改进卷积神经网络的COVID-19CT影像分类方法研究
2022-01-25吴辰文梁雨欣田鸿雁
吴辰文,梁雨欣,田鸿雁
兰州交通大学 电子与信息工程学院,兰州 730070
2019年12月初在中国湖北省武汉市出现与SARS病毒高度类似的病例,世界卫生组织(WHO)将SARSCov-2[1]这种病毒感染导致的疾病起名为新型冠状病毒(coronavirus disease 2019,COVID-19),新冠肺炎患者在感染后的前4至10天临床表现为呼吸困难、发热、干咳等症状。在治疗过程中,还没有特定的有效和安全的药物及治疗方法。大多数医院会对患者进行逆转录聚合酶链反应[2](RT-PCR)检测,但是该检测得出结果会花费大量时间,有报道称其假阴性率很高,并且全世界大多数感染地区缺乏诊断试剂盒。除了RT-PCR检测,计算机断层扫描[3](CT)检测更加快捷简便,已经成为辅助诊断和医治COVID-19的重要手段之一,国家卫生委员会确认湖北省将肺炎的影像学表现纳入临床诊断标准,保证了CT扫描影像对COVID-19严重程度的诊断意义。COVID-19胸部CT影像的突出表现为磨玻璃样混浊(GGO)、弥漫性肺泡损伤、病灶内合并血管增粗、病灶累及多个肺叶以及胸膜下部区域,呈“疯狂铺路”状等[4]。因此,开发计算机诊断辅助系统来检测新冠肺炎病例是非常重要的,既可以用于促进新冠肺炎患者的即时分流和治疗,又能防止疾病的广泛和快速传播。截止2021年6月初,已有200多个国家感染新冠肺炎,国内累计确诊超过10万例,累计治愈超过9万5千例;全球累计确诊超过1.73亿例,累计治愈超过1.39亿例。全国疫情数据如表1所示。
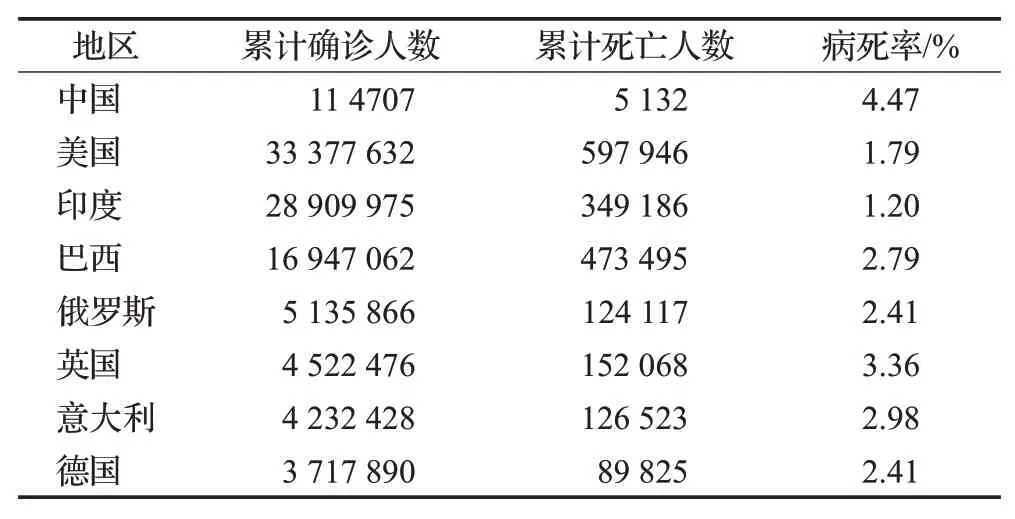
表1 截止2021年6月8日全球疫情数据Table 1 Global epidemic data as of June 8,2021
目前,深度学习在医疗领域的运用越来越普遍,卷积神经网络在解决医学图像处理以及计算机视觉等领域的问题时效果尤为显著,卷积神经网络由许多卷积层堆叠组成,用于从图像数据中自动提取特征。该方法已用于各种医学图像,如乳腺病变、脑和皮肤病变的分割以及肺结节的分割应用;另一方面,通过深度学习和计算机视觉对疾病进行诊断比放射科医生准确得多。因此在放射学中应用深度学习技术有助于获得更准确的诊断,将卷积神经网络应用到新冠肺炎CT影像检测中可以大大提高检测速度及精度。众所周知,基于深度学习的算法是基于大量样本数据的,卷积神经网络在数据集上获得较好效果的同时,依赖大量的数据和计算资源。因此,在有限公开的数据集下,经过一系列数据增强方法来扩充数据集是一项非常有必要的工作。