其基础上进行改进,重点解决了孪生网络所具有的平移不变性限制,打破了孪生网络不能利用深度网络进行学习和训练的限制;将孪生网络与RestNet相结合,并借鉴了SiamRPN中的RPN块以实现对目标的分类和回归操作。为了提高目标的精度,采用多层特征结合的方式提高了网络对特征的提取能力,而且所用网络利用深度相关层的聚合,有效降低了冗余的参数和成本。
最后,将系统算法与目前比较优秀的YOLOv3算法在特征提取、网络结构等方面进行分析比较,并且将2种算法训练的跟踪器运行在OTB数据集上共同进行评估测试,通过对测试结果的比较分析,可以验证系统的算法要比YOLOv3的适应性更强,同时精确度也有所提高。