林成创等人[5]系统性地梳理当前图像增广技术的相关研究并且介绍了每类增广研究中的代表性研究成果;Rajaraman等人[6]通过使用弱标记的CXR影像来扩展用于监督学习的训练数据分布,发现通过将简单的弱标记增强训练数据加入源数据集中可以显著提高性能;Ganesan等人[7]提出包括传统的数据增强技术,如翻转、旋转、弹性变形、随机裁剪以及基于生成对抗网络的合成数据生成方法;Loey等人[8]采用GAN来生成多的X光影像,并选取了三种深度迁移模型进行研究,以尽可能高的准确率从可用的X光影像中检测出该病毒。深度学习模型在医学影像中被普遍应用,因为它们可以自动提取特征或者通过一些预先训练的网络来提取特征。王坤等人[9]利用支持向量机、神经网络和随机森林三种方法对肝脏CT影像进行分类取得很好的效果;Nardelli等人[10]应用三维CNN的方法将胸部CT影像中的血管分类为动脉和静脉,还将提议的方法与随机森林分类器进行对比得到了更高的精度;Singh等人[11-12]基于粒子群优化的自适应神经模糊推理系统(ANFIS)提高了分类的精度;Hamdan等人[13]提出COVIDX-Net方法包含了七个深度学习模型的比较分析,该研究使用VGG19和DenseNet201获得了最高90%的准确率,然而,这项研究受到了小数据集的限制;此外,Sethy等人[14]使用ResNet50和支持向量机(SVM)分类,运用X射线影像诊断COVID-19,实验中使用了50张胸部X光影像;Narin等人[15]创建了深度卷积神经网络来自动检测X射线影像中的COVID-19,他们使用了基于迁移学习的方法和深度体系结构,如ResNet50、Inception v3等,由于患者的规模非常有限,网络模型深度过大会造成过度拟合风险上升。基于上述背景,本文提出了通过CGAN技术对有限数据集进行数据增强,并且将残差块融入到U-Net网络中,结合多层感知器以此建立一种新的网络架构基于CT影像检测COVID-19。
1 材料
1.1 数据集
本实验所用源数据为公开数据集COVID-19 CT(https://github.com/UCSD-AI4H/COVID-CT),其中包含来自216名患者的349个COVID-19影像和397个非COVID-19影像,使用条件生成对抗网络进行数据增强以扩大数据集的样本数量,减少发生过拟合现象,数据分布如表2所示。CT影像数据集示例如图1所示,图左为COVID-19 CT影像,图右为非COVID-19 CT影像。
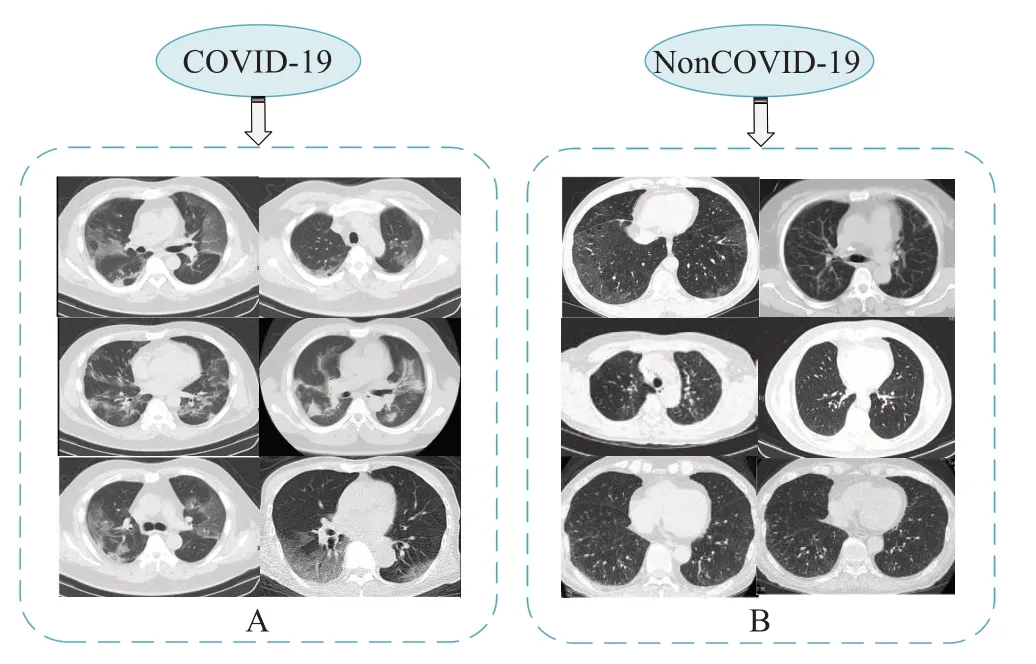
图1 CT影像数据集示例Fig.1 Example of CT image dataset

表2 CT影像的数据集分布Table 2 Data set distribution of CT images
1.2 数据预处理
实验中执行的预处理操作包括:(1)对CT影像进行阈值化,以移除非常亮的像素;(2)对CT影像进行15°旋转、水平翻转(处理胸部两侧的肺炎症状)、宽度偏移、高度偏移、缩放和随机裁剪(获取更深的像素关系)等;(3)对CT影像进行标准化,使像素值统一在(0,1)范围内,以降低计算复杂度;(4)对CT影像进行中值滤波以去除噪声和保留边缘;(5)对数据集通过条件生成对抗网络进行数据增强以扩充数据集,降低过拟合风险。对数据利用数据增强方法增强后的效果如图2所示。

图2 数据增强效果示例Fig.2 Example of data enhancement effect
2 方法
2.1 数据增强方法
2.1.1 生成对抗网络
生成对抗网络GAN(generative adversarial network)这个网络模型首次出现在2014年,是由Goodfellow等人发明的一种深度学习模型[16]。生成器(Generator)和判别器(Discriminator)这两部分组成了GAN。已经有大量的实验证明GAN可以有效处理数据集中样本量过少的问题。Frid-Adar等人[17]利用GAN生成合成医学图像,以此提升分类性能的精度;Gurumurthy等人[18]提出一种基于GAN的体系结构用于有限的训练数据场景,其结果是模型能够在生成的样本中实现多样性。Shin等人[19]同样利用GAN作为数据增强方式来说明它可以在肿瘤分割方面对性能进行改进。GAN的构造如图3所示。

图3 生成对抗网络结构Fig.3 Generative adversarial network structure
GAN损失函数V(D,G)由判别器最大化损失函数和生成器最小化损失函数构成:

式中,x表示实际的图像;z表示噪声图像;D(x)表示判别器对实际图像的判断值;D(G(z))表示判别器对生成图像G(z)的判断值;Pdata(x)表示实际图像的分布;Pz(z)表示噪声图像分布;Ex~Pdata(x)表示x服从实际图像分布取样的期望;Ez~Pz(z)表示z服从噪声图像分布取样的期望。
生成器它是以x作为模型输入,对x进行卷积操作可以提取到图像特征信息,生成的z服从实际图像分布的图像G(z)。生成器的损失函数V(G)越小,则G(z)与x越类似。判别器G(z)将和x同时作为输入,需要判断G(z)与x是否一致。判别器的损失函数V(D)在[0,1]之间,如果V(D)为1则生成的图像G(z)与实际图像x一致;如果V(D)为0则G(z)与x完全不一致。V(D)越大,G(z)与x越相似。判别器使G(z)尽可能地类似于x,最终得到D(x)。生成器和判别器两者通过博弈,最终使得生成器生成的G(z)无限接近于x。
2.1.2 条件生成对抗网络
CGAN是由两个不同类型的网络组成的,分别是生成器网络和判别器网络,其结构如图4所示。传统的生成对抗网络模型每次只能学习一类数据,对于含有多个类的样本集需要逐层学习,因此该模型存在效率低下的缺陷,而CGAN模型通过将相同的条件添加到生成器和判别器中,使GAN具备生成多类数据的生成能力。本文中使用的生成器网络由6个转置卷积层、5个ReLU层、5个批归一化层和末尾的Tanh层组成。而判别器网络由6个卷积层、5个leaky ReLU和4个批归一化组成,本文使用的CGAN构造如图5所示。与传统的GAN相比,CGAN修改了它的总体损失函数,如公式(2):

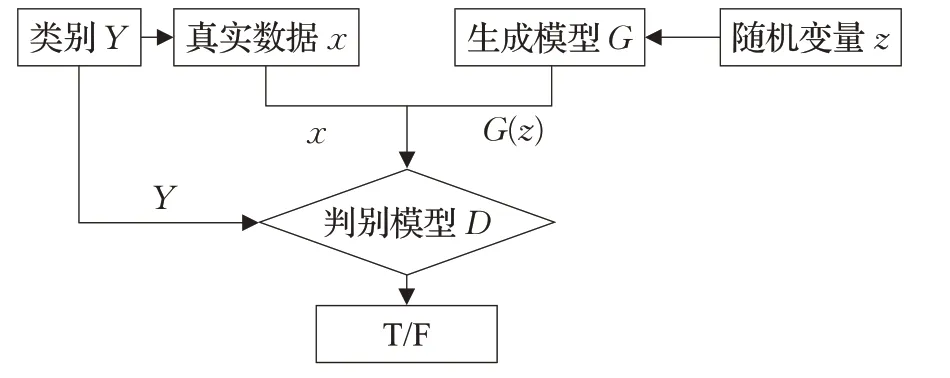
图4 条件生成对抗网络结构Fig.4 Conditional generative adversarial network structure

图5 本文使用的条件生成对抗网络结构Fig.5 Conditional generative adversarial network structure used in this article
由于公开的COVID-19 CT影像数据集有限,本文使用CGAN网络来克服COVID-19数据集中有限数量的CT影像造成的过拟合问题,它将数据集影像增加到了原始样本的6倍。数据增强有助于实现更好的分割精度和性能矩阵,实现的性能测量将在实验结果部分讨论。
2.2 改进的U-Net网络
2.2.1 U-Net网络
U-Net网络是一个基于CNN的端到端结构的图像分割网络,该网络广泛应用在医学图像分割上。U-Net是一个近乎对称的U字型模型,U左边为下采样,是一个编码过程,右边为上采样,是一个解码过程,其构造如图6所示。很多实验证明U-Net非常适用于医学图像的语义分割,贡荣麟等人[20]基于一种改进的U-Net算法通过融合自监督学习和有监督分割实现混合监督学习来实现乳腺超声图像的分割,以此提升图像分割准确性;纪玲玉等人[21]在U-Net网络的编码部分使用了带有卷积注意的Resnet34模块,使输出特征更加结构化,提升了血管分割的精度;邢妍妍等人[22]以U-Net网络为基础结合U-Net++最后一层特征,设计融合型的神经网络用于超声胎儿头部边缘检测。编码部分是为了得到更深层特征(即low resolution features,低分辨率特征),类似一种压缩操作。解码部分将编码后的深层特征还原回原始图像大小的最终输出图像。

图6 U-Net网络结构Fig.6 U-Net network structure
U-Net网络构造主要由卷积层、最大池化层、反卷积层和ReLU激活函数组成。鉴于医学图像界限模糊的特点,梯度较为复杂,因此底层信息对于精准分割尤为重要,U-Net这种网络模型可以很好地将高层的语义信息和浅层的位置信息融合起来。
2.2.2 改进的U-Net网络
(1)残差块
为了解决深度神经网络层次越深,会造成训练时出错率越多以及训练时间越长的问题,2016年He等人[23]在ImageNet图像识别竞赛中提出了残差网络(ResNet)这一模型,通过在网络中添加一个直连通道直接将输入结果添加到底层。其思想如公式(3)所示:

其中,x为输入,F(x)为隐藏层的输出结果,C(x)为底层映射。该残差块的结构如图7所示。

图7 残差块结构Fig.7 Residual block structure
(2)改进的U-Net网络
在U-Net中融入残差网络中的残差块,很大程度上避免了过拟合现象的出现,并且可以有效减少网络结构的层次加深导致的梯度消失问题,进而能够提升模型的分割性能。本文采用了一种改进的BIN残差块,以便在每次卷积后进行批标准化处理。BN层可以提升网络的泛化能力并且加速网络模型的训练,如公式(4):

其中,x∈ℝN×C×H×W为BN层输入,γ∈ℝC和β∈ℝC是从数据中学习到的映射参数,u(x)∈ℝC和σ(x)∈ℝC分别为输入的平均值和标准差。

Huang等人[24]提出IN层(instance-normalization)模型可以达到更快的训练速度。IN层的计算公式为公式(7)~(9):

Ioffe等人[25]通过说明BN的具体操作流程证明加入BN层可以大幅度加速模型的收敛。如公式(10)、(11)所示:

其中,μB和分别表示数据集的均值和方差。将归一化的数据输入网络,则在后续过程中不需要再调整网络学习来适应数据分布的变化。
本文将通道数相同的BN层和IN层同时添加到残差块的两层网络中,使用BIN残差块替换了原模型中的所有基于BN的残差块,使得残差块同时满足IN层和BN层的特点,首先会增大模型的收敛速度,模型可以不再依赖精细的参数初始化过程;其次,可以选择较大的学习率来解决反向传播过程中的梯度爆炸问题;另外,将会减少dropout层的使用频率,在一定程度上提升模型的泛化能力。两种残差块结构对比如图8所示。图8(a)为基于BN层的残差块结构,图8(b)为基于BIN层的残差块结构,其中BIN层由32通道的BN层和32通道的IN层组成,加入BN层和IN层不仅可以加速损失的收敛速度,也可以保留学习到的特征的语义信息。

图8 残差块结构对比Fig.8 Comparison of residual block structure
改进的U-Net网络使用的激活函数为sigmoid函数,损失函数Loss基于Dicecoeffient系数,如公式(12)、(13)所示:
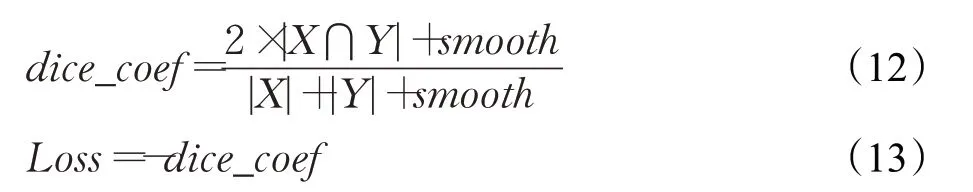
2.3 本文模型
本文所用算法主要包含三个步骤:(1)预处理。首先对收集到的COVID-19 CT数据集进行一系列基础预处理操作,主要包含翻转、旋转、偏移、缩放等。然后利用条件生成对抗网络对数据集进行数据增强以增加样本数量。(2)模型训练。本文模型是分割模型和分类模型的组合。具体来说,使用分割模型来获得肺部病变区域,然后使用分类模型来确定每个病变区域是否是新冠肺炎症状。分割模型是一个改进的U-Net网络,编码器部分交替使用了卷积和池化操作以此降低空间维度,将编码层和解码层中的全连接层全部替换为卷积操作,这样可以更好地提取层级特征。采用了两个3×3的卷积、一个3×3的BIN残差块以及一个2×2的池化操作。进行卷积操作来对图像进行初步的特征提取,第一层卷积减少通道数,并将数据送入下一个卷积进行处理,恢复特征映射的通道。残差块将输入特征和两层卷积后的结果相加,有效地减小了梯度消失。采用池化操作的目的是减少参数,防止过拟合。而解码器部分与编码器部分对称用以恢复池化操作造成的空间维度和目标上的细节损失,包含两个3×3的卷积、一个3×3的BIN残差块,最后加入1×1的卷积层做最后的分类。通过反卷积操作可以减半channel的数目,并且加倍特征图的分辨率。改进的U-Net网络的输出是一个32×32×1 024的张量,最后通过一个展平操作将数据转换成一维张量来执行分类。而多层感知器(multiple perceptron,MLP)由两个分别含有128和64个神经元的Dense层组成,以ReLU作为激活函数。最后是一个以sigmoid作为激活函数,含有1个神经元的Dense层用于图像分类。将CT影像输入到该网络模型平均1.79 s可以得到准确的分类。(3)性能评估:通过一系列的评价指标评估所提出算法的优劣。并且利用Grad-CAM技术如图9所示。

图9 本文提出的BUF-Net网络模型流程图Fig.9 Flow chart of BUF-Net network model proposed in this paper
2.4 实验设计
2.4.1 实验环境
本实验选择在Windows10操作系统上实现,通过在Tensorflow[26]后端上使用keras库[27]来开发和运行深度学习网络进行实验验证,其中有CUDA10.0和CUDNN8加速包的支持。实验运行的环境为python3.7,i5-8265U 2.30 GHz CPU,内存为8 GB。
2.4.2 实验设置
在实验中,通过改进的U-Net网络模型结合多层感知器对COVID-19 CT影像进行特征提取并分类,模型在训练过程中将初始学习率设置为0.001,动量设置为0.9。另外,还使用了提前停止策略技术即结果连续达到某个准确值就可以提前停止训练,以此防止网络过拟合,设置为40,模型训练100个epoch。选取随机梯度下降(SGD)优化器,其学习速率衰减率等于初始学习速率除以训练周期数。通过随机网格搜索方法优化模型的以下超参数:(1)动量;(2)SGD优化器的初始学习速率。
2.4.3 评价指标
为了验证本文提出的根据CT影像检测新冠肺炎的方法,采取五种不同的评估指标进行评估:正确率(Accuracy)、精确度(Precision)、敏感性(Sensitivity)、F1评分(F1-score)、特异性(Specificity)。其中,正确率是指正确辨识的样本数在所有样本数中占多少百分比。如式(14)所示;精确度如式(15)所示,是指正确辨识的样本数在所有判定为正确样本数中的比例;敏感性即召回率用来度量有多少个正例被正确辨别,如式(16)所示;灵敏度和精确度都可以从混淆矩阵中导出,F1-评分是精确度和敏感度的综合评估因子,如式(17)所示;特异性表示在所有的负例中被分对的部分所占的比例,如式(18)所示;AUC则表示“ROC曲线下面积”,与ACC相比,AUC对类别失衡的敏感性较低。
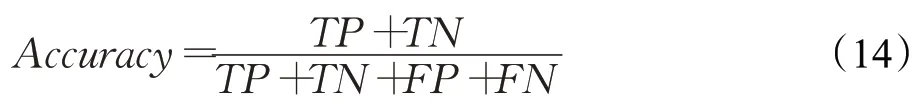

其中,TP表示被正确划分为正例的数量;TN表示被正确划分为负例的数量;FP表示被错误划分为正例的数量,也称误报率;FN表示被错误划分为负例的数量,也称漏报率。
3 结果
使用五倍交叉验证方案来验证模型性能,将训练数据随机分为五部分,在这五部分中,有四个部分被指定为训练集,其余部分被指定为验证集。这个过程重复了5次来训练和测试本文提出方法的性能。为了更直观地说明本文提出模型(BUF-Net)的有效性,将该算法与其他文献中提出的几种算法进行比较,表3为每个模型的性能指标(敏感性、准确率、F1值和敏感度)。可以看到本文提出模型的精确度和准确率表现较好,分别为97.1%和93.1%,特异性值对比另外几种模型结果较差。另外,其他模型大多没有利用Grad-CAM技术对分类结果进行可视化。

表3 BUF-Net算法与其他算法的比较Table 3 Comparison of BUF-Net algorithm with other algorithms %
混淆矩阵也是一种性能度量方法,它能更深入地了解所提出模型所实现的测试精度。图10表示原数据集A以及经过数据增强后数据集B的混淆矩阵对比图,结果表明,经过CGAN数据增强之后,所提出模型对大部分样本都进行了正确的分类,达到了97.1%的精确度。改进卷积神经网络和使用原始U-Net网络结合多层感知器模型的收敛性对比如图11所示,可以看出使用BIN残差块替换原残差块之后模型的收敛性更好,和加入BIN残差块之前相比,在第4到第18轮次收敛速度大幅度提升,迭代到第26轮次之后,收敛速度基本保持不变。图12为本文提出模型与其他经典算法分别在原始数据集和经过数据增强数据集两种场景的性能对比,结果显示AlexNet在场景1下的灵敏度最高,为87.9%,该指标指的是正确分类COVID-19 CT的能力。而GoogleNet的特异性较好,经过数据增强后该值略有增加。而较数据增强之前,VGGNet16的精确率有大幅度的提高,从75%提高到90%。VGG16和GoogleNet都有16层,包含了大量的参数。本文提出的模型在正确率、精确率、敏感性和F1指数这四个指标中都有明显的提高,从整体实验结果中可以得出BUF-Net模型的综合性能较其他算法表现较好,经过数据增强后性能有显著提升,达到了93%的准确率,较CGAN数据增强之前提高了9%的准确率。因此可以得出结论条件生成对抗网络是进行数据增强的有效方法。图13(a)显示了本文提出算法的ROC曲线,BUF-Net的AUC值达到了0.932。图13(b)为训练过程中的准确率和损失的对比曲线,为了防止过拟合,采取了提前停止策略技术将轮次设置为40,从图中看出大概在30轮次准确率和损失值达到平衡点,损失从1.3降低到0.13左右不再有变化。

图10 混淆矩阵Fig.10 Confusion matrix
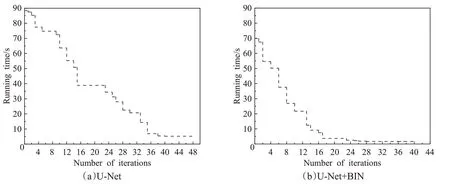
图11 收敛性对比Fig.11 Convergence comparison

图12 性能对比Fig.12 Performance comparison

图13 BUF-Net的ROC曲线和模型训练曲线Fig.13 ROC curve and model training curve of BUF-Net
通过梯度加权激活图(Grad-CAM)对输出结果可视化,以此生成分类区域,可以更直观地看出CT影像中肺结节的感染分布。Grad-CAM[33]是一种基于梯度的可视化方法,CAM方法仅限于特定的架构,其中平均池化层将卷积层与一个全连接层连接起来。在这种方法中,给定类的梯度是根据训练模型中最深的卷积层提取的特征计算的,并被输入到全局平均池化层,以获得决策所涉及的重要权重,然后会产生一个二维热图,它是将图像分类到各自类别的特征映射的加权组合。可视化结果如图14所示。红色和浅蓝色区域代表由深层神经网络激活的区域,深紫色背景代表未激活区域。根据Grad-CAM可以明显看出所提出模型对于检测COVID-19 CT有很好的作用。

图14 Grad-CAM可视化结果Fig.14 Grad-CAM visualization results
4 讨论和结论
本文的结果表明,相比于传统方法,深度学习方法能够改善诊断效率、提高治疗质量。本文提出的经过改进的分割联合分类的网络结构虽然可以有效提升准确度,但是还存在着一些不足,本研究针对的数据集样本量依然较小,结果易出现过拟合现象,所以未来工作需要考虑在更大的数据集上应用深度模型,另外需要探究更多的数据增强的方法,进一步验证本文提出研究方法的性能。
本文提出了一种新颖的方法,通过条件生成对抗网络对数据集进行数据增强来降低由于原始数据集样本量少造成的过拟合风险;另外,将增强后的CT影像数据集输入到改进的U-Net网络中进行医学分割,再结合多层感知器进行二元分类。通过与其他几种网络模型的评估指标进行比较,说明条件生成对抗网络是一种有效的数据增强的方法,本文提出的改进模型综合性能最优,达到了93.1%的分类准确率。最后,利用Grad-CAM技术对输出结果进行可视化,更直观地说明通过CT影像检测COVID-19的重要作用以及本文提出的BUF-Net算法对于预测COVID-19 CT影像的有效性。
